New Flame Steel Engine logo:

Soft & Games
I present to your attention a pure declarative programming language – Zakaz. The main idea of the new language is that the application contains commands for execution, written in any form, which must be executed by the “performers”. If no “executor” can execute the command, the execution of the program is stopped. Applications are called technical specifications (tez) and must have the extension .tez. Zakaz syntax obliges to observe two rules:
Hello World.tez example:
Show "Hello World" text on screen Show "Zakaz 'tez' example" text on screen
Example that prints description and open http://demensdeum.com in Firefox browser
Show "Show website demo" text on screen Show "You need Firefox installed on your system to run this 'tez', and it should be callable through \"system\" C function" text on screen Show "Also there should be \"FirefoxPerformer\" assigned to Zakaz Runtime, please check manual for more information" text on screen Show website with address "http://demensdeum.com" in Firefox
The above example must be run along with the FirefoxPerformer, which is able to handle the last command for displaying the site via Firefox
./ZakazRuntime openDemensdeumSite.tez FirefoxPerformer
To implement your “Performer”, you must implement it as a dynamic library using the abstract class ZakazRuntime :: Performer, and return it along with a smart pointer from the method of the global function createPerformer (). As an example, you can use the implementation of FirefoxPerformer.
https://gitlab.com/demensdeum/zakaz
In this post I will describe an example of adding functionality to a C ++ application using plugins. The practical part of the implementation for Linux is described; the theory can be found at the links at the end of the article.

To begin with, we will write a plugin – a function that we will call:
#include "iostream" using namespace std; extern "C" void extensionEntryPoint() { cout << "Extension entry point called" << endl; };
Next, we will build the plugin as a dynamic library “extension.so”, which we will connect in the future:
clang++ -shared -fPIC extension.cpp -o extension.so
Next we write the main application that will load the file “extension.so”, look for a pointer to the function “extensionEntryPoint” there, and call it, typing errors if necessary:
#include "iostream" #include "dlfcn.h" using namespace std; typedef void (*VoidFunctionPointer)(); int main (int argc, char *argv[]) { cout << "C++ Plugins Example" << endl; auto extensionHandle = dlopen("./extension.so", RTLD_LAZY); if (!extensionHandle) { string errorString = dlerror(); throw runtime_error(errorString); } auto functionPointer = VoidFunctionPointer(); functionPointer = (VoidFunctionPointer) dlsym(extensionHandle, "extensionEntryPoint"); auto dlsymError = dlerror(); if (dlsymError) { string errorString = dlerror(); throw runtime_error(errorString); } functionPointer(); exit(0); }
The dlopen function returns a handler for working with a dynamic library; dlsym function returns a pointer to the required function by string; dlerror contains a pointer to the string with the error text, if any.
Next, build the main application, copy the file of the dynamic library in the folder with it and run. The output should be the “Extension entry point called”
https://gitlab.com/demensdeum/cpppluginsexample
http://man7.org/linux/man-pages/man3/dlopen.3.htm
https://gist.github.com/tailriver/30bf0c943325330b7b6a
https://stackoverflow.com/questions/840501/how-do-function-pointers-in-c-work
[Feel the power of Artificial Intelligence]
В данной заметке я расскажу как предсказывать будущее.

В статистике существует класс задач – анализ временных рядов. Имея дату и значение некой переменной, можно прогнозировать значение этой переменной в будущем.
Поначалу я хотел реализовать решение данной задачи на TensorFlow, однако нашел библиотеку Prophet от Facebook.
Prophet позволяет делать прогноз на основе данных (csv), содержащих колонки даты (ds) и значения переменной (y). О том как с ней работать, можно узнать в документации на официальном сайте в разделе Quick Start
В качестве датасета я использовал выгрузку в csv с сайта https://www.investing.com, при реализации я использовал язык R и Prophet API для него. R мне очень понравился, так как его синтаксис упрощает работу с большими массивами данных, позволяет писать проще, допускать меньше ошибок, чем при работе с обычными языками (Python), так как пришлось бы работать с лямбда выражениями, а в R уже все лямбда выражения.
Для того чтобы не подготавливать данные к обработке, я использовал пакет anytime, который умеет переводить строки в дату, без предварительной обработки. Конвертация строк валюты в number осуществляется с помощью пакета readr.
В результате я получил прогноз по которому биткоин будет стоить 8400$ к концу 2019 года, а курс доллара будет 61 руб. Стоит ли верить данным прогнозам? Лично я считаю что не стоит, т.к. нельзя использовать математические методы, не понимая их сущности.
https://facebook.github.io/prophet
https://habr.com/company/ods/blog/323730/
https://www.r-project.org/
https://gitlab.com/demensdeum/MachineLearning/tree/master/4prophet
[Feel the power of Artificial Intelligence]
В этой заметке я опишу процесс создания генератора цитат.
Для обучения и генерации текста – использовать библиотеку textgenrnn, для фильтрации фраз нужно использовать проверку орфографии с помощью утилиты hunspell и ее библиотеки для C/python. После обучения в Colaboratory, можно приступать к генерации текста. Примерно 90% текста будет абсолютно не читаемым, однако оставшиеся 10% будут содержать толику смысла, а при ручной доработке фразы будут выглядеть вполне неплохо.
Проще всего запустить готовую нейросеть в Colaboratory:
https://colab.research.google.com/drive/1-wbZMmxvsm3SoclJv11villo9VbUesbc
https://gitlab.com/demensdeum/MachineLearning/tree/master/3quotesGenerator
https://minimaxir.com/2018/05/text-neural-networks/
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
https://medium.com/deep-learning-turkey/google-colab-free-gpu-tutorial-e113627b9f5d
https://github.com/wooorm/dictionaries
[Feel the power of Artificial Intelligence]
На Hacker News нашел очень интересную статью в которой автор предлагает использовать метод Петерсена-Линкольна, который используется биологами для подсчета популяции птичек, обезьянок и прочих животных, для *барабанная дробь* подсчета багов в приложении.

