Se você deseja usar redes neurais para ajudar a escrever código (a chamada codificação Vibe) e possui um computador bastante poderoso, por exemplo, com uma placa de vídeo Nvidia RTX, você pode implantar todo o ambiente de forma absolutamente gratuita em sua máquina. Isso resolve problemas com assinaturas pagas e permite que você trabalhe com segurança com projetos sob NDA, já que seu código não é enviado para lugar nenhum. Neste post irei descrever como montar um pacote local de LM Studio, VS Code e a extensão Continue.
Ferramentas para codificação local do Vibe
Para um trabalho confortável, precisamos de três componentes principais:
– LM Studio: um aplicativo conveniente para baixar e executar LLMs locais. Assume toda a complexidade de trabalhar com modelos GGUF e disponibiliza um servidor local compatível com a API OpenAI.
– VS Code: um editor de código popular e familiar.
– Continue: extensão para VS Code que integra redes neurais diretamente no ambiente de trabalho. Permite conversar, destacar código para refatoração e oferece suporte ao preenchimento automático.
Requisitos de hardware
Os modelos de idioma local consomem muita memória:
– Placa de vídeo (GPU): Nvidia com 8 GB VRAM ou superior (para trabalho confortável com modelos com 7 a 8 bilhões de parâmetros). Modelos mais pesados exigirão 16 GB de VRAM.
– Espaço em disco: cerca de 500 GB para armazenar vários modelos baixados.
Configurando o link
O processo de configuração é bastante simples e não requer manipulações complexas no terminal:
1. Baixe e instale o LM Studio. Use a pesquisa integrada para encontrar um modelo leve como Qwen Coder ou gemma3:12b.
2. No LM Studio, vá para a guia Servidor Local e clique em Iniciar Servidor. Por padrão, ele começará em `http://localhost:1234/v1`.
3. Abra o VS Code e instale a extensão Continue da loja de plugins.
4. Abra o arquivo de configuração Continue e adicione um novo modelo, especificando o provedor `openai` e o endereço do seu servidor local do LM Studio.
Você pode então se comunicar com seu LLM local diretamente na barra lateral Continuar, fazer perguntas sobre seu código e gerar novos componentes.
Por que isso funciona?
Como escrevi anteriormente, os LLMs se saem melhor com estrutura plana e código WET (Write Everything Twice). Os modelos de parâmetros locais podem ser inferiores a gigantes como o GPT-4 quando se trata de projetar arquiteturas complexas, mas são mais do que capazes de gerar código padrão, refatorar funções simples e prototipagem rápida.
Além disso, com a codificação local do Vibe, seu código nunca sai da máquina. Isso torna essa combinação ideal para desenvolvimento corporativo e trabalho com dados confidenciais.
Saída
As redes neurais locais não são capazes de substituir totalmente um programador ou projetar um sistema complexo. No entanto, a combinação de LM Studio + VS Code + Continue proporciona independência dos serviços em nuvem e mantém a privacidade. Esta é uma ferramenta auxiliar totalmente funcional para tarefas rotineiras, se você estiver disposto a suportar as limitações de pequenos modelos e controlar de forma independente a arquitetura do projeto.
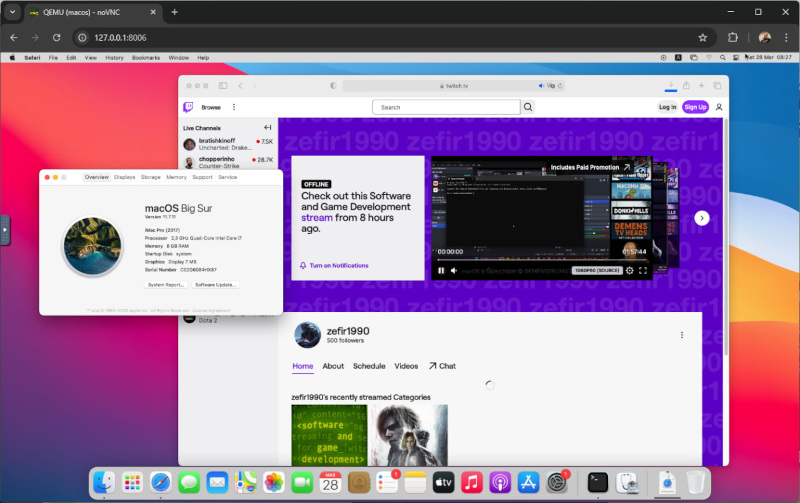
É possível rodar macOS no Docker, apesar das objeções de quem diz que isso é impossível, e supostamente o macOS possui algum tipo de sistema de proteção que pode resistir a isso.
Algumas das formas clássicas de executar o macOS em máquinas PC têm sido historicamente:
*Hackintosh
* Virtualização, por exemplo usando VMWare
Hackintosh pressupõe a presença de hardware semelhante ou muito próximo do Mac original. A virtualização impõe certos requisitos de hardware, mas geralmente não tão rígidos como no caso do Hackintosh. Porém, no caso da virtualização, existem problemas de desempenho, pois o macOS não está otimizado para funcionar em ambiente virtual.
Recentemente, tornou-se possível executar o macOS no Docker. Isso é possível graças ao projeto Docker-OSX, que fornece imagens macOS prontas para serem executadas no Docker. É importante notar que o Docker-OSX não é um projeto oficial da Apple e não é suportado por ele. No entanto, permite executar o macOS no Docker e usá-lo para desenvolver e testar aplicativos.
No entanto, nunca consegui iniciá-lo totalmente; depois de carregar no Recovery OS, meu teclado e mouse simplesmente caíram e não consegui continuar a instalação. Ao mesmo tempo, no primeiro menu de boot, o teclado funciona. Talvez o fato seja que este projeto não tem mais suporte tão ativo e há alguns problemas específicos ao rodar no Windows 11 + WSL2 + Ubuntu.
Permite rodar macOS no Docker, a interface funciona através do navegador via encaminhamento VNC(?). Após a inicialização, o macOS está disponível em http://localhost:5900
Consegui rodar este projeto e instalar o macOS Big Sur (minuto 2020) no Windows 11 + WSL2 + Ubuntu, mas apenas alterando o arquivo compose, a saber:
VERSÃO: “11” é a versão do macOS, neste caso Big Sur
RAM_SIZE: “8G” é a quantidade de RAM alocada para macOS
CPU_CORES: “4” é o número de núcleos de CPU alocados para macOS
No momento, executar o macOS tahoe (16) também é possível, mas há uma série de problemas que os desenvolvedores do projeto estão tentando resolver corajosamente.
Esta forma original de iniciar o macOS permite que você experimente em seu hardware que não seja Mac e, depois de sofrer o suficiente, compre um Mac. No entanto, pode ser útil para testar software em sistemas mais antigos e no desenvolvimento geral.
O ecossistema Swift está se desenvolvendo ativamente fora das plataformas Apple e hoje é bastante confortável escrever nele no Windows usando o Windows Subsystem for Linux (WSL2). Vale a pena considerar que para assemblies no Linux/WSL, uma versão leve do Swift está disponível – sem estruturas proprietárias da Apple (como SwiftUI, UIKit, AppKit, CoreData, CoreML, ARKit, SpriteKit e outras bibliotecas específicas do iOS/macOS), mas para utilitários de console e backend isso é mais que suficiente. Neste post, vamos percorrer passo a passo o processo de preparação do ambiente e construção do compilador Swift a partir do código-fonte dentro do WSL2 (usando Ubuntu/Debian como exemplo).
Atualizamos a lista de pacotes e o próprio sistema:
sudo apt update && sudo apt upgrade -y
Instale as dependências necessárias para a compilação:
No último artigo examinamos a teoria do padrão Interpreter, aprendemos o que é uma árvore AST e como abstrair expressões terminais e não terminais. Desta vez, vamos nos afastar da teoria e ver como esse padrão é aplicado em projetos comerciais sérios que todos usamos todos os dias!
Spoiler: Você pode estar usando o padrão Interpreter agora mesmo, apenas lendo este texto no seu navegador!
Um dos exemplos mais marcantes e, talvez, mais importantes do uso desse padrão na indústria é o JavaScript. A linguagem, que originalmente foi criada “no joelho”, hoje funciona em bilhões de dispositivos justamente graças ao conceito de interpretação.
10 dias que mudaram a Internet
A história do JavaScript está cheia de lendas. Em 1995, Brendan Eich, enquanto trabalhava na Netscape Communications, recebeu a tarefa de criar uma linguagem de script simples que pudesse ser executada diretamente em um navegador (Netscape Navigator) para tornar as páginas da web interativas. A administração queria algo com uma sintaxe semelhante ao então super popular Java, mas destinado não a engenheiros profissionais, mas a web designers.
Eich teve apenas 10 dias para escrever o primeiro protótipo da linguagem, que então se chamava Mocha (depois LiveScript, e só depois JavaScript por razões de marketing). A pressa não foi acidental: a Microsoft estava logo atrás, que ao mesmo tempo preparava ativamente sua própria linguagem de script VBScript para ser incorporada no navegador Internet Explorer. A Netscape precisava liberar urgentemente sua resposta para não perder na iminente guerra dos navegadores.
Simplesmente não havia tempo para escrever um compilador complexo em código de máquina. A solução óbvia e mais rápida para Eich foi a arquitetura do clássico Interpreter.
O primeiro intérprete (SpiderMonkey) funcionou assim:
Ele lê o código-fonte do texto do script na página.
O analisador léxico dividiu o texto em tokens.
O analisador construiu uma Árvore de Sintaxe Abstrata (AST). Em termos do padrão Interpreter, esta árvore consistia em expressões terminais (strings, números como 42) e não terminais (chamadas de função, instruções como If, While).
Então a máquina virtual “atravessou” esta árvore passo a passo, executando as instruções embutidas nela em cada nó (chamando um método semelhante a Interpret()).
Contexto e Objetos
Lembra do objeto Context que tivemos que passar para o método Interpret(Context context) na implementação clássica? O intérprete precisa dele para armazenar o estado atual da memória.
No caso do JavaScript, o papel deste contexto no nível superior é desempenhado por um objeto global (por exemplo, uma janela em um navegador). Quando seu nó AST tenta, digamos, escrever texto na tela via document.write(“Hello”), o interpretador acessa seu contexto (o objeto document) e chama a API interna do navegador desejada.
É graças ao interpretador que o JavaScript é capaz de interagir tão facilmente com o DOM (Document Object Model) – todos eles são apenas objetos em um contexto que são acessados por nós de árvore.
Evolução do intérprete: Compilação JIT
Historicamente, JS em navegadores permaneceu por muito tempo um intérprete “puro”. E isso tinha uma grande desvantagem – velocidade lenta. Analisar a árvore e percorrer cada nó lentamente cada vez que o script era executado tornava aplicativos da Web complexos mais lentos.
Com o advento do mecanismo V8 do Google (integrado ao Chrome) em 2008, ocorreu uma revolução. Os engenheiros perceberam que um intérprete não é suficiente para a web moderna. O mecanismo se tornou mais complexo: ele ainda constrói a árvore AST, mas agora usa compilação JIT (Just-In-Time).
Os mecanismos JS modernos (V8, SpiderMonkey) funcionam como um pipeline complexo:
O interpretador base rápido e burro começa a executar seu código JS instantaneamente, sem sequer esperar que ele seja compilado (o padrão clássico ainda funciona aqui).
Paralelamente, o mecanismo monitora seções “quentes” do código (loops ou funções que são chamadas milhares de vezes).
Essas seções são compiladas pelo compilador JIT diretamente no código de máquina otimizado, ignorando o interpretador lento.
Foi essa combinação do início instantâneo do interpretador e do poder computacional de compilação que permitiu que o JavaScript dominasse o mundo, tornando-se a linguagem dos servidores (Node.js) e dos aplicativos móveis (React Native).
Intérprete na indústria de jogos
Apesar do domínio do C++ na computação pesada, o padrão Interpreter é um padrão da indústria no desenvolvimento de jogos para a criação de lógica de jogos. Para que? Para que os designers de jogos possam fazer jogos sem o risco de “deixar cair” o motor ou a necessidade de recompilá-lo constantemente.
Um excelente exemplo histórico é o UnrealScript – a linguagem na qual a lógica dos jogos Unreal Tournament e Gears of War foi escrita no Unreal Engine 1, 2 e 3. O texto foi compilado em um bytecode de máquina abstrato compacto, que foi então passo a passo (interpretado) pela máquina virtual do motor.
