在黑客新闻上,我发现了一篇非常有趣的文章,其中作者建议使用Petersen-Lincoln 方法,生物学家使用该方法来计算鸟类、猴子和其他动物的数量,以便在应用程序中*击鼓*计数错误。

方法很简单,我们取两个鸟类学家,他们发现特定物种的鸟类,它们的任务是“确定这些鸟类的种群规模。两位鸟类学家对发现的鸟类进行标记,然后计算常见鸟类的数量,代入林肯指数公式,即可得出大致的种群规模。
现在开始申请——方法也很简单,我们进行了两次 QA,他们发现了应用程序中的 bug。假设一位测试人员发现了 10 个错误 (E1),第二位测试人员发现了 20 个错误 (E2),现在我们计算错误总数 – 3 (S),然后使用公式我们得到林肯指数:
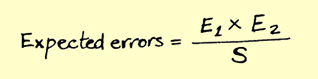
这是对整个应用程序中错误数量的预测,在给出的示例中大约有 66 个错误。
Swift 示例
我已经实现了一个测试平台来测试该方法,你可以在这里看到它:
https://paiza.io/projects/AY_9T3oaN9a-xICAx_H4qw?language=swift
可以更改的参数:
让 aliceErrorFindProbability = 20 – QA Alice 发现的错误百分比 (20%)
让 bobErrorFindProbability = 60 – QA Bob 发现的错误百分比 (60%)
让实际BugsCount = 200 –应用程序中到底有多少错误
在上次运行中我收到了以下数据:
估计错误数:213
实际错误数:200
也就是说,应用程序中有 200 个 bug,林肯指数给出了预测“200 个 bug”。 213:
“Alice 发现了 36 个错误”
“鲍勃发现了 89 个错误”
“常见错误数量:15”
—
估计错误数:213
实际错误数:200
弱点
此方法可用于评估应用程序在开发的各个阶段的错误数量;理想情况下,错误数量应该减少。 该方法的弱点包括人为因素,因为两个测试人员发现的错误数量应该不同,并且发现了不同的错误,但是 必须找到常见的,否则该方法将不起作用(零常见错误–被零除)< br/>此外,诸如常见错误这样的概念需要专家在场才能理解其共性。
来源
还有多少错误需要查找? –约翰·库克博士,总裁
The thrill of the chase – Brian Hayes
源代码
https://paiza.io/projects/AY_9T3oaN9a-xICAx_H4qw ?语言=swift
https://gitlab.com/demensdeum/statistics/tree/master/1_BugsCountEstimation/src