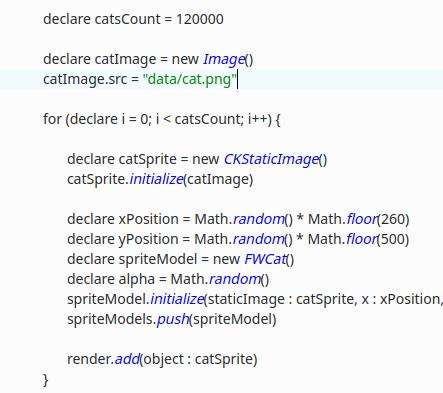
In this article I will describe my understanding of skeletal animation, which is used in all modern 3D engines for animating characters, game environments, etc.
I’ll start the description with the most tangible part – the vertex shader, because the entire calculation path, no matter how complex it is, ends with the transfer of prepared data for display in the vertex shader.

After calculation on the CPU, skeletal animation goes into the vertex shader.
Let me remind you of the vertex formula without skeletal animation:
gl_Position = projectionMatrix * viewMatrix * modelMatrix * vertex;
For those who do not understand how this formula came about, you can read my article describing the principle of working with matrices for displaying 3D content in the context of OpenGL.
For the rest – the formula for implementing skeletal animation:
” vec4 animatedVertex = bone0matrix * vertex * bone0weight +”
“bone1matrix * vertex * bone1weight +”
“bone2matrix * vertex * bone2weight +”
“bone3matrix * vertex * bone3weight;\n”
” gl_Position = projectionMatrix * viewMatrix * modelMatrix * animatedVertex;\n”
That is, we multiply the final matrix of bone transformation by the vertex and by the weight of this matrix relative to the vertex. Each vertex can be animated by 4 bones, the force of the impact is regulated by the bone weight parameter, the sum of the impacts must be equal to one.
What to do if the vertex is affected by less than 4 bones? You need to divide the weight between them, and make the impact of the rest equal to zero.
Mathematically, multiplying a weight by a matrix is called “Matrix-Scalar Multiplication”. Multiplying by a scalar allows you to sum the effects of matrices on the resulting vertex.
The bone transformation matrices themselves are transmitted as an array.Moreover, the array contains matrices for the entire model as a whole, and not for each mesh separately.
But for each vertex the following information is transmitted separately:
– Index of the matrix that affects the vertex
–The weight of the matrix that acts on the vertex
It is not just one bone that is transmitted, usually the effect of 4 bones on the vertex is used.
Also, the sum of the weights of 4 dice must always be equal to one.
Next, let’s look at how this looks in the shader.
Array of matrices:
“uniform mat4 bonesMatrices[kMaxBones];”
Information about the impact of the 4 bones on each vertex:
“attribute vec2 bone0info;”
“attribute vec2 bone1info;”
“attribute vec2 bone2info;”
“attribute vec2 bone3info;”
vec2 – in the X coordinate we store the bone index (and convert it to int in the shader), in the Y coordinate the weight of the bone’s impact on the vertex. Why do we have to pass this data in a two-dimensional vector? Because GLSL does not support passing readable C structures with correct fields to the shader.
Below is an example of obtaining the necessary information from a vector for further substitution into the animatedVertex formula:
“int bone0Index = int(bone0info.x);”
“float bone0weight = bone0info.y;”
“mat4 bone0matrix = bonesMatrices[bone0Index];”
“int bone1Index = int(bone1info.x);”
“float bone1weight = bone1info.y;”
“mat4 bone1matrix = bonesMatrices[bone1Index];”
“int bone2Index = int(bone2info.x);”
“float bone2weight = bone2info.y;”
“mat4 bone2matrix = bonesMatrices[bone2Index];”
“int bone3Index = int(bone3info.x);”
“float bone3weight = bone3info.y;”
“mat4 bone3matrix = bonesMatrices[bone3Index];”
Now the vertex structure that is filled on the CPU should look like this:
x, y, z, u, v, bone0index, bone0weight, bone1index, bone1weight, bone2index, bone2weight, bone3index, bone3weight
The vertex buffer structure is filled once during model loading, but the transformation matrices are transferred from the CPU to the shader at each rendering frame.
In the remaining parts I will describe the principle of calculating animation on the CPU, before passing it to the vertex shader, I will describe the tree of bone nodes, the passage through the hierarchy animation-model-nodes-mesh, matrix interpolation.
Sources
http://ogldev.atspace.co. uk/www/tutorial38/tutorial38.html
Source code
https://gitlab.com/demensdeum/skeletal-animation