Neste post descreverei o processo de construção de bibliotecas e aplicativos para Windows usando o conjunto de ferramentas MinGW32 no Ubuntu. Instale o vinho, mingw:
sudo apt-get install wine mingw-w64
Depois disso, você já pode criar aplicativos C/C++ para Windows:
Nesta nota, descreverei a implementação da execução de um autoteste para o ChromeDriver do navegador Chrome, que executa um autoteste de módulo traduzido de C++ usando Emscripten, lê a saída do console e retorna o resultado do teste. Primeiro você precisa instalar o Selenium, para Python 3-Ubuntu isso é feito assim:
pip3 install selenium
Em seguida, baixe o ChromeDriver do site oficial, coloque o chromedriver em /usr/local/bin, por exemplo, depois disso você pode começar a implementar o autoteste. Abaixo darei o código de autoteste que inicia o navegador Chrome com a página de autoteste aberta no Emscripten, verifica a presença do texto “Teste de janela bem sucedido”:
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
capabilities = DesiredCapabilities.CHROME
capabilities['goog:loggingPrefs'] = { 'browser':'ALL' }
driver = webdriver.Chrome()
driver.get("http://localhost/windowInitializeTest/indexFullscreen.html")
time.sleep(2)
exitCode = 1
for entry in driver.get_log('browser'):
if entry["source"] == "console-api":
message = entry["message"]
if "Window test succeded" in message:
print("Test succeded")
exitCode = 0
driver.close()
exit(exitCode)
Salve o teste como main.py e execute python3 main.py
Neste post irei descrever a construção de um projeto composto por diversas bibliotecas utilizando Emscripten. No momento, o Emscripten não oferece suporte à construção de bibliotecas compartilhadas, então o primeiro passo é transferir todas as bibliotecas de Compartilhadas para Estáticas. O Emscripten funciona com seus próprios arquivos de inclusão, portanto, o problema com a visibilidade dos arquivos de cabeçalho precisa ser resolvido. Resolvi isso encaminhando um link simbólico do diretório do sistema para o conjunto de ferramentas do Emscripten:
Se você estiver usando o CMake, será necessário alterar SHARED->STATIC no arquivo CMakeLists.txt do método add_library. Você pode construir uma biblioteca/aplicativo para links estáticos adicionais usando os comandos:
emcmake cmake .
emmake make
Em seguida, você precisará construir o aplicativo principal especificando os arquivos de biblioteca *.a no estágio de vinculação. Não consegui especificar um caminho relativo; a compilação foi concluída corretamente somente após especificar os caminhos completos no arquivo CMakeLists.txt:
Recentemente, decidi separar todas as partes do FlameSteelFramework em bibliotecas compartilhadas. Depois, mostrarei um exemplo de um arquivo CMakeLists.txt para FlameSteelCore:
Comandos que o CMake executa: coleta todos os arquivos com extensão *.cpp do diretório src/FlameSteelCore/ em uma biblioteca compartilhada, copia todos os cabeçalhos com extensão *.h de src/FlameSteelCore para include/FlameSteelFramework (no meu caso este é /usr/local/include/FlameSteelFramework), copia a lib compartilhada para o diretório lib (/usr/local/lib) Após a instalação, pode ser necessário atualizar o cache LD – sudoldconfig. Para compilar e instalar no Ubuntu (se você tiver o conjunto de ferramentas de compilação correto), basta executar os seguintes comandos:
cmake . && make && sudo make install
Para testar o processo de instalação, passo make prefix para a pasta local makeInstallTestPlayground:
cmake -DCMAKE_INSTALL_PREFIX:PATH=/home/demensdeum/makeInstallTestPlayground . && make && make install
Há pouco tempo me deparei com um projeto interessante chamado Cling, um interpretador de linguagem C++ que pode funcionar interativamente a partir do console, entre outras coisas. Você pode visualizar o projeto no seguinte link: https://github.com/root -projeto/agarrar A instalação do Ubuntu é simples – baixe o arquivo para a versão necessária, descompacte-o, vá para a pasta bin e execute cling no terminal. Abaixo está um exemplo de carregamento da biblioteca FlameSteelCore, inicializando o objeto, imprimindo o id:
O padrão Builder pertence a um grupo de padrões cuja existência não é particularmente clara para mim, noto a óbvia redundância disso. Pertence ao grupo de padrões de design generativos. Usado para implementar uma interface simples para criar objetos complexos.
Aplicabilidade
Simplificação da interface. Pode facilitar a criação de um objeto em construtores com um grande número de argumentos e melhorar objetivamente a legibilidade do código.
Exemplo em C++ sem construtor:
auto weapon = new Weapon(“Claws”);
monster->weapon = weapon;
auto health = new MonsterHealth(100);
monster->health = health;
Пример со строителем на C++:
.addWeapon(“Claws”)
.addHealth(100)
.build();
Однако в языках поддерживающих именованные аргументы (named arguments), необходимость использовать именно для этого случая отпадает.
Пример на Swift с использованием named arguments:
let monster = Monster(weapon: “Claws”, health: 100)
Imutabilidade. Usando o construtor, você pode garantir o encapsulamento do objeto criado até a fase final de montagem. Aqui você precisa pensar bem se usar um padrão vai te salvar da alta dinâmica do ambiente em que você trabalha talvez usar o padrão não dê nada, pela simples falta de cultura de uso de encapsulamento entre a equipe de desenvolvimento; .
Interação com componentes em diferentes estágios de criação de objetos. Também utilizando o padrão, é possível garantir a criação passo a passo de um objeto ao interagir com outros componentes do sistema. Provavelmente isso é muito útil (?)
Críticas
É claro que você precisa pensar *com cuidado* se vale a pena estabelecer o uso generalizado do padrão em seu projeto. Linguagens com sintaxe moderna e um IDE avançado eliminam a necessidade de uso do Builder, em termos de melhoria da legibilidade do código (veja o ponto sobre argumentos nomeados) Esse padrão deveria ter sido usado em 1994, quando o livro GoF foi publicado? Provavelmente sim, porém, a julgar pela base de código-fonte aberto daqueles anos, poucas pessoas o usaram.
O padrão Composite refere-se a padrões de design estrutural; em fontes domésticas é conhecido como “Compositor”. Digamos que estejamos desenvolvendo um aplicativo – álbum de fotos. O usuário pode criar pastas, adicionar fotos e realizar outras manipulações. Definitivamente, você precisa mostrar o número de arquivos em pastas, o número total de todos os arquivos e pastas. É óbvio que você precisa usar uma árvore, mas como implementar uma arquitetura em árvore com uma interface simples e conveniente? O padrão Composite vem em socorro.
Implementamos a interface Component com o método dataCount() que precisamos, através do qual retornaremos a quantidade de arquivos/diretórios. Vamos criar uma classe Directory com uma interface que permite adicionar/remover instâncias de classes que implementam a interface Component de acordo com o padrão, esta é Composite. Também criaremos uma classe File, onde armazenamos bytes com um cartão de foto, herdamos de Component e retornamos 1 através de dataCount, dizendo que há apenas uma foto!
A seguir no Diretório implementamos o método dataCount() – percorrendo todos os elementos da matriz de componentes, somando todos os seus dataCount’s.
Tudo está pronto!
Abaixo está um exemplo em Go:
package main
import "fmt"
type component interface {
dataCount() int
}
type file struct {
}
type directory struct {
c []component
}
func (f file) dataCount() int {
return 1
}
func (d directory) dataCount() int {
var outputDataCount int = 0
for _, v := range d.c {
outputDataCount += v.dataCount()
}
return outputDataCount
}
func (d *directory) addComponent(c component) {
d.c = append(d.c, c)
}
func main() {
var f file
var rd directory
rd.addComponent(f)
rd.addComponent(f)
rd.addComponent(f)
rd.addComponent(f)
fmt.Println(rd.dataCount())
var sd directory
sd.addComponent(f)
rd.addComponent(sd)
rd.addComponent(sd)
rd.addComponent(sd)
fmt.Println(sd.dataCount())
fmt.Println(rd.dataCount())
}
O padrão Adaptador refere-se a padrões de projeto estrutural.
O adaptador fornece conversão de dados/interface entre duas classes/interfaces.
Suponha que estejamos desenvolvendo um sistema para determinar as metas de um comprador em uma loja com base em redes neurais. O sistema recebe um stream de vídeo da câmera de uma loja, identifica os clientes pelo seu comportamento e os classifica em grupos. Tipos de grupos – veio comprar (potencial comprador), só para olhar (espectador), veio roubar algo (ladrão), veio devolver a mercadoria (comprador insatisfeito), veio bêbado/alto (potencial desordeiro).
Como todos os desenvolvedores experientes, encontramos uma rede neural pronta que pode classificar espécies de macacos em uma gaiola com base em um fluxo de vídeo, que o Instituto Zoológico do Zoológico de Berlim gentilmente disponibilizou gratuitamente, treiná-lo novamente em um fluxo de vídeo da loja e obtenha um sistema funcional de última geração .
Há apenas um pequeno problema – o stream de vídeo é codificado no formato mpeg2 e nosso sistema suporta apenas OGG Theora. Não temos o código fonte do sistema, a única coisa que podemos fazer é – alterar o conjunto de dados e treinar a rede neural. O que fazer? Escreva uma classe adaptadora que irá transferir o stream de mpeg2 -> OGG Theora e enviá-lo para a rede neural.
De acordo com o esquema clássico, o padrão envolve cliente, alvo, adaptado e adaptador. O cliente neste caso é uma rede neural que recebe um stream de vídeo no OGG Theora, alvo – a interface com a qual interage, adaptado – interface enviando stream de vídeo em mpeg2, adaptador – converte mpeg2 em OGG Theora e o envia pela interface de destino.
