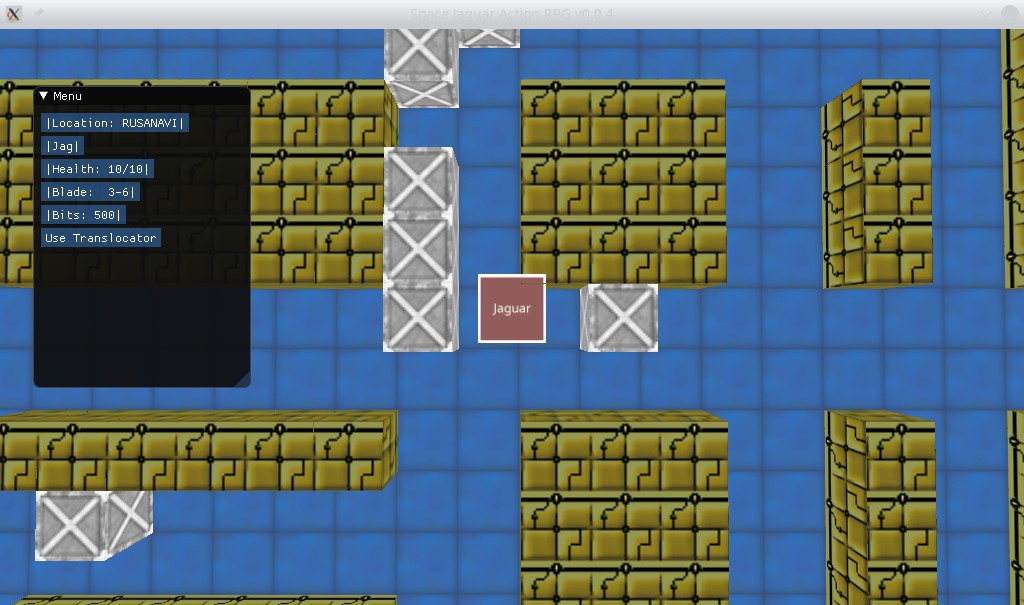
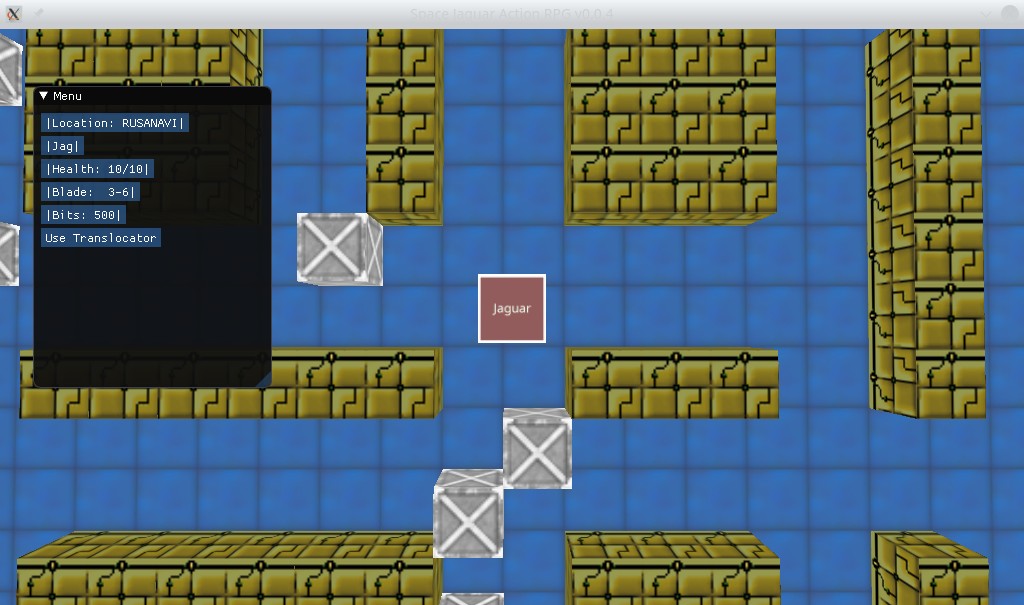
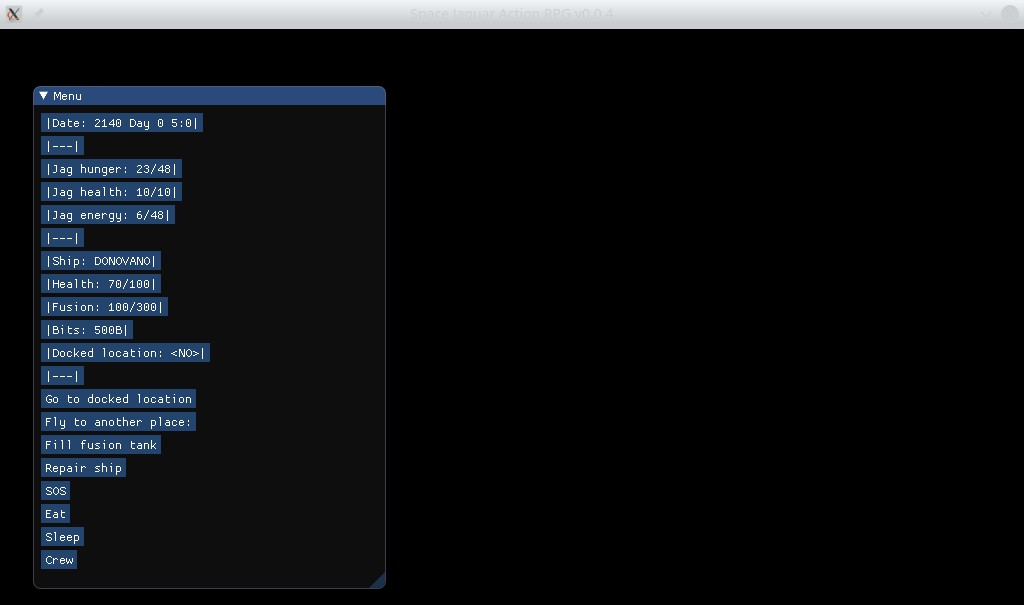
Der erste Prototyp des Space Jaguar Action-RPG-Spiels für Webassembly:
Das Laden dauert lange (53 MB), ohne dass eine Ladeanzeige angezeigt wird.
Space Jaguar Action-Rollenspiel – Lebenssimulator eines Weltraumpiraten. Im Moment stehen die einfachsten Spielmechaniken zur Verfügung:
im Weltraum fliegen
sterben
essen
schlafen
Stellen Sie ein Team ein
Schauen Sie sich den ruhelosen, schnell fliegenden Strom der Zeit an
Aufgrund der schlechten Optimierung der Darstellung von 3D-Szenen in der Webversion ist die Möglichkeit, in einer 3D-Umgebung herumzulaufen, nicht verfügbar. Die Optimierung wird in zukünftigen Versionen hinzugefügt.
Der Quellcode der Engine, des Spiels und der Skripte ist unter der MIT-Lizenz verfügbar. Alle Verbesserungsvorschläge werden äußerst positiv aufgenommen:
In dieser Notiz werde ich über die Bedeutung von Architekturentscheidungen bei der Entwicklung, der Unterstützung einer Anwendung und in einer Teamentwicklungsumgebung schreiben.
