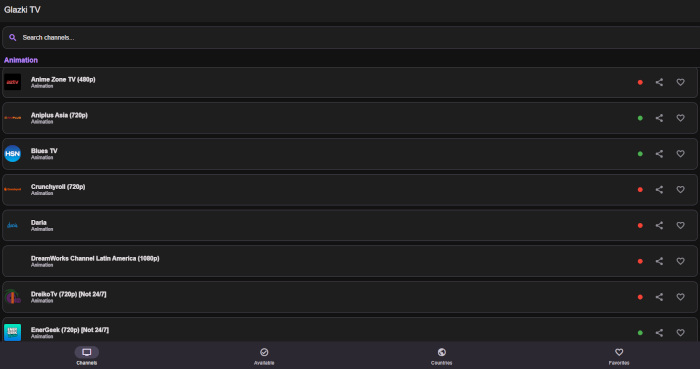
Ushki-Radio é um reprodutor de rádio multiplataforma para rádio online, feito com foco na simplicidade e no prazer de ouvir. Sem funções desnecessárias, sem interfaces sobrecarregadas – basta ligá-lo e ouvir.

https://demensdeum.com/software/ushki-radio
O projeto utiliza o Radio Browser de código aberto, disponibilizando no aplicativo milhares de rádios de todo o mundo. Você pode procurá-los por nome, gênero ou popularidade, adicioná-los aos seus favoritos e retornar rapidamente às suas estações favoritas.
Ushki-Radio é perfeito para o papel de reprodutor de rádio de fundo: lembra a última estação, permite controlar o volume e não requer configurações complexas. A interface é concisa e intuitiva – tudo é feito para que nada distraia a música, as conversas e a transmissão.
Tecnicamente, o projeto é construído em React Native e Expo, portanto funciona tanto no navegador quanto como aplicativo nativo. Nos bastidores, o expo-av é usado para reproduzir áudio e as configurações do usuário são armazenadas localmente. Há suporte para vários idiomas, incluindo russo e inglês.
Ushki-Radio é um bom exemplo do que um reprodutor de rádio moderno na Internet pode ser: aberto, leve, expansível e focado principalmente no ouvinte. O projeto é distribuído sob licença do MIT e é perfeito tanto para uso pessoal quanto como base para seus próprios experimentos com aplicativos de áudio.
Github:
https://github.com/demensdeum/Ushki-Radio
Google Play:
https://play.google.com/store/apps/details?id=com.demensdeum.ushkiradio