Сегодня я анонсирую три проекта сразу! Ухты! Первый проект – базовая платформа для кроссплатформенной разработки приложений Flame Steel Engine. Второй проект – набор библиотек для базовой платформы Flame Steel Game Toolkit, предназначенный для разработки игр. И третий проект – игра с генерируемыми уровнями в сеттинге киберфентези Flame Steel: Call of The Death Mask. Исходный доступен по лицензии MIT, игровые ресурсы будут доступны под разными лицензиями (проверяйте каждый файл отдельно)
“Нельзя стать мастером всего” – меня всегда смешили подобные фразы. В эту ловушку специализации попадают все – пользователи, программисты, начальники, заказчики. “Хочу как у Microsoft/Apple/Google”, “Почему нам просто не сделать русский айфон?”, “Почему здесь не как в ворде/убере/фотошопе?” – эти фразы слышал любой, причастный хоть как-то к ИТ. Эти фразы, повторенные из уст разных людей, звучат еще смешнее.
Я спрошу тебя читатель – зачем тебе еще один Ворд? Зачем тебе еще один убер? Зачем тебе еще один фотошоп? Зачем тебе нужно чтобы “было как в айфоне”? Почему ты привязываешь себя к интерфейсам и подходу только одной компании? Почему ты навешиваешь на себя ярлык любителя только продуктов Apple/Google/Microsoft? Почему ты не можешь открыть свой разум альтернативным подходам к решению задач, почему не хочешь быть более продуктивным?
Очень многим пользователям Microsoft не понравилось как компания решила что всем необходимо обновиться до Windows 10. Люди ругают неудобные интерфейсы айфона, крэши системы при обновлении, изменения в дизайне которые им не нужны, но все равно продолжают пользоваться ими, потому что так привыкли, и иметь “айфон” это статусно в современном обществе.
Иногда создается впечатление, что если Microsoft/Apple/Google попросят отдать собственных детей в обмен на продолжение работы с их продуктами, то из-за высокой привязанности к этим продуктам, люди запросто отдадут своих чад.
Не будь ими, не привязывайся к одному продукту, посмотри альтернативные варианты. Однажды мне предложили разработать систему для риелторов, с интерфейсом на Microsoft Excel, также были предложения разработать систему “интерактивной доски на Microsoft PowerPoint”. На вопрос почему именно Microsoft мне ответили что “так привыкли”, на вопрос есть ли лицензионное ПО от Microsoft в данных компаниях мне ответили уклончиво, что мол если нужно будет – то купят.
Читатель, я призываю тебя изучить грани ИТ мира, хотя-бы обзорно. Если ты пользуешься всю жизнь только Microsoft Windows, попробуй Apple OS X, или Linux. Если ты пользуешься только iPhone, попробуй хотя-бы неделю попользоваться Android последней версии. В момент когда ты переходишь на сторону только одной компании, закрываясь от продуктов других, в этот момент ты теряешь себя. Себя, как человека который может сам решать чего хочет, как человека который может выбирать наиболее удобный и продуктивный инструмент для решения конкретной задачи.
Программисты только одной платформы – еще одна головная боль лично для меня, как я считаю, для ИТ-индустрии в целом. Разработчики которые делают приложения с экспортом только в *.doc или только в *.pdf, разработчики которые привязываются к только одной устаревшей коммерческой БД (например IBM Informix, или боже упаси Firebird), только к одному типу железа (все эти нерабочие программы для x86 на андроид), я конечно понимаю что вы “привыкли”, но ребята пора меняться.
В своей работе очень часто пользуюсь не популярными, но очень удобными инструментами. Один из примеров – необходимо было уменьшить разрешение и сжать около 100 фотографий, для быстрой загрузки по 3G и выводе на iPad. В тот день я услышал одну из наиболее типичных фраз – “Нам придется все фотографии вручную в *фотошопе* переводить к нужному виду”. Смешной она мне показалась т.к. я представил себе человека который будет вручную, как раб божий, все эти 100 фотографий переделывать в фотошопе, или пытаться автоматизировать через встроенный механизм. Дело здесь именно в том что человек настолько привязан к фотошопу, что даже не подозревал о наличии бесплатного, открытого набора инструментов как ImageMagick. ImageMagick позволяет делать с векторными и растровыми изображениями очень много вещей, в том числе идеально подошел для 5-минутного решения задачи со 100 картинками.