In meiner Jugend habe ich an einer Taxi-Bestellanwendung gearbeitet. Im Programm können Sie einen Abholpunkt und einen Abgabepunkt auswählen, die Fahrtkosten und die Tarifart berechnen und tatsächlich ein Taxi bestellen. Ich habe die Anwendung in der letzten Phase des Vorabstarts erhalten; nach dem Hinzufügen mehrerer Korrekturen wurde die Anwendung im AppStore veröffentlicht. Bereits zu diesem Zeitpunkt war dem gesamten Team klar, dass die Implementierung sehr schlecht war, keine Entwurfsmuster verwendet wurden, alle Komponenten des Systems eng miteinander verbunden waren und es im Allgemeinen möglich war, es in eine große kontinuierliche Klasse (Gottobjekt) zu schreiben. Es hätte sich nichts geändert, so wie die Klassen ihre Verantwortungsgrenzen durcheinander brachten und sich in ihrer Gesamtmasse in einer toten Kopplung überlappten. Später beschloss das Management, die Anwendung unter Verwendung der richtigen Architektur von Grund auf neu zu schreiben, was auch geschah und das Endprodukt für mehrere Dutzend B2B-Kunden implementiert wurde.
Ich werde jedoch einen merkwürdigen Vorfall aus der Architektur der Vergangenheit beschreiben, von dem ich manchmal mitten in der Nacht schweißgebadet aufwache oder mich mitten am Tag plötzlich daran erinnere und hysterisch zu lachen beginne. Die Sache ist die, dass ich den Kerl an der Stange beim ersten Mal nicht treffen konnte, was den Großteil der Bewerbung zum Scheitern brachte, aber das Wichtigste zuerst.
Es war ein gewöhnlicher Arbeitstag, einer der Kunden erhielt die Aufgabe, das Anwendungsdesign leicht zu verfeinern – Es ist einfach, das Symbol in der Mitte des Auswahlbildschirms für die Abholadresse um ein paar Pixel nach oben zu verschieben. Nun, nachdem ich die Aufgabe professionell auf 10 Minuten geschätzt hatte, hob ich das Symbol um 20 Pixel an, völlig ahnungslos, und beschloss, den Taxiauftrag zu überprüfen.
Was? Die App zeigt den Bestellbutton nicht mehr an? Wie ist das passiert?
Ich traute meinen Augen nicht; nachdem ich das Symbol um 20 Pixel erhöht hatte, zeigte die Anwendung die Schaltfläche „Bestellung fortsetzen“ nicht mehr an. Nachdem ich die Änderung rückgängig gemacht hatte, sah ich die Schaltfläche wieder. Hier stimmte etwas nicht. Nachdem ich 20 Minuten im Debugger verbracht hatte, hatte ich es ein wenig satt, die vielen Aufrufe überlappender Klassen abzuwickeln, aber ich entdeckte, dass *das Verschieben des Bildes die Logik der Anwendung wirklich verändert*
Es drehte sich alles um das Symbol in der Mitte – Ein Mann auf einer Stange, der beim Bewegen der Karte nach oben sprang, um die Bewegung der Kamera zu animieren. Auf diese Animation folgte das Verschwinden des Knopfes unten. Anscheinend ging das Programm davon aus, dass der um 20 Pixel verschobene Mann einen Sprung machte, und versteckte daher gemäß seiner internen Logik die Bestätigungsschaltfläche.
Wie kann das passieren? Hängt der *Zustand* des Bildschirms wirklich nicht vom Muster der Zustandsmaschine ab, sondern von der *Darstellung* der Position des Mannes auf der Stange?
Es stellte sich heraus, dass jedes Mal, wenn die Karte gezeichnet wurde, die Anwendung *visuell* in die Mitte des Bildschirms gestochen und überprüft, was dort war. Wenn sich ein Mann auf einer Stange befindet, bedeutet dies, dass die Kartenverschiebungsanimation beendet ist und angezeigt werden muss Taste. Wenn der Mann nicht da ist, wird die Karte verschoben und die Schaltfläche muss ausgeblendet werden.
Im obigen Beispiel ist alles in Ordnung, erstens ist es ein Beispiel für Goldberg-Maschinen (abstruse Maschinen), zweitens ein Beispiel für die Zurückhaltung des Entwicklers, irgendwie mit anderen Entwicklern im Team zu interagieren (versuchen Sie, es ohne herauszufinden). Drittens können Sie alle Probleme nach SOLID, Mustern (Code-Smells), MVC-Verletzungen und vielem mehr auflisten.
Versuchen Sie, dies nicht zu tun, entwickeln Sie sich in alle möglichen Richtungen und helfen Sie Ihren Kollegen bei ihrer Arbeit. Frohes neues Jahr euch allen.
In diesem Beitrag beschreibe ich die Arbeit mit dem Fasttext-Textklassifikator.
Fasttext – Bibliothek für maschinelles Lernen zur Textklassifizierung. Versuchen wir ihr beizubringen, eine Metal-Band anhand des Songtitels zu identifizieren. Dazu nutzen wir überwachtes Lernen anhand eines Datensatzes.
Lassen Sie uns einen Datensatz von Liedern mit Gruppennamen erstellen:
В результате мы получим список классов на которые похож данный пример, с указанием уровня похожести цифрой, в нашем случае похожесть названия песни Bleed на одну из групп датасета.
Для того чтобы модель fasttext умела работать с датасетом выходящим за границы обучающей выборки, используют режим autotune с использованием файла валидации (файл тест). Во время автотюна fasttext подбирает оптимальные гиперпараметры модели, проводя валидацию результата на выборке из тест файла. Время автотюна ограничивается пользователем в самостоятельно, с помощью передачи аргумента autotuneDuration.
Пример создания модели с использованием файла тест:
In dieser Notiz beschreibe ich den Prozess des Aufrufs von C-Funktionen aus dem Assembler. Versuchen wir, printf(“Hello World!\n”); aufzurufen. und Exit(0);
message: db "Hello, world!", 10, 0
section .text
extern printf
extern exit
global main
main:
xor rax, rax
mov rdi, message
call printf
xor rdi, rdi
call exit
Alles ist viel einfacher als es scheint. Im Abschnitt .rodata beschreiben wir statische Daten, in diesem Fall die Zeile „Hallo Welt!“, 10 ist ein Zeilenumbruchzeichen und wir vergessen auch nicht, es auf Null zu setzen.
Im Codeabschnitt deklarieren wir die externen Funktionen printf, Exit der stdio- und stdlib-Bibliotheken und deklarieren auch die Eingabefunktion main:
extern printf
extern exit
global main
Wir übergeben 0 von der Rax-Funktion an das Rückgaberegister. Sie können mov rax, 0; aber um es zu beschleunigen, benutzen sie xor rax, rax; Als nächstes übergeben wir einen Zeiger auf die Zeichenfolge an das erste Argument:
In diesem Beitrag beschreibe ich den Prozess der Einrichtung der IDE und schreibe den ersten Hello World in x86_64-Assembler für das Ubuntu-Linux-Betriebssystem. Beginnen wir mit der Installation der SASM-IDE, Nasm-Assembler:
Hello World-Code aus dem Blog James Fisher, angepasst für Assemblierung und Debugging in SASM. In der SASM-Dokumentation heißt es, dass der Einstiegspunkt eine Funktion namens „main“ sein muss, da sonst das Debuggen und Kompilieren des Codes fehlerhaft ist. Was haben wir in diesem Code gemacht? Habe einen Systemaufruf getätigt – Zugriff auf den Kernel des Linux-Betriebssystems mit korrekten Argumenten in Registern, einem Zeiger auf eine Zeichenfolge im Datenabschnitt.