Scripts gráficos visuais (Blueprints)
Hoje, o texto foi substituído pela programação visual – o sistema Blueprints no Unreal Engine 4 e 5.
Se você já abriu um Blueprint no Unreal Engine, viu muitos nós conectados por fios. Arquitetonicamente, todo o gráfico do Blueprints é uma enorme Árvore de Sintaxe Abstrata (AST) desenhada na tela:
Expressões de Terminal: Nós constantes. Por exemplo, um nó que simplesmente armazena o número 42 ou uma string. Eles retornam um valor específico quando interpretados.
Expressões não terminais: Nós de computação (Adicionar) ou nós de controle de fluxo (Filial). Eles têm entradas de argumentos, que o intérprete avalia primeiro recursivamente antes de produzir o resultado como um pino de saída.
E o papel do contexto aqui é desempenhado pela memória de uma instância de um objeto de jogo específico (Ator). A Máquina Interpretadora “caminha” com segurança por esse gráfico, solicitando dados e realizando transições.
Onde mais o Interpretador é usado?
O padrão de intérprete pode ser encontrado em quase todos os sistemas complexos onde instruções dinâmicas precisam ser executadas. Aqui estão apenas alguns exemplos de software comercial:
Linguagens de programação interpretadas (Python, Ruby, PHP). Todo o seu tempo de execução é baseado no padrão clássico. Por exemplo, a implementação de referência do CPython primeiro analisa seu script .py em um AST, compila-o em bytecode e, em seguida, uma enorme máquina virtual (loop de computação) interpreta esse bytecode passo a passo.
Java Virtual Machine (JVM). Inicialmente, o código Java é compilado não em instruções de máquina, mas em bytecode. Quando você executa o aplicativo, a JVM atua como um intérprete (embora com compilação JIT agressiva, assim como na V8).
Bancos de dados e SQL Quando você emite uma consulta SQL (SELECT * FROM users) no PostgreSQL ou MySQL, o mecanismo de banco de dados atua como um intérprete. Ele realiza análises lexicais, constrói uma árvore de consulta AST, gera um plano de execução e, em seguida, literalmente “interpreta” esse plano iterando nas linhas das tabelas.
Expressões regulares (RegEx). Qualquer mecanismo de expressão regular analisa internamente um padrão de string (por exemplo, ^\d{3}-\d{2}$) em um gráfico de estado (NFA/DFA Automata), pelo qual o interpretador interno passa, combinando cada caractere de entrada com os vértices deste gráfico.
Unity Shader Graph / Unreal Material Editor – interpreta nós visuais em código de shader modular (GLSL/HLSL).
Nós de geometria do Blender – interpreta operações matemáticas e geométricas para gerar modelos 3D de forma processual em tempo real.
Total
O padrão Interpreter já ultrapassou o escopo de “escrever sua própria calculadora”. Este é o padrão mais poderoso da indústria. Desde mecanismos JavaScript que executam gigabytes de código nos bastidores dos navegadores todos os dias até designers de jogos que permitem construir lógica complexa sem conhecimento de C++, os intérpretes continuam sendo um dos conceitos de arquitetura mais importantes no desenvolvimento de TI moderno.
O diagrama de blocos é uma ferramenta visual que ajuda a transformar um algoritmo complexo em uma sequência de ações compreensíveis e estruturadas. Da programação ao gerenciamento de processos de negócios, eles servem como uma linguagem universal para visualização, análise e otimização dos sistemas mais complexos.
Imagine um mapa onde, em vez de estradas, é lógica e, em vez de cidades – ações. Esta é um diagrama de blocos-uma ferramenta indispensável para navegação nos processos mais confusos.
Exemplo 1: Esquema de lançamento de jogo simplificado
Para entender o princípio do trabalho, vamos apresentar um simples esquema de lançamento de jogo.
Esse esquema mostra o script perfeito quando tudo acontece sem falhas. Mas na vida real, tudo é muito mais complicado.
Exemplo 2: Esquema expandido para iniciar o jogo com carregamento de dados
Os jogos modernos geralmente exigem conexão à Internet para baixar dados, salvamento ou configurações do usuário. Vamos adicionar essas etapas ao nosso esquema.
Esse esquema já é mais realista, mas o que acontecerá se algo der errado?
Como foi: um jogo que “quebrou” com a perda da Internet
No início do projeto, os desenvolvedores não puderam levar em consideração todos os cenários possíveis. Por exemplo, eles se concentraram na lógica principal do jogo e não pensaram no que aconteceria se o jogador tivesse uma conexão com a Internet.
Em tal situação, o diagrama de blocos de seu código ficaria assim:
Nesse caso, em vez de emitir um erro ou fechar corretamente, o jogo congelou na fase de espera por dados que ela não recebeu devido à falta de uma conexão. Isso levou à “tela preta” e congelando o aplicativo.
Como se tornou: correção nas reclamações de usuários
Após inúmeras reclamações dos usuários sobre pairando, a equipe do desenvolvedor percebeu que precisávamos corrigir o erro. Eles fizeram alterações no código adicionando uma unidade de processamento de erros que permite que o aplicativo responda corretamente à falta de conexão.
É assim que o diagrama de blocos corrigido se parece, onde ambos os cenários são levados em consideração:
Graças a essa abordagem, o jogo agora informa corretamente o usuário sobre o problema e, em alguns casos, ele pode até ir para o modo offline, permitindo que você continue o jogo. Este é um bom exemplo de por que os diagramas de blocos são tão importantes : eles fazem o desenvolvedor pensar não apenas sobre a maneira ideal de execução, mas também sobre todas as falhas possíveis, tornando o produto final muito mais estável e confiável.
comportamento incerto
Pendurado e erros são apenas um exemplos de comportamento imprevisível do programa. Na programação, existe um conceito de comportamento incerto (comportamento indefinido) – Esta é uma situação em que o padrão do idioma não descreve como o programa deve se comportar em um determinado caso.
Isso pode levar a qualquer coisa: do “lixo” aleatório na retirada ao fracasso do programa ou mesmo à séria vulnerabilidade de segurança. O comportamento indefinido geralmente ocorre ao trabalhar com memória, por exemplo, com linhas na linguagem de C.
Um exemplo do idioma c:
Imagine que o desenvolvedor copiou a linha para o buffer, mas esqueceu de adicionar ao final o símbolo zero (`\ 0`) , que marca o final da linha.
Resultado esperado: “Olá” O resultado real é imprevisível.
Por que isso está acontecendo? A função `printf` com o especificador`%s` espera que a linha termine com um símbolo zero. Se ele não estiver, ela continuará lendo a memória fora do buffer destacado.
Aqui está o diagrama de blocos deste processo com dois resultados possíveis:
Este é um exemplo claro de por que os diagramas de blocos são tão importantes: eles fazem o desenvolvedor pensar não apenas sobre a maneira ideal de execução, mas também sobre todas as falhas possíveis, incluindo problemas de baixo nível, tornando o produto final muito mais estável e confiável.
No mundo do desenvolvimento de interfaces, existe um conceito comum – “Pixel perfeito no alojamento” . Isso implica a reprodução mais precisa da máquina de design ao menor pixel. Durante muito tempo, era um padrão -ouro, especialmente na era de um design clássico da web. No entanto, com a chegada da milha declarativa e o rápido crescimento da variedade de dispositivos, o princípio de “Pixel Perfect” está se tornando mais efêmero. Vamos tentar descobrir o porquê.
Imperial Wysiwyg vs. Código declarativo: Qual é a diferença?
Tradicionalmente, muitas interfaces, especialmente o desktop, eram criadas usando abordagens imperativas ou wysiwyg (o que você vê é o que recebe) dos editores. Nessas ferramentas, o designer ou desenvolvedor manipula diretamente com elementos, colocando -os em tela com precisão no pixel. É semelhante ao trabalho com um editor gráfico – você vê como o seu elemento se parece e definitivamente pode posicioná -lo. Nesse caso, a conquista de “Pixel Perfect” era um objetivo muito real.
No entanto, o desenvolvimento moderno é cada vez mais baseado em milhas declarativas . Isso significa que você não diz ao computador para “colocar este botão aqui”, mas descreva o que deseja obter. Por exemplo, em vez de indicar as coordenadas específicas do elemento, você descreve suas propriedades: “Este botão deve ser vermelho, ter recua de 16px de todos os lados e estar no centro do contêiner”. Freimvorki como React, Vue, Swiftui ou Jetpack Compose apenas use esse princípio.
Por que “Pixel Perfect” não funciona com uma milha declarativa para muitos dispositivos
Imagine que você cria um aplicativo que deve parecer igualmente bom no iPhone 15 Pro Max, Samsung Galaxy Fold, iPad Pro e uma resolução 4K. Cada um desses dispositivos possui resolução de tela diferente, densidade de pixels, partes e tamanhos físicos.
Quando você usa a abordagem declarativa, o próprio sistema decide como exibir a interface descrita em um dispositivo específico, levando em consideração todos os seus parâmetros. Você define as regras e dependências, não coordenadas duras.
* Adaptabilidade e capacidade de resposta: O principal objetivo das milhas declarativas é criar interfaces adaptativas e responsivas . Isso significa que sua interface deve se adaptar automaticamente ao tamanho e orientação da tela sem quebrar e manter a legibilidade. Se procurássemos “pixel perfeito” em cada dispositivo, teríamos que criar inúmeras opções para a mesma interface, o que nivelará completamente as vantagens da abordagem declarativa.
* densidade de pixel (DPI/PPI): Os dispositivos têm densidade de pixels diferentes. O mesmo elemento com o tamanho de 100 pixels “virtuais” em um dispositivo com alta densidade parecerá muito menor do que em um dispositivo de baixa densidade, se você não levar em consideração a escala. As estruturas declarativas são abstraídas por pixels físicos, trabalhando com unidades lógicas.
* Conteúdo dinâmico: em aplicativos modernos geralmente é dinâmico – seu volume e estrutura podem variar. Se embutirmos com força para os pixels, qualquer alteração no texto ou imagem levaria ao “colapso” do layout.
* Várias plataformas: Além da variedade de dispositivos, existem diferentes sistemas operacionais (iOS, Android, Web, Desktop). Cada plataforma possui seu próprio design, controles padrão e fontes. Uma tentativa de fazer uma interface perfeita de pixel absolutamente idêntica em todas as plataformas levaria a um tipo não natural e uma experiência de usuário ruim.
As abordagens antigas não foram embora, mas evoluíram
É importante entender que a abordagem das interfaces não é uma escolha binária entre “imperativo” e “declarativo”. Historicamente, para cada plataforma, havia suas próprias ferramentas e abordagens para a criação de interfaces.
* Arquivos de interface nativos: Para iOS, eram xib/storyboards, para arquivos de marcação Android-xml. Esses arquivos são um layout wysiwyg perfeito para pixels, que é exibido no rádio como no editor. Essa abordagem não desapareceu em nenhum lugar, continua a se desenvolver, integrando -se com quadros declarativos modernos. Por exemplo, SwiftUi na Apple e Jetpack compor no Android partiu no caminho de um código puramente declarativo, mas, ao mesmo tempo, manteve a oportunidade de usar um layout clássico.
* Soluções híbridas: Em projetos reais, é usada uma combinação de abordagens. Por exemplo, a estrutura básica do aplicativo pode ser implementada declarativamente e, para específicos, exigindo posicionamento preciso de elementos, métodos imperativos de nível inferior, podem ser usados ou componentes nativos desenvolvidos levando em consideração as especificidades da plataforma.
Do monólito à adaptabilidade: como a evolução dos dispositivos formou uma milha declarativa
O mundo das interfaces digitais passou por tremendas mudanças nas últimas décadas. De computadores estacionários com licenças fixas, chegamos à era do crescimento exponencial da variedade de dispositivos de usuário . Hoje, nossos aplicativos devem funcionar igualmente bem em:
* smartphones de todos os fatores de forma e tamanhos de tela.
* comprimidos com seus modos de orientação exclusivos e uma tela separada.
* Laptops e desktops com várias licenças de monitores.