O padrão delegado é um dos principais padrões de design. Digamos que estamos desenvolvendo um aplicativo para uma barbearia. O aplicativo possui um calendário para seleção de um dia para gravação; ao tocar na data deverá abrir uma lista de barbeiros com opção. Vamos implementar uma ligação ingênua de componentes do sistema, combinar o calendário e a tela usando ponteiros entre si para implementar uma exibição de lista:
// псевдокод
class BarbershopScreen {
let calendar: Calendar
func showBarbersList(date: Date) {
showSelectionSheet(barbers(forDate: date))
}
}
class Calendar {
let screen: BarbershopScreen
func handleTap(on date: Date) {
screen.showBarbersList(date: date)
}
}
Depois de alguns dias, os requisitos mudam; antes de exibir a lista, é necessário mostrar ofertas com opção de serviços (aparar barba, etc.), mas nem sempre, em todos os dias, exceto sábado. Adicionamos ao calendário uma verificação se é sábado ou não, dependendo disso chamamos o método da lista de barbeiros ou da lista de serviços, para maior clareza irei demonstrar:
// псевдокод
class BarbershopScreen {
let calendar: Calendar
func showBarbersList(date: Date) {
showSelectionSheet(barbers(forDate: date))
}
func showOffersList() {
showSelectionSheet(offers)
}
}
class Calendar {
let screen: BarbershopScreen
func handleTap(on date: Date) {
if date.day != .saturday {
screen.showOffersList()
}
else {
screen.showBarbersList(date: date)
}
}
}
Uma semana depois, somos solicitados a adicionar um calendário à tela de feedback e, nesse momento, acontece o primeiro erro arquitetônico! O que fazer? O calendário está intimamente ligado à tela de marcação de corte de cabelo. uau! eca! ah ah Se você continuar trabalhando com essa arquitetura maluca de aplicação, você deve fazer uma cópia de toda a classe de calendário e associar essa cópia à tela de feedback. Ok, parece bom, então adicionamos mais algumas telas e várias cópias do calendário, e então chegou o momento X. Fomos solicitados a alterar o design do calendário, o que significa que agora precisamos encontrar todas as cópias do calendário e adicionar as mesmas alterações a todas. Essa “abordagem” afeta muito a velocidade de desenvolvimento e aumenta a chance de cometer erros. Como resultado, tais projetos acabam em um estado quebrado, quando até mesmo o autor da arquitetura original não entende mais como funcionam as cópias de suas aulas, e outros hacks adicionados ao longo do caminho desmoronam na hora. O que precisava ser feito, ou melhor ainda, o que não era tarde demais para começar a fazer? Use o padrão de delegação! A delegação é uma forma de passar eventos de classe por meio de uma interface comum. Abaixo está um exemplo de delegado para um calendário:
Como resultado, desvinculamos completamente o calendário da tela ao selecionar uma data no calendário, ele transmite o evento de seleção de data – *delega* processamento de eventos ao assinante; O assinante é a tela. Que benefícios obtemos com esta abordagem? Agora podemos alterar a lógica do calendário e da tela de forma independente, sem duplicar classes, simplificando ainda mais o suporte; Desta forma, é implementado o “princípio da responsabilidade exclusiva” pela implementação dos componentes do sistema e observado o princípio DRY. Ao usar a delegação, você pode adicionar, alterar a lógica de exibição das janelas, a ordem de qualquer coisa na tela, e isso não afetará em nada o calendário e outras classes, que objetivamente não devem participar de processos não diretamente relacionados a elas.< br/>Alternativamente, os programadores que não se preocupam muito usam o envio de mensagens através de um barramento comum, sem escrever uma interface separada de protocolo/delegado, onde seria melhor usar a delegação. Escrevi sobre as desvantagens dessa abordagem em um post anterior & # 8211; “Padrão do Observador.”
O padrão Observer refere-se a padrões de design comportamentais. O padrão permite enviar uma mudança no estado de um objeto aos assinantes usando uma interface comum. Digamos que estamos desenvolvendo um mensageiro para programadores, temos uma tela de chat no aplicativo. Ao receber uma mensagem com o texto “problema” e “erro” ou “algo está errado”, você precisa colorir a tela da lista de erros e a tela de configurações de vermelho. A seguir, descreverei 2 opções para resolver o problema, a primeira é simples, mas extremamente difícil de suportar, e a segunda é muito mais estável no suporte, mas requer que você vire a cabeça durante a implementação inicial.
Ônibus comum
Todas as implementações do padrão contêm o envio de mensagens quando os dados são alterados, a assinatura de mensagens e o processamento adicional em métodos. A opção de barramento compartilhado contém um único objeto (geralmente um singleton) que despacha mensagens aos destinatários. A simplicidade de implementação é a seguinte:
O objeto envia uma mensagem abstrata para o barramento compartilhado
Outro objeto inscrito no barramento compartilhado captura a mensagem e decide se deve processá-la ou não.
Uma das opções de implementação disponíveis na Apple (subsistema NSNotificationCenter), adicionou correspondência do cabeçalho da mensagem ao nome do método que é chamado pelo destinatário na entrega. A maior desvantagem desta abordagem – Se você alterar ainda mais a mensagem, primeiro precisará lembrar e depois editar manualmente todos os locais para onde ela é processada e enviada. É um caso de implementação inicial rápida, seguida de suporte longo e complexo que requer uma base de conhecimento para operação correta.
Delegado multicast
Nesta implementação, faremos a classe delegada multicast final, assim como no caso de um barramento compartilhado, os objetos podem se inscrever nele para receber “mensagens” ou “eventos”, mas o trabalho de análise e filtragem de mensagens é feito; não atribuído aos objetos. Em vez disso, as classes de assinantes devem implementar os métodos multicast do delegado com os quais são notificados. Isso é implementado usando interfaces/protocolos delegados; quando a interface geral muda, a aplicação não será mais construída, momento em que será necessário refazer todos os locais para processamento de uma determinada mensagem, sem a necessidade de manter uma base de conhecimento separada. para lembrar desses lugares. O compilador é seu amigo. Esta abordagem aumenta a produtividade da equipe, pois não há necessidade de escrever ou armazenar documentação, não há necessidade de um novo desenvolvedor tentar entender como uma mensagem e seus argumentos são processados, ao invés disso eles trabalham com uma interface conveniente e compreensível , é assim que o paradigma de documentação por meio de código é implementado. O delegado multicast em si é baseado no padrão de delegado, sobre o qual escreverei no próximo post.
O padrão Proxy refere-se a padrões de projeto estruturais. O padrão descreve a técnica de trabalhar com uma classe através de uma camada de classe – procuração. Um proxy permite alterar a funcionalidade da classe original, com a capacidade de preservar o comportamento original, enquanto mantém a interface da classe original. Vamos imaginar a situação – em 2015, um dos países da Europa Ocidental decide registar todos os pedidos aos sites dos utilizadores do país, de forma a melhorar as estatísticas e a compreensão aprofundada dos sentimentos políticos dos cidadãos. Imaginemos o pseudocódigo de uma implementação ingênua do gateway que os cidadãos utilizam para acessar a Internet:
class InternetRouter {
private let internet: Internet
init(internet: Internet) {
self.internet = internet
}
func handle(request: Request, from client: Client) -> Data {
return self.internet.handle(request)
}
}
No código acima, criamos uma classe de roteador de Internet com um ponteiro para um objeto que fornece acesso à Internet. Quando um cliente faz uma solicitação de site, retornamos uma resposta da Internet.
Usando o padrão Proxy e o antipadrão singleton, adicionaremos funcionalidade para registrar o nome e URL do cliente:
class InternetRouterProxy {
private let internetRouter: InternetRouter
init(internet: Internet) {
self.internetRouter = InternetRouter(internet: internet)
}
func handle(request: Request, from client: Client) -> Data {
Logger.shared.log(“Client name: \(client.name), requested URL: \(request.URL)”)
return self.internetRouter.handle(request: request, from: client)
}
}
Devido à preservação da interface InternetRouter original na classe proxy InternetRouterProxy, basta substituir a classe de inicialização do InternerRouter pelo seu proxy, não sendo necessárias mais alterações na base de código.
O padrão de protótipo pertence ao grupo de padrões de projeto generativos. Digamos que estamos desenvolvendo aplicativos de namoro Tender De acordo com nosso modelo de negócio, temos a oportunidade paga de fazer cópias do seu próprio perfil, alterando automaticamente o nome e a ordem das fotos nos locais. Isso foi feito para que o usuário tivesse a oportunidade de manter vários perfis ao mesmo tempo com um conjunto diferente de amigos no aplicativo. Ao clicar no botão para criar uma cópia do perfil, precisamos implementar a cópia do perfil, gerar automaticamente um nome e reordenar as fotos. Implementação ingênua de pseudocódigo:
fun didPressOnCopyProfileButton() {
let profileCopy = new Profile()
profileCopy.name = generateRandomName()
profileCopy.age = profile.age
profileCopy.photos = profile.photos.randomize()
storage.save(profileCopy)
}
Agora vamos imaginar que outros membros da equipe copiaram e colaram o código de cópia ou o criaram do zero e, depois disso, um novo campo foi adicionado – gosta. Este campo armazena o número de curtidas do perfil, agora você precisa atualizar *todos* os locais onde a cópia ocorre manualmente adicionando um novo campo. É muito demorado e difícil manter o código, bem como testar. Para resolver este problema, o padrão de design Prototype foi inventado. Vamos criar um protocolo de cópia geral, com um método copy() que retorna uma cópia de um objeto com os campos necessários. Depois de alterar os campos da entidade, você só precisará atualizar um método copy(), em vez de pesquisar e atualizar manualmente todos os locais que contêm o código de cópia.
Neste artigo irei descrever o uso da máquina de estados (State Machine), mostrar uma implementação simples, uma implementação utilizando o padrão State. Vale ressaltar que não é desejável utilizar o padrão Estado se houver menos de três estados, pois isso geralmente leva a uma complexidade desnecessária na legibilidade do código e a problemas de suporte associados. tudo deve ser feito com moderação.
MEAACT PHOTO / STUART PRICE.
Senhor das Bandeiras
Suponha que estejamos desenvolvendo uma tela de player de vídeo para o sistema de mídia de uma aeronave civil, o player deve ser capaz de carregar um stream de vídeo, reproduzi-lo, permitir ao usuário interromper o processo de download, retroceder e realizar outras operações usuais para um jogador. Digamos que o player armazenou em cache o próximo pedaço do stream de vídeo, verificou se há pedaços suficientes para reprodução, começou a reproduzir o fragmento para o usuário e ao mesmo tempo continua baixando o próximo. Neste momento, o usuário retrocede até o meio do vídeo, ou seja, agora é necessário interromper a reprodução do fragmento atual e iniciar o carregamento a partir de uma nova posição. Porém, existem situações em que isso não pode ser feito – o usuário não pode controlar a reprodução do fluxo de vídeo enquanto está vendo um vídeo sobre segurança aérea. Vamos verificar o sinalizador isSafetyVideoPlaying para verificar esta situação. O sistema também deve ser capaz de pausar o vídeo atual e transmitir um alerta do capitão e da tripulação do navio através do player. Vamos adicionar outro sinalizador isAnnouncementPlaying. Além disso, há um requisito para não pausar a reprodução enquanto exibe ajuda sobre como trabalhar com o player. Outro sinalizador éHelpPresenting.
Pseudocódigo de exemplo do reprodutor de mídia:
class MediaPlayer {
public var isHelpPresenting = false
public var isCaching = false
public var isMediaPlaying: Bool = false
public var isAnnouncementPlaying = false
public var isSafetyVideoPlaying = false
public var currentMedia: Media = null
fun play(media: Media) {
if isMediaPlaying == false, isAnnouncementPlaying == false, isSafetyVideoPlaying == false {
if isCaching == false {
if isHelpPresenting == false {
media.playAfterHelpClosed()
}
else {
media.playAfterCaching()
}
}
}
fun pause() {
if isAnnouncementPlaying == false, isSafetyVideoPlaying == false {
currentMedia.pause()
}
}
}
O exemplo acima é difícil de ler e manter devido à alta variabilidade (entropia). Este exemplo é baseado em minha experiência trabalhando com a base de código de *muitos* projetos que não usavam uma máquina de estado. Cada checkbox deve “controlar” especificamente os elementos da interface e da lógica de negócio da aplicação, o desenvolvedor, adicionando outro checkbox, deve ser capaz de fazer malabarismos com eles, verificando e verificando tudo várias vezes com todas as opções possíveis. Substituindo na fórmula “2 ^ número de caixas de seleção” você pode obter 2 ^ 6 = 64 opções de comportamento do aplicativo para apenas 6 caixas de seleção, todas essas combinações de caixas de seleção precisarão ser marcadas e mantidas manualmente. Do lado do desenvolvedor, adicionar novas funcionalidades a esse sistema é assim: – Precisamos adicionar a capacidade de mostrar a página do navegador da companhia aérea, e isso deve minimizar a semelhança com os filmes se os membros da tripulação anunciarem algo. – Ok, eu farei isso. (Ah, droga, terei que adicionar outra bandeira e verificar novamente todos os locais onde as bandeiras se cruzam, há muitas coisas que precisam ser alteradas!)