Unter der Lupe
Sehen wir uns den Code genauer an:
global – директива ассемблера позволяющая задавать глобальные символы со строковыми именами. Хорошая аналогия – интерфейсы заголовочных файлов языков C/C++. В данном случае мы задаем символ main для функции входа.
section – директива ассемблера позволяющая задавать секции (сегменты) кода. Директивы section или segment равнозначны. В секции .text помещается код программы.
Обьявляем начало функции main. В ассемблере функции называются подпрограммами (subroutine)
Первая машинная команда mov – помещает значение из аргумента 1 в аргумент 2. В данном случае мы переносим значение регистра rbp в rsp. Из комментария можно понять что эту строку добавил SASM для упрощения отладки. Видимо это личные дела между SASM и дебаггером gdb.
Далее посмотрим на код до сегмента данных .rodata, два вызова syscall, первый выводит строку Hello World, второй обеспечивает выход из приложения с корректным кодом 0.
Представим себе что регистры это переменные с именами rax, rdi, rsi, rdx, r10, r8, r9. По аналогии с высокоуровневыми языками, перевернем вертикальное представление ассемблера в горизонтальное, тогда вызов syscall будет выглядеть так:
Тогда вызов печати текста:
Вызов exit с корректным кодом 0:
Рассмотрим аргументы подробнее, в заголовочном файле asm/unistd_64.h находим номер функции __NR_write – 1, далее в документации смотрим аргументы для write:
ssize_t write(int fd, const void *buf, size_t count);
Первый аргумент – файловый дескриптор, второй – буфер с данными, третий – счетчик байт для записи в дескриптор. Ищем номер файлового дескриптора для стандартного вывода, в мануале по stdout находим код 1. Далее дело за малым, передать указатель на буфер строки Hello World из секции данных .rodata – msg, счетчик байт – msglen, передать в регистры rax, rdi, rsi, rdx корректные аргументы и вызвать syscall.
Обозначение константных строк и длины описывается в мануале nasm:
Der erste Artikel über das in der Entwicklung befindliche Spiel, Space Jaguar Action RPG. In diesem Artikel beschreibe ich die Gameplay-Funktion des Jaguar – Eigenschaften.
Viele Rollenspiele verwenden ein statisches Charakterstatistiksystem, wie zum Beispiel die Statistiken von DnD (Stärke, Konstitution, Geschicklichkeit, Intelligenz, Weisheit, Charisma) oder Fallout – S.P.E.C.I.A.L (Stärke, Wahrnehmung, Ausdauer, Charisma, Intelligenz, Geschicklichkeit, Glück). ).
In Space Jaguar plane ich die Implementierung eines dynamischen Systems von Eigenschaften. Beispielsweise hat die Hauptfigur des Spiels Jag zu Beginn nur drei Eigenschaften – Beherrschung einer Klinge (Halbsäbel), zwielichtige Operationen (Geschäfte in der kriminellen Welt abschließen), Schurkenfähigkeiten (Schlösser knacken, Diebstahl). Während des Spiels werden den Charakteren im Rahmen des Spielmoduls dynamische Eigenschaften verliehen und entzogen. Alle Überprüfungen erfolgen auf der Grundlage des Niveaus bestimmter Eigenschaften, die für eine bestimmte Spielsituation erforderlich sind. Beispielsweise kann Jag eine Schachpartie nicht gewinnen, wenn er nicht über die Eigenschaft verfügt, Schach zu spielen, oder nicht über ein ausreichendes Level verfügt, um die Prüfung zu bestehen.
Zur Vereinfachung der Prüflogik erhält jedes Merkmal einen 6-stelligen Code in englischen Buchstaben, einen Namen und eine Beschreibung. Um beispielsweise eine Klinge zu besitzen:
Перед стартом игрового модуля можно будет просмотреть список публичных проверок необходимых для прохождения, также создатель может скрыть часть проверок для создания интересных игровых ситуаций.
Ноу-хау? Будет ли интересно? Лично я нахожу такую систему интересной, позволяющей одновременно обеспечить свободу творчества создателям игровых модулей, и возможность переноса персонажей из разных, но похожих по характеристикам, модулей для игроков.
Mit der Hash-Tabelle können Sie eine assoziative Array-Datenstruktur (Wörterbuch) mit einer durchschnittlichen Leistung von O(1) für Einfüge-, Lösch- und Suchvorgänge implementieren.
Unten finden Sie ein Beispiel für die einfachste Implementierung einer Hash-Map in nodeJS:
Wie funktioniert es? Passen Sie auf Ihre Hände auf:
Innerhalb der Hash-Map befindet sich ein Array
Im Array-Element befindet sich ein Zeiger auf den ersten Knoten der verknüpften Liste
Speicher wird für ein Array von Zeigern zugewiesen (z. B. 65535 Elemente)
Sie implementieren eine Hash-Funktion, der Wörterbuchschlüssel ist die Eingabe, und am Ausgang kann sie alles tun, aber am Ende gibt sie den Index des Array-Elements zurück
So funktioniert die Aufnahme:
Am Eingang liegt ein Schlüsselpaar – Wert
Hash-Funktion gibt Index nach Schlüssel zurück
Einen verknüpften Listenknoten aus einem Array nach Index abrufen
Überprüfen Sie, ob es mit dem Schlüssel übereinstimmt
Wenn es übereinstimmt, ersetzen Sie den Wert
Wenn es nicht übereinstimmt, fahren Sie mit dem nächsten Knoten fort, bis wir einen Knoten mit dem erforderlichen Schlüssel finden oder finden.
Wenn der Knoten immer noch nicht gefunden wird, erstellen Sie ihn am Ende der verknüpften Liste
So funktioniert die Suche nach Schlüssel:
Am Eingang liegt ein Schlüsselpaar – Wert
Hash-Funktion gibt Index nach Schlüssel zurück
Einen verknüpften Listenknoten aus einem Array nach Index abrufen
Überprüfen Sie, ob es mit dem Schlüssel übereinstimmt
Wenn es übereinstimmt, wird der Wert zurückgegeben
Wenn es nicht übereinstimmt, fahren Sie mit dem nächsten Knoten fort, bis wir einen Knoten mit dem erforderlichen Schlüssel finden oder finden.
Warum brauchen wir eine verknüpfte Liste innerhalb eines Arrays? Aufgrund möglicher Kollisionen bei der Berechnung der Hash-Funktion. In diesem Fall befinden sich mehrere verschiedene Schlüssel-Wert-Paare am selben Index im Array. In diesem Fall wird die verknüpfte Liste durchlaufen, um den erforderlichen Schlüssel zu finden.