Будьте мастером всего, изучайте, пробуйте, не становитесь рабом конкретной корпорации.
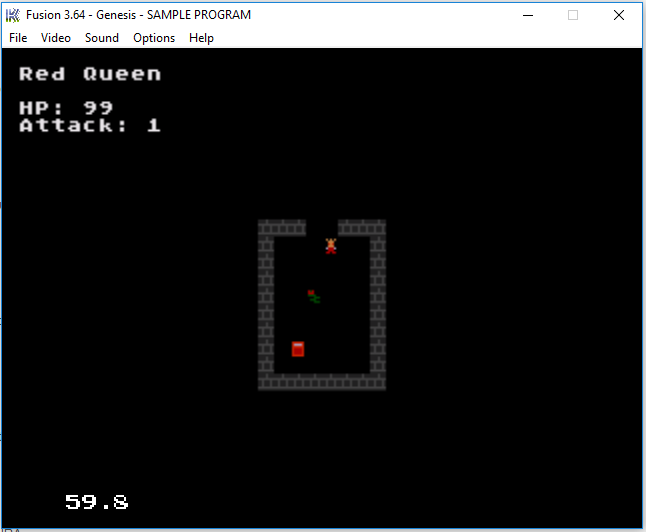
Мне пришло на почту сообщение: “Эй мы тут открываем ретро гейм-джем – bibitjam3!!! Ты должен сделать игру на ретро платформу 8-16 бит!!!” Ба! Это же мечта моего детства – сделать игру для Сеги Меги Драйв Два. Что-ж я попробовал сделать игрушку, и у меня что-то даже получилось:
Игру я назвал “Замес Красной Королевы”. История такова – “Красная Королева была брошена в смертельный лабиринт, теперь она убьет всех на своем пути к свободе.” Можно ходить, можно атаковать зеленую штучку с красными глазами, открывать сундуки с сокровищами, и переходить из сцены в сцену. Это конечно уровень “на попробовать” хоть что-нибудь сделать для сеги и для конкурса. Я использовать SGDK тулкит – компилятор для моторолы 68к на базе GCC, библиотеки для работы с железом сеги меги. Теперь я понимаю что это реально было сложно – делать игры 20-30 лет назад. Например каждый тайл – должен быть поделен на кусочки 8х8 пикселей и отрисован кусками по очереди. Также палитра для каждого тайла должна не превышать 16 цветов! Сейчас конечно гораздо проще. Конечно же нужно создать игровой, звуковой, графический движок для игры, как и сейчас. Вы можете поиграть в Красную Королеву с помощью эмулятора Sega Genesis и РОМа игры: http://demensdeum.com/games/redQueenRampageSegaGenesis/RedQueenRampage.zip
Если вы хотите посмотреть исходники: http://demensdeum.com/games/redQueenRampageSegaGenesis/RedQueenRampageSource.zip
У меня сейчас нет времени для записи видео, поэтому здесь короткая текстовая версия туториала.
Вообще вы можете скачать код игры Demon’s Cave и собрать на своей машине.
Сегодня мы будет выводить лого компании Demens Deum на движке Rajawali (OpenGL-ES 2.0)
6. Добавляем demensdeum_logo.png в res/drawable папку
7. Собираем-проверяем на вашем Android девайсе
Вы должны увидеть картинку – логотип компании Demens Deum, если она будет по горизонтали зеркальная – поверните ее в Gimp сначала.
Продвинутые пользователи могут ничего не зеркалить, вам стоит попробовать использовать самую последнюю версию Rajawali, некорректные текстурные координаты для Plane это известная проблема старых версий.
Пока отечественная пресса подтягивается, на западе уже во всю пишут обзоры. Сайт App Games выпустили обзор игры Demon’s Cave
From animations to the game world and everything in between, Demon’s Cave does show quality and a great promise. It’s a pleasant and fun title with a lot of cool things to offer. It’s one of the best casual arcade games that you can try out so you should check it out, it really deserves your time!
Игра Demon’s Cave скоро выходит на Android. Я начал запись курса портирования игры на Android, так как есть много людей которым действительно интересен процесс разработки. Напишите мне если у вас есть вопросы, или если вы хотите добавить что-то к данному курсу. Также вы можете добавить субтитры для других языков: http://www.youtube.com/timedtext_video?ref=share&v=rx7NYkAJB2I
Вопрос: “Можно ли мне скопировать игру Demon’s Cave на свой сайт, или блог, или на свою страницу между умилительными котятами и цитатами Коэльо / Стэтхэма?” Нельзя, я запрещаю лично. Шучу, не лично. Просто скопируй и вставь HTML код:
Вопрос: “Я хочу повесить Demon’s Cave на страницу с рекламой, можно?” Да, тебе все можно.
