In dieser Notiz beschreibe ich meine Erfahrungen und die Erfahrungen meiner Kollegen bei der Arbeit mit dem Singleton-Muster (Singleton in der ausländischen Literatur) während der Arbeit an verschiedenen (erfolgreichen und weniger erfolgreichen) Projekten. Ich werde beschreiben, warum ich persönlich denke, dass dieses Muster nirgendwo verwendet werden kann, und ich werde auch beschreiben, welche psychologischen Faktoren im Team die Integration dieses Antimusters beeinflussen. Gewidmet allen gefallenen und verkrüppelten Entwicklern, die zu verstehen versuchten, warum alles damit begann, dass eines der Teammitglieder einen kleinen süßen Welpen mitbrachte, der leicht zu handhaben war und keine besondere Pflege und Kenntnisse erforderte, um ihn zu pflegen, und mit dem aufgezogenen Biest endete Ihr Projekt als Geisel zu nehmen, erfordert immer mehr Arbeitsstunden und frisst die Nerven des Benutzers, Ihr Geld und schafft absolut monströse Zahlen für die Beurteilung der Umsetzung scheinbar einfacher Dinge Dinge.

Wolf in sheep’s clothing by SarahRichterArt
Die Geschichte spielt in einem alternativen Universum, alle Zufälle sind zufällig…
Streicheln Sie die Katze zu Hause mit Cat@Home
Jeder Mensch verspürt manchmal im Leben den unwiderstehlichen Wunsch, eine Katze zu streicheln. Analysten auf der ganzen Welt gehen davon aus, dass das erste Startup, das eine Anwendung für die Lieferung und Vermietung von Katzen entwickelt hat, äußerst beliebt sein wird und in naher Zukunft für Billionen Dollar von Moogle gekauft wird. Bald passiert das – Ein Mann aus Tjumen erstellt die Anwendung Cat@Home und wird bald zum Billionär, die Firma Moogle erhält eine neue Einnahmequelle und Millionen gestresster Menschen erhalten die Gelegenheit dazu Bestellen Sie eine Katze zum weiteren Bügeln und Beruhigen zu sich nach Hause.
Angriff der Klonkrieger
Ein äußerst reicher Zahnarzt aus Murmansk, Alexey Goloborodko, beeindruckt von einem Artikel über Cat@Home von Forbes, beschließt, dass er auch astronomisch reich sein möchte. Um dieses Ziel zu erreichen, findet er über seine Freunde eine Firma aus Goldfield – Wakeboard DevPops, ein Anbieter von Softwareentwicklungsdiensten, beauftragt das Unternehmen mit der Entwicklung eines Cat@Home-Klons.
Siegerteam
Das Projekt heißt Fur&Pure und wird einem talentierten Entwicklungsteam von 20 Leuten anvertraut; Konzentrieren wir uns als Nächstes auf ein mobiles Entwicklungsteam von 5 Personen. Jedes Teammitglied erhält seinen Teil der Arbeit, bewaffnet mit Agile und Scrum, das Team schließt die Entwicklung pünktlich (in sechs Monaten) ohne Fehler ab, veröffentlicht die Anwendung im iStore, wo sie von 100.000 Benutzern mit 5 bewertet wird, davon gibt es viele Kommentare darüber, wie großartig die Anwendung ist, wie ausgezeichneter Service (immerhin ein alternatives Universum). Die Katzen sind gebügelt, die App ist veröffentlicht, alles scheint gut zu laufen. Allerdings hat Moogle es nicht eilig, ein Startup für Billionen Dollar zu kaufen, denn in Cat@Home sind bereits nicht nur Katzen, sondern auch Hunde aufgetaucht.
Der Hund bellt, die Karawane zieht weiter
Der Eigentümer des Antrags entscheidet, dass es an der Zeit ist, Hunde zum Antrag hinzuzufügen, bittet das Unternehmen um eine Bewertung und erhält ungefähr mindestens sechs Monate Zeit, um Hunde zum Antrag hinzuzufügen. Tatsächlich wird die Anwendung erneut von Grund auf neu geschrieben. Während dieser Zeit wird Moogle Schlangen, Spinnen und Meerschweinchen zur Anwendung hinzufügen und Fur&Pur wird nur Hunde erhalten.