Um mit Ressourcen in Android über ndk zu arbeiten – C++ gibt es mehrere Möglichkeiten:
Verwenden Sie den Zugriff auf Ressourcen aus einer APK-Datei mit AssetManager
Laden Sie Ressourcen aus dem Internet herunter, entpacken Sie sie in das Anwendungsverzeichnis und verwenden Sie sie mit Standard-C++-Methoden
Kombinierte Methode – Greifen Sie über AssetManager auf das Archiv mit Ressourcen in der APK zu, entpacken Sie sie in das Anwendungsverzeichnis und verwenden Sie sie dann mit Standard-C++-Methoden
Als nächstes werde ich die kombinierte Zugriffsmethode beschreiben, die in der Flame Steel Engine-Spiel-Engine verwendet wird. Wenn Sie SDL verwenden, können Sie den Zugriff auf Ressourcen von einer APK aus vereinfachen. Die Bibliothek umschließt Aufrufe an AssetManager und bietet Schnittstellen ähnlich wie stdio (fopen, fread, fclose usw.).
Nachdem Sie das Archiv von der APK in den Puffer heruntergeladen haben, müssen Sie das aktuelle Arbeitsverzeichnis in das Anwendungsverzeichnis ändern. Es steht der Anwendung zur Verfügung, ohne dass zusätzliche Berechtigungen eingeholt werden müssen. Dazu verwenden wir einen SDL-Wrapper:
chdir(SDL_AndroidGetInternalStoragePath());
Als nächstes schreiben Sie das Archiv mit fopen, fwrite, fclose aus dem Puffer in das aktuelle Arbeitsverzeichnis. Sobald sich das Archiv in einem für C++ zugänglichen Verzeichnis befindet, entpacken Sie es. Zip-Archive können mit einer Kombination aus zwei Bibliotheken entpackt werden – minizip und zlib, das erste kann mit der Struktur von Archiven arbeiten, während das zweite Daten entpackt. Um mehr Kontrolle zu erlangen und die Portierung zu vereinfachen, habe ich mein eigenes Archivformat ohne Komprimierung namens FSCest (Flame Steel Chest) implementiert. Dieses Format unterstützt das Archivieren eines Verzeichnisses mit Dateien und das Entpacken; Es gibt keine Unterstützung für die Ordnerhierarchie; Sie können nur mit Dateien arbeiten. Wir verbinden den Header der FSCest-Bibliothek, entpacken das Archiv:
Nach dem Entpacken haben die C/C++-Schnittstellen Zugriff auf die Dateien aus dem Archiv. Daher musste ich nicht die gesamte Arbeit mit Dateien in der Engine neu schreiben, sondern fügte nur das Entpacken von Dateien in der Startphase hinzu.
Angenommen, wir müssen einen einfachen Bytecode-Interpreter implementieren. Welchen Ansatz zur Implementierung dieser Aufgabe sollten wir wählen?
Datenstruktur Der Stack bietet die Möglichkeit, eine einfache Bytecode-Maschine zu implementieren. Funktionen und Implementierungen von Stack-Maschinen werden in vielen Artikeln im westlichen und inländischen Internet beschrieben; ich möchte nur erwähnen, dass die Java Virtual Machine ein Beispiel für eine Stack-Maschine ist.
Das Funktionsprinzip der Maschine ist einfach: Ein Programm mit Daten und Operationscodes (Opcodes) wird dem Eingang zugeführt und die erforderlichen Operationen werden durch Manipulationen am Stapel implementiert. Schauen wir uns ein Beispiel-Bytecode-Programm von meiner Stack-Maschine an:
пMVkcatS olleHП
Am Ausgang erhalten wir die Zeichenfolge „Hello StackVM“. Die Stapelmaschine liest das Programm von links nach rechts und lädt Daten Zeichen für Zeichen auf den Stapel, wenn ein Opcode im Symbol – implementiert den Befehl mithilfe des Stapels.
Beispiel für die Implementierung einer Stack-Maschine in nodejs:
Umgekehrte polnische Notation (RPN)
Stack -Maschinen sind auch einfach zum Implementieren von Taschenrechnern zu verwenden. Dafür verwenden sie umgekehrte polnische Notation (Postfix -Notation). Beispiel einer regulären Infix-Notation: 2*2+3*4
Konvertiert in RPN: 22*34*+
Um den Postfix-Datensatz zu zählen, verwenden wir eine Stapelmaschine: 2– an die Spitze des Stapels (Stapel: 2) 2– an die Spitze des Stapels (Stapel: 2,2) *– Holen Sie sich zweimal die Oberseite des Stapels, multiplizieren Sie das Ergebnis und senden Sie es an die Oberseite des Stapels (Stapel: 4) 3– an die Spitze des Stapels (Stapel: 4, 3) 4– an die Spitze des Stapels (Stapel: 4, 3, 4) *– Holen Sie sich zweimal die Oberseite des Stapels, multiplizieren Sie das Ergebnis und senden Sie es an die Oberseite des Stapels (Stapel: 4, 12) +– Holen Sie sich zweimal die Spitze des Stapels, addieren Sie das Ergebnis und senden Sie es an die Spitze des Stapels (Stapel: 16)
Wie Sie sehen können – Das Ergebnis der Operationen 16 verbleibt auf dem Stapel. Es kann durch Implementierung von Stapeldruck-Opcodes gedruckt werden, zum Beispiel: p22*34*+P
P – Stapeldruck-Start-Opcode, p – Opcode zum Fertigstellen des Stapeldrucks und zum Senden der letzten Zeile zum Rendern. Um arithmetische Operationen von Infix in Postfix umzuwandeln, wird der Algorithmus „Sorting Yard“ von Edsger Dijkstra verwendet. Ein Beispiel für die Implementierung finden Sie oben oder im Repository des NodeJS-Maschinenstack-Projekts unten.
Ich beschreibe weiterhin den Skelettanimationsalgorithmus, wie er in der Flame Steel Engine implementiert ist.
Da der Algorithmus der komplexeste von allen ist, die ich implementiert habe, können in den Notizen zum Entwicklungsprozess Fehler auftreten. Im vorherigen Artikel über diesen Algorithmus habe ich einen Fehler gemacht; das Array von Knochen wird für jedes Netz separat und nicht für das gesamte Modell an den Shader übertragen.
Knotenhierarchie
Damit der Algorithmus korrekt funktioniert, ist es notwendig, dass das Modell eine Verbindung zwischen den Knochen untereinander enthält (Grafik). Stellen wir uns eine Situation vor, in der zwei Animationen gleichzeitig abgespielt werden – Springe und hebe deine rechte Hand. Die Sprunganimation muss das Modell entlang der Y-Achse anheben, während die Animation zum Anheben des Arms dies berücksichtigen und beim Springen mit dem Modell ansteigen muss, sonst bleibt der Arm von selbst an Ort und Stelle.
Wir werden die Verbindung von Knoten für diesen Fall beschreiben – Der Körper enthält die Hand. Bei der Ausarbeitung des Algorithmus wird der Knochengraph ausgelesen, alle Animationen werden mit den richtigen Verbindungen berücksichtigt. Im Speicher des Modells wird das Diagramm getrennt von allen Animationen gespeichert, nur um die Konnektivität der Knochen des Modells widerzuspiegeln.