Também é um ponto fraco do sistema de bandeiras – fazer alterações no comportamento do aplicativo. É muito difícil imaginar como alterar o comportamento de forma rápida/flexível com base em sinalizadores, se depois de alterar apenas um sinalizador você tiver que verificar tudo novamente. Esta abordagem ao desenvolvimento leva a muitos problemas, perda de tempo e dinheiro.
Entre na máquina
Se você observar atentamente os sinalizadores, poderá entender que, na verdade, estamos tentando processar processos específicos que ocorrem no mundo real. Nós os listamos: modo normal, exibição de vídeo de segurança, transmissão de mensagem do capitão ou tripulantes. Para cada processo é conhecido um conjunto de regras que alteram o comportamento da aplicação. De acordo com as regras do padrão de máquina de estado (máquina de estado), listaremos todos os processos como estados no enum, adicionaremos um conceito como estado ao código do jogador, implementaremos comportamento baseado em estado removendo combinações nos sinalizadores. Assim, reduziremos as opções de testes exatamente ao número de estados.
Pseudocódigo:
enum MediaPlayerState {
mediaPlaying,
mediaCaching,
crewSpeaking,
safetyVideoPlaying,
presentingHelp
}
class MediaPlayer {
fun play(media: Media) {
media.play()
}
func pause() {
media.pause()
}
}
class MediaPlayerStateMachine {
public state: MediaPlayerState
public mediaPlayer: MediaPlayer
public currentMedia: Media
//.. init (mediaPlayer) etc
public fun set(state: MediaPlayerState) {
switch state {
case mediaPlaying:
mediaPlayer.play(currentMedia)
case mediaCaching, crewSpeaking,
safetyVideoPlaying, presentingHelp:
mediaPlayer.pause()
}
}
}
A grande diferença entre um sistema de sinalizadores e uma máquina de estado é o funil lógico de comutação de estado no método set(state: ..), que permite traduzir a compreensão humana do estado em código de programa, sem ter que jogar lógica jogos de conversão de bandeiras em estados quando houver suporte adicional ao código.
Estado do padrão
A seguir mostrarei a diferença entre a implementação ingênua da máquina de estados e o padrão de estados. Vamos imaginar que precisávamos adicionar 10 estados; como resultado, a classe da máquina de estados crescerá até o tamanho de um objeto divino, o que será difícil e caro de manter. Claro, esta implementação é melhor do que a implementação de flag (com o sistema de flag, o desenvolvedor irá atirar em si mesmo primeiro, e se não, então vendo 2 ^ 10 = 1024 variações, o QA se enforcará, mas se ambos *não notar* a complexidade da tarefa, então o usuário cuja aplicação é simples perceberá que se recusará a trabalhar com uma determinada combinação de flags) Se houver um grande número de estados, é necessário utilizar o padrão State. Vamos adicionar um conjunto de regras ao protocolo do Estado:
Vamos mover a implementação do conjunto de regras para estados separados, por exemplo, o código para um estado:
class CrewSpeakingState: State {
func playMedia(context: MediaPlayerContext) {
showWarning(“Can’ t play media - listen to announce!”)
}
func mediaCaching(context: MediaPlayerContext) {
showActivityIndicator()
}
func crewSpeaking(context: MediaPlayerContext) {
set(volume: 100)
}
func safetyVideoPlaying(context: MediaPlayerContext) {
set(volume: 100)
}
func presentHelp(context: MediaPlayerContext) {
showWarning(“Can’ t present help - listen to announce!”)
}
}
A seguir, vamos criar um contexto com o qual cada estado funcionará e integrar a máquina de estados:
final class MediaPlayerContext {
private
var state: State
public fun set(state: State) {
self.state = state
}
public fun play(media: Media) {
state.play(media: media, context: this)
}
…
остальные возможные события
}
Os componentes da aplicação trabalham com o contexto através de métodos públicos; os próprios objetos de estado decidem de qual estado fazer a transição usando a máquina de estado dentro do contexto. Assim, implementamos a decomposição do Objeto Deus, manter um estado de mudança será muito mais fácil, graças ao compilador rastreando as alterações no protocolo, reduzindo a complexidade de compreensão dos estados devido à redução no número de linhas de código, e focando em resolver um problema de estado específico. Agora você também pode compartilhar o trabalho em equipe, entregando a implementação de um estado específico aos membros da equipe, sem se preocupar com a necessidade de “resolver” conflitos, o que acontece quando se trabalha com uma grande classe de máquina de estado.
Neste artigo descreverei minha compreensão da animação esquelética, que é usada em todos os motores 3D modernos para animar personagens, ambientes de jogos, etc. Começarei a descrição com a parte mais tangível – sombreador de vértice, pois todo o caminho de cálculo, por mais complexo que seja, termina com a transferência dos dados preparados para exibição para o sombreador de vértice.
A animação do esqueleto, após ser processada na CPU, vai para o vertex shader. Deixe-me lembrá-lo da fórmula para vértice sem animação esquelética: gl_Position = projeçãoMatrix * viewMatrix * modelMatrix * vértice; Para quem não entende como surgiu essa fórmula, pode ler meu artigo que descreve o princípio de trabalhar com matrizes para exibição de conteúdo 3D no contexto do OpenGL. Quanto ao resto – fórmula para implementar animação esquelética: ” vec4 animadoVertex = bone0matrix * vértice * bone0weight +” “bone1matrix * vértice * bone1weight +” “bone2matrix * vértice * bone2weight +” “bone3matrix * vértice * bone3weight;\n” ” gl_Position = projeçãoMatrix * viewMatrix * modelMatrix * animadoVertex;\n”
Ou seja, multiplicamos a matriz de transformação óssea final pelo vértice e pelo peso desta matriz em relação ao vértice. Cada vértice pode ser animado por 4 ossos, a força do impacto é regulada pelo parâmetro peso do osso, a soma dos impactos deve ser igual a um. O que fazer se menos de 4 ossos afetarem o vértice? Precisamos dividir o peso entre eles e fazer com que o impacto do restante seja igual a zero. Matematicamente, multiplicar um peso por uma matriz é chamado de “multiplicação escalar de matriz”. Multiplicar por um escalar permite resumir o efeito das matrizes no vértice resultante.
As próprias matrizes de transformação óssea são transmitidas como uma matriz. Além disso, a matriz contém matrizes para todo o modelo como um todo, e não para cada malha separadamente.
Mas para cada vértice as seguintes informações são transmitidas separadamente: – Índice da matriz que afeta o vértice – Peso da matriz que afeta o vértice Mais de um osso é transmitido, geralmente é utilizado o efeito de 4 ossos no vértice. Além disso, a soma dos pesos dos 4 dados deve ser sempre igual a um. A seguir, vamos ver como fica no shader. Matriz matricial: “bonesMatrices mat4 uniformes[kMaxBones];”
Informações sobre o efeito de 4 ossos em cada vértice: “atributo vec2 bone0info;” “atributo vec2 bone1info;” “atributo vec2 bone2info;” “atributo vec2 bone3info;”
vec2 – na coordenada X armazenamos o índice do osso (e convertemos para int no shader), na coordenada Y armazenamos o peso do impacto do osso no vértice. Por que você tem que transmitir esses dados em um vetor bidimensional? Porque o GLSL não suporta a passagem de estruturas legíveis em C com campos válidos para o shader.
A seguir darei um exemplo de obtenção das informações necessárias de um vetor para posterior substituição na fórmula animadoVertex:
Agora a estrutura de vértices preenchida na CPU deve ficar assim: x, y, z, u, v, bone0index, bone0weight, bone1index, bone1weight, bone2index, bone2weight, bone3index, bone3weight
A estrutura do buffer de vértice é preenchida uma vez durante o carregamento do modelo, mas as matrizes de transformação são transferidas da CPU para o shader em cada quadro de renderização.
Nas partes restantes, descreverei o princípio de cálculo da animação na CPU, antes de transferi-la para o vertex shader, descreverei a árvore de nós ósseos, percorrendo a hierarquia de animação-modelo-nós-malha, matriz interpolação.
O método padrão refere-se a padrões de design comportamentais. O padrão descreve uma maneira de substituir parte da lógica de uma classe sob demanda, deixando a parte geral inalterada para os descendentes.
Suponha que estejamos desenvolvendo um banco cliente, considere a tarefa de desenvolver um módulo de autorização – o usuário deve ser capaz de fazer login no aplicativo usando dados de login abstratos. O módulo de autorização deve ser multiplataforma, suportando diferentes tecnologias de autorização e armazenando dados criptografados de diferentes plataformas. Para implementar o módulo, escolhemos a linguagem Kotlin multiplataforma, usando a classe abstrata (protocolo) do módulo de autorização, escreveremos uma implementação para o telefone MyPhone:
class MyPhoneSuperDuperSecretMyPhoneAuthorizationStorage {
fun loginAndPassword() : Pair {
return Pair("admin", "qwerty65435")
}
}
class ServerApiClient {
fun authorize(authorizationData: AuthorizationData) : Unit {
println(authorizationData.login)
println(authorizationData.password)
println("Authorized")
}
}
class AuthorizationData {
var login: String? = null
var password: String? = null
}
interface AuthorizationModule {
abstract fun fetchAuthorizationData() : AuthorizationData
abstract fun authorize(authorizationData: AuthorizationData)
}
class MyPhoneAuthorizationModule: AuthorizationModule {
override fun fetchAuthorizationData() : AuthorizationData {
val loginAndPassword = MyPhoneSuperDuperSecretMyPhoneAuthorizationStorage().loginAndPassword()
val authorizationData = AuthorizationData()
authorizationData.login = loginAndPassword.first
authorizationData.password = loginAndPassword.second
return authorizationData
}
override fun authorize(authorizationData: AuthorizationData) {
ServerApiClient().authorize(authorizationData)
}
}
fun main() {
val authorizationModule = MyPhoneAuthorizationModule()
val authorizationData = authorizationModule.fetchAuthorizationData()
authorizationModule.authorize(authorizationData)
}
Agora para cada telefone/plataforma teremos que duplicar o código de envio de autorização ao servidor, isso é uma violação do princípio DRY. O exemplo acima é muito simples, em classes mais complexas haverá ainda mais duplicação. Para eliminar a duplicação de código, você deve usar o padrão Template Method. Vamos mover as partes comuns do módulo para métodos imutáveis e transferir a funcionalidade de transferência de dados criptografados para classes de plataforma específicas:
class MyPhoneSuperDuperSecretMyPhoneAuthorizationStorage {
fun loginAndPassword() : Pair {
return Pair("admin", "qwerty65435")
}
}
class ServerApiClient {
fun authorize(authorizationData: AuthorizationData) : Unit {
println(authorizationData.login)
println(authorizationData.password)
println("Authorized")
}
}
class AuthorizationData {
var login: String? = null
var password: String? = null
}
interface AuthorizationModule {
abstract fun fetchAuthorizationData() : AuthorizationData
fun authorize(authorizationData: AuthorizationData) {
ServerApiClient().authorize(authorizationData)
}
}
class MyPhoneAuthorizationModule: AuthorizationModule {
override fun fetchAuthorizationData() : AuthorizationData {
val loginAndPassword = MyPhoneSuperDuperSecretMyPhoneAuthorizationStorage().loginAndPassword()
val authorizationData = AuthorizationData()
authorizationData.login = loginAndPassword.first
authorizationData.password = loginAndPassword.second
return authorizationData
}
}
fun main() {
val authorizationModule = MyPhoneAuthorizationModule()
val authorizationData = authorizationModule.fetchAuthorizationData()
authorizationModule.authorize(authorizationData)
}
O padrão Bridge refere-se a padrões de projeto estrutural. Ele permite abstrair a implementação da lógica de classe movendo a lógica para uma classe abstrata separada. Parece simples, certo?