Вопрос: “Я хочу продавать игру Demon’s Cave, можно?” Можешь делать с движком игры fsagamelibrary.js что угодно, только оставь линк на demensdeum.com А вот графику и музыку надо либо купить (та что платная), либо использовать свою. Подробнее список ресурсов тут. Если ты не оставишь ссылку на главный сайт, то демон придет в твои сны.
Вопрос: “Я хочу сделать мод игры Demon’s Cave, или вообще сделать ее в 3д на юнити, можно я потом ссылку кину тебе?” Конечно. Кидай вк.
Demens Deum – команда инди-разработчиков, мы создаем новые интересные вещи, будь то игры, программы, музыка, комиксы. В мире сейчас очень мало команд готовых эксперементировать с идеями, технологиями, воплощением. Наш манифест – долой привычные рамки жанров, долой серые штампованные хиты – ударим экспериментом, оригинальными вселенными, захватывающими историями по мозгу обывателя, взбудоражим сердца жаждующих!
Demon’s Cave – игра в которой нужно лететь в пещере и уворачиваться от скал, собирая монетки! Вердж — отважный охотник на демонов, на своем самолете и запасе энтузиазма пытается поймать легендарного демона планеты Сириус 9.
Оракул изрек: – Имя королевы однажды было запрещено произносить. Хотя оно было обычным королевским именем и не намекало ни на что особенное: ни на запрещенную религию, ни на расу, ни даже, на размер ноги. И папа и мама, хоть и молодые, были уже бесконечно мудры. Они берегли своего сына от лишних знаний. Они прекрасно знали, как зовут королеву, но упорно отмалчивались.
Герострат сжег храм, и имя его должно было быть предано вечному забвению, а получилось наоборот: спроси любого прыщавого обалдуя, сколько будет семижды восемь, и он не скажет, а спроси, кто сжег храм Артемиды, так он вспомнит чей то там храм и Герострата. Вот, что значит запретный плод. Каленым железом не выжжешь такие знания из мозга, и даже инфрактором пунктирных волн. Эти знания имеют тени, которые неизвестно, где всплывут однажды в мозгу, и что будет с носителем такого мозга. Это был единственный случай, который противоречил изречению: знания лишними не бывают. Поэтому родители молчали. Зато они много говорили при ребенке обо всем остальном, на грани опасности, на грани приличия, на грани секретности.
Солнце близилось к закату. В небе над морем кружили птицы, перекрикиваясь между собой. Небо багровела своими красками, а день постепенно исчезал под покровом ночи. Молодая пара прогуливалась по набережной, с обеих сторон держа своего малыша за руки, и о чем-то тихо беседуя.
— Мам, пап, а почему у Ее Величества нету имени? — спросил мальчик, лет шести на вид. — Потому что не велено, сынок, — отозвался отец. — Что не велено? Иметь имя? Ведь мы же имеем имя, и каждый имеет, — не успокаивался мальчик. В его сапфировых глазах горел интерес. — Сынок, таков закон, и мы обязаны его соблюдать, — на этот раз уже мать объясняла мальчику. — Но, мам, кто придумал такой закон? Ведь я могу спросить твое имя или папы, почему ее имени не могу? — Потому что она королева, сынок. — Но она ведь тоже человек. Вот я встречу ее на улице и захочу познакомиться, я скажу ей, как меня зовут и что она мне ответит? Она же должна ответить мне и сказать свое имя. Это же правильно, так все говорят, — не уставал мальчик. Отец с матерью засмеялись. — Ты просто еще маленький и не всего можешь понять, но пройдет немного времени и все станет для тебя ясно, — улыбаясь, отец похлопал мальчика по голове, чем растрепал его гладкие, темные волосы. — Пап, смотри какая большая птица, — мальчик показал на черную точку на горизонте, которая стремительно приближалась. — Да, пожалуй, очень большая, — сказала мама. — Это… не птица, мальчик мой, — задумчиво сказал отец, зафиксировав свой взгляд на точке, которая с каждой секундой становилась все больше и больше. — Очень странно, ведь полеты запрещены Ее Величеством на целый год, в связи с тем инцидентом, что же это за корабль тогда? — Корабль?! — восторженно вскрикнул мальчик.
