
《Donki Hills》是一款第一人称恐怖喜剧冒险游戏,带领玩家经历一个结合了悬念和意想不到的幽默的神秘故事。
主角詹姆斯去寻找他的网友玛丽亚,但她的联系突然被切断。唯一的证据是一张随机照片,指向新西伯利亚地区偏远的顿基山村庄。为了查清真相,詹姆斯开始自己的调查,以查明玛丽亚失踪的所有情况。
该游戏已在 Steam 上发售:
https://store.steampowered.com/app/3476390/Donki_Hills/
《Donki Hills》是一款第一人称恐怖喜剧冒险游戏,带领玩家经历一个结合了悬念和意想不到的幽默的神秘故事。
主角詹姆斯去寻找他的网友玛丽亚,但她的联系突然被切断。唯一的证据是一张随机照片,指向新西伯利亚地区偏远的顿基山村庄。为了查清真相,詹姆斯开始自己的调查,以查明玛丽亚失踪的所有情况。
该游戏已在 Steam 上发售:
https://store.steampowered.com/app/3476390/Donki_Hills/

Masonry AR 是一款基于位置的多人增强现实 (AR) 游戏,让您沉浸在秘密社团的世界中。探索你所在城市的街道,收集共济会知识书籍,建立你自己的小屋,并争夺对现实世界地图的影响力。
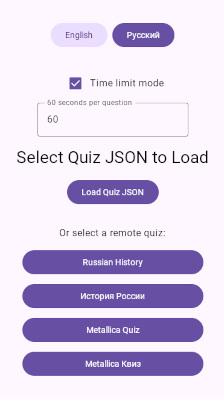
Teflecher 是一款快速、交互式、跨平台的测验应用程序,构建于 Kotlin Multiplatform (KMP) 和 Compose Multiplatform 之上。它允许用户直观地从本地 JSON 文件或远程 URL 加载测验、回答多项选择题、查看正确答案的即时反馈并跟踪结果。
网址:
https://demensdeum.com/software/teflecher/
GitHub:
https://github.com/zefir1990/teflecher
也是基于 Ionic + Capacitor 技术的 Teflecher Editor 格式的测验编辑器

Ghost Contacts 是一个简单的 Web 应用程序,旨在隐藏标准系统 API 和电话簿中的联系人。所有信息仅存储在您的浏览器本地,不会传输到外部服务器。

欢迎来到Cube Art Project 2 – 一个冥想的 3D 画布,您可以在其中尽情发挥您的想象力。创建体素绘画、尝试颜色并在浏览器中将独特的 3D 模型变为现实。
这是一款创意游戏,可将您的屏幕变成用于 3D 绘画的交互式画布。在你面前的是一个干净的三维空间,准备好充满你的想法、形状和明亮的色彩。
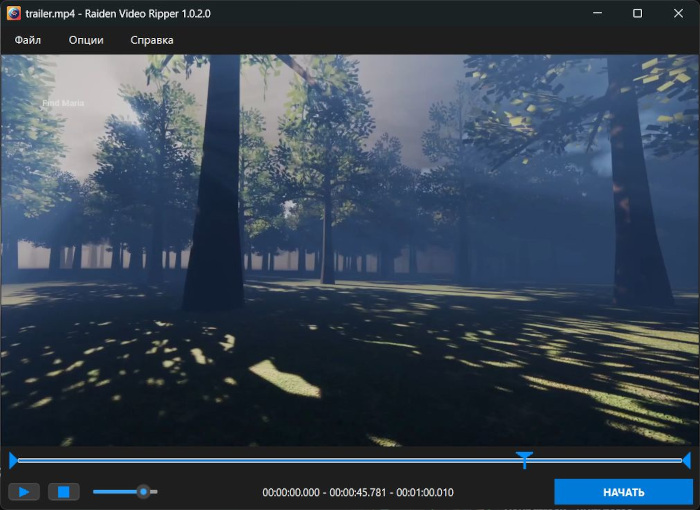
Raiden Video Ripper 是一个专为视频编辑和格式转换而设计的开源项目。它是使用 Qt 6 (Qt Creator) 创建的,允许您编辑视频并将其转换为 MP4、GIF 和 WebM 格式。您还可以从视频中提取音频并将其转换为 MP3 格式。
微软商店:
https://apps.microsoft.com/detail/9nvzjs98smgc
GitHub:
https://github.com/demensdeum/RaidenVideoRipper/releases