Suponha que implementemos um bot de spam que seja capaz de enviar mensagens para diferentes tipos de mensageiros. Nós o implementamos usando um protocolo comum:
protocol User {
let token: String
let username: String
}
protocol Messenger {
var authorize(login: String, password: String)
var send(message: String, to user: User)
}
class iSeekUUser: User {
let token: String
let username: String
}
class iSeekU: Messenger {
var authorizedUser: User?
var requestSender: RequestSender?
var requestFactory: RequestFactory?
func authorize(login: String, password: String) {
authorizedUser = requestSender?.perform(requestFactory.loginRequest(login: login, password: password))
}
func send(message: String, to user: User) {
requestSender?.perform(requestFactory.messageRequest(message: message, to: user)
}
}
class SpamBot {
func start(usersList: [User]) {
let iSeekUMessenger = iSeekU()
iSeekUMessenger.authorize(login: "SpamBot", password: "SpamPassword")
for user in usersList {
iSeekUMessennger.send(message: "Hey checkout demensdeum blog! http://demensdeum.com", to: user)
}
}
}
Agora vamos imaginar o lançamento de um protocolo novo e mais rápido para envio de mensagens para o mensageiro iSekU. Para adicionar um novo protocolo, você precisará duplicar a implementação do bot iSekU, alterando apenas uma pequena parte dele. Não está claro por que fazer isso se apenas uma pequena parte da lógica da classe mudou. Com esta abordagem, o princípio DRY é violado; com o desenvolvimento do produto, a falta de flexibilidade se fará sentir através de erros e atrasos na implementação de novos recursos. Vamos mover a lógica do protocolo para uma classe abstrata, implementando assim o padrão Bridge:
protocol User {
let token: String
let username: String
}
protocol Messenger {
var authorize(login: String, password: String)
var send(message: String, to user: User)
}
protocol MessagesSender {
func send(message: String, to user: User)
}
class iSeekUUser: User {
let token: String
let username: String
}
class iSeekUFastMessengerSender: MessagesSender {
func send(message: String, to user: User) {
requestSender?.perform(requestFactory.messageRequest(message: message, to: user)
}
}
class iSeekU: Messenger {
var authorizedUser: User?
var requestSender: RequestSender?
var requestFactory: RequestFactory?
var messagesSender: MessengerMessagesSender?
func authorize(login: String, password: String) {
authorizedUser = requestSender?.perform(requestFactory.loginRequest(login: login, password: password))
}
func send(message: String, to user: User) {
messagesSender?.send(message: message, to: user)
}
}
class SpamBot {
var messagesSender: MessagesSender?
func start(usersList: [User]) {
let iSeekUMessenger = iSeekU()
iSeekUMessenger.authorize(login: "SpamBot", password: "SpamPassword")
for user in usersList {
messagesSender.send(message: "Hey checkout demensdeum blog! http://demensdeum.com", to: user)
}
}
}
Uma das vantagens desta abordagem é, sem dúvida, a capacidade de expandir a funcionalidade da aplicação escrevendo plugins/bibliotecas que implementam lógica abstraída sem alterar o código da aplicação principal. Qual é a diferença com o padrão Estratégia? Ambos os padrões são muito semelhantes, no entanto, Estratégia descreve *algoritmos* de comutação, enquanto Bridge permite alternar grandes partes de *qualquer lógica complexa*.
A produtora Jah-Pictures fez um documentário sobre rastafáris comunistas da Libéria chamado “Red Dawn of Marley”. O filme é muito longo (8 horas), interessante, mas antes de ser lançado descobriu-se que em alguns países os planos e frases do filme podem ser considerados heresia e não receberão licença de distribuição. Os produtores do filme decidem recortar do filme momentos que contenham frases duvidosas, de forma manual e automática. É necessária uma dupla verificação para que os representantes do distribuidor não sejam simplesmente fuzilados em alguns países em caso de erro durante a inspeção e instalação manual. Os países estão divididos em quatro grupos – países sem censura, com censura moderada, média e muito rigorosa. É tomada a decisão de usar redes neurais para classificar o nível de heresia no fragmento assistido do filme. Para o projeto, são adquiridos neurônios de última geração, caríssimos, treinados para diferentes níveis de censura, tarefa do desenvolvedor – tarefa do desenvolvedor. quebrar o filme em fragmentos e transmiti-los através de uma cadeia de redes neurais, de livre a estrita, até que uma delas detecte heresia, então o fragmento é transferido para revisão manual para posterior edição. É impossível passar por todos os neurônios, porque seu trabalho exige muito poder de computação (afinal, ainda temos que pagar pela eletricidade), basta parar no primeiro que funcionar. Implementação ingênua de pseudocódigo:
import StateOfArtCensorshipHLNNClassifiers
protocol MovieCensorshipClassifier {
func shouldBeCensored(movieChunk: MovieChunk) -> Bool
}
class CensorshipClassifier: MovieCensorshipClassifier {
let hnnclassifier: StateOfArtCensorshipHLNNClassifier
init(_ hnnclassifier: StateOfArtCensorshipHLNNClassifier) {
self.hnnclassifier = hnnclassifier
}
func shouldBeCensored(_ movieChunk: MovieChunk) -> Bool {
return hnnclassifier.shouldBeCensored(movieChunk)
}
}
let lightCensorshipClassifier = CensorshipClassifier(StateOfArtCensorshipHLNNClassifier("light"))
let normalCensorshipClassifier = CensorshipClassifier(StateOfArtCensorshipHLNNClassifier("normal"))
let hardCensorshipClassifier = CensorshipClassifier(StateOfArtCensorshipHLNNClassifier("hard"))
let classifiers = [lightCensorshipClassifier, normalCensorshipClassifier, hardCensorshipClassifier]
let movie = Movie("Red Jah rising")
for chunk in movie.chunks {
for classifier in classifiers {
if classifier.shouldBeCensored(chunk) == true {
print("Should censor movie chunk: \(chunk), reported by \(classifier)")
}
}
}
Em geral, a solução com um array de classificadores não é tão ruim, porém! Vamos imaginar que não podemos criar um array, temos a oportunidade de criar apenas uma entidade classificadora, que já determina o tipo de censura para um fragmento de filme. Tais restrições são possíveis ao desenvolver uma biblioteca que expanda a funcionalidade da aplicação (plugin). Vamos usar o padrão decorador – Vamos adicionar uma referência ao próximo classificador da cadeia à classe do classificador e interromper o processo de verificação na primeira classificação bem-sucedida. Assim, implementamos o padrão Cadeia de Responsabilidade:
import StateOfArtCensorshipHLNNClassifiers
protocol MovieCensorshipClassifier {
func shouldBeCensored(movieChunk: MovieChunk) -> Bool
}
class CensorshipClassifier: MovieCensorshipClassifier {
let nextClassifier: CensorshipClassifier?
let hnnclassifier: StateOfArtCensorshipHLNNClassifier
init(_ hnnclassifier: StateOfArtCensorshipHLNNClassifier, nextClassifier: CensorshipClassifiers?) {
self.nextClassifier = nextClassifier
self.hnnclassifier = hnnclassifier
}
func shouldBeCensored(_ movieChunk: MovieChunk) -> Bool {
let result = hnnclassifier.shouldBeCensored(movieChunk)
print("Should censor movie chunk: \(movieChunk), reported by \(self)")
if result == true {
return true
}
else {
return nextClassifier?.shouldBeCensored(movieChunk) ?? false
}
}
}
let censorshipClassifier = CensorshipClassifier(StateOfArtCensorshipHLNNClassifier("light"), nextClassifier: CensorshipClassifier(StateOfArtCensorshipHLNNClassifier("normal", nextClassifier: CensorshipClassifier(StateOfArtCensorshipHLNNClassifier("hard")))))
let movie = Movie("Red Jah rising")
for chunk in movie.chunks {
censorshipClassifier.shouldBeCensored(chunk)
}
O padrão Decorator refere-se a padrões de projeto estrutural.
O decorador é usado como alternativa à herança para estender a funcionalidade das classes. Existe a tarefa de expandir a funcionalidade do aplicativo dependendo do tipo de produto. O cliente exige três tipos de produto – Básico, Profissional, Final. Básico– conta o número de caracteres, Profissional – recursos Basic + imprime texto em letras maiúsculas, Ultimate – Básico + Profissional + imprime texto dizendo ULTIMATE. Nós o implementamos usando herança:
protocol Feature {
func textOperation(text: String)
}
class BasicVersionFeature: Feature {
func textOperation(text: String) {
print("\(text.count)")
}
}
class ProfessionalVersionFeature: BasicVersionFeature {
override func textOperation(text: String) {
super.textOperation(text: text)
print("\(text.uppercased())")
}
}
class UltimateVersionFeature: ProfessionalVersionFeature {
override func textOperation(text: String) {
super.textOperation(text: text)
print("ULTIMATE: \(text)")
}
}
let textToFormat = "Hello Decorator"
let basicProduct = BasicVersionFeature()
basicProduct.textOperation(text: textToFormat)
let professionalProduct = ProfessionalVersionFeature()
professionalProduct.textOperation(text: textToFormat)
let ultimateProduct = UltimateVersionFeature()
ultimateProduct.textOperation(text: textToFormat)
Agora existe a necessidade de implementação do produto “Ultimate Light” – Basic + Ultimate, mas sem os recursos da versão Professional. O primeiro OH! acontece, porque… você terá que criar uma classe separada para uma tarefa tão simples e duplicar o código. Vamos continuar a implementação usando herança:
O exemplo pode ser desenvolvido para maior clareza, mas mesmo agora a complexidade de suportar um sistema baseado em uma base de herança é visível – complicado e falta de flexibilidade. Um decorador é um conjunto de protocolos que descreve a funcionalidade, uma classe abstrata contendo uma referência a uma instância concreta filha da classe decoradora que estende a funcionalidade. Vamos reescrever o exemplo acima usando o padrão:
Agora podemos criar variações de qualquer tipo de produto – basta inicializar os tipos combinados na fase de inicialização do aplicativo; o exemplo abaixo é a criação da versão Ultimate + Professional:
O padrão Mediador refere-se a padrões de design comportamentais.