* TVs e centros de mídia , controlados remotamente. Vale ressaltar que, mesmo para as TVs, cujas observações podem ser simples como Apple TV Remote com um mínimo de botões, ou vice -versa, sobrecarregados com muitas funções, os requisitos modernos para interfaces são tais que o código não exija adaptação específica para esses recursos de entrada. A interface deve funcionar “como se por si só”, sem uma descrição adicional do que “como” interagir com um controle remoto específico.
* relógios inteligentes e dispositivos vestíveis com telas minimalistas.
* Capacetes de realidade virtual (VR) , exigindo uma abordagem completamente nova para uma interface espacial.
* Dispositivos de realidade aumentada (AR) , aplicando informações sobre o mundo real.
* Informações de automóveis e sistemas de entretenimento .
* E até eletrodomésticos : de geladeiras com telas sensoriais e máquinas de lavar com displays interativos para fornos e sistemas inteligentes da casa inteligente.
Cada um desses dispositivos possui seus próprios recursos exclusivos: dimensões físicas, proporção de partes, densidade de pixels, métodos de entrada (tela de toque, mouse, controladores, gestos, comandos vocais) e, principalmente, as sutilezas do ambiente do usuário . Por exemplo, um shlesh de VR requer uma imersão profunda e um trabalho intuitivo e rápido do smartphone em movimento, enquanto a interface da geladeira deve ser tão simples e grande para navegação rápida.
Abordagem clássica: o ônus de apoiar interfaces individuais
Na era do domínio dos desktops e dos primeiros dispositivos móveis, o negócio usual era a criação e o suporte de arquivos de interface individuais ou mesmo um código de interface completamente separado para cada plataforma .
* O desenvolvimento em iOS geralmente exigia o uso de storyboards ou arquivos XIB no Xcode, escrevendo código no Objective-C ou Swift.
* Para Android Os arquivos de marcação XML e o código em Java ou Kotlin foram criados.
* Interfaces da Web ativadas em HTML/CSS/JavaScript.
* Para aplicativos C ++ Em várias plataformas de desktop, foram usadas suas estruturas e ferramentas específicas:
* Em Windows Estes foram MFC (Microsoft Foundation Classes), API Win32 com elementos de desenho manual ou usando arquivos de recursos para janelas de diálogo e elementos de controle.
* Cacau (Objective-C/Swift) ou A API de carbono antigo para controle direto da interface gráfica foram usados no macOS .
* Nos sistemas Linux/UNIX , bibliotecas como GTK+ ou QT foram frequentemente usadas, o que forneceu seu conjunto de widgets e mecanismos para criar interfaces, geralmente por meio de arquivos de marcação do tipo XML (por exemplo, arquivos .ui no designer QT) ou criação de software direto de elementos.
Essa abordagem garantiu o controle máximo sobre cada plataforma, permitindo que você levasse em consideração todos os seus recursos específicos e elementos nativos. No entanto, ele teve uma enorme desvantagem: duplicação de esforços e enormes custos de apoio . A menor mudança no design ou funcionalidade exigia a introdução de um direito a vários, de fato, bases de código independentes. Isso se transformou em um pesadelo real para as equipes de desenvolvedores, diminuindo a desaceleração da produção de novas funções e aumentando a probabilidade de erros.
Miles declarativos: um único idioma para a diversidade
Foi uma resposta a essa rápida complicação que as milhas declarativas apareceram como o paradigma dominante. Framws como React, Vue, Swiftui, Jetpack compõem e outros não são apenas uma nova maneira de escrever código, mas uma mudança fundamental no pensamento.
A idéia principal da abordagem declarativa : em vez de dizer o sistema “como” desenhar todos os elementos (imperativos), descrevemos “o que” queremos ver (declarativo). Definimos as propriedades e a condição da interface, e a estrutura decide como exibi -la melhor em um dispositivo específico.
Isso se tornou possível graças às seguintes vantagens importantes:
1. Abstração dos detalhes da plataforma: O Fraimvorki declarativo é especialmente projetado para esquecer os detalhes de baixo nível de cada plataforma. O desenvolvedor descreve os componentes e seus relacionamentos em um nível mais alto de abstração, usando um único código transferido.
2. Adaptação e capacidade de resposta automáticas: Freimvorki assume a responsabilidade pela escala automática, alterando o layout e a adaptação dos elementos para diferentes tamanhos de telas, densidade de pixels e métodos de entrada. Isso é conseguido através do uso de sistemas de layout flexíveis, como Flexbox ou grade, e conceitos semelhantes a “pixels lógicos” ou “dp”.
3. Consistência da experiência do usuário: Apesar das diferenças externas, a abordagem declarativa permite manter uma única lógica de comportamento e interação em toda a família de dispositivos. Isso simplifica o processo de teste e fornece uma experiência mais previsível do usuário.
4. A aceleração do desenvolvimento e redução de custos: Com o mesmo código capaz de trabalhar em muitas plataformas, significativamente é reduzido pelo tempo e custo de desenvolvimento e suporte . As equipes podem se concentrar na funcionalidade e no design, e não na reescrita repetida na mesma interface.
5. prontidão para o futuro: A capacidade de abstrair das especificidades dos dispositivos atuais torna o código declarativo mais mais resistente ao surgimento de novos tipos de dispositivos e fatores de forma . O Freimvorki pode ser atualizado para oferecer suporte a novas tecnologias, e seu código já escrito receberá esse suporte é relativamente perfeito.
Conclusão
A milha declarativa não é apenas uma tendência de moda, mas a etapa evolutiva necessária causada pelo rápido desenvolvimento de dispositivos de usuário, incluindo a esfera da a Internet das Coisas (IoT) e eletrodomésticos inteligentes. Ele permite que desenvolvedores e designers criem interfaces complexas, adaptativas e uniformes, sem se afogar em inúmeras implementações específicas para cada plataforma. A transição do controle imperativo sobre cada pixel para a descrição declarativa do estado desejado é um reconhecimento de que no mundo das interfaces futuras deve ser flexível, transferido e intuitivo independentemente de qual tela são exibidas.
Programadores, designers e usuários precisam aprender a viver neste novo mundo. Os detalhes extras do pixel perfeito, projetados para um dispositivo ou resolução específica, levam a custos de tempo desnecessários para desenvolvimento e suporte. Além disso, esses layouts severos podem simplesmente não funcionar em dispositivos com interfaces não padrão, como TVs de entrada limitadas, mudanças de VR e AR, bem como outros dispositivos do futuro, que ainda nem conhecemos hoje. Flexibilidade e adaptabilidade – essas são as chaves para a criação de interfaces bem -sucedidas no mundo moderno.
Com o desenvolvimento de grandes modelos de idiomas (LLM), como ChatGPT, mais e mais desenvolvedores os usam para gerar código, projetar arquitetura e acelerar a integração. No entanto, com a aplicação prática, torna -se perceptível: os princípios clássicos da arquitetura – sólidos, secos, limpos – se dão mal com as peculiaridades da gordura do LLM.
Isso não significa que os princípios estejam desatualizados – pelo contrário, eles funcionam perfeitamente com o desenvolvimento manual. Mas com o LLM, a abordagem deve ser adaptada.
Por que o LLM não pode lidar com os princípios arquitetônicos
Encapsulamento
O incapsolamento requer a compreensão dos limites entre partes do sistema, conhecimento sobre as intenções do desenvolvedor, bem como seguem restrições estritas de acesso. O LLM geralmente simplifica a estrutura, torna o Fields público sem motivo ou duplica a implementação. Isso torna o código mais vulnerável a erros e viola os limites arquitetônicos.
Resumos e interfaces
Os padrões de design, como uma fábrica ou estratégia abstrata, requerem uma visão holística do sistema e entender sua dinâmica. Os modelos podem criar uma interface sem um objetivo claro sem garantir sua implementação ou violar a conexão entre as camadas. O resultado é uma arquitetura excessiva ou não funcional.
seco (não se repete)
O LLM não procura minimizar o código de repetição – pelo contrário, é mais fácil para eles duplicarem blocos do que fazer lógica geral. Embora eles possam oferecer refatoração mediante solicitação, os modelos padrão tendem a gerar fragmentos “auto -suficientes”, mesmo que isso leve à redundância.
Arquitetura limpa
A limpeza implica uma hierarquia estrita, independência das estruturas, dependência direcionada e conexão mínima entre as camadas. A geração de tal estrutura requer uma compreensão global do sistema – e o trabalho de LLM no nível de probabilidade de palavras, não a integridade arquitetônica. Portanto, o código é misturado, com a violação das direções da dependência e uma divisão simplificada em níveis.
O que funciona melhor ao trabalhar com LLM
Molhado em vez de seco
A abordagem molhada (escreva tudo duas vezes) é mais prática para trabalhar com o LLM. A duplicação do código não requer contexto do modelo de retenção, o que significa que o resultado é previsível e é mais fácil de corretamente correto. Também reduz a probabilidade de conexões e bugs não óbvios.
Além disso, a duplicação ajuda a compensar a lembrança curta do modelo: se um certo fragmento de lógica for encontrado em vários lugares, é mais provável que o LLM leve em consideração com mais geração. Isso simplifica o acompanhamento e aumenta a resistência ao “esquecimento”.
estruturas simples em vez de encapsulamento
Evitando encapsulamento complexo e confiar na transmissão direta de dados entre as partes do código, você pode simplificar bastante a geração e a depuração. Isto é especialmente verdade com um rápido desenvolvimento iterativo ou criação de MVP.
Arquitetura simplificada
Uma estrutura simples e plana do projeto com uma quantidade mínima de dependências e abstrações fornece um resultado mais estável durante a geração. O modelo adapta esse código mais fácil e menos frequentemente viola as conexões esperadas entre os componentes.
Integração SDK – manualmente confiável
A maioria dos modelos de idiomas é treinada em versões desatualizadas de documentação. Portanto, ao gerar instruções para a instalação do SDK, os erros geralmente aparecem: comandos desatualizados, parâmetros irrelevantes ou links para recursos inacessíveis. Mostra de prática: é melhor usar documentação oficial e ajuste manual, deixando o LLM uma função auxiliar – por exemplo, gerando um código de modelo ou adaptação de configurações.
Por que os princípios ainda funcionam – mas com desenvolvimento manual
É importante entender que as dificuldades de sólido, seco e limpo dizem respeito à código de código através do LLM. Quando o desenvolvedor escreve o código manualmente, esses princípios continuam demonstrando seu valor: reduzem a conexão, simplificam o suporte, aumentam a legibilidade e a flexibilidade do projeto.
Isso se deve ao fato de que o pensamento humano é propenso à generalização. Estamos procurando padrões, trazemos a lógica repetida para entidades individuais, criamos padrões. Provavelmente, esse comportamento tem raízes evolutivas: reduzir a quantidade de informações salva recursos cognitivos.
O LLM age de maneira diferente: eles não experimentam cargas do volume de dados e não se esforçam para economizar. Pelo contrário, é mais fácil para eles trabalhar com informações fragmentadas e duplicadas do que construir e manter abstrações complexas. É por isso que é mais fácil lidar com o código sem encapsulamento, com estruturas repetidas e severidade arquitetônica mínima.
Conclusão
Modelos de idiomas grandes são uma ferramenta útil no desenvolvimento, especialmente nos estágios iniciais ou ao criar um código auxiliar. Mas é importante adaptar a abordagem a eles: simplificar a arquitetura, limitar a abstração, evitar dependências complexas e não confiar nelas ao configurar o SDK.
Os princípios de sólidos, secos e limpos ainda são relevantes, mas dão o melhor efeito nas mãos de uma pessoa. Ao trabalhar com a LLM, é razoável usar um estilo prático e simplificado que permite obter um código confiável e compreensível que seja fácil de finalizar manualmente. E onde LLM esquece – a duplicação do código o ajuda a se lembrar.
Neste post vou descrever como portei o motor de jogo Surreal Engine para WebAssembly.
Motor Surreal – um motor de jogo que implementa a maior parte das funcionalidades do Unreal Engine 1, jogos famosos neste motor – Torneio Unreal 99, Unreal, Deus Ex, Imortal. Refere-se a mecanismos clássicos que funcionavam principalmente em um ambiente de execução de thread único.
Inicialmente tive a ideia de assumir um projeto que não conseguiria concluir em um prazo razoável, mostrando assim aos meus seguidores do Twitch que existem projetos que nem eu consigo realizar. Durante minha primeira transmissão, de repente percebi que a tarefa de portar o Surreal Engine C++ para WebAssembly usando Emscripten é viável.