Огромная масса черного металла, раскаленного о атмосферу, неслась над морем, рассекая вечерний, морской воздух. Оглушающий гул двигателей был слышен из далека, приводя в легкий ужас, в совокупности с видом этой машины. Корабль приковал взгляды многих, кто находился в тот момент на набережной. Люди шептались между собой, перекидываясь несколькими вопросительными фразами, недоумевая, почему это корабль в это время появился в воздухе.
Без опознавательных знаков, железный монстр завис в воздухе над набережной, сверкая металлом от красного света заходящего солнца и поднимая пыль от разогретых двигателей. Из-под днища корабля появился синий луч света, который начал, будто сканировать людей, находящихся на набережной. После нескольких личностей, он перекинулся на молодую пару с ребенком, и просканировав их, в чреве этого монстра открылась дыра. На набережной разразилась паника, люди бросились в разброс от корабля. Отец схватил мальчика на руки и они бросились бежать. Но было поздно: луч как магнитом притягивал к себе мальчика, который не мог пошевелиться, поднимая его все выше в воздух. — Кто вы такие?! Что вы хотите от нашего ребенка!? — кричала мать в сторону корабля. Две внезапные вспышки из источника синего луча и будто два пучка энергии столкнулись с родителями мальчика на набережной, после чего они упали без чувств. Мальчик пропал во тьме закрывающегося люка корабля, после чего машина резко развернулась, ее двигателя засияли синим пламенем и исчезла во вспышке гиперскорости, оставив после себя атмосферный след в вечернем небе, когда солнце близилось к закату, а день собирался уступить место ночи…
Шесть отборных рыцарей Ее Величества, прошедшие через битву при Вартигосе, ожесточенную осаду Королевского замка 2130 года, известную как “Осада тысячи машин”, лучшие из лучших воинов Королевы, барахтались в водах курорта Лорсума среди обломков отеля Хилтон.
– Мы проиграли, абсолютно. – Промямлил стрелок Тернер. – Потеряли Королеву, теперь головы с плеч. Пять голов повернулись в его сторону. – Лично ты больше всех напивался вчера! Лично ты несешь ответственность за произошедшее! – Совсем оборзел Гейбл, твоя идея была пойти оторваться в баре! Старшина Крейвс заорал: – Заткнитесь оба! Смотрите, там на глубине что-то поднимается. Неподалеку в темноте вод замаячил луч света, из глубин поднималось что-то огромное, всех начало раскачивать на волнах. – Не может быть это… С грохотом на поверхность воды вырывается боемашина MST-430, она раскрашена в граффити, дверь в кабину пилота отломана, освещение частично выломано. – Что с ней стало? – Похоже Гейбл ты вчера потерял не все наши машины, одна вернулась к нам сама.
Было очевидно что в боемашине сработала аварийная система всплытия, судя по виду машины, на ней покаталась местная шпана, и не поняв как разблокировать оружейную систему, выбросили ее в залив. Эрни влезает в кресло пилота. – Шеф, все системы в норме. – Но ведь мы все равно опоздали… – Погоди еще! Тернер садится в стрелковый обзор. – Крейвс! Здесь точка от маячка Королевы. Мы еще можем догнать их пока они не покинули пределы планеты. – Хорошо, вылетайте и спасите Ее Величество. Пока мы выберемся на берег и обсушимся.
Боемашина с лучшими воинами взлетает и устремляется в сторону солнца. Им предстояла битва с очень хитрым и матерым противником.
Вечером того же дня Крейвс встретил команду вместе со спасенной Королевой. Судя по всему она даже не поняла что ее сначала потеряли, а потом вернули в последний момент. – Я была в аду… – Да ваше Высочество. – Меня заставляли смотреть шоу Малахера… – Это ужасно. – В этом шоу одни старухи… Они сплетничают на разные темы и Малахер подкидывает дрова в огонь… – Вы очень сильная. – Конечно я очень сильная. Любая другая уже сошла бы с ума.
Ее Величество выглядела неважно. За два часа которые она провела в плену, были потеряны все Королевские побрякушки, на ногах были армейские ботинки, которые отдал ей стрелок Тернер. – Вы как всегда правы. – Однажды ты будешь возглавлять армию, Крейвс. Изабелла упала в руки Крейвса, и он понес ее в безопасное место.