Um dia você recebe um pedido para desenvolver um aplicativo de piadas – um aplicativo de piadas. o usuário pressiona um botão no meio da tela e ouve-se um som engraçado de um pato grasnando. Depois de fazer o upload para a app store, o aplicativo se torna um sucesso: todo mundo grasna seu aplicativo, Elon Musk grasna em seu Instagram no próximo lançamento de um túnel de altíssima velocidade em Marte, Hillary Clinton supera Donald Trump no debate e vence as eleições na Ucrânia, sucesso! A implementação ingênua do aplicativo é assim:
class DuckButton {
func didPress() {
print("quack!")
}
}
let duckButton = DuckButton()
duckButton.didPress()
Em seguida você decide adicionar o som de um cachorro latindo, para isso você precisa mostrar dois botões para selecionar o som – com um pato e um cachorro. Vamos criar duas classes de botões: DuckButton e DogButton. Altere o código:
class DuckButton {
func didPress() {
print("quack!")
}
}
class DogButton {
func didPress() {
print("bark!")
}
}
let duckButton = DuckButton()
duckButton.didPress()
let dogButton = DogButton()
dogButton.didPress()
Depois de mais um sucesso, adicionamos o som do guincho de um porco, agora existem três classes de botões:
class DuckButton {
func didPress() {
print("quack!")
}
}
class DogButton {
func didPress() {
print("bark!")
}
}
class PigButton {
func didPress() {
print("oink!")
}
}
let duckButton = DuckButton()
duckButton.didPress()
let dogButton = DogButton()
dogButton.didPress()
let pigButton = PigButton()
pigButton.didPress()
Os usuários reclamam que os sons se sobrepõem. Adicionamos uma verificação para evitar que isso aconteça e, ao mesmo tempo, apresentamos as classes umas às outras:
class DuckButton {
var isMakingSound = false
var dogButton: DogButton?
var pigButton: PigButton?
func didPress() {
guard dogButton?.isMakingSound ?? false == false &&
pigButton?.isMakingSound ?? false == false else { return }
isMakingSound = true
print("quack!")
isMakingSound = false
}
}
class DogButton {
var isMakingSound = false
var duckButton: DuckButton?
var pigButton: PigButton?
func didPress() {
guard duckButton?.isMakingSound ?? false == false &&
pigButton?.isMakingSound ?? false == false else { return }
isMakingSound = true
print("bark!")
isMakingSound = false
}
}
class PigButton {
var isMakingSound = false
var duckButton: DuckButton?
var dogButton: DogButton?
func didPress() {
guard duckButton?.isMakingSound ?? false == false &&
dogButton?.isMakingSound ?? false == false else { return }
isMakingSound = true
print("oink!")
isMakingSound = false
}
}
let duckButton = DuckButton()
duckButton.didPress()
let dogButton = DogButton()
dogButton.didPress()
let pigButton = PigButton()
pigButton.didPress()
Na esteira do sucesso de seu aplicativo, o governo decide fazer uma lei segundo a qual charlatões, latidos e grunhidos em dispositivos móveis só podem ser feitos das 9h às 15h nos demais dias de semana; Nesse momento, o usuário do seu aplicativo corre o risco de ser preso por 5 anos por produção de som obsceno usando dispositivos eletrônicos pessoais. Altere o código:
import Foundation
extension Date {
func mobileDeviceAllowedSoundTime() -> Bool {
let hour = Calendar.current.component(.hour, from: self)
let weekend = Calendar.current.isDateInWeekend(self)
let result = hour >= 9 && hour <= 14 && weekend == false
return result
}
}
class DuckButton {
var isMakingSound = false
var dogButton: DogButton?
var pigButton: PigButton?
func didPress() {
guard dogButton?.isMakingSound ?? false == false &&
pigButton?.isMakingSound ?? false == false &&
Date().mobileDeviceAllowedSoundTime() == true else { return }
isMakingSound = true
print("quack!")
isMakingSound = false
}
}
class DogButton {
var isMakingSound = false
var duckButton: DuckButton?
var pigButton: PigButton?
func didPress() {
guard duckButton?.isMakingSound ?? false == false &&
pigButton?.isMakingSound ?? false == false &&
Date().mobileDeviceAllowedSoundTime() == true else { return }
isMakingSound = true
print("bark!")
isMakingSound = false
}
}
class PigButton {
var isMakingSound = false
var duckButton: DuckButton?
var dogButton: DogButton?
func didPress() {
guard duckButton?.isMakingSound ?? false == false &&
dogButton?.isMakingSound ?? false == false &&
Date().mobileDeviceAllowedSoundTime() == true else { return }
isMakingSound = true
print("oink!")
isMakingSound = false
}
}
let duckButton = DuckButton()
let dogButton = DogButton()
let pigButton = PigButton()
duckButton.dogButton = dogButton
duckButton.pigButton = pigButton
dogButton.duckButton = duckButton
dogButton.pigButton = pigButton
pigButton.duckButton = duckButton
pigButton.dogButton = dogButton
duckButton.didPress()
dogButton.didPress()
pigButton.didPress()
De repente, o aplicativo lanterna começa a tirar o nosso do mercado, não vamos deixar que ele nos derrote e adicione uma lanterna pressionando o botão “oink-oink” e o restante dos botões:
import Foundation
extension Date {
func mobileDeviceAllowedSoundTime() -> Bool {
let hour = Calendar.current.component(.hour, from: self)
let weekend = Calendar.current.isDateInWeekend(self)
let result = hour >= 9 && hour <= 14 && weekend == false
return result
}
}
class Flashlight {
var isOn = false
func turn(on: Bool) {
isOn = on
}
}
class DuckButton {
var isMakingSound = false
var dogButton: DogButton?
var pigButton: PigButton?
var flashlight: Flashlight?
func didPress() {
flashlight?.turn(on: true)
guard dogButton?.isMakingSound ?? false == false &&
pigButton?.isMakingSound ?? false == false &&
Date().mobileDeviceAllowedSoundTime() == true else { return }
isMakingSound = true
print("quack!")
isMakingSound = false
}
}
class DogButton {
var isMakingSound = false
var duckButton: DuckButton?
var pigButton: PigButton?
var flashlight: Flashlight?
func didPress() {
flashlight?.turn(on: true)
guard duckButton?.isMakingSound ?? false == false &&
pigButton?.isMakingSound ?? false == false &&
Date().mobileDeviceAllowedSoundTime() == true else { return }
isMakingSound = true
print("bark!")
isMakingSound = false
}
}
class PigButton {
var isMakingSound = false
var duckButton: DuckButton?
var dogButton: DogButton?
var flashlight: Flashlight?
func didPress() {
flashlight?.turn(on: true)
guard duckButton?.isMakingSound ?? false == false &&
dogButton?.isMakingSound ?? false == false &&
Date().mobileDeviceAllowedSoundTime() == true else { return }
isMakingSound = true
print("oink!")
isMakingSound = false
}
}
let flashlight = Flashlight()
let duckButton = DuckButton()
let dogButton = DogButton()
let pigButton = PigButton()
duckButton.dogButton = dogButton
duckButton.pigButton = pigButton
duckButton.flashlight = flashlight
dogButton.duckButton = duckButton
dogButton.pigButton = pigButton
dogButton.flashlight = flashlight
pigButton.duckButton = duckButton
pigButton.dogButton = dogButton
pigButton.flashlight = flashlight
duckButton.didPress()
dogButton.didPress()
pigButton.didPress()
Como resultado, temos um aplicativo enorme que contém muito código de copiar e colar, as classes internas são conectadas entre si por um link morto - não há acoplamento fraco, tal milagre é muito difícil de manter e mudança no futuro devido às grandes chances de cometer um erro.
Use o Mediador
Vamos adicionar uma classe mediadora intermediária - ApplicationController. Esta classe fornecerá baixo acoplamento de objetos, garantirá a separação de responsabilidades entre classes e eliminará código duplicado. Vamos reescrever:
import Foundation
class ApplicationController {
private var isMakingSound = false
private let flashlight = Flashlight()
private var soundButtons: [SoundButton] = []
func add(soundButton: SoundButton) {
soundButtons.append(soundButton)
}
func didPress(soundButton: SoundButton) {
flashlight.turn(on: true)
guard Date().mobileDeviceAllowedSoundTime() &&
isMakingSound == false else { return }
isMakingSound = true
soundButton.didPress()
isMakingSound = false
}
}
class SoundButton {
let soundText: String
init(soundText: String) {
self.soundText = soundText
}
func didPress() {
print(soundText)
}
}
class Flashlight {
var isOn = false
func turn(on: Bool) {
isOn = on
}
}
extension Date {
func mobileDeviceAllowedSoundTime() -> Bool {
let hour = Calendar.current.component(.hour, from: self)
let weekend = Calendar.current.isDateInWeekend(self)
let result = hour >= 9 && hour <= 14 && weekend == false
return result
}
}
let applicationController = ApplicationController()
let pigButton = SoundButton(soundText: "oink!")
let dogButton = SoundButton(soundText: "bark!")
let duckButton = SoundButton(soundText: "quack!")
applicationController.add(soundButton: pigButton)
applicationController.add(soundButton: dogButton)
applicationController.add(soundButton: duckButton)
pigButton.didPress()
dogButton.didPress()
duckButton.didPress()
Muitos artigos sobre arquiteturas de aplicativos de interface de usuário descrevem o padrão MVC e seus derivados. O modelo é utilizado para trabalhar com dados lógicos de negócio, a visualização ou representação mostra informações ao usuário na interface/fornece interação com o usuário, o controlador é um mediador que garante a interação dos componentes do sistema.
The Strategy pattern allows you to select the type of algorithm that implements a common interface, right while the application is running. This pattern refers to the behavioral design patterns.
Suppose we are developing a music player with embedded codecs. The built-in codecs imply reading music formats without using external sources of the operating system (codecs), the player should be able to read tracks of different formats and play them. VLC player has such capabilities, it supports various types of video and audio formats, it runs on popular and not very operating systems.
Imagine what a naive player implementation looks like:
var player: MusicPlayer?
func play(filePath: String) {
let extension = filePath.pathExtension
if extension == "mp3" {
playMp3(filePath)
}
elseif extension == "ogg" {
playOgg(filePath)
}
}
func playMp3(_ filePath: String) {
player = MpegPlayer()
player?.playMp3(filePath)
}
func playOgg(_ filePath: String) {
player = VorbisPlayer()
player?.playMusic(filePath)
}
Next, we add several formats, which leads to the need to write additional methods.Plus, the player must support plug-in libraries, with new audio formats that will appear later.There is a need to switch the music playback algorithm, the Strategy pattern is used to solve this problem.
Let’s create a common protocol MusicPlayerCodecAlgorithm, write the implementation of the protocol in two classes MpegMusicPlayerCodecAlgorithm and VorbisMusicPlayerCodecAlgorithm, to play mp3 and ogg files with-but.Create a class MusicPlayer, which will contain a reference for the algorithm that needs to be switched, then by the file extension we implement codec type switching:
The above example also shows the simplest example of a factory (switching the codec type from the file extension) It is important to note that the Strategy strategy does not create objects, it only describes how to create a common interface for switching the family of algorithms.
In this article I will describe the Iterator pattern.
This pattern refers to the behavioral design patterns.
