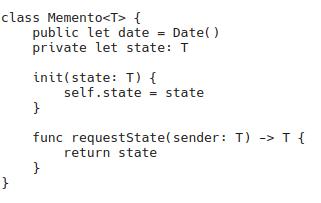
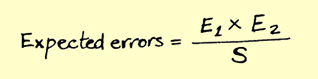この記事では、キャラクターやゲーム環境などをアニメーション化するために最新のすべての 3D エンジンで使用されているスケルトン アニメーションについての私の理解を説明します。
最も具体的な部分から説明を始めます –なぜなら、計算パス全体は、それがどれほど複雑であっても、表示用に準備されたデータを頂点シェーダーに転送することで終了するからです。

スケルトン アニメーションは、CPU で処理された後、頂点シェーダーに入ります。
スケルトン アニメーションを使用しない頂点の公式を思い出させてください。
gl_Position = 投影マトリックス * ビューマトリックス * モデルマトリックス * 頂点;
この式がどのように生まれたのか理解できない人は、OpenGL のコンテキストで 3D コンテンツを表示するための行列の操作原理を説明した私の記事を読んでください。
残りについては –スケルトン アニメーションを実装するための公式:
” vec4 アニメーション頂点 = ボーン 0 マトリックス * 頂点 * ボーン 0 ウェイト +”
“ボーン 1 マトリックス * 頂点 * ボーン 1 ウェイト +”
“ボーン 2 マトリックス * 頂点 * ボーン 2 ウェイト +”
“bone3matrix * 頂点 *bone3weight;\n”
” gl_Position = projectMatrix * viewMatrix * modelMatrix * animeVertex;\n”
つまり、最終的なボーン変換行列に頂点と、頂点に対するこの行列の重みを乗算します。各頂点は 4 つのボーンでアニメーション化でき、衝撃の強さはボーンの重量パラメータによって制御され、衝撃の合計は 1 に等しくなる必要があります。
頂点に影響を与えるボーンが 4 つ未満の場合はどうすればよいですか?重みを分担して残りの影響をゼロにする必要があります
。数学的には、重みと行列を乗算することを「行列のスカラー乗算」と呼びます。スカラーを乗算すると、結果の頂点に対する行列の効果を合計できます。
ボーン変換行列自体は配列として送信されます。 さらに、配列には各メッシュの行列ではなく、モデル全体の行列が含まれています。
ただし、頂点ごとに次の情報が個別に送信されます。
–頂点に影響を与える行列のインデックス
です。–頂点に影響を与える行列の重み
です。複数のボーンが送信され、通常は頂点の 4 つのボーンの効果が使用されます。
また、4つのサイコロの重みの合計は必ず1に
ならなければなりません。次にシェーダーでの見え方を
見てみましょう。行列配列:
“均一マット 4 ボーン行列[kMaxBones];”
各頂点の 4 つのボーンの効果に関する情報:
“属性 vec2bone0info;”
“属性 vec2bone1info;”
“属性 vec2bone2info;”
“属性 vec2bone3info;”
vec2 – X 座標にはボーンのインデックスを保存し (シェーダーで int に変換します)、Y 座標には頂点に対するボーンの影響の重みを保存します。なぜこのデータを 2 次元ベクトルで送信する必要があるのでしょうか? GLSL は、有効なフィールドを持つ C 読み取り可能な構造体をシェーダーに渡すことをサポートしていないためです。
以下に、animatedVertex 式にさらに代入するために必要な情報をベクトルから取得する例を示します。
“intbone0Index = int(bone0info.x);”
“floatbone0weight =bone0info.y;”
“mat4bone0matrix =bonesMatrices[bone0Index];”
“intbone1Index = int(bone1info.x);”
“floatbone1weight =bone1info.y;”
“mat4bone1matrix =boneMatrices[bone1Index];”
“intbone2Index = int(bone2info.x);”
“floatbone2weight =bone2info.y;”
“mat4bone2matrix =bonesMatrices[bone2Index];”
“intbone3Index = int(bone3info.x);”
“floatbone3weight =bone3info.y;”
“mat4bone3matrix =bonesMatrices[bone3Index];”
これで、CPU に設定された頂点構造は次のようになります。
x、y、z、u、v、bone0index、bone0weight、bone1index、bone1weight、bone2index、bone2weight、bone3index、bone3weight
頂点バッファ構造はモデルの読み込み中に一度埋められますが、変換マトリックスは各レンダリング フレームで CPU からシェーダーに転送されます。
残りの部分では、CPU 上でアニメーションを計算する原理を説明します。アニメーションを頂点シェーダーに転送する前に、アニメーション、モデル、ノード、メッシュ階層、マトリックスをたどるボーン ノードのツリーについて説明します。補間。
ソース
http://ogldev.atspace.co.英国/www/tutorial38/tutorial38.html
ソースコード
https://gitlab.com/demensdeum/skeletal-animation