O controle, como no original, é feito através das setas do teclado. Em seguida, pretendo adaptá-lo para controle móvel (tachi), adicionando iluminação correta e outros recursos gráficos da renderização do Unreal Tournament 99.
Por onde começar?
A primeira coisa que quero dizer é que qualquer projeto pode ser portado de C++ para WebAssembly usando Emscripten, a única dúvida é quão completa será a funcionalidade. Escolha um projeto cujas portas de biblioteca já estejam disponíveis para Emscripten, no caso do Surreal Engine, você tem muita sorte, pois o mecanismo usa as bibliotecas SDL 2, OpenAL – ambos foram portados para o Emscripten. No entanto, Vulkan é usado como uma API gráfica, que atualmente não está disponível para HTML5, o trabalho está em andamento para implementar WebGPU, mas também está em fase de rascunho, e também não se sabe quão simples será a porta adicional de Vulkan para WebGPU , depois de totalmente padronizado. Portanto, tive que escrever minha própria renderização básica OpenGL-ES/WebGL para Surreal Engine.
Construindo o projeto
Construir sistema no Surreal Engine – CMake, que também simplifica a portabilidade, porque Emscripten fornece aos seus construtores nativos – emcmake, emmake.
O porte do Surreal Engine foi baseado no código do meu último jogo em WebGL/OpenGL ES e C++ chamado Death-Mask, por isso o desenvolvimento foi muito mais simples, eu tinha todos os build flags necessários comigo e exemplos de código.
Um dos pontos mais importantes em CMakeLists.txt são os sinalizadores de construção do Emscripten. Abaixo está um exemplo do arquivo do projeto:
Em seguida, prepararemos o índice .html , que inclui o pré-carregador do sistema de arquivos do projeto. Para fazer upload para a web, usei o Unreal Tournament Demo versão 338. Como você pode ver no arquivo CMake, a pasta do jogo descompactada foi adicionada ao diretório de construção e vinculada como um arquivo de pré-carregamento para Emscripten.
Alterações no código principal
Então foi necessário alterar o loop do jogo, você não pode executar um loop infinito, isso faz com que o navegador congele, em vez disso você precisa usar emscripten_set_main_loop, escrevi sobre esse recurso em minha nota de 2017 “< a href="https://demensdeum.com /blog/ru/2017/03/29/porting-sdl-c-game-to-html5-emscripten/" rel="noopener" target="_blank">Portar jogo SDL C++ para HTML5 (Emscripten)”
Alteramos o código para sair do loop while para if, então exibimos a classe principal do mecanismo de jogo, que contém o loop do jogo, no escopo global, e escrevemos uma função global que chamará a etapa do loop do jogo do objeto global :
Depois disso, você precisa ter certeza de que não há threads em segundo plano no aplicativo, se houver, então prepare-se para reescrevê-los para execução de thread único ou use a biblioteca phtread no Emscripten.
O thread de segundo plano no Surreal Engine é usado para reproduzir música, os dados vêm do thread do mecanismo principal sobre a faixa atual, a necessidade de tocar música ou sua ausência, então o thread de segundo plano recebe um novo estado por meio de um mutex e começa a tocar nova música ou pausa-o. O fluxo de fundo também é usado para armazenar música em buffer durante a reprodução.
Minhas tentativas de construir o Surreal Engine para Emscripten com pthread não tiveram sucesso, porque as portas SDL2 e OpenAL foram construídas sem suporte a pthread e eu não queria reconstruí-las por causa da música. Portanto, transferi a funcionalidade do fluxo de música de fundo para execução de thread único usando um loop. Ao remover as chamadas pthread do código C++, movi o buffer e a reprodução da música para o thread principal, para que não houvesse atrasos, aumentei o buffer em alguns segundos.
A seguir, descreverei implementações específicas de gráficos e som.
Vulkan não é compatível!
Sim, Vulkan não é compatível com HTML5, embora todos os folhetos de marketing apresentem suporte multiplataforma e ampla plataforma como a principal vantagem do Vulkan. Por esse motivo, tive que escrever meu próprio renderizador gráfico básico para um tipo OpenGL simplificado – – ES, é usado em dispositivos móveis, às vezes não contém os recursos modernos do OpenGL moderno, mas porta muito bem para WebGL, que é exatamente o que o Emscripten implementa. A escrita da renderização básica de blocos, renderização bsp, para a exibição da GUI mais simples e renderização de modelos + mapas foi concluída em duas semanas. Esta foi talvez a parte mais difícil do projeto. Ainda há muito trabalho pela frente para implementar todas as funcionalidades da renderização do Surreal Engine, portanto, qualquer ajuda dos leitores é bem-vinda na forma de código e solicitações pull.
OpenAL compatível!
Grande sorte é que o Surreal Engine usa OpenAL para saída de áudio. Depois de escrever um hello world simples em OpenAL e montá-lo em WebAssembly usando Emscripten, ficou claro para mim como tudo era simples e comecei a portar o som.
Após várias horas de depuração, ficou óbvio que a implementação OpenAL do Emscripten possui vários bugs, por exemplo, ao inicializar a leitura do número de canais mono, o método retornou um número infinito, e após tentar inicializar um vetor de tamanho infinito, C++ trava com a exceção vector::length_error.
Conseguimos contornar isso codificando o número de canais mono para 2048:
O Surreal Engine atualmente não suporta jogos online, jogar com bots é compatível, mas precisamos de alguém para escrever IA para esses bots. Teoricamente, você pode implementar um jogo em rede no WebAssembly/Emscripten usando Websockets.
Conclusão
Concluindo, gostaria de dizer que a portabilidade do Surreal Engine acabou sendo bastante tranquila devido ao uso de bibliotecas para as quais existem portas Emscripten, bem como à minha experiência anterior na implementação de um jogo em C++ para WebAssembly em Emscripten. Abaixo estão links para fontes de conhecimento e repositórios sobre o tema. M-M-M-MATANÇA DE MONSTRO!
Além disso, se você quiser ajudar o projeto, de preferência com código de renderização WebGL/OpenGL ES, escreva para mim no Telegram: https://t.me/demenscave
Comprei recentemente um teclado USB Getorix GK-45X muito barato com retroiluminação RGB. Ao conectá-lo a um MacBook Pro com processador M1, ficou claro que a luz de fundo RGB não funcionava. Mesmo pressionando a combinação mágica Fn + Scroll Lock não conseguiu ligar a luz de fundo; apenas o nível de luz de fundo da tela do MacBook mudou. Existem várias soluções para este problema, nomeadamente OpenRGB (não funciona), HID LED Test (não funciona). Apenas o utilitário kvmswitch funcionou: https://github.com/stoutput/OSX-KVM
Você precisa baixá-lo do GitHub e permitir que ele seja executado no terminal no painel Segurança das Configurações do Sistema. Pelo que entendi pela descrição, após iniciar o utilitário, ele pressiona Fn + Scroll Lock, ligando/desligando assim a luz de fundo do teclado.
Classificação em árvore – classificação usando uma árvore de pesquisa binária. Complexidade de tempo – O(n²). Nessa árvore, cada nó da esquerda tem números menores que o nó, à direita há mais que o nó, ao vir da raiz e imprimir os valores da esquerda para a direita, obtemos uma lista ordenada de números . Surpreendente, certo?
Considere o diagrama de árvore de pesquisa binária:
Tente ler manualmente os números começando pelo penúltimo nó esquerdo do canto inferior esquerdo, para cada nó à esquerda – um nó – à direita.
Ficará assim:
Penúltimo nó no canto inferior esquerdo – 3.
Tem um ramo esquerdo – 1.
Pegue este número (1)
Em seguida, pegamos o vértice 3 (1, 3)
À direita está o ramo 6, mas contém ramos. Portanto, lemos da mesma maneira.
Ramo esquerdo do nó 6 número 4 (1, 3, 4)
O próprio nó é 6 (1, 3, 4, 6)
Direita 7 (1, 3, 4, 6, 7)
Vá até o nó raiz – 8 (1,3, 4,6, 7, 8)
Imprimimos tudo à direita por analogia
Obtemos a lista final – 1, 3, 4, 6, 7, 8, 10, 13, 14
Para implementar o algoritmo em código, você precisará de duas funções:
Montando uma árvore de pesquisa binária
Imprimindo a árvore de pesquisa binária na ordem correta
A árvore binária de busca é montada da mesma forma que é lida, um número é anexado a cada nó à esquerda ou à direita, dependendo se é menor ou maior.
Exemplo em Lua:
function Node:new(value, lhs, rhs)
output = {}
setmetatable(output, self)
self.__index = self
output.value = value
output.lhs = lhs
output.rhs = rhs
output.counter = 1
return output
end
function Node:Increment()
self.counter = self.counter + 1
end
function Node:Insert(value)
if self.lhs ~= nil and self.lhs.value > value then
self.lhs:Insert(value)
return
end
if self.rhs ~= nil and self.rhs.value < value then
self.rhs:Insert(value)
return
end
if self.value == value then
self:Increment()
return
elseif self.value > value then
if self.lhs == nil then
self.lhs = Node:new(value, nil, nil)
else
self.lhs:Insert(value)
end
return
else
if self.rhs == nil then
self.rhs = Node:new(value, nil, nil)
else
self.rhs:Insert(value)
end
return
end
end
function Node:InOrder(output)
if self.lhs ~= nil then
output = self.lhs:InOrder(output)
end
output = self:printSelf(output)
if self.rhs ~= nil then
output = self.rhs:InOrder(output)
end
return output
end
function Node:printSelf(output)
for i=0,self.counter-1 do
output = output .. tostring(self.value) .. " "
end
return output
end
function PrintArray(numbers)
output = ""
for i=0,#numbers do
output = output .. tostring(numbers[i]) .. " "
end
print(output)
end
function Treesort(numbers)
rootNode = Node:new(numbers[0], nil, nil)
for i=1,#numbers do
rootNode:Insert(numbers[i])
end
print(rootNode:InOrder(""))
end
numbersCount = 10
maxNumber = 9
numbers = {}
for i=0,numbersCount-1 do
numbers[i] = math.random(0, maxNumber)
end
PrintArray(numbers)
Treesort(numbers)
Важный нюанс что для чисел которые равны вершине придумано множество интересных механизмов подцепления к ноде, я же просто добавил счетчик к классу вершины, при распечатке числа возвращаются по счетчику.
Classificação por bucket – classificação por buckets. O algoritmo é semelhante à classificação por contagem, com a diferença de que os números são coletados em intervalos de “baldes”, então os baldes são classificados usando qualquer outro algoritmo de classificação suficientemente produtivo, e a etapa final é desdobrar os “baldes” um por um, resultando em uma lista ordenada
.
A complexidade de tempo do algoritmo é O(nk). O algoritmo funciona em tempo linear para dados que obedecem a uma lei de distribuição uniforme. Simplificando, os elementos devem estar em um determinado intervalo, sem “picos”, por exemplo, números de 0,0 a 1,0. Se entre esses números houver 4 ou 999, então, de acordo com as leis do pátio, essa linha não será mais considerada “par”.
Exemplo de implementação em Julia:
buckets = Vector{Vector{Int}}()
for i in 0:bucketsCount - 1
bucket = Vector{Int}()
push!(buckets, bucket)
end
maxNumber = maximum(numbers)
for i in 0:length(numbers) - 1
bucketIndex = 1 + Int(floor(bucketsCount * numbers[1 + i] / (maxNumber + 1)))
push!(buckets[bucketIndex], numbers[1 + i])
end
for i in 0:length(buckets) - 1
bucketIndex = 1 + i
buckets[bucketIndex] = sort(buckets[bucketIndex])
end
flat = [(buckets...)...]
print(flat, "\n")
end
numbersCount = 10
maxNumber = 10
numbers = rand(1:maxNumber, numbersCount)
print(numbers,"\n")
bucketsCount = 10
bucketSort(numbers, bucketsCount)
На производительность алгоритма также влияет число ведер, для большего количества чисел лучше взять большее число ведер (Algorithms in a nutshell by George T. Heineman)
Classificação de raiz – classificação de raiz. O algoritmo é semelhante à classificação por contagem, pois não há comparação de elementos; em vez disso, os elementos são agrupados *caractere por caractere* em *baldes* (baldes), o balde é selecionado pelo índice do caractere numérico atual. Complexidade de tempo – O(nd).