Interpolation auf der CPU
Im letzten Artikel habe ich das Prinzip des Renderns von Skelettanimationen beschrieben – „Transformationsmatrizen werden bei jedem Rendering-Frame von der CPU an den Shader übertragen.“
Jeder Rendering-Frame wird auf der CPU verarbeitet; für jeden Mesh-Bone erhält die Engine die endgültige Transformationsmatrix mithilfe von Positionsinterpolation, Drehung und Zoom. Während der Interpolation der endgültigen Knochenmatrix wird für alle aktiven Knotenanimationen ein Durchlauf durch den Knotenbaum durchgeführt, die endgültige Matrix wird mit den übergeordneten Matrix multipliziert und dann zum Rendern an den Vertex-Shader gesendet.
Vektoren werden zur Positionsinterpolation und Vergrößerung verwendet; Quaternionen werden zur Rotation verwendet, weil Sie sind im Gegensatz zu Euler-Winkeln sehr einfach zu interpolieren (SLERP) und auch sehr einfach als Transformationsmatrix darzustellen.
So vereinfachen Sie die Implementierung
Um das Debuggen des Vertex-Shaders zu vereinfachen, habe ich mithilfe des Makros FSGLOGLNEWAGERENDERER_CPU_BASED_VERTEX_MODS_ENABLED eine Simulation des Vertex-Shaders auf der CPU hinzugefügt. Der Grafikkartenhersteller NVIDIA verfügt über ein Dienstprogramm zum Debuggen von Shader-Code, Nsight. Vielleicht kann es auch die Entwicklung komplexer Vertex-/Pixel-Shader-Algorithmen vereinfachen, aber ich konnte seine Funktionalität nie ausreichend auf der CPU testen.
Im nächsten Artikel möchte ich das Mischen mehrerer Animationen beschreiben und die verbleibenden Lücken schließen.
In diesem Beitrag beschreibe ich eine Möglichkeit, mithilfe der Tiny-JS-Bibliothek Unterstützung für JavaScript-Skripte zu einer C++-Anwendung hinzuzufügen.
Tiny-JS ist eine Bibliothek zum Einbetten in C++, die die Ausführung von JavaScript-Code ermöglicht und Bindungen unterstützt (die Möglichkeit, C++-Code aus Skripten aufzurufen)
Zuerst wollte ich die beliebten Bibliotheken ChaiScript, Duktape oder Connect Lua verwenden, aber aufgrund von Abhängigkeiten und möglichen Schwierigkeiten bei der Portabilität auf verschiedene Plattformen entschied ich mich, eine einfache, minimale, aber leistungsstarke MIT Tiny-Bibliothek zu finden; JS erfüllt diese Kriterien. Der einzige Nachteil dieser Bibliothek ist die fehlende Unterstützung/Entwicklung durch den Autor, ihr Code ist jedoch recht einfach, sodass Sie bei Bedarf die Unterstützung übernehmen können.
In diesem Beitrag beschreibe ich das Verfahren zum Erstellen einer C++-SDL-Anwendung für iOS unter Linux, zum Signieren eines IPA-Archivs ohne kostenpflichtiges Apple Developer-Abonnement und zum Installieren auf einem sauberen Gerät (iPad) mit macOS ohne Jailbreak.< /p>
Im Moment müssen Sie Xcode dmg herunterladen und das SDK von dort kopieren, um den cctools-Port zu erstellen. Dieser Schritt ist unter macOS einfacher durchzuführen; kopieren Sie einfach die erforderlichen SDK-Dateien aus dem installierten Xcode. Nach erfolgreicher Assemblierung enthält das Terminal den Pfad zur Cross-Compiler-Toolchain.
Als nächstes können Sie mit der Erstellung der SDL-Anwendung für iOS beginnen. Öffnen wir cmake und fügen die notwendigen Änderungen hinzu, um den C++-Code zu erstellen:
In meinem Fall werden die Bibliotheken SDL, SDL_Image und SDL_mixer vorab in Xcode unter macOS für die statische Verknüpfung kompiliert; Von Xcode kopierte Frameworks. Außerdem wurde die Bibliothek libclang_rt.ios.a hinzugefügt, die iOS-spezifische Laufzeitaufrufe enthält, beispielsweise isOSVersionAtLeast. Für die Arbeit mit OpenGL ES ist ein Makro enthalten, das ähnlich wie bei Android nicht unterstützte Funktionen in der mobilen Version deaktiviert.
Nachdem Sie alle Build-Probleme gelöst haben, sollten Sie die zusammengestellte Binärdatei für arm erhalten. Betrachten wir als Nächstes die Ausführung der zusammengestellten Binärdatei auf einem Gerät ohne Jailbreak.
Installieren Sie unter macOS Xcode, registrieren Sie sich im Apple-Portal, ohne für das Entwicklerprogramm zu bezahlen. Fügen Sie ein Konto in Xcode hinzu -> Einstellungen -> Konten, erstellen Sie eine leere Anwendung und bauen Sie auf einem echten Gerät auf. Während der Montage wird das Gerät dem kostenlosen Entwicklerkonto hinzugefügt. Nach der Zusammenstellung und dem Start müssen Sie das Archiv erstellen. Wählen Sie dazu „Generisches iOS-Gerät und -Produkt“ aus. Archiv. Sobald das Archiv erstellt ist, extrahieren Sie die Dateien „embedded.mobileprovision“ und „PkgInfo“ daraus. Suchen Sie im Build-Protokoll auf dem Gerät die Codesign-Zeile mit dem richtigen Signaturschlüssel und den Pfad zur Berechtigungsdatei mit der Erweiterung app.xcent und kopieren Sie sie.
Kopieren Sie den .app-Ordner aus dem Archiv, ersetzen Sie die Binärdatei im Archiv durch eine, die von einem Cross-Compiler unter Linux kompiliert wurde (z. B. SpaceJaguar.app/SpaceJaguar), fügen Sie dann die erforderlichen Ressourcen zur .app hinzu und überprüfen Sie die Integrität der Dateien „PkgInfo“ und „embedded.mobileprovision“ in der .app aus dem Archiv, ggf. erneut kopieren. Wir signieren die .app erneut mit dem Codesign-Befehl – Codesign erfordert einen Eingabeschlüssel für sign, den Pfad zur Berechtigungsdatei (kann mit der Erweiterung .plist umbenannt werden)
Erstellen Sie nach dem erneuten Signieren einen Payload-Ordner, verschieben Sie den Ordner mit der Erweiterung .app dorthin, erstellen Sie ein Zip-Archiv mit Payload im Stammverzeichnis und benennen Sie das Archiv mit der Erweiterung .ipa um. Öffnen Sie anschließend in Xcode die Geräteliste und ziehen Sie das neue ipa per Drag & Drop in die Anwendungsliste des Geräts. Die Installation über Apple Configurator 2 funktioniert bei dieser Methode nicht. Wenn die Neusignierung korrekt durchgeführt wurde, wird die Anwendung mit der neuen Binärdatei auf einem iOS-Gerät (z. B. iPad) mit einem 7-Tage-Zertifikat installiert, das reicht für den Testzeitraum.
Die vierte Ausgabe einer sehr inkonsistenten Kolumne über Games Vision-Spiele.
