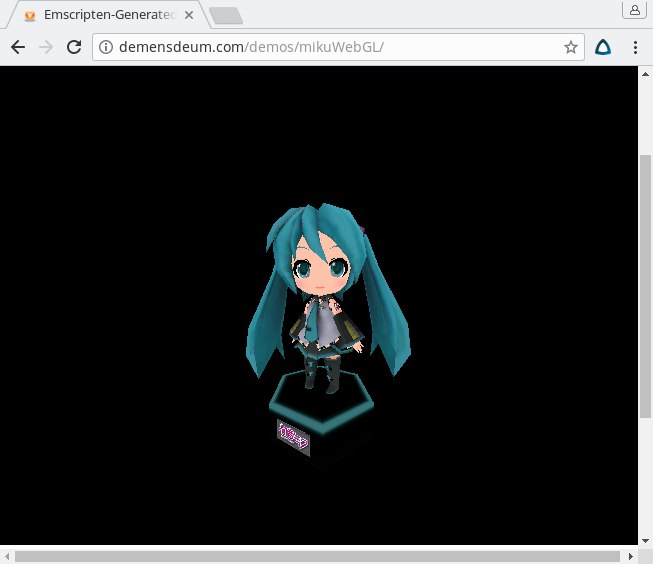
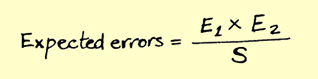Malevich periodically comes to any developer on OpenGL. This happens unexpectedly and boldly, you just start the project and see a black square instead of a wonderful render:
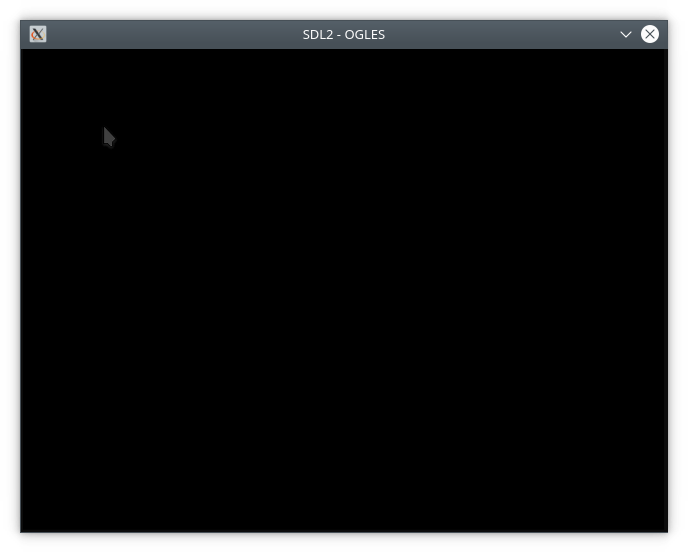
Today I will describe for what reason I was visited by a black square, the problems found because of which Opengl does not draw anything on the screen, and sometimes even makes the window transparent.
Use tools
For debugging Opengl, two tools helped me: renderdoc and and apitrace . Renderdoc – tool for debugging the OpenGL rendering process, you can view everything – Vertexes, shaders, textures, debt messages from the driver. Apitrace – A tool for tracing challenges of a graphic API, makes a dump calls and shows arguments. There is also a great opportunity to compare two dumps via WDIFF (or without, but not so convenient)
Check with whom you work
I have an operating system Ubuntu 16.10 with old dependencies SDL2, GLM, Assimp, Glew. In the latest version of Ubuntu 18.04, I get the assembly of the game Death-Mask which does not show anything on the screen (only a black square). When using Chroot and assembly at 16.10 I I get a working assembly of the game with graphics .

It seems something broke in Ubuntu 18.04
LDD showed the linkka to identical libraries SDL2, GL. Driving a non -working build in Renderdoc, I saw garbage at the entrance to the vertex shader, but I needed a more solid confirmation. In order to understand the difference between the binarics, I drove them both through apitrace . Comparison of dumps showed me that the assembly on a fresh Ubunta breaks the program of the prospects in OpenGL, actually sending garbage there:

Matrices gather in the GLM library. After copying GLM from 16.04 – I got the working build of the game again. The problem was the difference in the initialization of a single matrix in GLM 9.9.0, it is necessary to clearly indicate the MAT4 (1.0F) argument in it in the constructor. Having changed the initialization and by writing off the author of the library, I began to do tests for fsgl . In the process of writing which I found flaws in FSGL, I will describe them further.
Determine who is in life
For the correct work with OpenGL, you need to voluntarily forcibly request the context of a certain version. So it looks for SDL2 (you need to put the version strictly before initializing the context):
sdl_gl_seettrtribute (sdl_gl_context_major_version, 3 );
SDL_GL_SETTRIBUTE (SDL_GL_CONTEXT_MINOR_VERSION, 2 );
SDL_GL_SETTRIBUTE (SDL_GL_CONTEXT_PROFILE_MASK, SDL_GL_CONTEXT_PROFILE_CORE);
For example, Renderdoc does not work with contexts below 3.2. I would like to note that after switching the context there is a high probability of seeing the same black screen . Why?
Because the context of Opengl 3.2 must require the presence of VAO buffer , without which 99% of graphic drivers do not work. Add it easy:
Glgenvertexarrays ( 1 , & vao);
GLBINDVERTEXARAY (VAO);
Do not sleep, freeze
I also met an interesting problem on Kubuntu, instead of a black square I was displayed transparent, and sometimes everything was rendered correctly. I found the solution to this problem at Stack Overflow:
https://stackoverflow.com/questions/38411515/sdl2-opengl-window-appears-semi-transparent-sometimes
The FSGL test render code was also present Sleep (2S) ; So on the Xubuntu and Ubuntu I received the correct render and sent the application to sleep, but on Kubuntu I received a transparent screen in 80% of the launch of Dolphin and 30% of launches and terminal. To solve this problem, I added rendering in each frame, after a SDlevent survey, as recommended in the documentation.
Test code:
https://gitlab.com/demensdeum/FSGLtests/blob/master/renderModelTest/
Talk to the driver
Opengl supports the communication channel between the application and the driver, to activate it, you need to turn on the flags Gl_debug_outPut, GL_DEBUG_OUTPUT_SYNCHRONUS, affix the warning GLDEBUGMESSAGECONTROL and tie the calback through GLDEBUGMESSAGECALLBACK .
An example of initialization can be taken here:
https://github.com/rock-core/gui-vizkit3d/blob/master/src/EnableGLDebugOperation.cpp