Он все думал что Королева скажет когда увидит себя в зеркало. Ведь на лбу у нее теперь был выбит штрих-код и подпись “Собственность Селектума Альфредо“.
Старшина Крейвс встал сегодня очень рано. Он вообще не рассчитывал это делать, так как кроме медуз Ее Величеству ничего не угрожало, ведь они находились на курорте Лорсума. Он не мог простить себе что теплое солнце и пляж расслабили его, он позволил своим ребятам развлекаться в баре, вместо того чтобы обеспечивать защиту Королевы. – Рота подъем! В комнате пентхауса отеля Хилтон в ответ раздается вялое “Отвали”. – Подъем бараны! Королеву выкрали у нас из под носа! Из дальней комнаты выходит стрелок Тернер, заспанный с красными глазищами, с бутылкой коньяка в одной руке и статуэткой местной богини Арши в другой. – Мы не дадим им украсть Королеву! Тернер падает на пол прямо в кучу подушек на полу. – Они уже ее выкрали! Вставайте немедленно! – Кто они?! Спрашивает механик Гейбл выходя из ванной в женском халате и розовых тапочках с надписью Q.D. – Они это… В этот момент раздается грохот на нижних этажах отеля, кричат люди, похоже что произошел взрыв, здание начинает очень громко скрипеть и трястись. От грохота просыпается вся Королевская рота Рыцарей Ее Величества, кто в чем… – Рота слушай мою команду! Все по машинам! Пилот Эрни громко ругается, сквозь мат становится понятно что ключи от военного погрузчика были проиграны в баре. – Играл в пирамиду вчера, на последнем стакане пирамида упала, пришлось отдать ключ какому-то лысому парню. Крейвс понимает что теперь ситуацию не исправишь. Без машин, без оружия, без Королевы… Отель сотрясает снова, здание начинает заваливаться на бок. – Крейвс что делать!? Сейчас мы об землю матушку разобьемся! Здание падает на бок, все падают вместе с ним. Мимо старшины пролетали журналы, пивные кружки, губная гормошка ударила в лоб и полетела дальше. Удар, стало темно. И тут Крейвс понимает что упал в воду, начинает всплывать. – Ахаха! Повезло нам что отель стоит на берегу, мы шлепнулись прямо в воду! – кричит связистка Мэни.
<СЕКРЕТНО: ДОСТУП А> 2142.03.21 Перехват сообщения QDFS-0076
Всем привет! Я – Селена жива и здорова – снова с вами! После моей прошлой заметки “Как сделать взрывного кота?!” дорогие читатели закидали меня письмами с вопросами об использовании технологии копирования на человеке.
“Свободная Селена, привет тебе! По инструкции из твоей заметки мы с женой сделали взрывного кота. Соседский цербер пытался его съесть – пса взрывом разнесло по всей округе. Благодаря тебе мы решили огромную проблему – гаденыш больше не гадит у нас во дворе. Искреннее спасибо. У меня возник вопрос – возможно ли достать бОльшую камеру Грувса и сделать взрывную копию себя или моей жены?
С уважением, Ролум Менстрив”
Всегда пожалуйста Роли! Ты настоящий свободный человек Королевского сектора, в новой заметке я отвечу именно тебе!
Как известно Кригг Грувс изобрел т.н. “камеру Грувса” для копирования вещей малого размера. Он был растяпой, постоянно терял вещи, поэтому хотел иметь несколько копий про запас. И знаешь что Роли? УВЕРЕНА НЕ ЗНАЕШЬ! БОльшой камеры просто не существует. Смешно да? Ее просто нет.
На самом деле есть – скрывают. Лично один я собрала сама для нашего Батальона Огня! (Ты же не думаешь что я буду выдавать настоящее название?!) Ниже перечислю список деталей нужных для сборки камеры Груввса (снова) (ненавижу повторяться!!!):
Все это легко достать, даже в твоем секторе. Как быть с “бОльшей” камерой, спросишь ты меня? Копию себя любимого невозможно втиснуть в микроволновку. Или ты размером с кота?
Роли, тебе надо отыскать ремонтный блок, который используется для ремонта боемашин. Нужно еще много элллллектричества!!! Мне электричество идет прямо из фазовой шахты звезды. Ролум, у тебя есть свободная звезда?
Итак список необходимого:
1.Ремонтный блок боемашины 2.Электричество из фазовой шахты 3.Лазер Груввса
К этой заметке добавила я схемы сборки, этапы тех. процесса и щепотку черной магии!