World Of Horror (plattformübergreifend, panstasz) – schurkenhaftes Early-Access-Spiel im Stil äh was? Text-Horror-Adventure mit RPG-Elementen? Grafisch erinnert es an Spiele der 80er Jahre. Sie können zwischen einer 1-Bit- oder 2-Bit-Palette mit Variationen wählen.
Die Steuerung scheint zunächst seltsam, aber mit der Zeit gewöhnt man sich daran, denn deshalb ist es ein Roguelike – in jeder Hinsicht zu überraschen und originell zu sein. Erstaunliche Chiptune-Musik, japanische Ästhetik der späten 80er, von der Arbeit von Junji Ito inspirierte Visuals, seltsame Geschichten im Stil von Lovecraft, nahezu endloser Wiederspielwert. Was brauchen Sie noch? Bewertung: 9/10
Eternal Castle [REMASTERED] (PC, Daniele Vicinanzo, Giulio Perrone, Leonard Menchiari) – ein modernes Spiel im Stil von Another World, Flashback. Die Palette wurde speziell auf CGA-Farben reduziert. Die Beschreibung dieses Spiels muss mit der Legende seiner Entstehung beginnen: Etwa 1987 sah eines der Kinder der Eternal Castle-Entwickler das Spiel und erinnerte sich für den Rest seines Lebens daran. Infolgedessen wurde das Spiel nie veröffentlicht Der Quellcode wurde 2019 gefunden und wiederhergestellt, wodurch eine verbesserte Version veröffentlicht wurde. Die Beschreibung auf Steam enthält jedoch Hinweise darauf, dass es sich um ein Remaster eines Bestsellers aus dem Jahr 1987 handelt, in diesem Jahr jedoch kein Spiel mit diesem Namen veröffentlicht wurde. Was wahr ist und was nicht, liegt bei Ihnen.
Die Grafik und das Gameplay sind eindeutig auf diejenigen zugeschnitten, die sich gerne an die guten alten Zeiten erinnern; sehr oft gibt es Momente, in denen es scheint, als sei das Spiel eingefroren, aber in Wirklichkeit muss man nur die Bewegungs- oder Aktionstasten drücken, um zu sehen, was passiert auf dem Bildschirm. Dieses Gimmick erzeugt ein Gefühl der Unbeholfenheit und des Kontrollverlusts, das in älteren Spielen oft verwendet wurde, in modernen Spielen jedoch völlig aufgegeben wurde. Bewertung: 8/10
Tod & Steuern (PC, Placeholder Gameworks) – Haben Sie jemals davon geträumt, gleichzeitig als Richter und Henker zu arbeiten? Magst du lange schwarze Roben, Metallzöpfe und das Knacken deiner Knöchel? Dann ist dies das perfekte Spiel für Sie, denn „Die einzigen zwei Dinge, die Sie nicht vermeiden können, sind Tod und Steuern.“
Dies ist ein einzigartiger Simulator des Todesengels. Sie müssen entscheiden, wer lebt und wer stirbt. Zusätzlich zum Töten oder Geben von Leben können Sie den Newsfeed auf Ihrem Smartphone lesen und sehen, wie sich Ihre Wahl auf die Welt der Erde auswirkt. Sie müssen auch mit Ihrem direkten Vorgesetzten namens Faith (Schicksal) kommunizieren, Gegenstände und alle möglichen Utensilien für den Tisch kaufen, zum Beispiel habe ich mir einen brutalen Kaktus gekauft. Vergessen Sie nicht, mit dem Spiegel zu sprechen, es ist sehr aufregend. Unter den Minuspunkten ist die allgemeine Intimität des Geschehens zu erwähnen; nach ein paar Tagen im Spiel wird das Spiel etwas eintönig. Bewertung: 8/10
Nachdem ich den HP Pavilion Laptop 1,5 Jahre lang mit einer Dual-HDD (Windows 10) und SSD (Ubuntu) verwendet hatte, bemerkte ich sehr lange Ladezeiten für Anwendungen, eine allgemeine Nichtreaktion der Benutzeroberfläche und ein Einfrieren bei den einfachsten Vorgängen in Windows 10. Das Problem wurde soweit minimiert, dass der Laptop wieder verwendet werden konnte. Als Nächstes beschreibe ich die Schritte, die ich unternommen habe, um das Problem zu beheben.
Diagnose
Um mit der Forschung zu beginnen, müssen wir zunächst jede Art von Falschmeldung beseitigen. Lassen Sie uns die Hauptursachen für Festplattenausfälle ermitteln. Was kann beim Arbeiten mit einer Festplatte schiefgehen? Probleme können auf der physischen Ebene der Elektronik und auf der logischen Software-Datenebene auftreten. Zu den elektronischen Problemen gehören beispielsweise: ein nicht funktionierendes Computer-/Laptop-Netzteil, Probleme mit dem Laptop-Akku; Abnutzung von Festplattenkomponenten, Probleme in den Schaltkreisen und Chips der internen Komponenten des Laufwerks, Firmware-Fehler, Folgen von Stößen/Stürzen des Laufwerks oder ähnliche Probleme mit anderen Geräten, die seinen Betrieb beeinträchtigen. Als kritischer Verschleiß einer Festplatte gilt der Moment, in dem so viele fehlerhafte Sektoren (Bad Block) auftreten, dass ein weiterer Betrieb der Festplatte unmöglich ist. Diese Blöcke werden von der Festplatten-Firmware blockiert, die Daten werden automatisch in andere Sektoren übertragen und sollten den Betrieb der Festplatte bis zu einem bestimmten kritischen Moment nicht beeinträchtigen. Zu den Programmlogikproblemen gehören Fehler im Dateisystem aufgrund fehlerhafter Ausführung von Anwendungen, Benutzeraktionen: Ausschalten des Geräts im heißen Zustand, Abschließen von Aufzeichnungsvorgängen ohne ordnungsgemäßes Stoppen von Anwendungen, Fehler in Treibern und Betriebssystemdiensten. Ohne spezielle elektronische Diagnosetools können wir nur die Richtigkeit des Softwarestands überprüfen. Dabei können elektronische Probleme entdeckt werden, die normalerweise durch die Blockreparaturmethode (Austausch von Komponenten/Chips) behoben werden. Als nächstes betrachten wir Softwarediagnosemethoden mithilfe von Diagnosedienstprogrammen. Es ist zu beachten, dass alle Dienstprogramme mit höchster Priorität auf dem System gestartet werden müssen, denn Andere Anwendungen können die Leistungsmessung beeinträchtigen und die Festplatte beim Lesen/Schreiben blockieren, was zu falschen Diagnoseergebnissen führt.
SMART
S.M.A.R.T. Speichergeräte-Statusüberwachungssystem – HDD, SDD, eMMC usw. Ermöglicht Ihnen, den Verschleiß des Geräts zu bewerten, die Anzahl fehlerhafter Blöcke anzuzeigen und basierend auf den Daten weitere Maßnahmen zu ergreifen. Sie können SMART in verschiedenen Anwendungen zum Arbeiten mit Datenträgern anzeigen. Ich bevorzuge die Verwendung von Dienstprogrammen des Herstellers. Für meine Seagate-Festplatte habe ich das Dienstprogramm SeaTools verwendet, dessen Status als GUT angezeigt wurde, d. h. die Festplatten-Firmware geht davon aus, dass alles in Ordnung ist.
