Ushki-Radio — это кроссплатформенный радиоплеер для онлайн-радио, сделанный с упором на простоту и удовольствие от прослушивания. Без лишних функций, без перегруженных интерфейсов — просто включил и слушаешь.

https://demensdeum.com/software/ushki-radio
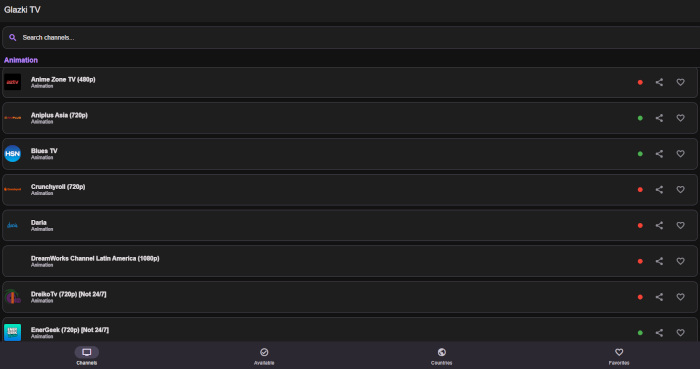
Проект использует открытую базу Radio Browser, благодаря чему в приложении доступны тысячи радиостанций со всего мира. Их можно искать по названию, жанрам или популярности, добавлять в избранное и быстро возвращаться к любимым станциям.
Ushki-Radio отлично подходит именно для роли фонового радиоплеера: он запоминает последнюю станцию, позволяет управлять громкостью и не требует сложной настройки. Интерфейс лаконичный и понятный — всё сделано так, чтобы ничего не отвлекало от музыки, разговоров и эфира.
Технически проект построен на React Native и Expo, поэтому работает как в браузере, так и в виде нативного приложения. Под капотом используется expo-av для воспроизведения аудио, а пользовательские настройки хранятся локально. Есть поддержка нескольких языков, включая русский и английский.
Ushki-Radio — это хороший пример того, каким может быть современный интернет-радиоплеер: открытый, лёгкий, расширяемый и ориентированный в первую очередь на слушателя. Проект распространяется под лицензией MIT и отлично подойдёт как для личного использования, так и как база для собственных экспериментов с аудио-приложениями.
GitHub:
https://github.com/demensdeum/Ushki-Radio
Google Play:
https://play.google.com/store/apps/details?id=com.demensdeum.ushkiradio