Funciona mais ou menos assim:
A entrada serão os números 6, 12, 44, 9
Criaremos 10 grupos de listas (0-9), nos quais adicionaremos/classificaremos números pouco a pouco.
Próximo:
Inicie um loop com o contador i até o número máximo de caracteres no número
Pelo índice i da direita para a esquerda obtemos um símbolo para cada número; se não houver símbolo, então assumimos que é zero
;
Converta o símbolo em um número
Selecione um intervalo por número de índice e coloque o número inteiro lá
Depois de terminar de pesquisar os números, converta todos os grupos novamente em uma lista de números
Obter números classificados por classificação
Repita até que todos os dígitos desapareçam
Exemplo de classificação Radix em Scala:
import scala.util.Random.nextInt
object RadixSort {
def main(args: Array[String]) = {
var maxNumber = 200
var numbersCount = 30
var maxLength = maxNumber.toString.length() - 1
var referenceNumbers = LazyList.continually(nextInt(maxNumber + 1)).take(numbersCount).toList
var numbers = referenceNumbers
var buckets = List.fill(10)(ListBuffer[Int]())
for( i <- 0 to maxLength) { numbers.foreach( number => {
var numberString = number.toString
if (numberString.length() > i) {
var index = numberString.length() - i - 1
var character = numberString.charAt(index).toString
var characterInteger = character.toInt
buckets.apply(characterInteger) += number
}
else {
buckets.apply(0) += number
}
}
)
numbers = buckets.flatten
buckets.foreach(x => x.clear())
}
println(referenceNumbers)
println(numbers)
println(s"Validation result: ${numbers == referenceNumbers.sorted}")
}
}
O algoritmo também possui uma versão para execução paralela, por exemplo em uma GPU; Há também uma opção de classificação, que deve sermuito interessante e realmente de tirar o fôlego!
Heapsort – classificação em pirâmide. Complexidade de tempo do algoritmo – O (n log n), rápido, certo? Eu chamaria isso de classificação de classificação de pedras que caem. Parece-me que a maneira mais fácil de explicar é visualmente.
A entrada é uma lista de números, por exemplo:
5, 0, 7, 2, 3, 9, 4
Da esquerda para a direita, uma estrutura de dados é criada – uma árvore binária, ou como eu chamo – pirâmide. Os elementos da pirâmide podem ter no máximo dois elementos filhos, mas apenas um elemento superior.
Vamos fazer uma árvore binária:
⠀⠀5
⠀0⠀7
2 3 9 4
Se você olhar a pirâmide por muito tempo, verá que são apenas números de uma matriz, vindo um após o outro, o número de elementos em cada andar é multiplicado por dois.
A seguir, a diversão começa; vamos classificar a pirâmide de baixo para cima usando o método das pedras caindo (heapify). A classificação poderia ser iniciada a partir do último andar (2 3 9 4), mas não adianta porque não há piso abaixo onde você possa cair.
Portanto, começamos a descartar elementos do penúltimo andar (0 7)
⠀⠀5
⠀0⠀7
2 3 9 4
O primeiro elemento a cair é selecionado da direita, no nosso caso é 7, então olhamos o que está abaixo dele, e abaixo dele estão 9 e 4, nove é maior que quatro, e também nove é maior que Sete! Colocamos 7 em 9 e colocamos 9 no lugar 7.
⠀⠀5
⠀0⠀9
2 3 7 4
A seguir, entendemos que o sete não tem onde cair, passamos para o número 0, que está localizado no penúltimo andar à esquerda:
⠀⠀5
⠀0⠀9
2 3 7 4
Vamos ver o que há por baixo – 2 e 3, dois é menor que três, três é maior que zero, então trocamos zero por três:
⠀⠀5
⠀3⠀9
2 0 7 4
Quando chegar ao final do andar, vá para o andar de cima e largue tudo lá, se puder.
O resultado é uma estrutura de dados – um heap, ou seja, max heap, porque no topo está o maior elemento:
⠀⠀9
⠀3⠀7
2 0 5 4
Se você retornar para uma representação de array, você obterá uma lista:
[9, 3, 7, 2, 0, 5, 4]
A partir disso podemos concluir que ao trocar o primeiro e o último elemento, obtemos o primeiro número na posição final ordenada, ou seja, 9 deve estar no final da lista ordenada, troque de lugar:
[4, 3, 7, 2, 0, 5, 9]
Vejamos uma árvore binária:
⠀⠀4
⠀3⠀7
2 0 5 9
O resultado é uma situação em que a parte inferior da árvore está ordenada, basta colocar 4 na posição correta, repetir o algoritmo, mas não levar em consideração os números já ordenados, nomeadamente 9:
⠀⠀4
⠀3⠀7
2 0 5 9
⠀⠀7
⠀3⠀4
2 0 5 9
⠀⠀7
⠀3⠀5
2 0 4 9
Acontece que nós, tendo perdido 4, aumentamos o próximo maior número depois de 9 – 7. Troque o último número não classificado (4) e o maior número (7)
⠀⠀4
⠀3⠀5
2 0 7 9
Acontece que agora temos dois números na posição final correta:
4, 3, 5, 2, 0, 7, 9
Em seguida repetimos o algoritmo de classificação, ignorando os já classificados, no final obtemos um heap tipo:
⠀⠀0
⠀2⠀3
4 5 7 9
Ou como uma lista:
0, 2, 3, 4, 5, 7, 9
Implementação
O algoritmo geralmente é dividido em três funções:
Criando uma pilha
Algoritmo de peneiração (heapify)
Substituindo o último elemento não classificado e o primeiro
O heap é criado percorrendo a penúltima linha da árvore binária usando a função heapify, da direita para a esquerda, até o final do array. A seguir no ciclo, é feita a primeira substituição de números, após a qual o primeiro elemento cai/permanece no lugar, como resultado o elemento maior cai em primeiro lugar, o ciclo é repetido com uma diminuição de participantes em um, porque após cada passagem, os números classificados permanecem no final da lista.
Exemplo de Heapsort em Ruby:
module Colors
BLUE = "\033[94m"
RED = "\033[31m"
STOP = "\033[0m"
end
def heapsort(rawNumbers)
numbers = rawNumbers.dup
def swap(numbers, from, to)
temp = numbers[from]
numbers[from] = numbers[to]
numbers[to] = temp
end
def heapify(numbers)
count = numbers.length()
lastParentNode = (count - 2) / 2
for start in lastParentNode.downto(0)
siftDown(numbers, start, count - 1)
start -= 1
end
if DEMO
puts "--- heapify ends ---"
end
end
def siftDown(numbers, start, rightBound)
cursor = start
printBinaryHeap(numbers, cursor, rightBound)
def calculateLhsChildIndex(cursor)
return cursor * 2 + 1
end
def calculateRhsChildIndex(cursor)
return cursor * 2 + 2
end
while calculateLhsChildIndex(cursor) <= rightBound
lhsChildIndex = calculateLhsChildIndex(cursor)
rhsChildIndex = calculateRhsChildIndex(cursor)
lhsNumber = numbers[lhsChildIndex]
biggerChildIndex = lhsChildIndex
if rhsChildIndex <= rightBound
rhsNumber = numbers[rhsChildIndex]
if lhsNumber < rhsNumber
biggerChildIndex = rhsChildIndex
end
end
if numbers[cursor] < numbers[biggerChildIndex]
swap(numbers, cursor, biggerChildIndex)
cursor = biggerChildIndex
else
break
end
printBinaryHeap(numbers, cursor, rightBound)
end
printBinaryHeap(numbers, cursor, rightBound)
end
def printBinaryHeap(numbers, nodeIndex = -1, rightBound = -1)
if DEMO == false
return
end
perLineWidth = (numbers.length() * 4).to_i
linesCount = Math.log2(numbers.length()).ceil()
xPrinterCount = 1
cursor = 0
spacing = 3
for y in (0..linesCount)
line = perLineWidth.times.map { " " }
spacing = spacing == 3 ? 4 : 3
printIndex = (perLineWidth / 2) - (spacing * xPrinterCount) / 2
for x in (0..xPrinterCount - 1)
if cursor >= numbers.length
break
end
if nodeIndex != -1 && cursor == nodeIndex
line[printIndex] = "%s%s%s" % [Colors::RED, numbers[cursor].to_s, Colors::STOP]
elsif rightBound != -1 && cursor > rightBound
line[printIndex] = "%s%s%s" % [Colors::BLUE, numbers[cursor].to_s, Colors::STOP]
else
line[printIndex] = numbers[cursor].to_s
end
cursor += 1
printIndex += spacing
end
print line.join()
xPrinterCount *= 2
print "\n"
end
end
heapify(numbers)
rightBound = numbers.length() - 1
while rightBound > 0
swap(numbers, 0, rightBound)
rightBound -= 1
siftDown(numbers, 0, rightBound)
end
return numbers
end
numbersCount = 14
maximalNumber = 10
numbers = numbersCount.times.map { Random.rand(maximalNumber) }
print numbers
print "\n---\n"
start = Time.now
sortedNumbers = heapsort(numbers)
finish = Time.now
heapSortTime = start - finish
start = Time.now
referenceSortedNumbers = numbers.sort()
finish = Time.now
referenceSortTime = start - finish
print "Reference sort: "
print referenceSortedNumbers
print "\n"
print "Reference sort time: %f\n" % referenceSortTime
print "Heap sort: "
print sortedNumbers
print "\n"
if DEMO == false
print "Heap sort time: %f\n" % heapSortTime
else
print "Disable DEMO for performance measure\n"
end
if sortedNumbers != referenceSortedNumbers
puts "Validation failed"
exit 1
else
puts "Validation success"
exit 0
end
Esse algoritmo não é fácil de entender sem visualização, então a primeira coisa que recomendo é escrever uma função que imprima a visualização atual da árvore binária.
Recently, it turned out that users of modern Nvidia GPUs under Arch Linux do not need to use the bumblebee package at all, for example, for me it did not detect an external monitor when connected. I recommend removing the bumblebee package and all related packages, and installing prime using the instructions on the Arch Wiki.
Next, to launch all games on Steam and 3D applications, add prime-run, for Steam this is done like this prime-run %command% in additional launch options.
To check the correctness, you can use glxgears, prime-run glxgears. https://bbs.archlinux.org/viewtopic.php? pid=2048195#p2048195
Quicksort é um algoritmo de classificação de divisão e conquista. Recursivamente, peça por peça, analisamos a matriz de números, colocando os números em ordem menor e maior a partir do elemento de referência selecionado, e inserimos o próprio elemento de referência no corte entre eles. Após várias iterações recursivas, você terá uma lista ordenada. Complexidade de tempo O(n2).
Esquema:
Começamos obtendo uma lista de elementos externos, os limites de classificação. Na primeira etapa, os limites de classificação serão do início ao fim.
Verifique se os limites inicial e final não se cruzam; se isso acontecer, é hora de terminar.
Selecione algum elemento da lista e chame-o de pivô
Mova-o para a direita até o final do último índice para que não atrapalhe
Crie um contador de *números menores* ainda iguais a zero
Percorrer a lista da esquerda para a direita, até e incluindo o último índice onde o elemento de referência está localizado
Comparamos cada elemento com o de referência
Se for menor que o de referência, trocamos de acordo com o índice do contador de números menores. Aumente o contador de números menores.
Quando o loop atinge o elemento de suporte, paramos e trocamos o elemento de suporte pelo elemento de acordo com o contador de números menores.
Executamos o algoritmo separadamente para a parte menor à esquerda da lista e separadamente para a parte maior à direita da lista.
Como resultado, todas as iterações recursivas começarão a parar devido à verificação no ponto 2
Obter uma lista ordenada
Quicksort foi inventado pelo cientista Charles Anthony Richard Hoare na Universidade Estadual de Moscou. Depois de aprender russo, ele estudou tradução computacional, bem como teoria das probabilidades na escola Kolmogorov. Em 1960, devido à crise política, deixou a União Soviética.