Print it
Suppose we need to print a list of tracks from the album “Procrastinate them all” of the group “Procrastinallica”.
The naive implementation (Swift) looks like this:
for i=0; i < tracks.count; i++ {
print(tracks[i].title)
}
Suddenly during compilation, it is detected that the class of the tracks object does not give the number of tracks in the count call, and moreover, its elements cannot be accessed by index. Oh…
Filter it
Suppose we are writing an article for the magazine “Wacky Hammer”, we need a list of tracks of the group “Djentuggah” in which bpm exceeds 140 beats per minute. An interesting feature of this group is that its records are stored in a huge collection of underground groups, not sorted by albums, or for any other grounds. Let’s imagine that we work with a language without functionality:
var djentuggahFastTracks = [Track]()
for track in undergroundCollectionTracks {
if track.band.title == "Djentuggah" && track.info.bpm == 140 {
djentuggahFastTracks.append(track)
}
}
Suddenly, a couple of tracks of the group are found in the collection of digitized tapes, and the editor of the magazine suggests finding tracks in this collection and writing about them. A Data Scientist friend suggests to use the Djentuggah track classification algorithm, so you don’t need to listen to a collection of 200 thousand tapes manually. Try:
var djentuggahFastTracks = [Track]()
for track in undergroundCollectionTracks {
if track.band.title == "Djentuggah" && track.info.bpm == 140 {
djentuggahFastTracks.append(track)
}
}
let tracksClassifier = TracksClassifier()
let bpmClassifier = BPMClassifier()
for track in cassetsTracks {
if tracksClassifier.classify(track).band.title == "Djentuggah" && bpmClassifier.classify(track).bpm == 140 {
djentuggahFastTracks.append(track)
}
}
Mistakes
Now, just before sending to print, the editor reports that 140 beats per minute are out of fashion, people are more interested in 160, so the article should be rewritten by adding the necessary tracks.
Apply changes:
var djentuggahFastTracks = [Track]()
for track in undergroundCollectionTracks {
if track.band.title == "Djentuggah" && track.info.bpm == 160 {
djentuggahFastTracks.append(track)
}
}
let tracksClassifier = TracksClassifier()
let bpmClassifier = BPMClassifier()
for track in cassetsTracks {
if tracksClassifier.classify(track).band.title == "Djentuggah" && bpmClassifier.classify(track).bpm == 140 {
djentuggahFastTracks.append(track)
}
}
The most attentive ones noticed an error; the bpm parameter was changed only for the first pass through the list. If there were more passes through the collections, then the chance of a mistake would be higher, that is why the DRY principle should be used. The above example can be developed further, for example, by adding the condition that you need to find several groups with different bpm, by the names of vocalists, guitarists, this will increase the chance of error due to duplication of code.
Behold the Iterator!
In the literature, an iterator is described as a combination of two protocols / interfaces, the first is an iterator interface consisting of two methods – next(), hasNext(), next() returns an object from the collection, and hasNext() reports that there is an object and the list is not over. However in practice, I observed iterators with one method – next(), when the list ended, null was returned from this object. The second is a collection that should have an interface that provides an iterator – the iterator() method, there are variations with the collection interface that returns an iterator in the initial position and in end – the begin() and end() methods are used in C ++ std.
Using the iterator in the example above will remove duplicate code, eliminate the chance of mistake due to duplicate filtering conditions. It will also be easier to work with the collection of tracks on a single interface – if you change the internal structure of the collection, the interface will remain old and the external code will not be affected.
Wow!
let bandFilter = Filter(key: "band", value: "Djentuggah")
let bpmFilter = Filter(key: "bpm", value: 140)
let iterator = tracksCollection.filterableIterator(filters: [bandFilter, bpmFilter])
while let track = iterator.next() {
print("\(track.band) - \(track.title)")
}
Changes
While the iterator is running, the collection may change, thus causing the iterator’s internal counter to be invalid, and generally breaking such a thing as “next object”. Many frameworks contain a check for changing the state of the collection, and in case of changes they return an error / exception. Some implementations allow you to remove objects from the collection while the iterator is running, by providing the remove() method in the iterator.
Neste post irei descrever o padrão “Snapshot” ou “Memento”
Este padrão refere-se a padrões “Comportamentais” padrões de design.
Suponha que estamos desenvolvendo um editor gráfico e precisamos adicionar a capacidade de reverter ações mediante um comando do usuário. Também é muito importante que os componentes do sistema não tenham acesso ao estado interno das “ações” seu estado interno, fornecendo uma interface externa clara e simples. Para resolver este problema, o padrão “Snapshot” ou “Guardião”.
Exemplo de trabalho “Instantâneo” apresentado abaixo:
Ao clicar, um sprite aparece, ao clicar na seta enrolada, a ação é cancelada – O sprite desaparece. O exemplo consiste em três classes:
Tela na qual os sprites e a interface gráfica são exibidos.
Controlador de tela, processa cliques e controla a lógica da tela.
Os estados da tela que persistem a cada alteração são revertidos, se necessário, usando o controlador de tela.
No contexto do padrão “Snapshot” as aulas são:
Tela – fonte, os estados desta classe são salvos como “instantâneos”, para reversão posterior mediante solicitação. Além disso, a fonte deve ser capaz de restaurar o estado ao transferir um “instantâneo”
Controlador – custodiante, esta classe sabe como e quando salvar/reverter estados.
Estado – snapshot, uma classe que armazena o estado da origem, além de informações de data ou um índice a partir do qual a ordem de reversão pode ser estabelecida com precisão.
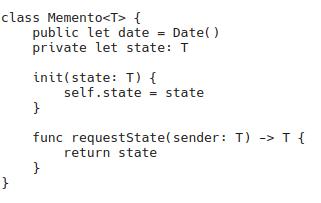
Uma característica importante do padrão é que apenas a fonte deve ter acesso aos campos internos do estado salvo no instantâneo. Isso é necessário para proteger os instantâneos de alterações externas (de desenvolvedores úteis que desejam alterar algo ignorando o encapsulamento; , quebrando a lógica do sistema). Para implementar o encapsulamento, são usadas classes integradas e, em C++, elas usam a capacidade de especificar classes amigas. Pessoalmente, implementei uma versão simples sem encapsulamento para Rise e usando Generic ao implementar para Swift. Na minha versão – Memento fornece seu estado interno apenas para entidades do mesmo estado de classe:
Neste post irei descrever um padrão de design chamado “Visitante” ou “Visitante” Este padrão pertence ao grupo de Padrões de comportamento.
Vamos encontrar um problema
Esse padrão é usado principalmente para contornar a limitação do envio único em linguagens de ligação antecipada.
Alice X por NFGPhoto (CC-2.0) Vamos criar uma classe/protocolo abstrato Band, fazer uma subclasse de MurpleDeep, criar uma classe Visitor com dois métodos – um para enviar qualquer descendente de Band para o console, o segundo para gerar qualquer MurpleDeep, o principal é que os nomes (assinaturas) dos métodos sejam os mesmos e os argumentos diferem apenas por classe. Usando o método de impressão intermediário com o argumento Band, criamos uma instância de Visitor e chamamos o método visit para MurpleDeep. Abaixo está o código em Kotlin:
A saída será “Esta é a classe Band“
Como isso é possível?!
Por que isso acontece é descrito em palavras inteligentes em muitos artigos, inclusive em russo, mas sugiro que você imagine como o compilador vê o código, talvez tudo fique claro imediatamente:
Resolvendo o problema
Existem muitas soluções para resolver este problema, a seguir consideraremos uma solução usando o padrão Visitor. Adicionamos o método Accept com o argumento Visitor à classe/protocolo abstrato, chamamos Visitor.visit(this) dentro do método e, em seguida, adicionamos uma substituição/implementação do método Accept à classe MurpleDeep, violando DRY de forma decisiva e calma, novamente escrevendo visitante.visita(este).< br />Código final:
Neste post irei descrever o padrão estrutural “Leve” ou “Oportunista” (Peso mosca) Este padrão pertence ao grupo de Padrões Estruturais.
Vejamos abaixo um exemplo de como o padrão funciona:
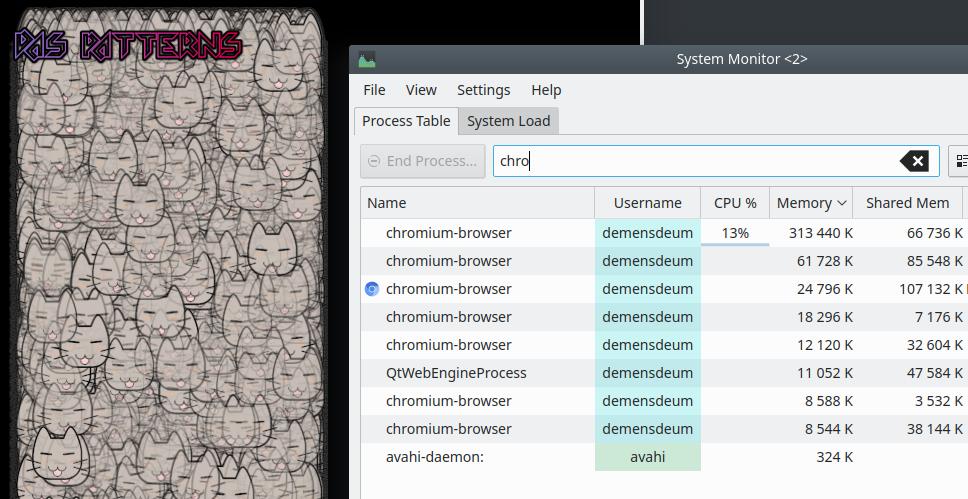
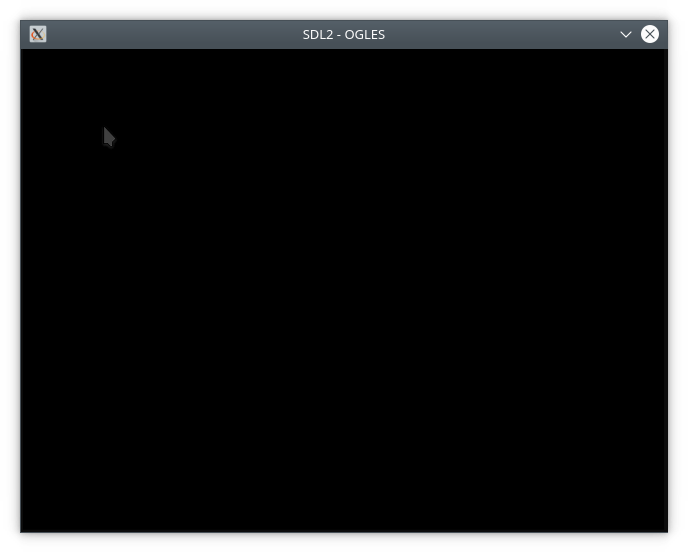
Por que é necessário? Para economizar RAM. Concordo que em tempos de uso generalizado do Java (que consome CPU e memória à toa), isso não é mais tão importante, mas vale a pena usar. No exemplo acima, apenas 40 objetos são gerados, mas se você aumentar o número para 120.000, o consumo de memória aumentará proporcionalmente. Vejamos o consumo de memória sem usar o padrão flyweight no navegador Chromium:
Sem usar um padrão, o consumo de memória é de aproximadamente 300 megabytes.