Dienstprogramme des Herstellers
Die Dienstprogramme des Festplattenherstellers bieten Tests zur Überprüfung der Funktionsfähigkeit an. SeaTools verfügt über mehrere Arten von Tests. Sie können sie alle verwenden, um das Problem zu lokalisieren. Schnelle und einfache Tests offenbaren möglicherweise keine Probleme, bevorzugen Sie daher lange Tests. In meinem Fall hat nur Long Test Fehler gefunden.
Während der Softwarediagnose wurden keine Elektronikprobleme festgestellt; das blockweise Lesen der gesamten Festplatte wurde korrekt abgeschlossen, aber SeaTools zeigte während des Langzeittests Fehler.
Dienstprogramme des Herstellers
Zusätzlich zur Diagnose bietet die Software des Festplattenherstellers Fehlerkorrekturverfahren. In SeaTools ist hierfür die Schaltfläche „Alle reparieren“ zuständig; nach Bestätigung Ihrer Zustimmung zum möglichen Datenverlust beginnt der Korrekturvorgang. Hat dieser Fix in meinem Fall geholfen? Nein, die Festplatte arbeitete weiterhin laut und langsam, aber der Langzeittest zeigte keine Fehler mehr.
CHKDSK
CHKSDK ist ein Microsoft-Dienstprogramm zur Fehlerbehebung von Softwarefehlern für Windows-Dateisysteme. Mit der Zeit sammeln sich solche Fehler auf der Festplatte an und können die Arbeit stark beeinträchtigen, bis hin zur Unfähigkeit, überhaupt Daten zu lesen/schreiben. Anweisungen zur Verwendung des Dienstprogramms finden Sie auf der Microsoft-Website. Ich empfehle jedoch, alle möglichen Flags zu verwenden, um Fehler zu beheben (zum Zeitpunkt des Verfassens dieses Artikels ist dies /r /b /f); Sie müssen den Scan mit Administratorrechten über das Windows-Terminal (cmd) ausführen. Für die Systempartition erfolgt er beim Systemstart und kann sehr lange dauern, in meinem Fall dauerte er 12 Stunden. Hat dieser Fix in meinem Fall geholfen? Nein.
Festplattendefragmentierung
Daten auf der Festplatte werden in Blöcken verarbeitet; große Dateien werden normalerweise in mehreren Blöcken/Fragmenten geschrieben. Im Laufe der Zeit erzeugen viele gelöschte Dateien leere Blöcke, die nicht in der Nähe sind. Aus diesem Grund füllen sie beim Schreiben von Dateien diese Lücken und der Plattenkopf muss physisch weite Strecken zurücklegen. Dieses Problem wird Fragmentierung genannt und tritt nur bei Festplattenbenutzern auf. Zum Zeitpunkt mehrerer Korrekturen betrug die Fragmentierung meiner Festplatte 41 %, optisch sah es so aus:
Das heißt, alles ist schlecht. Sie können die Fragmentierung erkennen und mit dem Defragmentierungsprogramm oder dem integrierten Defragmentierer defragmentieren. Sie können auch den Dienst „Laufwerke optimieren“ aktivieren. Planen Sie in Windows 10 die Defragmentierung in der Systemsteuerung. Nur HDD-Laufwerke benötigen eine Defragmentierung; es ist nicht ratsam, sie für SSD-Laufwerke zu aktivieren, da dies zu einem beschleunigten Festplattenverschleiß führt. Aus diesem Grund ist die Hintergrunddefragmentierung offenbar standardmäßig deaktiviert.
Eine alternative Defragmentierungsoption ist ebenfalls bekannt – Übertragen von Daten auf eine andere Festplatte, Formatieren der Festplatte und Zurückkopieren der Daten. In diesem Fall werden die Daten in völlig leere Sektoren geschrieben, während die korrekte logische Struktur für den Systembetrieb beibehalten wird. Diese Option ist mit Problemen beim Zurücksetzen potenziell kritischer Metadaten behaftet, die beim normalen Kopieren möglicherweise nicht verschoben werden.
Dienste deaktivieren
Verwenden des Dienstprogramms Process Monitor von Mark Russinovich Sie können die Prozesse verfolgen, die die Festplatte mit ihrer Arbeit belasten, indem Sie einfach die Spalten „IO Write/Read“ aktivieren. Nachdem ich diese Kolumne recherchiert hatte, habe ich den Xbox Game Bar-Dienst, den bekannten Hintergrundbeschleunigungsdienst für Superfetch-Programme unter dem neuen Namen SysMain, über das Bedienfeld „Dienste“ deaktiviert. Superfetch muss ständig die vom Benutzer verwendeten Anwendungen analysieren und deren Start durch Zwischenspeichern im RAM beschleunigen. Dies führte in meinem Fall dazu, dass die gesamte Festplatte im Hintergrund geladen wurde und nicht mehr funktionierte.
Reinigen der Festplatte
Ich habe auch alte Anwendungen und unnötige Dateien gelöscht, wodurch Sektoren für eine korrekte Fragmentierung frei wurden, die Bedienung des Betriebssystems vereinfacht und die Anzahl nutzloser, schwerer Dienste und Programme reduziert wurde.
Gesamt
Was hat am meisten geholfen? Ein spürbarer Leistungsunterschied wurde nach der Defragmentierung der Festplatte erzielt; spontane Einfrierungen wurden durch die Deaktivierung der Xbox- und Superfetch-Dienste beseitigt. Würden diese Probleme nicht auftreten, wenn ich eine SSD verwendet hätte? Probleme mit einem langsamen Betrieb durch Fragmentierung gäbe es definitiv nicht, Probleme mit Diensten müssten auf jeden Fall behoben werden und Softwarefehler seien nicht von der Art des Laufwerks abhängig. In naher Zukunft plane ich einen kompletten Umstieg auf SSD, aber vorerst gilt: „Lang lebe Pfannkuchen, Pfannkuchen für immer!“
Slowride – Dienstprogramm zur Überprüfung der Lesegeschwindigkeit von Blockgeräten für POSIX-kompatible Betriebssysteme mit Root-Zugriff auf /dev/sd*. Sie können die Leseleistung von Blockgeräten mithilfe eines Zeitschwellenwerts testen, um die Leseleistung zu diagnostizieren. Befehl zum Lesen von 100-MB-Blöcken auf dem gesamten Gerät und zur Ausgabe von Blöcken über dem 2-Sekunden-Schwellenwert:
Ich habe schon lange keine neuen Projekte mehr angekündigt) Das nächste Projekt, an dem ich zu arbeiten beginne – 3D-Action-Rollenspiel namens Space Jaguar. Eine Geschichte in einer Science-Fiction-Umgebung über einen harten Kerl namens Jag und sein schwieriges Abenteuer auf der Suche nach seinem vermissten Vater. Es wird 3D-Grafiken auf der Flame Steel Engine (oder möglicherweise einer anderen beliebten Engine) geben, die Entwicklungen aus früheren Projekten (Death Mask, Cube Art Project) verwenden, eine Comedy-Handlung mit vielen Referenzen, Arcade-Kämpfe und Bosse. Ich bin noch nicht bereit, über das Erscheinungsdatum der Vollversion zu sprechen; ich habe vor, das Spiel in Teilen zu veröffentlichen.