Exemplo de implementação em Rust:
use rand::Rng;
fn swap(numbers: &mut [i64], from: usize, to: usize) {
let temp = numbers[from];
numbers[from] = numbers[to];
numbers[to] = temp;
}
fn quicksort(numbers: &mut [i64], left: usize, right: usize) {
if left >= right {
return
}
let length = right - left;
if length <= 1 {
return
}
let pivot_index = left + (length / 2);
let pivot = numbers[pivot_index];
let last_index = right - 1;
swap(numbers, pivot_index, last_index);
let mut less_insert_index = left;
for i in left..last_index {
if numbers[i] < pivot {
swap(numbers, i, less_insert_index);
less_insert_index += 1;
}
}
swap(numbers, last_index, less_insert_index);
quicksort(numbers, left, less_insert_index);
quicksort(numbers, less_insert_index + 1, right);
}
fn main() {
let mut numbers = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0];
let mut reference_numbers = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0];
let mut rng = rand::thread_rng();
for i in 0..numbers.len() {
numbers[i] = rng.gen_range(-10..10);
reference_numbers[i] = numbers[i];
}
reference_numbers.sort();
println!("Numbers {:?}", numbers);
let length = numbers.len();
quicksort(&mut numbers, 0, length);
println!("Numbers {:?}", numbers);
println!("Reference numbers {:?}", reference_numbers);
if numbers != reference_numbers {
println!("Validation failed");
std::process::exit(1);
}
else {
println!("Validation success!");
std::process::exit(0);
}
}
Se nada estiver claro, sugiro assistir ao vídeo de Rob Edwards, da Universidade de San Diego https://www.youtube.com/watch?v=ZHVk2blR45Q mostra de maneira mais simples, passo a passo, a essência e a implementação do algoritmo.
A classificação por inserção binária é uma variante da classificação por inserção na qual a posição de inserção é determinada usando pesquisa binária. A complexidade de tempo do algoritmo é O(n2)
O algoritmo funciona assim:
Um loop começa de zero até o final da lista
No loop, um número é selecionado para classificação, o número é armazenado em uma variável separada
A pesquisa binária procura o índice para inserir esse número nos números à esquerda
Uma vez encontrado o índice, os números à esquerda são deslocados uma posição para a direita, começando no índice de inserção. No processo, o número que precisa ser classificado será apagado.
O número salvo anteriormente é inserido no índice de inserção
No final do loop, a lista inteira será classificada
Durante uma pesquisa binária, é possível que o número não seja encontrado e o índice não seja retornado. Devido à peculiaridade da busca binária será encontrado o número mais próximo do buscado, então para retornar o índice será necessário compará-lo com o procurado, se o procurado for menor então o procurado deverá estar em o índice à esquerda e, se for maior ou igual, à direita.
Código Go:
import (
"fmt"
"math/rand"
"time"
)
const numbersCount = 20
const maximalNumber = 100
func binarySearch(numbers []int, item int, low int, high int) int {
for high > low {
center := (low + high) / 2
if numbers[center] < item { low = center + 1 } else if numbers[center] > item {
high = center - 1
} else {
return center
}
}
if numbers[low] < item {
return low + 1
} else {
return low
}
}
func main() {
rand.Seed(time.Now().Unix())
var numbers [numbersCount]int
for i := 0; i < numbersCount; i++ {
numbers[i] = rand.Intn(maximalNumber)
}
fmt.Println(numbers)
for i := 1; i < len(numbers); i++ { searchAreaLastIndex := i - 1 insertNumber := numbers[i] insertIndex := binarySearch(numbers[:], insertNumber, 0, searchAreaLastIndex) for x := searchAreaLastIndex; x >= insertIndex; x-- {
numbers[x+1] = numbers[x]
}
numbers[insertIndex] = insertNumber
}
fmt.Println(numbers)
}
Shell Sort – uma variante da classificação por inserção com combinação preliminar de uma matriz de números.
Precisamos lembrar como funciona a classificação por inserção:
1. Um loop é iniciado do zero até o final do loop, assim o array é dividido em duas partes 2. Para a parte esquerda, um segundo loop é iniciado, comparando os elementos da direita para a esquerda, o elemento menor à direita é descartado até que um elemento menor à esquerda seja encontrado 3. No final de ambos os loops, obtemos uma lista ordenada
Era uma vez, o cientista da computação Donald Schell se perguntou como melhorar o algoritmo de classificação por inserção. Ele também teve a ideia de primeiro percorrer o array em dois ciclos, mas a uma certa distância, reduzindo gradativamente o “pente” até que ele se transforme em um algoritmo regular de ordenação por inserção. Tudo é realmente tão simples, sem armadilhas, aos dois ciclos acima acrescentamos outro, no qual vamos reduzindo gradativamente o tamanho do “pente”. A única coisa que você precisa fazer é verificar a distância ao comparar para que ela não ultrapasse o array.
Um tópico realmente interessante é escolher a sequência para alterar o comprimento da comparação a cada iteração do primeiro loop. É interessante porque o desempenho do algoritmo depende disso.
Pessoas diferentes estiveram envolvidas no cálculo da distância ideal, aparentemente, esse assunto era muito interessante para elas. Eles não poderiam simplesmente executar Ruby e chamar o algoritmo sort() mais rápido?
Em geral, essas pessoas estranhas escreveram dissertações sobre o tema do cálculo da distância/gap do “pente” para o algoritmo Shell. Simplesmente usei os resultados do trabalho deles e verifiquei 5 tipos de sequências, Hibbard, Knuth-Pratt, Chiura, Sedgwick.
import time
import random
from functools import reduce
import math
DEMO_MODE = False
if input("Demo Mode Y/N? ").upper() == "Y":
DEMO_MODE = True
class Colors:
BLUE = '\033[94m'
RED = '\033[31m'
END = '\033[0m'
def swap(list, lhs, rhs):
list[lhs], list[rhs] = list[rhs], list[lhs]
return list
def colorPrintoutStep(numbers: List[int], lhs: int, rhs: int):
for index, number in enumerate(numbers):
if index == lhs:
print(f"{Colors.BLUE}", end = "")
elif index == rhs:
print(f"{Colors.RED}", end = "")
print(f"{number},", end = "")
if index == lhs or index == rhs:
print(f"{Colors.END}", end = "")
if index == lhs or index == rhs:
print(f"{Colors.END}", end = "")
print("\n")
input(">")
def ShellSortLoop(numbers: List[int], distanceSequence: List[int]):
distanceSequenceIterator = reversed(distanceSequence)
while distance:= next(distanceSequenceIterator, None):
for sortArea in range(0, len(numbers)):
for rhs in reversed(range(distance, sortArea + 1)):
lhs = rhs - distance
if DEMO_MODE:
print(f"Distance: {distance}")
colorPrintoutStep(numbers, lhs, rhs)
if numbers[lhs] > numbers[rhs]:
swap(numbers, lhs, rhs)
else:
break
def ShellSort(numbers: List[int]):
global ShellSequence
ShellSortLoop(numbers, ShellSequence)
def HibbardSort(numbers: List[int]):
global HibbardSequence
ShellSortLoop(numbers, HibbardSequence)
def ShellPlusKnuttPrattSort(numbers: List[int]):
global KnuttPrattSequence
ShellSortLoop(numbers, KnuttPrattSequence)
def ShellPlusCiuraSort(numbers: List[int]):
global CiuraSequence
ShellSortLoop(numbers, CiuraSequence)
def ShellPlusSedgewickSort(numbers: List[int]):
global SedgewickSequence
ShellSortLoop(numbers, SedgewickSequence)
def insertionSort(numbers: List[int]):
global insertionSortDistanceSequence
ShellSortLoop(numbers, insertionSortDistanceSequence)
def defaultSort(numbers: List[int]):
numbers.sort()
def measureExecution(inputNumbers: List[int], algorithmName: str, algorithm):
if DEMO_MODE:
print(f"{algorithmName} started")
numbers = inputNumbers.copy()
startTime = time.perf_counter()
algorithm(numbers)
endTime = time.perf_counter()
print(f"{algorithmName} performance: {endTime - startTime}")
def sortedNumbersAsString(inputNumbers: List[int], algorithm) -> str:
numbers = inputNumbers.copy()
algorithm(numbers)
return str(numbers)
if DEMO_MODE:
maximalNumber = 10
numbersCount = 10
else:
maximalNumber = 10
numbersCount = random.randint(10000, 20000)
randomNumbers = [random.randrange(1, maximalNumber) for i in range(numbersCount)]
ShellSequenceGenerator = lambda n: reduce(lambda x, _: x + [int(x[-1]/2)], range(int(math.log(numbersCount, 2))), [int(numbersCount / 2)])
ShellSequence = ShellSequenceGenerator(randomNumbers)
ShellSequence.reverse()
ShellSequence.pop()
HibbardSequence = [
0, 1, 3, 7, 15, 31, 63, 127, 255, 511, 1023, 2047, 4095,
8191, 16383, 32767, 65535, 131071, 262143, 524287, 1048575,
2097151, 4194303, 8388607, 16777215, 33554431, 67108863, 134217727,
268435455, 536870911, 1073741823, 2147483647, 4294967295, 8589934591
]
KnuttPrattSequence = [
1, 4, 13, 40, 121, 364, 1093, 3280, 9841, 29524, 88573, 265720,
797161, 2391484, 7174453, 21523360, 64570081, 193710244, 581130733,
1743392200, 5230176601, 15690529804, 47071589413
]
CiuraSequence = [
1, 4, 10, 23, 57, 132, 301, 701, 1750, 4376,
10941, 27353, 68383, 170958, 427396, 1068491,
2671228, 6678071, 16695178, 41737946, 104344866,
260862166, 652155416, 1630388541
]
SedgewickSequence = [
1, 5, 19, 41, 109, 209, 505, 929, 2161, 3905,
8929, 16001, 36289, 64769, 146305, 260609, 587521,
1045505, 2354689, 4188161, 9427969, 16764929, 37730305,
67084289, 150958081, 268386305, 603906049, 1073643521,
2415771649, 4294770689, 9663381505, 17179475969
]
insertionSortDistanceSequence = [1]
algorithms = {
"Default Python Sort": defaultSort,
"Shell Sort": ShellSort,
"Shell + Hibbard" : HibbardSort,
"Shell + Prat, Knutt": ShellPlusKnuttPrattSort,
"Shell + Ciura Sort": ShellPlusCiuraSort,
"Shell + Sedgewick Sort": ShellPlusSedgewickSort,
"Insertion Sort": insertionSort
}
for name, algorithm in algorithms.items():
measureExecution(randomNumbers, name, algorithm)
reference = sortedNumbersAsString(randomNumbers, defaultSort)
for name, algorithm in algorithms.items():
if sortedNumbersAsString(randomNumbers, algorithm) != reference:
print("Sorting validation failed")
exit(1)
print("Sorting validation success")
exit(0)
Na minha implementação, para um conjunto aleatório de números, as lacunas mais rápidas são Sedgwick e Hibbard.
meupy
Gostaria também de mencionar o analisador de tipagem estática para Python 3 – meu Deus. Ajuda a resolver os problemas inerentes às linguagens com digitação dinâmica, nomeadamente, elimina a possibilidade de colar algo onde não é necessário.
Como dizem programadores experientes, “a digitação estática não é necessária quando você tem uma equipe de profissionais”, um dia todos nos tornaremos profissionais, escreveremos código em total unidade e compreensão com as máquinas, mas por enquanto você pode usar utilitários semelhantes e linguagens de tipo estaticamente.
Classificação por seleção dupla – um subtipo de classificação por seleção, parece que deveria ser duas vezes mais rápido. O algoritmo vanilla faz um loop duplo pela lista de números, encontra o número mínimo e troca de lugar com o número atual apontado pelo loop no nível acima. A classificação por seleção dupla procura os números mínimo e máximo e, em seguida, substitui os dois dígitos apontados pelo loop no nível acima de – dois números à esquerda e à direita. Toda essa orgia termina quando os cursores dos números a serem substituídos são encontrados no meio da lista e, como resultado, os números ordenados são obtidos à esquerda e à direita do centro visual. A complexidade de tempo do algoritmo é semelhante à classificação por seleção – O(n2), mas supostamente há uma aceleração de 30 %.