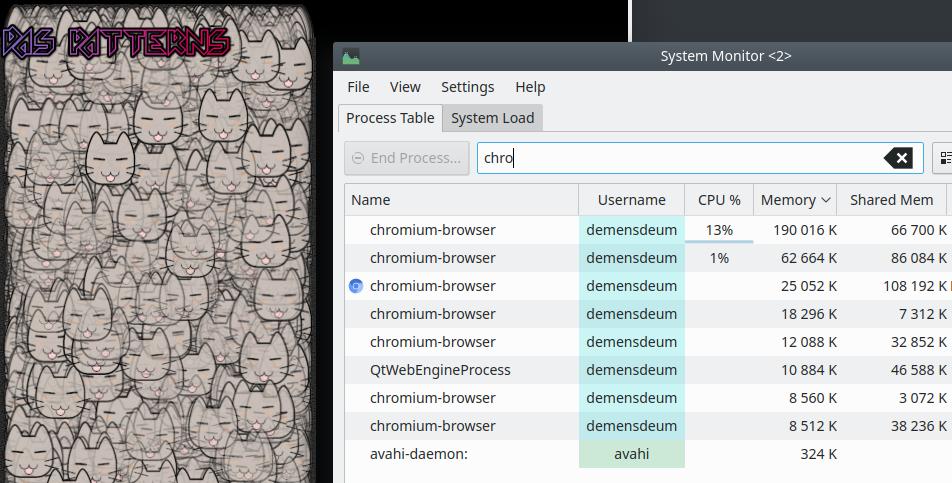
Agora vamos adicionar um padrão ao aplicativo e ver o consumo de memória:
Usando o padrão, o consumo de memória é de aproximadamente 200 megabytes, então economizamos 100 megabytes de memória no aplicativo de teste; em projetos sérios, a diferença pode ser muito maior.
Como funciona?
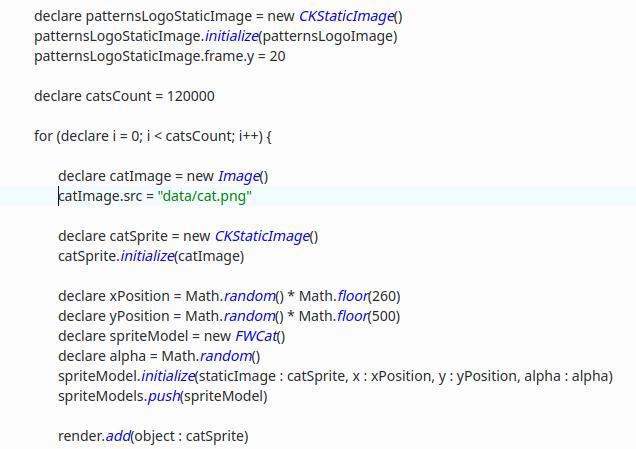
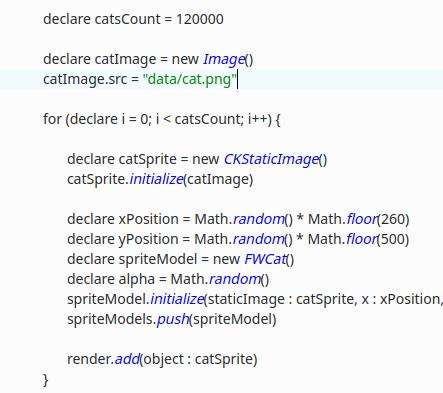
No exemplo acima, desenhamos 40 gatos, ou para maior clareza, 120 mil. Cada gato é carregado na memória como uma imagem png e, na maioria das renderizações, ele é convertido em um bitmap para renderização (na verdade, bmp), isso é feito para aumentar a velocidade, já que um png compactado leva muito tempo para ser renderizado. Sem usar o padrão, carregamos 120 mil fotos de gatos na RAM e desenhamos, mas ao usar o padrão “leve” carregamos um gato na memória e desenhamos 120 mil vezes com diferentes posições e transparência. A mágica é que implementamos coordenadas e transparência separadamente da imagem do gato durante a renderização, a renderização pega apenas um gato e usa um objeto com coordenadas e transparência para a renderização correta.
A imagem do gato é carregada separadamente para cada objeto no loop – catImage.
Usando padrão:
Uma imagem de um gato é usada por 120 mil objetos.
Onde é usado?
Usado em estruturas GUI, por exemplo, o “reuse” (reutilizar) células da tabela UITableViewCell, o que aumenta a barreira de entrada para iniciantes que não conhecem esse padrão. Também comumente usado no desenvolvimento de jogos.
Nesta nota descreverei minha experiência e a experiência de meus colegas ao trabalhar com o padrão Singleton (Singleton na literatura estrangeira), enquanto trabalhava em vários projetos (bem-sucedidos e não tão bem-sucedidos). Descreverei por que pessoalmente acho que esse padrão não pode ser usado em lugar nenhum e também descreverei quais fatores psicológicos na equipe influenciam a integração desse antipadrão. Dedicado a todos os desenvolvedores caídos e aleijados que estavam tentando entender por que tudo começou com um dos membros da equipe trazendo um cachorrinho fofo, fácil de manusear, que não requer cuidados e conhecimentos especiais para cuidar dele, e terminou com a fera criada tomar seu projeto como refém, requer cada vez mais horas de trabalho e consome os nervos do usuário, seu dinheiro e cria números absolutamente monstruosos para avaliar a implementação de coisas aparentemente simples coisas.
A história se passa em um universo alternativo, todas as coincidências são aleatórias…
Acaricie o gato em casa com Cat@Home
Toda pessoa às vezes na vida tem um desejo irresistível de acariciar um gato. Analistas de todo o mundo prevêem que a primeira startup que criou um aplicativo para entrega e aluguel de gatos se tornará extremamente popular e em um futuro próximo será comprada pelo Moogle por trilhões de dólares. Logo isso acontece – um cara de Tyumen cria o aplicativo Cat@Home e logo se torna um trilionário, a empresa Moogle obtém uma nova fonte de lucro e milhões de pessoas estressadas têm a oportunidade de peça um gato para sua casa para passar mais roupas e se acalmar.
Ataque dos Clones
Um dentista extremamente rico de Murmansk, Alexey Goloborodko, impressionado com um artigo sobre Cat@Home da Forbes, decide que também quer ser astronomicamente rico. Para atingir esse objetivo, através de seus amigos, ele encontra uma empresa de Goldfield – que é a cidade de Goldfield. Wakeboard DevPops, que fornece serviços de desenvolvimento de software, encomenda a eles o desenvolvimento de um clone Cat@Home.
Time vencedor
O projeto se chama Fur&Pure, confiado a uma talentosa equipe de desenvolvimento de 20 pessoas; A seguir, vamos nos concentrar em uma equipe de desenvolvimento móvel de 5 pessoas. Cada membro da equipe recebe sua parte do trabalho, munido de ágil e scrum, a equipe conclui o desenvolvimento no prazo (em seis meses), sem bugs, lança o aplicativo na iStore, onde é avaliado em 5 por 100.000 usuários, há muitos comentários sobre o quão bom é o aplicativo, quão excelente é o serviço (afinal, universo alternativo). Os gatos estão passados, o aplicativo está liberado, tudo parece estar indo bem. Porém, Moogle não tem pressa em comprar uma startup por trilhões de dólares, porque não só gatos, mas também cachorros já apareceram no Cat@Home.
O cachorro late, a caravana segue em frente
O proprietário do aplicativo decide que é hora de adicionar cães ao aplicativo, solicita uma avaliação à empresa e recebe aproximadamente pelo menos seis meses para adicionar cães ao aplicativo. Na verdade, o aplicativo será escrito do zero novamente. Durante esse período, o Moogle adicionará cobras, aranhas e porquinhos-da-índia ao aplicativo, e o Fur&Pur receberá apenas cães. Por que isso aconteceu? A falta de arquitetura de aplicação flexível é a culpada por tudo; um dos fatores mais comuns é o antipadrão Singleton.
O que há de errado?
Para encomendar um gato em casa o consumidor precisa criar um pedido e encaminhá-lo para o escritório, onde o escritório irá processá-lo e enviar um entregador com o gato, o entregador já receberá o pagamento pelo serviço. Um dos programadores decide criar uma classe “Cat Application” com os campos necessários, traz esta classe para o espaço global da aplicação através de um singleton. Por que ele está fazendo isso? Para economizar tempo (economizando meia hora), porque é mais fácil tornar um aplicativo público do que pensar na arquitetura do aplicativo e usar injeção de dependência. Então outros desenvolvedores pegam esse objeto global e vinculam suas classes a ele. Por exemplo, todas as telas acessam o objeto global “Cat Request” e mostrar dados do aplicativo. Como resultado, esse aplicativo monolítico é testado e lançado. Tudo parece estar bem, mas de repente aparece um cliente com a necessidade de adicionar solicitações de cães ao aplicativo. A equipe começa a avaliar freneticamente quantos componentes do sistema serão afetados por essa mudança. Ao final da análise, verifica-se que é necessário refazer de 60 a 90% do código para ensinar a aplicação a aceitar não apenas “Request For Cat” mas também “Pedido de Cachorro”, já é inútil avaliar a adição de outros animais nesta fase, para dar conta de pelo menos dois.
Como prevenir o singleton
Primeiro, na fase de levantamento de requisitos, indique explicitamente a necessidade de criar uma arquitetura flexível e extensível. Em segundo lugar, vale a pena realizar uma revisão independente do código do produto paralelamente, com pesquisa obrigatória dos pontos fracos. Se você é um desenvolvedor e adora singletons, sugiro que recupere o juízo antes que seja tarde demais, caso contrário, noites sem dormir e nervos em frangalhos serão garantidos. Se você estiver trabalhando em um projeto legado que possui muitos singletons, tente se livrar deles ou do projeto o mais rápido possível. Você precisa mudar do antipadrão de objetos/variáveis globais singletons para injeção de dependência – o padrão de design mais simples no qual todos os dados necessários são fornecidos a uma instância de uma classe no estágio de inicialização, sem necessidade adicional de serem vinculados ao espaço global.
In this post I will describe an example of adding functionality to a C ++ application using plugins.The practical part of the implementation for Linux is described; the theory can be found at the links at the end of the article.
Composition over inheritance!
To begin with, we will write a plugin – a function that we will call:
Next, we will build the plugin as a dynamic library “extension.so”, which we will connect in the future: clang++ -shared -fPIC extension.cpp -o extension.so
Next we write the main application that will load the file “extension.so”, look for a pointer to the function “extensionEntryPoint” there, and call it, typing errors if necessary:
The dlopen function returns a handler for working with a dynamic library;dlsym function returns a pointer to the required function by string;dlerror contains a pointer to the string with the error text, if any.
