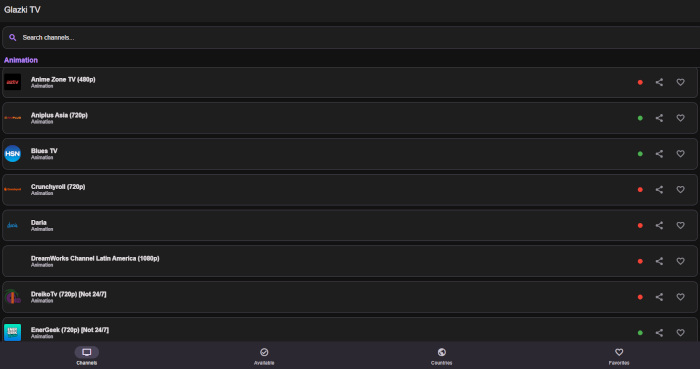
Ushki-Radio is a cross-platform radio player for online radio, made with a focus on simplicity and listening pleasure. No unnecessary functions, no overloaded interfaces – just turn it on and listen.

https://demensdeum.com/software/ushki-radio
The project uses the open source Radio Browser, making thousands of radio stations from all over the world available in the application. You can search for them by name, genre or popularity, add them to your favorites and quickly return to your favorite stations.
Ushki-Radio is perfect for the role of a background radio player: it remembers the last station, allows you to control the volume and does not require complex settings. The interface is concise and understandable – everything is done so that nothing distracts from music, conversations and broadcasting.
Technically, the project is built on React Native and Expo, so it works both in the browser and as a native application. Under the hood, expo-av is used to play audio, and user settings are stored locally. There is support for several languages, including Russian and English.
Ushki-Radio is a good example of what a modern Internet radio player can be: open, lightweight, expandable and focused primarily on the listener. The project is distributed under the MIT license and is perfect for both personal use and as a basis for your own experiments with audio applications.
GitHub:
https://github.com/demensdeum/Ushki-Radio
Google Play:
https://play.google.com/store/apps/details?id=com.demensdeum.ushkiradio