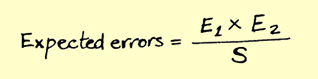Dans cet article, je décrirai ma compréhension de l’animation squelettique, qui est utilisée dans tous les moteurs 3D modernes pour animer des personnages, des environnements de jeu, etc.
Je vais commencer la description par la partie la plus tangible : vertex shader, car l’ensemble du chemin de calcul, aussi complexe soit-il, se termine par le transfert des données préparées pour l’affichage vers le vertex shader.

L’animation du squelette, après avoir été traitée sur le CPU, passe dans le vertex shader.
Laissez-moi vous rappeler la formule du sommet sans animation squelettique :
gl_Position = projectionMatrix * viewMatrix * modelMatrix * sommet;
Pour ceux qui ne comprennent pas comment est née cette formule, vous pouvez lire mon article décrivant le principe du travail avec des matrices pour afficher du contenu 3D dans le contexte d’OpenGL.
Pour le reste – formule pour implémenter l’animation squelettique :
” vec4 animéVertex = bone0matrix * sommet * bone0weight +”
“bone1matrix * sommet * bone1weight +”
“bone2matrix * sommet * bone2weight +”
“bone3matrix * sommet * bone3weight;\n”
” gl_Position = projectionMatrix * viewMatrix * modelMatrix * animationVertex;\n”
C’est-à-dire que nous multiplions la matrice de transformation osseuse finale par le sommet et par le poids de cette matrice par rapport au sommet. Chaque sommet peut être animé par 4 os, la force de l’impact est régulée par le paramètre poids de l’os, la somme des impacts doit être égale à un.
Que faire si moins de 4 os affectent le sommet ? Nous devons diviser le poids entre eux et rendre l’impact du reste égal à zéro.
Mathématiquement, multiplier un poids par une matrice est appelé « multiplication matricielle-scalaire ». La multiplication par un scalaire vous permet de résumer l’effet des matrices sur le sommet résultant.
Les matrices de transformation osseuse elles-mêmes sont transmises sous forme de tableau. De plus, le tableau contient des matrices pour l’ensemble du modèle dans son ensemble, et non pour chaque maillage séparément.
Mais pour chaque sommet les informations suivantes sont transmises séparément :
– Index de la matrice qui affecte le sommet
– Poids de la matrice qui affecte le sommet
Plus d’un os est transmis, généralement l’effet de 4 os sur le sommet est utilisé.
Aussi, la somme des poids des 4 dés doit toujours être égale à un.
Voyons ensuite à quoi cela ressemble dans le shader.
Tableau matriciel :
“uniform mat4 bonesMatrices[kMaxBones];”
Informations sur l’effet de 4 os sur chaque sommet :
“attribut vec2 bone0info;”
“attribut vec2 bone1info;”
“attribut vec2 bone2info;”
“attribut vec2 bone3info;”
vec2 – dans la coordonnée X, nous stockons l’index de l’os (et le convertissons en int dans le shader), dans la coordonnée Y, nous stockons le poids de l’impact de l’os sur le sommet. Pourquoi devez-vous transmettre ces données dans un vecteur bidimensionnel ? Parce que GLSL ne prend pas en charge la transmission de structures lisibles en C avec des champs valides au shader.
Ci-dessous, je vais donner un exemple d’obtention des informations nécessaires à partir d’un vecteur pour une substitution ultérieure dans la formule animationVertex :
“int bone0Index = int(bone0info.x);”
“float bone0weight = bone0info.y;”
“mat4 bone0matrix = bonesMatrices[bone0Index];”
“int bone1Index = int(bone1info.x);”
“float bone1weight = bone1info.y;”
“mat4 bone1matrix = bonesMatrices[bone1Index];”
“int bone2Index = int(bone2info.x);”
“float bone2weight = bone2info.y;”
“mat4 bone2matrix = bonesMatrices[bone2Index];”
“int bone3Index = int(bone3info.x);”
“float bone3weight = bone3info.y;”
“mat4 bone3matrix = bonesMatrices[bone3Index];”
Maintenant, la structure des sommets renseignée sur le processeur devrait ressembler à ceci :
x, y, z, u, v, bone0index, bone0weight, bone1index, bone1weight, bone2index, bone2weight, bone3index, bone3weight
La structure du vertex buffer est remplie une fois lors du chargement du modèle, mais les matrices de transformation sont transférées du CPU vers le shader à chaque image de rendu.
Dans les parties restantes, je décrirai le principe de calcul de l’animation sur le CPU, avant de la transférer vers le vertex shader, je décrirai l’arbre des nœuds osseux, en parcourant la hiérarchie animation-modèle-nœuds-mesh, la matrice interpolation.
Sources
http://ogldev.atspace.co. fr/www/tutorial38/tutorial38.html
Code source
https://gitlab.com/demensdeum/skeletal-animation