Next, build the main application, copy the file of the dynamic library in the folder with it and run.The output should be the “Extension entry point called”
Difficult moments include the lack of a single standard for working with dynamic libraries, because of this there is a need to export the function to a relatively global scope with extern C;the difference in working with different operating systems associated with this subtlety of work;the lack of a C ++ interface to implement OOP approach to working with dynamic libraries, however, there are open-source wrappers, for example m-renaud/libdlibxx
Na estatística existe uma classe de problemas – análise de série temporal. Tendo uma data e o valor de uma determinada variável, você pode prever o valor desta variável no futuro. Primeiro eu queria implementar uma solução para este problema usando TensorFlow, mas encontrou a biblioteca Profeta por Facebook. Prophet permite que você faça uma previsão com base em dados (csv) contendo colunas de data (ds) e valor variável (y). Você pode descobrir como trabalhar com ele na documentação do site oficial na seção Início rápido Como conjunto de dados, usei um upload csv do site https://www.investing.com, ao implementar usei Linguagem R e API do Profeta para ele. Gostei muito do R, pois sua sintaxe simplifica o trabalho com grandes quantidades de dados, permite escrever de forma mais simples e cometer menos erros do que ao trabalhar com linguagens convencionais (Python), já que teria que trabalhar com expressões lambda, e no R você já tem todas as expressões lambda. Para não preparar os dados para processamento, utilizei o pacote a qualquer momento, que pode converter strings em uma data, sem pré-processamento. A conversão de strings de moeda em números é feita usando o pacote readr
Como resultado, recebi uma previsão segundo a qual o Bitcoin custará US$ 8.400 até o final de 2019 e a taxa de câmbio do dólar será de 61 rublos. Devemos acreditar nessas previsões? Pessoalmente, acho que não vale a pena, porque… Você não pode usar métodos matemáticos sem compreender sua essência.
Malevich chega periodicamente a qualquer desenvolvedor no OpenGL. Isso acontece inesperadamente e com ousadia, você apenas inicia o projeto e vê um quadrado preto em vez de uma renderização maravilhosa:
Hoje descreverei por que motivo fui visitado por um quadrado preto, os problemas encontrados por causa dos quais o OpenGL não desenha nada na tela e às vezes até torna a janela transparente.
Use ferramentas
Para depurar o OpenGL, duas ferramentas me ajudaram: renderdoc e Death-Mask O que não mostra nada na tela (apenas um quadrado). Ao usar chroot e montagem em 16.10 i recebo uma assembléia de trabalho do jogo com gráficos .
Parece que algo quebrou no Ubuntu 18.04
ldd mostrou a linkka às bibliotecas idênticas sdl2, gl. Dirigindo uma construção não trabalhadora no RenderDoc, vi lixo na entrada do shader do vértice, mas precisava de uma confirmação mais sólida. Para entender a diferença entre os binarticos, eu os dirigi através do Apitrace . A comparação de lixeiras me mostrou que a assembléia em uma nova ubunta quebra o programa das perspectivas no OpenGL, na verdade enviando lixo lá:
Matrizes se reúnem na biblioteca GLM. Depois de copiar o GLM de 16.04 – Recebi a construção do jogo novamente. O problema foi a diferença na inicialização de uma única matriz no GLM 9.9.0, é necessário indicar claramente o argumento MAT4 (1.0F) nele no construtor. Tendo mudado a inicialização e escrevendo O autor da biblioteca, eu comecei a fazer testes para fsgl . No processo de escrita que encontrei falhas no FSGL, as descrevo ainda mais.
Determine quem está na vida
Para o trabalho correto com o OpenGL, você precisa voluntariamente à força solicitar o contexto de uma determinada versão. Então, ele procura SDL2 (você precisa colocar a versão estritamente antes de inicializar o contexto):
Por exemplo, o renderDoc não funciona com contextos abaixo de 3.2. Gostaria de observar que, depois de alternar o contexto , há uma alta probabilidade de ver a mesma tela preta . Por que?
Como o contexto do OpenGL 3.2 deve exigir a presença de buffer VAO , sem o qual 99% dos drivers gráficos não funcionam. Adicione fácil:
O código de renderização do teste FSGL também estava presente Sleep (2s) ; Então, no Xubuntu e Ubuntu, recebi a renderização correta e enviei o pedido para dormir, mas no Kubuntu recebi uma tela transparente em 80% do lançamento do golfinho e 30% dos lançamentos e terminais. Para resolver esse problema, adicionei a renderização em cada quadro, após uma pesquisa do SDLEVENT, conforme recomendado na documentação.
OpenGL suporta o canal de comunicação entre o aplicativo e o driver, para ativá-lo, você precisa ativar os sinalizadores GL_DEBUG_OUTPUT, GL_DEBUG_OUTPUT_SYNCHRONUS, Afixar o aviso GLDebugMessagEntrol e tie the callback através de .
Um exemplo de inicialização pode ser tomado aqui: https://github.com/rock-core/gui-vizkit3d/blob/master/src/EnableGLDebugOperation.cpp
Neste post falarei sobre minhas desventuras com ponteiros inteligentes shared_ptr. Depois de implementar a geração do próximo nível em meu jogo Death-Mask, notei uma memória vazar . Cada novo nível proporcionou um aumento de + 1 megabyte na RAM consumida. É Obviamente que alguns objetos permaneceram na memória e não a liberaram. Para corrigir este facto, foi necessário implementar a correcta implementação de recursos quando o nível se encontra sobrecarregado, o que aparentemente não foi feito. Como usei ponteiros inteligentes, havia várias opções para resolver esse problema, a primeira envolvia a revisão manual do código (longa e enfadonha), enquanto a segunda envolvia pesquisar os recursos do depurador lldb e do código-fonte libstdc++ para a possibilidade de rastreamento automático contra alterações.
Na Internet, todos os conselhos se resumiam a revisar manualmente o código, corrigi-lo e bater-se com chicotes depois de encontrar a linha de código problemática. Também foi proposta a implementação de um sistema próprio para trabalhar com memória, como fazem todos os grandes projetos desenvolvidos desde as décadas de 90 e 2000, antes da chegada dos ponteiros inteligentes no padrão C++11. Tentei usar pontos de interrupção no construtor de uma cópia de todos os shared_ptrs, mas depois de vários dias nada de útil aconteceu. Houve uma ideia de adicionar log à biblioteca libstdc++, mas os custos de mão de obra acabaram sendo monstruosos.
Cowboy Bebop (1998)
A solução me ocorreu de repente na forma de rastrear alterações na variável privada shared_ptr – use_count. Isso pode ser feito usando watchpoints embutidos no lldb. Depois de criar um shared_ptr via make_shared, as alterações no contador no lldb podem ser rastreadas usando a linha: .
Onde a “câmera” este é um objeto shared_ptr cujo estado do contador precisa ser rastreado. Claro, os aspectos internos do shared_ptr irão variar dependendo da versão do libstdc++, mas o princípio geral pode ser entendido. Após instalar o watchpoint, iniciamos os aplicativos e lemos o stacktrace de cada alteração do contador, depois olhamos o código (sic!), encontramos o problema e corrigimos. No meu caso, os objetos não foram liberados das tabelas de cache e das tabelas lógicas do jogo. Espero que este método ajude você a lidar com vazamentos ao trabalhar com shared_ptr e ame ainda mais essa ferramenta de memória. Boa depuração.
Apresento a sua atenção um exemplo simples de como trabalhar com um framework para trabalhar com Deep Learning – TensorFlow. Neste exemplo, ensinaremos uma rede neural a detectar números positivos, negativos e zero. Instalação do TensorFlow e CUDA Eu te instruo, esta tarefa realmente não é fácil)
Para resolver problemas de classificação, classificadores. TensorFlow tem vários classificadores de alto nível prontos que exigem configuração mínima para funcionar. Primeiro, treinaremos DNNClassifier usando conjunto de dados com números positivos, negativos e zero – com os “rótulos” corretos. No nível humano, um conjunto de dados é um conjunto de números com resultados de classificação (rótulos):
10 – positivo -22– negativo 0 – zero 42 – positivo … outros números com classificação
Em seguida, inicia-se o treinamento, após o qual você pode inserir números que nem foram incluídos no conjunto de dados – a rede neural deve identificá-los corretamente. Abaixo está o código completo do classificador com gerador de conjunto de dados para treinamento e dados de entrada:
importartensorflowimportaritertoolsimportaraleatóriodetempotempo de importaçãoclassClassifiedNumber:__número =0__classifiedAs =3def__init__(self, número):self.__number = númeroif número ==0:self.__classifiedAs = 0# zeroelif número >0:self.__classifiedAs = 1# positivoelif número <0:self.__classifiedAs = 2# negativodefnúmero(eu):returnself.__númerodefclassificadoAs(eu):returnself.__classificadoAsdefclassifiedAsString(classifiedAs):if classificadoAs ==0:return"Zero"elif classificadoAs ==1:return"Positivo"elif classificadoAs ==2:return"Negativo"deftrainDatasetFunction():trainNumbers = []trainNumberLabels = []para i emintervalo(-1000, 1001):número = NúmeroClassificado(i)trainNumbers.append(number.number())trainNumberLabels.append(number.classifiedAs())return ( {"number" : trainNumbers } , trainNumberLabels)definputDatasetFunction():global randomSeedrandom.seed(randomSeed) # para obter o mesmo resultadonúmeros = []para i emintervalo(0, 4):números.append(random.randint(-9999999, 9999999))return {"número" : números }defprincipal():print("Teste do classificador de números Positive-Negative-Zero do TensorFlow por demensdeum 2017 (demensdeum@gmail. com)")maximalClassesCount =len(definir< /span>(trainDatasetFunction()[1])) +1numberFeature = tensorflow.feature_column. numeric_column("número")classificador = tensorflow.estimador. DNNClassifier(feature_columns = [numberFeature], unidades_ocultas = [10, 20, 10], n_classes = maximalClassesCount)gerador = classificador.train(input_fn = trainDatasetFunction, etapas =1000).predict(input_fn = inputDatasetFunction)inputDataset = inputDatasetFunction()resultados =lista(itertools. islice(generator, len(inputDatasetFunction()["número"])))i =0para resultado em resultados:imprimir("número: %d classificado como %s"% (inputDataset["número"][i], classificadoAsString(result["class_ids"][0 ])))i +=1randomSeed = tempo()principal()
Tudo começa no método main(), definimos a coluna numérica com a qual o classificador irá funcionar – tensorflow.feature_column.numeric_column(“number”) Em seguida, os parâmetros do classificador são definidos. É inútil descrever os argumentos de inicialização atuais, pois a API muda todos os dias, e você definitivamente deve consultar a documentação da versão instalada do TensorFlow e não confiar em manuais desatualizados.
Em seguida, é lançado o treinamento indicando uma função que retorna um conjunto de dados de números de -1000 a 1000 (trainDatasetFunction), com a classificação correta desses números com base em positivo, negativo ou zero. A seguir, enviamos como entrada números que não estavam no conjunto de dados de treinamento – aleatório de -9999999 a 9999999 (inputDatasetFunction) para classificá-los.
Finalmente, lançamos iterações com base no número de dados de entrada (itertools.islice), imprimimos o resultado, executamos e ficamos surpresos:
número: 4063470 classificado como Positivonúmero: 6006715 classificado como Positivonúmero: -5367127 classificado como Negativonúmero: -7834276 classificado como Negativo
Para ser honesto, ainda estou um pouco surpreso que o classificador *entenda* até mesmo aqueles números que eu não ensinei. Espero que no futuro eu entenda o tópico de aprendizado de máquina com mais detalhes e que haja mais tutoriais.
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.