Estado limítrofe
Já nesta fase, você pode imaginar o momento de uma colisão, por exemplo, quando o número do cursor esquerdo (o número mínimo) aponta para o número máximo da lista, então o número mínimo é reorganizado, o rearranjo do número máximo quebra imediatamente. Portanto, todas as implementações do algoritmo contêm a verificação de tais casos e a substituição dos índices pelos corretos. Na minha implementação, uma verificação foi suficiente:
maximalNumberIndex = minimalNumberIndex;
}
Реализация на Cito
Cito – язык либ, язык транслятор. На нем можно писать для C, C++, C#, Java, JavaScript, Python, Swift, TypeScript, OpenCL C, при этом совершенно ничего не зная про эти языки. Исходный код на языке Cito транслируется в исходный код на поддерживаемых языках, далее можно использовать как библиотеку, либо напрямую, исправив сгенеренный код руками. Эдакий Write once – translate to anything.
Double Selection Sort на cito:
{
public static int[] sort(int[]# numbers, int length)
{
int[]# sortedNumbers = new int[length];
for (int i = 0; i < length; i++) {
sortedNumbers[i] = numbers[i];
}
for (int leftCursor = 0; leftCursor < length / 2; leftCursor++) {
int minimalNumberIndex = leftCursor;
int minimalNumber = sortedNumbers[leftCursor];
int rightCursor = length - (leftCursor + 1);
int maximalNumberIndex = rightCursor;
int maximalNumber = sortedNumbers[maximalNumberIndex];
for (int cursor = leftCursor; cursor <= rightCursor; cursor++) { int cursorNumber = sortedNumbers[cursor]; if (minimalNumber > cursorNumber) {
minimalNumber = cursorNumber;
minimalNumberIndex = cursor;
}
if (maximalNumber < cursorNumber) {
maximalNumber = cursorNumber;
maximalNumberIndex = cursor;
}
}
if (leftCursor == maximalNumberIndex) {
maximalNumberIndex = minimalNumberIndex;
}
int fromNumber = sortedNumbers[leftCursor];
int toNumber = sortedNumbers[minimalNumberIndex];
sortedNumbers[minimalNumberIndex] = fromNumber;
sortedNumbers[leftCursor] = toNumber;
fromNumber = sortedNumbers[rightCursor];
toNumber = sortedNumbers[maximalNumberIndex];
sortedNumbers[maximalNumberIndex] = fromNumber;
sortedNumbers[rightCursor] = toNumber;
}
return sortedNumbers;
}
}
Classificação de coqueteleira – classificação por shaker, uma variante da classificação por bolha bidirecional. O algoritmo funciona da seguinte maneira:
A direção inicial da pesquisa no loop é selecionada (geralmente da esquerda para a direita)
A seguir no loop, os números são verificados em pares
Se o próximo elemento for maior, eles serão trocados
Ao terminar, o processo de busca recomeça com a direção invertida
A busca é repetida até que não haja mais permutações
A complexidade de tempo do algoritmo é semelhante à bolha – O(n2).
If the game doesn’t start with fcntl(5) for /tmp/source_engine_2808995433.lock failed, then try deleting the /tmp/source_engine_2808995433.lock file rm /tmp/source_engine_2808995433.lock
Usually the lock file is left over from the last game session unless the game was closed naturally.
How to check?
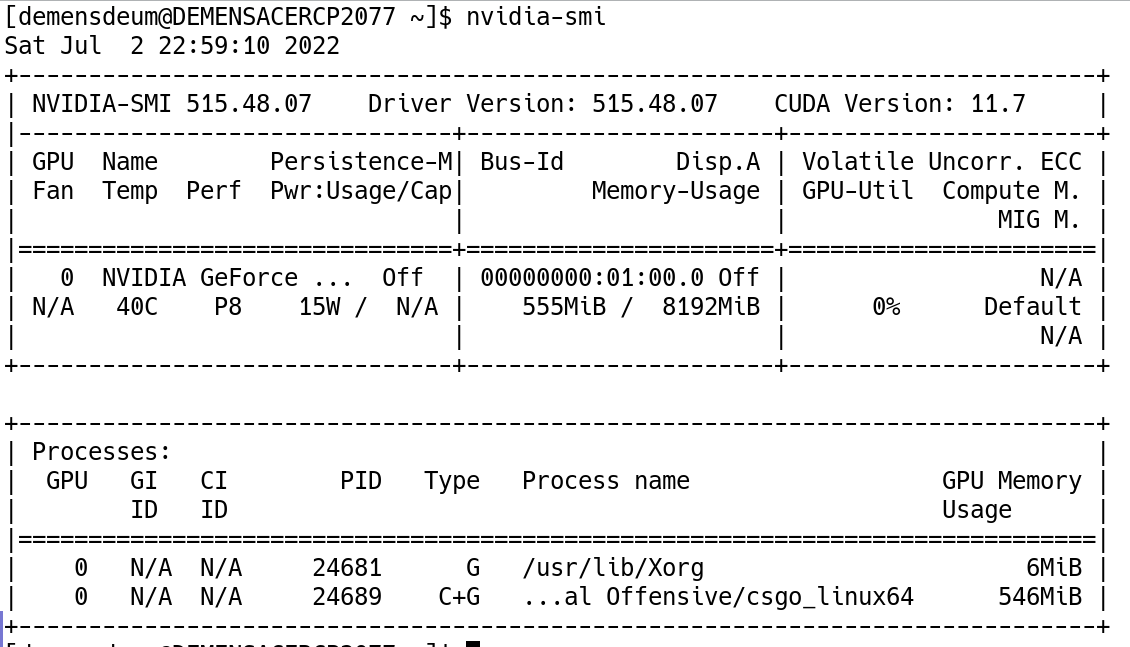
The easiest way to check the launch of applications on a discrete Nvidia graphics card is through the nvidia-smi utility:
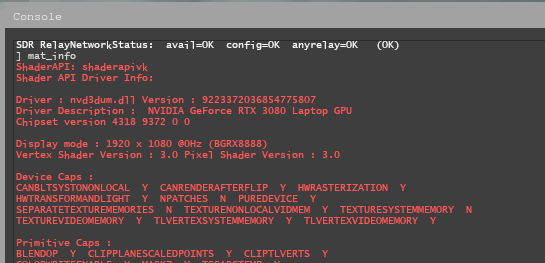
For games on the Source engine, you can check through the game console using the mat_info command:
Classificação do sono – sleep sort, outro representante de algoritmos determinísticos de classificação estranha.
Funciona assim:
Percorre uma lista de elementos
Um thread separado é lançado para cada loop
O thread fica suspenso por um período de tempo – valor do elemento e saída do valor após dormir
No final do loop, aguarde a conclusão do sono mais longo do thread e exiba a lista classificada
Exemplo de código para algoritmo de classificação de sono em C:
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
typedef struct {
int number;
} ThreadPayload;
void *sortNumber(void *args) {
ThreadPayload *payload = (ThreadPayload*) args;
const int number = payload->number;
free(payload);
usleep(number * 1000);
printf("%d ", number);
return NULL;
}
int main(int argc, char *argv[]) {
const int numbers[] = {2, 42, 1, 87, 7, 9, 5, 35};
const int length = sizeof(numbers) / sizeof(int);
int maximal = 0;
pthread_t maximalThreadID;
printf("Sorting: ");
for (int i = 0; i < length; i++) { pthread_t threadID; int number = numbers[i]; printf("%d ", number); ThreadPayload *payload = malloc(sizeof(ThreadPayload)); payload->number = number;
pthread_create(&threadID, NULL, sortNumber, (void *) payload);
if (maximal < number) {
maximal = number;
maximalThreadID = threadID;
}
}
printf("\n");
printf("Sorted: ");
pthread_join(maximalThreadID, NULL);
printf("\n");
return 0;
}
Nesta implementação usei a função usleep em microssegundos com o valor multiplicado por 1000, ou seja, em milissegundos. Complexidade de tempo do algoritmo – O(muito longo)
Classificação de Stalin – sort through, um dos algoritmos de classificação com perda de dados. O algoritmo é muito produtivo e eficiente, complexidade de tempo O(n).
Funciona assim:
Percorre o array, comparando o elemento atual com o próximo
Se o próximo elemento for menor que o atual, remova-o
Como resultado, obtemos um array ordenado em O(n)
Exemplo de saída do algoritmo:
Gulag: [1, 3, 2, 4, 6, 42, 4, 8, 5, 0, 35, 10]
Element 2 sent to Gulag
Element 4 sent to Gulag
Element 8 sent to Gulag
Element 5 sent to Gulag
Element 0 sent to Gulag
Element 35 sent to Gulag
Element 10 sent to Gulag
Numbers: [1, 3, 4, 6, 42]
Gulag: [2, 4, 8, 5, 0, 35, 10]
Código Python 3:
gulag = []
print(f"Numbers: {numbers}")
print(f"Gulag: {numbers}")
i = 0
maximal = numbers[0]
while i < len(numbers):
element = numbers[i]
if maximal > element:
print(f"Element {element} sent to Gulag")
gulag.append(element)
del numbers[i]
else:
maximal = element
i += 1
print(f"Numbers: {numbers}")
print(f"Gulag: {gulag}")
As desvantagens incluem a perda de dados, mas se avançarmos em direção a uma lista utópica, ideal e ordenada em O(n), então de que outra forma?
Classificação por seleção – algoritmo de classificação por seleção. Escolhendo o quê? Mas o número mínimo!!! Complexidade de tempo do algoritmo – O(n2)
O algoritmo funciona da seguinte maneira:
Percorremos o array em um loop da esquerda para a direita, lembre-se do índice inicial atual e do número no índice, vamos chamá-lo de número A
Dentro do loop, executamos outro para ir da esquerda para a direita, procurando algo menor que A
Quando encontramos o menor, lembramos do índice, agora o menor vira o número A
Quando o loop interno terminar, troque o número no índice inicial e o número A
Depois de passar completamente pelo loop superior, obtemos um array ordenado
Não encontrei uma implementação de Objective-C no Rosetta Code , eu mesmo escrevi:
#include <Foundation/Foundation.h>
@implementation SelectionSort
- (void)performSort:(NSMutableArray *)numbers
{
NSLog(@"%@", numbers);
for (int startIndex = 0; startIndex < numbers.count-1; startIndex++) {
int minimalNumberIndex = startIndex;
for (int i = startIndex + 1; i < numbers.count; i++) {
id lhs = [numbers objectAtIndex: minimalNumberIndex];
id rhs = [numbers objectAtIndex: i];
if ([lhs isGreaterThan: rhs]) {
minimalNumberIndex = i;
}
}
id temporary = [numbers objectAtIndex: minimalNumberIndex];
[numbers setObject: [numbers objectAtIndex: startIndex]
atIndexedSubscript: minimalNumberIndex];
[numbers setObject: temporary
atIndexedSubscript: startIndex];
}
NSLog(@"%@", numbers);
}
@end
Собрать и запустить можно либо на MacOS/Xcode, либо на любой операционной системе поддерживающей GNUstep, например у меня собирается Clang на Arch Linux.
Скрипт сборки:
Classificação de contagem – algoritmo de classificação de contagem. Em termos de? Sim! Simples assim!
O algoritmo envolve pelo menos dois arrays, o primeiro – lista de inteiros a serem classificados, segundo – uma matriz de tamanho = (número máximo – número mínimo) + 1, contendo inicialmente apenas zeros. Em seguida, os números são classificados na primeira matriz e o elemento numérico é usado para obter um índice na segunda matriz, que é incrementado em um. Depois de percorrer toda a lista, obteremos um segundo array completamente preenchido com o número de repetições dos números do primeiro. O algoritmo tem uma séria sobrecarga – a segunda matriz também contém zeros para números que não estão na primeira lista, a chamada. sobrecarga da memória
Após receber o segundo array, iteramos por ele e escrevemos a versão ordenada do número por índice, decrementando o contador a zero. Inicialmente, um contador zero é ignorado.
Um exemplo de operação não otimizada do algoritmo de classificação por contagem:
Matriz de entrada 1,9,1,4,6,4,4
Então o array a ser contado será 0,1,2,3,4,5,6,7,8,9 (número mínimo 0, máximo 9)
Com contadores totais 0,2,0,0,3,0,1,0,0,1
Matriz classificada total 1,1,4,4,4,6,9
Código do algoritmo em Python 3:
numbers = [42, 89, 69, 777, 22, 35, 42, 69, 42, 90, 777]
minimal = min(numbers)
maximal = max(numbers)
countListRange = maximal - minimal
countListRange += 1
countList = [0] * countListRange
print(numbers)
print(f"Minimal number: {minimal}")
print(f"Maximal number: {maximal}")
print(f"Count list size: {countListRange}")
for number in numbers:
index = number - minimal
countList[index] += 1
replacingIndex = 0
for index, count in enumerate(countList):
for i in range(count):
outputNumber = minimal + index
numbers[replacingIndex] = outputNumber
replacingIndex += 1
print(numbers)
Из-за использования двух массивов, временная сложность алгоритма O(n + k)
Pseudo-classificação ou classificação por pântano, um dos algoritmos de classificação mais inúteis.