Удачных взрывов Роли! Свободу от тирании Королевства!
– Они все идиоты, все отдают сами. – Ведь ты со своими ребятами захватываешь их корабль, что им остается? Маркус встает в полный рост, достает пистолет и наводит на меня. – Блокнот. Важнее всего он для тебя, мне его отдай. – Но зачем тебе мой блокнот? Я слышу как перещелкивает предохранитель пистолета. Послушно отдаю свой блокнот с записями. – Ты такой же идиот. Маркус забирает блокнот и уходит в сторону корабля. – Но как же интервью? Там мои записи, я не смогу опубликовать если ты не отдашь мне его! Маркус Лоботряс – известный галактический пират, авантюрист. Не судите о нем по смешному прозвищу. Он известен грабежами транспортных кораблей, разбоями.
Любой деловой человек галактики отказывается работать в том секторе где объявляется Маркус. На его счету смерть охотника за головами Шустрого Франко. Кажется что Рыцари Ее Величества желают получить его голову сильнее чем полный и тотальный контроль над мятежными секторами. Теперь он стоит передо мной, длинная черная кожаная куртка, кружевные узоры переливающегося синего цвета на одежде, взгляд ястреба. – Тебе жить не больше двух лет. Он кидает блокнот на землю. – Озвереешь, безумцем станешь. Слышу как разбойники банды Маркуса открывают очередной контейнер. Раздается громкий смех “Ааа! Здесь еще выпивка!” Несколько бандитов уже открывают бутылки и начинают пить под общее гоготанье. Маркус показывает пальцем в сторону своей команды. – Быть как они хочешь? Вопрос меня сбил с толку. Он хочет чтобы я стал частью его банды? – Нет к разбою у меня душа не лежит. Слышу смешок с его стороны. – Шатаешься без дела по галактике. Закончишь как они. – Но я журналист, это моя работа! Слышно как сварка вскрывает очередной контейнер. Сначала слышны смешки, но внезапно раздается нечеловеческий рев, крики одного из бандитов “Что это!”, другой “Это чудовище шахт! Мы все умрем!” Огромный монстр возникает перед моим взором. Чудище высотой с гору, когтями, шерстью и красными полными ярости глазами. – Прячься!
Маркус бежит в сторону монстра, я прячусь за ближайшим валуном. Огромной лапой чудовище выбивает несколько бандитов, они разлетаются в стороны. Раздаются крики и выстрелы. Мой редактор Жорен видит что происходит, отправляет мне сообщение: – Шенон, выбирайся оттуда, я не хочу получить тебя назад кусками! Собираюсь с силами и начинаю бежать в сторону корабля. Маркус кричит своей команде чтобы те отступали к кораблю и улетали. Чудище своим ревом заставляет оцепенеть от ужаса несколько человек, они встают намертво и оно вбивает их в землю огромной лапой. Маркус кричит мне: – Беги журналист! Я успеваю нажать на кнопку шлюза, из-за бури двери тяжело открываются. Успеваю забежать. Вижу как Маркус забегает в последний момент в шлюз. – Хаха не так и страшно чудище шахт да?! И тут я вижу как он падает на металлический пол. Одна нога остается по ту сторону приоткрытой двери. Огромный коготь чудища торчит в его ноге. – Идиот помоги мне! Хватаю Маркуса за руку, несколько человек хватают меня и пытаются вытянуть нас. В этот момент я понимаю что корабль уже взлетел. Нас начинает швырять по шлюзу, вытягивать в открывающуюся дверь шлюза. Слышно как чудовище бьет второй лапой по кораблю, нас вытягивает все сильнее. Сигнальный красный свет начинается светить, истошно кричит звук разгерметизации. Раздается крик Маркуса, его рука вылетает из моей, потоком меня выталкивает вместе с ним вниз, прямо на землю планеты Тизис 4.
—
– Дед ты опять свои байки рассказываешь? Элинора входит в комнату, ставит две чашки чая на стол. – Я внучке рассказываю истории из своей жизни. – Опять про “чудище шахт”? Нахмуриваюсь, неужели нельзя просто выслушать старого человека и не высмеивать. Молодежь. – Дедушка, а что дальше было? – Доченька, дедушка убил чудище, и он вообще герой. А тебе спать пора. – Ты все врешь! Как он его убил если дедушка маленький, а чудище большое! Ведь она права…
Привет дорогой читатель. В этой заметке я опишу свой опыт создания первой игры для мобильников Андроид. Многим людям нравится эта история, я считаю ее необходимо опубликовать. Это не история успеха, но думаю многим начинающим разработчикам даст понимание с чего начинать и что нужно делать для создания простенькой игры. Обязательно опишу свои ошибки, и что можно было сделать лучше.
