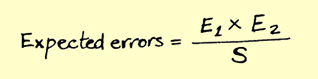In this post I will describe an example of adding functionality to a C ++ application using plugins. The practical part of the implementation for Linux is described; the theory can be found at the links at the end of the article.

To begin with, we will write a plugin – a function that we will call:
#include "iostream" using namespace std; extern "C" void extensionEntryPoint() { cout << "Extension entry point called" << endl; };
Next, we will build the plugin as a dynamic library “extension.so”, which we will connect in the future:
clang++ -shared -fPIC extension.cpp -o extension.so
Next we write the main application that will load the file “extension.so”, look for a pointer to the function “extensionEntryPoint” there, and call it, typing errors if necessary:
#include "iostream" #include "dlfcn.h" using namespace std; typedef void (*VoidFunctionPointer)(); int main (int argc, char *argv[]) { cout << "C++ Plugins Example" << endl; auto extensionHandle = dlopen("./extension.so", RTLD_LAZY); if (!extensionHandle) { string errorString = dlerror(); throw runtime_error(errorString); } auto functionPointer = VoidFunctionPointer(); functionPointer = (VoidFunctionPointer) dlsym(extensionHandle, "extensionEntryPoint"); auto dlsymError = dlerror(); if (dlsymError) { string errorString = dlerror(); throw runtime_error(errorString); } functionPointer(); exit(0); }
The dlopen function returns a handler for working with a dynamic library; dlsym function returns a pointer to the required function by string; dlerror contains a pointer to the string with the error text, if any.
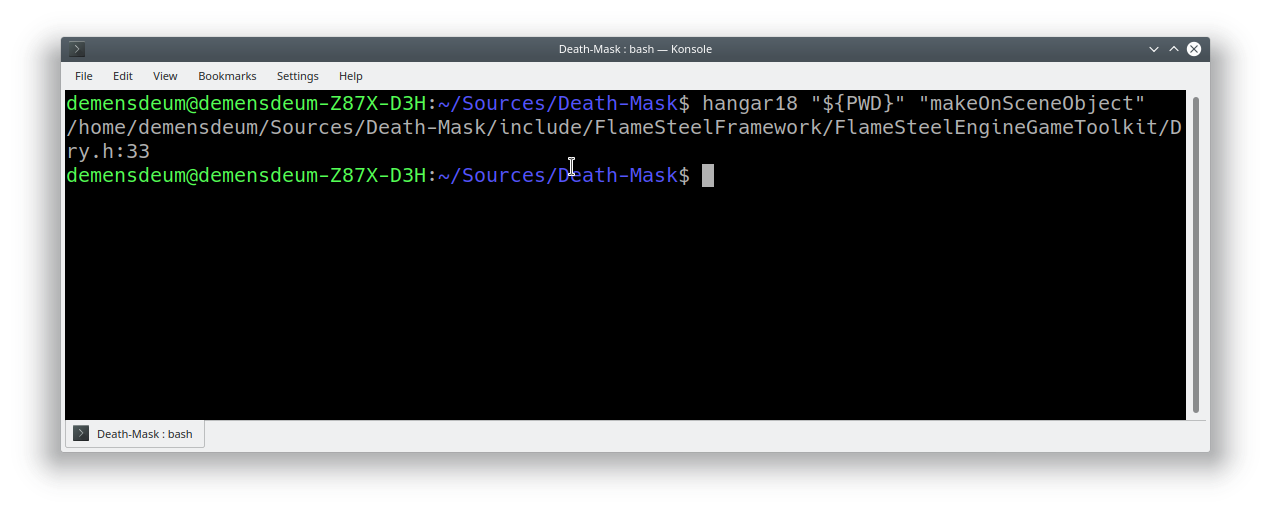
Next, build the main application, copy the file of the dynamic library in the folder with it and run. The output should be the “Extension entry point called”
Example Source Code
https://gitlab.com/demensdeum/cpppluginsexample
Documents
http://man7.org/linux/man-pages/man3/dlopen.3.htm
https://gist.github.com/tailriver/30bf0c943325330b7b6a
https://stackoverflow.com/questions/840501/how-do-function-pointers-in-c-work