Funciona assim: 1. A entrada é uma matriz de números 2. Uma matriz de números é embaralhada aleatoriamente (embaralhar) 3. Verifica se o array está classificado 4. Se não for classificado, o array será embaralhado novamente 5. Toda essa ação é repetida até que o array seja classificado aleatoriamente.
Como você pode ver, o desempenho deste algoritmo é terrível, pessoas inteligentes acreditam que mesmo O(n * n!), ou seja, há uma chance de você ficar preso jogando dados para a glória do deus do caos por muitos anos, o array nunca será classificado, ou talvez será classificado?
Implementação
Para implementá-lo em TypeScript, precisei implementar as seguintes funções: 1. Embaralhe uma série de objetos 2. Comparação de matrizes 3. Gerando um número aleatório no intervalo de zero a um número (sic!) 4. Imprima o progresso, porque parece que a classificação continua indefinidamente
Abaixo está o código de implementação do TypeScript:
const randomInteger = (maximal: number) => Math.floor(Math.random() * maximal);
const isEqual = (lhs: any[], rhs: any[]) => lhs.every((val, index) => val === rhs[index]);
const shuffle = (array: any[]) => {
for (var i = 0; i < array.length; i++) { var destination = randomInteger(array.length-1); var temp = array[i]; array[i] = array[destination]; array[destination] = temp; } } let numbers: number[] = Array.from({length: 10}, ()=>randomInteger(10));
const originalNumbers = [...numbers];
const sortedNumbers = [...numbers].sort();
let numberOfRuns = 1;
do {
if (numberOfRuns % 1000 == 0) {
printoutProcess(originalNumbers, numbers, numberOfRuns);
}
shuffle(numbers);
numberOfRuns++;
} while (isEqual(numbers, sortedNumbers) == false)
console.log(`Success!`);
console.log(`Run number: ${numberOfRuns}`)
console.log(`Original numbers: ${originalNumbers}`);
console.log(`Current numbers: ${originalNumbers}`);
console.log(`Sorted numbers: ${sortedNumbers}`);
Для отладки можно использовать VSCode и плагин TypeScript Debugger от kakumei.
Как долго
Вывод работы алгоритма:
src/bogosort.ts:1
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 8,7,0,2,4,7,2,5,9,5, try number: 145000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 7,5,2,4,9,8,0,5,2,7, try number: 146000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 0,2,7,4,9,5,7,5,8,2, try number: 147000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 5,9,7,8,5,4,2,7,0,2, try number: 148000
src/bogosort.ts:2
Success!
src/bogosort.ts:24
Run number: 148798
src/bogosort.ts:25
Original numbers: 5,4,8,7,5,0,2,9,7,2
src/bogosort.ts:26
Current numbers: 5,4,8,7,5,0,2,9,7,2
src/bogosort.ts:27
Sorted numbers: 0,2,2,4,5,5,7,7,8,9
Для массива из 10 чисел Богосорт перемешивал исходный массив 148798 раз, многовато да?
Алгоритм можно использовать как учебный, для понимания возможностей языка с которым предстоит работать на рынке. Лично я был удивлен узнав что в ванильных JS и TS до сих пор нет своего алгоритма перемешивания массивов, генерации целого числа в диапазоне, доступа к хэшам объектов для быстрого сравнения.
O padrão Interpreter refere-se a padrões de design comportamentais. Este padrão permite implementar sua própria linguagem de programação trabalhando com uma árvore AST, cujos vértices são expressões terminais e não terminais que implementam o método Interpret, que fornece a funcionalidade da linguagem.
Expressão terminal – por exemplo, constante de string – “Olá, Mundo”
Expressão não terminal – por exemplo Print(“Hello World”), contém Print e um argumento da expressão Terminal “Hello World”
Qual é a diferença? A diferença é que a interpretação termina nas expressões terminais, mas para as não-terminais ela continua em profundidade em todos os vértices/argumentos recebidos. Se a árvore AST consistisse apenas em expressões não terminais, o aplicativo nunca seria concluído, porque é necessária uma certa finitude de qualquer processo, essa finitude é o que são as expressões terminais, elas geralmente contêm dados, por exemplo strings.
Um exemplo de árvore AST está abaixo:
Dcoetzee, CC0, via Wikimedia Commons
Como você pode ver, as expressões terminais são constantes e variáveis, as expressões não terminais são o resto.
O que não está incluído
A implementação do Interpretador não inclui a análise da entrada da string de idioma na árvore AST. Basta implementar classes de expressões terminais e não terminais, métodos Interpret com o argumento Context na entrada, criar uma árvore de expressões AST e executar o método Interpret na expressão raiz. Um contexto pode ser usado para armazenar o estado do aplicativo em tempo de execução.
Implementação
O padrão envolve:
Cliente – retorna a árvore AST e executa Interpret(context) para o nó raiz (Cliente)
Contexto – contém o estado da aplicação, passado para expressões quando interpretado (Contexto)
Expressão abstrata – uma classe abstrata contendo o método Interpret(context) (Expression)
A expressão terminal é uma expressão final, descendente de uma expressão abstrata (TerminalExpression)
Uma expressão não terminal não é uma expressão finita; ela contém ponteiros para vértices profundos na árvore AST. Os vértices subordinados geralmente afetam o resultado da interpretação da expressão não terminal (NonTerminalExpression).
Exemplo de cliente em C#
static void Main(string[] args)
{
var context = new Context();
var initialProgram = new PerformExpression(
new IExpression[] {
new SetExpression("alpha", "1"),
new GetExpression("alpha"),
new PrintExpression(
new IExpression[] {
new ConstantExpression("Hello Interpreter Pattern")
}
)
}
);
System.Console.WriteLine(initialProgram.interpret(context));
}
}
Exemplo de expressão abstrata em C#
{
String interpret(Context context);
}
Exemplo de expressão terminal em C# (String Constant)
Exemplo de expressão não terminal em C# (Iniciando e concatenando os resultados de vértices subordinados, utilizando o delimitador “;”
{
public PerformExpression(IExpression[] leafs) : base(leafs) {
this.leafs = leafs;
}
override public String interpret(Context context) {
var output = "";
foreach (var leaf in leafs) {
output += leaf.interpret(context) + ";";
}
return output;
}
}
Você consegue fazer isso funcionalmente?
Como é sabido, todas as linguagens Turing-completas são equivalentes. É possível transferir o padrão Orientado a Objetos para a linguagem de programação Funcional?
Para um experimento, vamos usar uma linguagem FP para a web chamada Elm. Não há classes no Elm, mas existem registros e tipos, portanto, os seguintes registros e tipos estão envolvidos na implementação:
Expressão – listando todas as expressões de linguagem possíveis (Expressão)
Expressão subordinada – uma expressão subordinada à expressão não terminal (ExpressionLeaf)
Contexto – um registro que armazena o estado do aplicativo (Contexto)
Funções que implementam métodos Interpret(context) – todas as funções necessárias que implementam a funcionalidade de expressões terminais e não terminais
Registros auxiliares do estado do Intérprete – necessários para o correto funcionamento do Intérprete, armazenam o estado do Intérprete, contexto
Um exemplo de função que implementa a interpretação para todo o conjunto de expressões possíveis no Elm:
case input.expression of
Constant text ->
{
output = text,
context = input.context
}
Perform leafs ->
let inputs = List.map (\leaf -> { expressionLeaf = leaf, context = input.context } ) leafs in
let startLeaf = { expressionLeaf = (Node (Constant "")), context = { variables = Dict.empty } } in
let outputExpressionInput = List.foldl mergeContextsAndRunLeafs startLeaf inputs in
{
output = (runExpressionLeaf outputExpressionInput).output,
context = input.context
}
Print printExpression ->
run
{
expression = printExpression,
context = input.context
}
Set key value ->
let variables = Dict.insert key value input.context.variables in
{
output = "OK",
context = { variables = variables }
}
Get key ->
{
output = Maybe.withDefault ("No value for key: " ++ key) (Dict.get key input.context.variables),
context = input.context
}
E quanto à análise?
A análise do código-fonte em uma árvore AST não está incluída no padrão Interpreter, existem várias abordagens para análise do código-fonte, mas falaremos mais sobre isso em outro momento. Na implementação do Interpreter for Elm, escrevi um analisador simples na árvore AST, consistindo em duas funções – análise de um vértice, análise de vértices subordinados.
parseLeafs state =
let tokensQueue = state.tokensQueue in
let popped = pop state.tokensQueue in
let tokensQueueTail = tail state.tokensQueue in
if popped == "Nothing" then
state
else if popped == "Perform(" then
{
tokensQueue = tokensQueue,
result = (state.result ++ [Node (parse tokensQueue)])
}
else if popped == ")" then
parseLeafs {
tokensQueue = tokensQueueTail,
result = state.result
}
else if popped == "Set" then
let key = pop tokensQueueTail in
let value = pop (tail tokensQueueTail) in
parseLeafs {
tokensQueue = tail (tail tokensQueueTail),
result = (state.result ++ [Node (Set key value)])
}
else if popped == "Get" then
let key = pop tokensQueueTail in
parseLeafs {
tokensQueue = tail tokensQueueTail,
result = (state.result ++ [Node (Get key)])
}
else
parseLeafs {
tokensQueue = tokensQueueTail,
result = (state.result ++ [Node (Constant popped)])
}
parse tokensQueue =
let popped = pop tokensQueue in
let tokensQueueTail = tail tokensQueue in
if popped == "Perform(" then
Perform (
parseLeafs {
tokensQueue = tokensQueueTail,
result = []
}
).result
else if popped == "Set" then
let key = pop tokensQueueTail in
let value = pop (tail tokensQueueTail) in
Set key value
else if popped == "Print" then
Print (parse tokensQueueTail)
else
Constant popped
Neste post irei descrever o algoritmo para conversão de um buffer RGB para cinza (Escala de Cinza). E isso é feito de forma bastante simples, cada canal de cor de pixel do buffer é convertido de acordo com uma determinada fórmula e a saída é uma imagem cinza. Método médio:
red = average;
green = average;
blue = average;
Складываем 3 цветовых канала и делим на 3.
Однако существует еще один метод – метод средневзвешенный, он учитывает цветовосприятие человека:
red = luminance;
green = luminance;
blue = luminance;
Какой метод лучше использовать? Да какой вам больше подходит для конкретной задачи. Далее сравнение методов с помощью тестовой цветовой сетки:
Пример реализации на JavaScript + HTML 5
image,
canvas,
weightedAverage
) {
const context = canvas.getContext('2d');
const imageWeight = image.width;
const imageHeight = image.height;
canvas.width = imageWeight;
canvas.height = imageHeight;
context.drawImage(image, 0, 0);
let pixels = context
.getImageData(
0,
0,
imageWeight,
imageHeight
);
for (let y = 0; y & lt; pixels.height; y++) {
for (let x = 0; x & lt; pixels.width; x++) {
const i = (y * 4) * pixels.width + x * 4;
let red = pixels.data[i];
let green = pixels.data[i + 1];
let blue = pixels.data[i + 2]
const average = (red + green + blue) / 3;
const luminance = 0.2126 * red +
0.7152 * green +
0.0722 * blue;
red = weightedAverage ? luminance : average;
green = weightedAverage ? luminance : average;
blue = weightedAverage ? luminance : average;
pixels.data[i] = red;
pixels.data[i + 1] = green;
pixels.data[i + 2] = blue;
}
}
context
.putImageData(
pixels,
0,
0,
0,
0,
pixels.width,
pixels.height
);
}
Se você receber o erro SDL_GetDesktopDisplayMode_REAL em um Macbook M1 ao iniciar o CSGO, faça conforme descrito abaixo. 1. Adicione opções de inicialização ao Steam para CSGO: -w 1440 -h 900 -tela cheia 2. Inicie o CSGO via Steam 3. Clique em Ignorar ou Sempre Ignorar o erro SDL_GetDesktopDisplayMode_REAL 4. Aproveite
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.