Баг в естественной среде обитания – Bigfoot Sighting by Derek Hatfield
Метод очень прост, берем двух орнитологов, они находят птичек какого-то определенного вида, их задача – определить размер популяции этих птичек. Найденные птички помечаются обоими орнитологами, далее подсчитывается количество общих, подставляется в формулу индекса Линкольна и мы получаем примерный размер популяции.
Теперь для приложений – метод также очень прост, берем двух QA и они находят баги в приложении. Допустим один тестировщик нашел 10 багов (E1), а второй 20 багов (E2), теперь берем число общих багов – 3 (S), далее по формуле получаем индекс Линкольна:
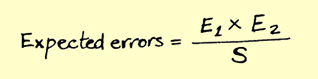
Это и есть прогноз числа багов во всем приложении, в приведенном примере ~66 багов.
Я реализовал тестовый стенд для проверки метода, посмотреть можно здесь:
https://paiza.io/projects/AY_9T3oaN9a-xICAx_H4qw?language=swift
Параметры которые можно менять:
let aliceErrorFindProbability = 20 – процент нахождения багов у QA Alice (20%)
let bobErrorFindProbability = 60 – процент нахождения багов у QA Bob (60%)
let actualBugsCount = 200 – сколько багов в приложении на самом деле
В последнем запуске я получил следующие данные:
Estimation bugs count: 213
Actual bugs count: 200
Тоесть в приложении есть 200 багов, индекс Линкольна дает прогноз – 213:
“Alice found 36 bugs”
“Bob found 89 bugs”
“Common bugs count: 15”
—
Estimation bugs count: 213
Actual bugs count: 200
Использовать данный метод можно для оценки количества ошибок в приложении, на всех этапах разработки, в идеале количество багов должно уменьшаться. К слабым сторонам метода я могу отнести человеческий фактор, так как количество найденных багов от двух тестировщиков должно быть разным и найдены разные баги, однако должны быть найдены и общие, иначе метод работать не будет (ноль общих багов – деление на ноль)
Также такое понятие как общие баги требует обязательное наличие эксперта для понимания их общности.
How many errors are left to find? – John D. Cook, PhD, President
The thrill of the chase – Brian Hayes
https://paiza.io/projects/AY_9T3oaN9a-xICAx_H4qw?language=swift
https://gitlab.com/demensdeum/statistics/tree/master/1_BugsCountEstimation/src
[Feel the power of Artificial Intelligence]
Ах муза, как сложно тебя поймать порой.
Разработка Death-Mask, и связанных фреймворков (Flame Steel Core, Game Toolkit и др.) приостанавливается на несколько месяцев, для того чтобы определиться с художественной частью игры, музыкальным, звуковым сопровождением, продумыванием геймплея.
В планах – создать редактор для Flame Steel Game Toolkit, написать интерпретатор игровых скриптов (на основе синтаксиса Rise), реализовать игру Death-Mask для максимально большого количества платформ.
Сложнейший этап пройден – на практике доказана возможность написания своего собственного кроссплатформенного игрового движка, своего IDE, набора библиотек.
Перехожу к этапу создания действительно продуманного, интересного проекта, следите за новостями.
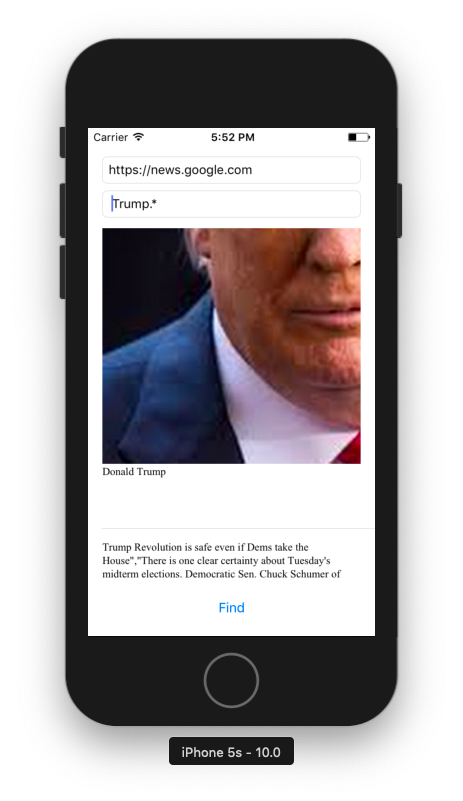
News Crawler for iOS. This application allows you to search text while file downloading.
Big files support by default (> 200mb), saves result into result.log file.
Simple clever design.
Regex support through Regex library.
Source code:
https://gitlab.com/demensdeum/news-crawler