在这颗红色星球的恶劣条件下,每一秒、每一个区域都至关重要。我们很高兴推出火星矿工,这是一款回合制策略游戏,您可以在其中为殖民地的生存和宝贵的火星资源的控制权而战。
在火星矿工中,您控制着火星上的一家采矿公司。你的任务是建立基地,占领资源区,并在面对人工智能或其他玩家的激烈竞争时协调自主采矿单位的行动。

在充满冷光的工业巨型建筑的无尽走廊中,新的挑战正在等待着您。我们很高兴推出Flame Steel: Death Mask 2,这是一款结合了经典美学与现代实时游戏玩法的 3D 地下城探索游戏。
想象一下在一个程序生成的迷宫中醒来,其中每个回合都可能潜伏着一个名为“过滤器”的敌对实体。在Flame Steel: Death Mask 2中,您将扮演探索者的角色,探索基于 Flame Steel 引擎 2(使用 Three.js 图形渲染)构建的世界。
该游戏是为浏览器创建的并使用:
Ushki-Radio 是一款用于在线广播的跨平台广播播放器,专注于简单性和聆听乐趣。没有不必要的功能,没有超载的接口 – 只需打开它并聆听即可。
![]()
https://demensdeum.com/software/ushki-radio
该项目使用开源广播浏览器,使来自世界各地的数千个广播电台可以在应用程序中使用。您可以按名称、流派或受欢迎程度搜索它们,将它们添加到您的收藏夹并快速返回您最喜欢的电台。
Ushki-Radio 非常适合背景广播播放器的角色:它会记住最后一个电台,允许您控制音量并且不需要复杂的设置。界面简洁易懂 – 一切都经过精心设计,不会分散音乐、对话和广播的注意力。
从技术上讲,该项目是基于 React Native 和 Expo 构建的,因此它既可以在浏览器中运行,也可以作为本机应用程序运行。在底层,expo-av 用于播放音频,用户设置存储在本地。支持多种语言,包括俄语和英语。
Ushki-Radio 是现代互联网广播播放器的一个很好的例子:开放、轻量级、可扩展并且主要以听众为中心。该项目根据 MIT 许可证分发,非常适合个人使用,也可以作为您自己的音频应用实验的基础。
GitHub:
https://github.com/demensdeum/Ushki-Radio
谷歌播放:
https://play.google.com/store/apps/details?id=com.demensdeum.ushkiradio
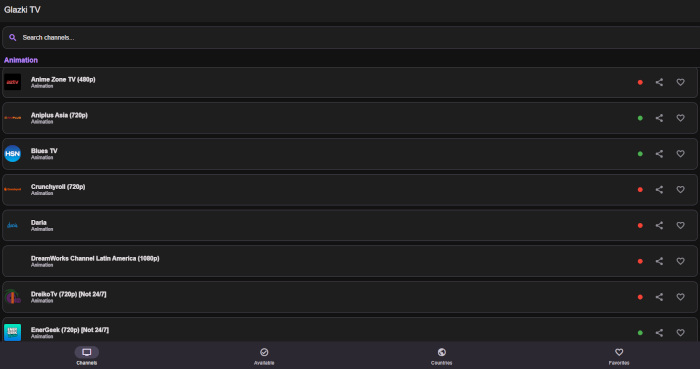
Glazki TV 是一款现代、高性能的互联网电视 (IPTV) 播放器,建立在 React Native 和 Expo 的基础上。该项目注重易用性和速度,为在移动设备和浏览器中观看 IPTV 频道提供便捷的界面。
该项目基于现代开发工具:
网页版:
https://demensdeum.com/software/glazki-tv/
谷歌播放版本:
https://play.google.com/store/apps/details?id=com.demensdeum.glazkitv

Zefir1990 – Ilia Prokhorov,我是一名拥有超过 15 年商业开发经验的开发人员。 Demens Deum 工作室的创始人,该工作室为移动、网络和桌面系统开发游戏和应用程序。 Android 2上的第一款3D OpenGL ES 2游戏Mad Racer于2010年发布,他是该项目的程序员和游戏设计师,他还参与了作曲家Anton Dmitriev(coolspotdreamer)的开发,在游戏成功推出后他从事全职定制开发和合同项目开发。客户包括迪卡侬、花花公子、Fitbit。
我也是软件开发、游戏、设计模式、算法、人工智能方面文章的作者,我计划写一本关于软件熵的书。
首选编程语言:ASM、C、C++、ObjC、Python、Kotlin、Swift、Java、Rust、Go、TypeScript、JavaScript、C#、Dart、PHP。
LinkedIn:linkedin.com/in/zefir1990
GitHub:github.com/zefir1990
电报:t.me/zefir1990
电子邮件:ceo@demensdeum.com
抽搐:twitch.tv/zefir1990
YouTube:youtube.com/zefir1990