Да простят меня Jamie Hewlett и Alan Martin, публикую отличный арт Tank Girl без их разрешения
Иногда впадаешь в такое состояние, в котором хочется создать что-то эдакое, чтобы все ахнули и разинув рты говорили “Ну ты крут“. Такая история случилась со мной в 2011 году, когда я посмотрев отрывок фильма “Tank Girl” загорелся идеей создать аркадную игру в комиксном стиле. Почему для Андроид, а не iOS? Причина проста – у меня не было макинтоша и айфона, зато было огромное желание поддержать Линукс на мобильниках. В то время мне нравилась идеология FSF, а Ричард Метью Столлман был моим божеством.
Песня линукс хакеров. Прежде чем петь – поверь в мир во всем мире
На момент разработки последней версией андроид был 2.0, также необходимо было оставить поддержку для старых версий, так как пользователей 1.6 было очень много. Многие производители телефонов даже не выпускали обновлений до версии 2.0.
Я сразу поставил временные рамки для реализации данного проекта – один месяц. За это время предстояло подтянуть знания по Java, изучить Android SDK, Eclipse, встретиться с монстром в лице OpenGL ES и положить его на обе лопатки. Со стороны графики предстояло создать около шести 3d моделей, оптимизированных для мобильников. Также необходимо было выпустить проект на золото в Android Market, в то время Google Play назывался так)
Так как времени было мало, необходимо было выбрать готовый 3d движок. Создать свой движок с нуля можно, но не очень продуктивно, так как на тестирование и совместимость со всеми устройствами уйдет большая часть времени. До прихода Unreal Engine, Unity, ThreeJS (HTML5), лидирующим движком был JPCT-AE. Движок поставлялся в виде готовой java библиотеки, поддерживал старые версии андроида. Также его создатель EgonOlsen оперативно занимается поддержкой и исправлением ошибок по запросу разработчиков.
Кадры решают все – хулиган Антон согласился написать музыку для игры. Я всегда восхищался его творчеством, его работа послужила локомотивом движущим весь геймплей, заставляющим пользователя играть до последнего сбитого вертолета.
Столько всего, с чего же начать? Начать надо с установки Android SDK. Сейчас она поставляется со встроенным IDE – Android Studio. Но на тот момент IDE и SDK поставлялись отдельно. По документации на сайте Google произвел установку Android SDK, Eclipse. Также были установлены необходимые пакеты для Eclipse обеспечивающие сборку и запуск эмулятора Андроид. Через час я собрал тестовый проект jpct-AE:
Это было ухты! Но в эмуляторе телефона все тормозило очень сильно. Поэтому было принято решение купить телефон на платформе Андроид. Для этих целей был приобретен LG Optimus One P500. С тех пор я не пользуюсь отличными кнопочными телефонами нокиа на платформе Симбиан) Были проблемы с подключением телефона к Линуксу, если кто-то с ними встречается до сих пор, то проверьте настройки udev.
Джобс цитирует Пабло Пикассо
Посмотрев на Alien Runner, я понял что инопланетянина можно заменить на мотоцикл и двух панков с базукой, поляну вокруг превратить в мегаполис, а туман заменить на ночь из баллад Iron Maiden.
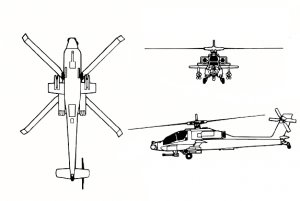
Как делать 3д модели? Да очень просто, открываешь урок по созданию low-poly моделей на Youtube и делаешь. Весь процесс заключался в обводке проекций в 3д редакторе. Мною были найдены чертежи вертолета Apache, и была сделана модель вертолета. Текстуры были взяты из открытых источников армии сша.
Зачем нужен вертолет в игре с двумя панками и базукой? Когда я играл в прототип, то заметил что игрок может просто стоять на месте и набивать очки. Идеальным решением оказался вертолет, который прилетает и закидывает игрока субмаринными торпедами, не давая ему останавливаться.