Warum ist das passiert? Schuld daran ist der Mangel an flexibler Anwendungsarchitektur; einer der häufigsten Faktoren ist das Singleton-Anti-Pattern.
Was ist los?
Um eine Katze zu Hause zu bestellen, muss der Verbraucher eine Anfrage erstellen und diese an das Büro senden, wo das Büro die Anfrage bearbeitet und einen Kurier mit der Katze schickt. Der Kurier erhält bereits die Zahlung für die Dienstleistung.
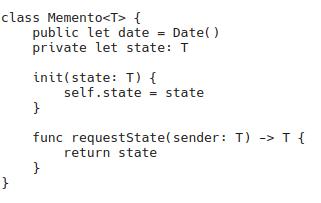
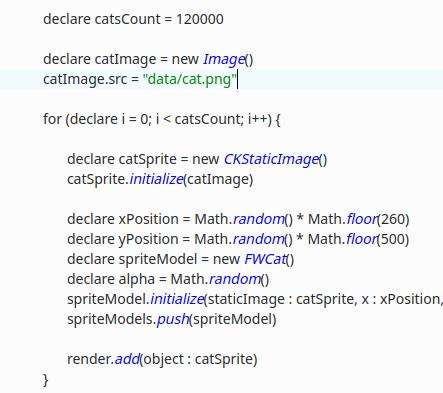
Einer der Programmierer beschließt, eine Klasse „Cat Application“ zu erstellen. mit den notwendigen Feldern bringt diese Klasse über einen Singleton in den globalen Anwendungsraum. Warum macht er das? Um Zeit zu sparen (einen Penny von einer halben Stunde), weil es einfacher ist, eine Anwendung öffentlich zu machen, als die Anwendungsarchitektur zu durchdenken und Abhängigkeitsinjektion zu verwenden. Dann greifen andere Entwickler auf dieses globale Objekt zurück und binden ihre Klassen daran. Zum Beispiel greifen alle Bildschirme selbst auf das globale Objekt „Cat Request“ zu. und Daten zur Anwendung anzeigen. Als Ergebnis wird eine solche monolithische Anwendung getestet und freigegeben.
Alles scheint in Ordnung zu sein, aber plötzlich erscheint ein Kunde mit der Anforderung, Hundewünsche in den Antrag aufzunehmen. Das Team beginnt verzweifelt abzuschätzen, wie viele Komponenten im System von dieser Änderung betroffen sein werden. Am Ende der Analyse stellt sich heraus, dass 60 bis 90 % des Codes wiederholt werden müssen, um der Anwendung beizubringen, nicht nur „Request For Cat“ zu akzeptieren. Aber auch „Bewerbung für einen Hund“ ist es in diesem Stadium bereits sinnlos, die Hinzufügung weiterer Tiere zu bewerten, um mit mindestens zwei zurechtzukommen.
So verhindern Sie Singleton
Machen Sie in der Phase der Anforderungserfassung zunächst ausdrücklich deutlich, dass eine flexible, erweiterbare Architektur erforderlich ist. Zweitens lohnt es sich, nebenbei eine unabhängige Prüfung des Produktcodes durchzuführen und dabei zwingend Schwachstellen zu recherchieren. Wenn Sie Entwickler sind und Singletons lieben, empfehle ich Ihnen, zur Besinnung zu kommen, bevor es zu spät ist, sonst sind schlaflose Nächte und ausgefranste Nerven garantiert. Wenn Sie an einem Legacy-Projekt arbeiten, das viele Singletons enthält, versuchen Sie, diese oder das Projekt so schnell wie möglich zu entfernen.
Sie müssen vom Anti-Pattern von Singletons-globalen Objekten/Variablen zur Abhängigkeitsinjektion wechseln – das einfachste Entwurfsmuster, bei dem alle erforderlichen Daten in der Initialisierungsphase an eine Instanz einer Klasse übergeben werden, ohne dass eine weitere Bindung an den globalen Raum erforderlich ist.
Quellen
https://stackoverflow. com/questions/137975/what-is-so-bad-about-singletons
http://misko.hevery.com/2008/08/17/singletons-are-pathological-liars/
https://blog.ndepend.com/singleton-pattern-costs/