В мобильных приложениях и играх того времени остро выражена проблема нехватки памяти, как на самом телефоне, так и в оперативной памяти. Производительность была тоже на троечку. Один ARM процессор с частотой 300-500 мгц. В результате тестирования на телефонах друзей, оказалось что у HTC в два раза меньше видеопамяти чем в LG, 8мб и 4мб со-но, из-за чего игра выбивала лимиты памяти и не запускалась. Все ресурсы были ужаты до того состояния, чтобы получить фреймрейт 30 кадров в секунду, и возможность запускаться почти на всем.
Не повторять!
В Alien Runner управление осуществлялось с помощью нажатий на экран. Такой тип управления мне показался не удобным, я реализовал управление с помощью акселерометра. Тоесть поворачиваешь телефон – поворачивается мотоцикл. Мне так понравилось что я даже добавил вид от первого лица, для самых смелых.
Поддержка со стороны разработчика движка jpct-AE мне понадобилась когда я увидел что в игре исчезает затемнение впереди. Это происходило после сворачивания и разворачивания приложения. Я создал тему на форуме jpct-AE и уже через два дня проблема была решена. Я интегрировал исправленную версию движка в игру.
Также стоял вопрос как реализовать бесконечную подачу машин. Для мобильной игры необходимо было придумать способ обеспечивающий добавление машин на игровую сцену БЫСТРО. Вариант с загрузкой из медленной памяти или sd карты был сразу отвергнут. На помощь пришел паттерн проектирования под названием объектный пул. Когда машина выходила из области видимости или уничтожалась, то она отключалась и в момент когда требовалось подать новую машину в начало сцены – то она включалась и ставилась туда.
Чтож настал день релиза. Игра была оттестирована, предварительный показ друзьям проведен, теперь предстояло выйти в золото на Android Market. Регистрация в Android Market стоила 20$, оплачена. Добавлено описание, скриншоты. И в этот момент я понял что нужно записать видео.
Как записать видео для мобильного проекта? Неужели снимать мобильный телефон на камеру, а потом выкладывать? Решение было интересным, я использовал Андроид эмулятор, отыграл в игру с фреймрейтом два кадра в секунду, записав все происходящее на экране с помощью программы которая называется примерно так gtkDesktopRecorder. С помощью VirtualDub скорость видео была увеличена до 30 кадров в секунду. Потом в лучшей программе для редактирования видео – Windows Movie Maker я добавил все игровые звуки и музыку.
Теперь настал момент ошибок. В раскрутку проекта не было вложено ничего, ни усилий, ни денег. Я тогда считал что проект отобьет сам себя. Игра ушла на золото, я создал тему на форуме jpct-AE о Mad Racer. Я получил 12 установок по доллару за две недели. И обнаружил игру в бесплатном доступе на куче варезных сайтов на следующий же день.
Напевая песню FSF “Share the software” я решил сделать бесплатную версию, с рекламой. Игра была переведена в разряд AdWare, внизу появился рекламный баннер от сети AdMob. Интеграция с рекламной системой прошла гладко. За месяц игра была установлена на десять тысяч устройств. Из рекламной сети я получил 50$.
Вообщем не забывайте о рекламе, я считаю что это должна быть одна из главнейших статей расходов на ваш проект.
Из положительных сторон хочу отметить получение мной места iOS разработчика в одной из лучших компании нашего города. И конечно же бесценный опыт.
Опытный программист с широким опытом кроссплатформенной разработки для мобильных, десктоп систем, различных архитектур (x86, x86-64, ARM, PowerPC, Motorola 68000, Z80, MSP-430), веб-разработки и программирования драйверов для macOS. Могу создавать проекты с нуля, выводить их на рынок и поддерживать как внутренние, так и внешние проекты. Легко осваиваю новые технологии для решения бизнес-задач.
Реализовывал и поддерживал проекты для таких брендов, как Decathlon, Мать и Дитя, Fitbit и Playboy.
– Разработка архитектур и приложений с нуля.
– Обучение сотрудников и создание отделов разработки и тестирования.
– Принятие кадровых решений и проведение технических интервью.
– Проведение презентаций и мастер-классов.
– Делегирование и управление командами разработчиков.
Также имею опыт работы аналитиком, взаимодействуя с международными клиентами для сбора требований и оценки бизнес-задач.
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.








 Ковчег by
Ковчег by