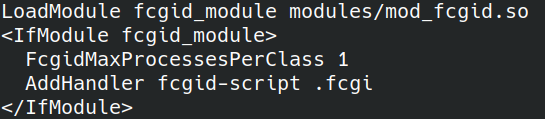
Eine kurze Anmerkung dazu, wie ich den Serverteil für den 3D-Editor Cube Art Project geschrieben habe: Der Server sollte die Arbeit der Benutzer der Webversion speichern und anzeigen und ihnen über die Schaltfläche „Speichern“ kurze URLs geben. Zuerst wollte ich Swift/PHP/Ruby/JS oder eine ähnliche moderne Sprache für das Backend verwenden, aber nachdem ich mir die Eigenschaften meines VPS angesehen hatte, entschied ich mich, den Server in C/C++ zu schreiben. Zuerst müssen Sie libfcgi auf dem Server und das fcgi-Unterstützungsmodul für Ihren Webserver installieren, Beispiel für Ubuntu und Apache:
sudo apt install libfcgi libapache2-mod-fcgid
Als nächstes konfigurieren wir das Modul in der config:
FcgidMaxProcessesPerClass – Maximale Anzahl von Prozessen pro Klasse. Ich habe sie auf 1 Prozess festgelegt, da ich keine große Auslastung erwarte. AddHandler fcgid-script .fcgi – Dateierweiterung, mit der das fcgi-Modul starten soll. Fügen Sie der Konfiguration den Ordner hinzu, aus dem CGI-Anwendungen gestartet werden:
Als nächstes schreiben wir eine Anwendung in C/C++ mit fcgi-Unterstützung, assemblieren sie und kopieren sie in den Ordner /var/www/html/cgi-bin. Beispiele für Code und Build-Skript: https://gitlab.com/demensdeum/cube-art-project-server/-/blob/master/src/cubeArtProjectServer.cpp https://gitlab.com/demensdeum/cube-art-project-server/-/blob/master/src/build.sh
Danach müssen Sie Ihren Webserver neu starten:
systemctl restart apache2
Als nächstes geben Sie die notwendigen Berechtigungen ein, um den cgi-bin-Ordner über chmod auszuführen. Danach sollte Ihr CGI-Programm über einen Browser über den Link funktionieren, Beispiel für den Cube Art Project-Server: http://192.243.103.70/cgi-bin/cubeArtProject/cubeArtProjectServer.fcgi
Wenn etwas nicht funktioniert, sehen Sie sich die Webserverprotokolle an oder stellen Sie eine Verbindung mit einem Debugger zum laufenden Prozess her. Der Debugging-Prozess sollte sich nicht vom Debugging-Prozess einer regulären Clientanwendung unterscheiden.
Cube Art Project – kubischer 3D-Editor. Sie haben die großartige Möglichkeit, sich auf der Bühne zu bewegen, Würfel mit den Tasten WSAD + E zu erstellen und zu löschen und das Mausrad zu drehen, um die Farbe des Würfels zu ändern. Derzeit werden nur 16 Farben unterstützt, für die Zukunft sind jedoch viele Verbesserungen geplant.
In diesem Beitrag beschreibe ich meine Erfahrungen mit der Portierung eines Prototyps eines 3D-Editors Cube Art Projectauf Android. Schauen wir uns zunächst das Ergebnis an: Im Emulator läuft ein Editor mit einem roten 3D-Würfelcursor:
Für eine erfolgreiche Montage mussten Sie Folgendes tun:
Installieren Sie das neueste Android SDK und NDK (je neuer die NDK-Version, desto besser).
Laden Sie den SDL2-Quellcode herunter und verwenden Sie die Vorlage von dort, um die Android-Anwendung zu erstellen.
SDL Image und SDL Mixer zur Baugruppe hinzufügen.
Fügen Sie die Bibliotheken meiner Spiel-Engine und meines Toolkits sowie deren Abhängigkeiten hinzu (GLM, JSON für Modern C++)
Assembly-Dateien für Gradle anpassen.
C++-Code für Kompatibilität mit Android anpassen, betroffene plattformabhängige Komponenten ändern (OpenGL ES, Grafikkontextinitialisierung)
Erstellen und testen Sie das Projekt auf dem Emulator.
Projektvorlage
Laden der Quellen SDL, SDL Image, SDL Mixer: https://www.libsdl.org/download-2.0.php
Der Ordner „docs“ enthält detaillierte Anweisungen zum Arbeiten mit der Android-Projektvorlage. Kopieren Sie das Android-Projektverzeichnis in einen separaten Ordner, erstellen Sie einen Symlink oder kopieren Sie den SDL-Ordner nach Android-Projekt/App/jni. Wir ersetzen das Avd-Flag durch die richtige Kennung und starten den Android-Emulator aus dem Verzeichnis Sdk:
cd ~/Android/Sdk/emulator
./emulator -avd Pixel_2_API_24
Geben Sie die Pfade im Skript an und stellen Sie das Projekt zusammen:
Wir laden das alles nach app/jni hoch, jedes „Modul“ in einen separaten Ordner, zum Beispiel app/jni/FSGL. Als nächstes haben Sie die Möglichkeit, funktionierende Generatoren für die Dateien Application.mk und Android.mk zu finden. Ich habe sie nicht gefunden, aber vielleicht gibt es eine einfache Lösung, die auf CMake basiert. Folgen Sie den Links und machen Sie sich mit dem Assembly-Dateiformat für Android NDK vertraut: https://developer.android.com/ndk/guides/application_mk https://developer.android.com/ndk/guides/android_mk
Nach der Einarbeitung erstellen wir für jedes „Modul“ eine Android.mk-Datei, gefolgt von einer Beispiel-Assembly-Datei der gemeinsam genutzten Bibliothek Cube-Art-Project:
Jeder erfahrene CMake-Benutzer wird diese Konfiguration von den ersten Zeilen an verstehen, die Formate sind sehr ähnlich, Android.mk fehlt GLOB_RECURSIVE, sodass Sie mit der Walk-Funktion rekursiv nach Quelldateien suchen müssen.
Wir ändern Application.mk und Android.mk, um C++ und nicht C-Code zu erstellen:
Versuchen Sie als Nächstes, das Projekt zu erstellen. Wenn Sie vom Compiler Fehlermeldungen über das Fehlen von Headern sehen, überprüfen Sie die Richtigkeit der Pfade in Android.mk. Wenn vom Linker Fehler wie „undefinierte Referenz“ auftreten, überprüfen Sie, ob die Quellcodedateien in den Assemblys korrekt angegeben sind, indem Sie $(info $(FILE_LIST)) in der Datei Android.mk angeben. Vergessen Sie nicht den doppelten Verknüpfungsmechanismus, die Verwendung von Modulen im Schlüssel LOCAL_SHARED_LIBRARIES und die korrekte Verknüpfung über LD, zum Beispiel für FSGL:
LOCAL_LDLIBS := -lEGL -lGLESv2
Anpassung und Einführung
Ich musste einige Dinge ändern, zum Beispiel GLEW aus den Builds für iOS und Android entfernen, einige der OpenGL-Aufrufe umbenennen, das EOS-Postfix hinzufügen (glGenVertexArrays -> glGenVertexArraysOES) und ein Makro für die fehlenden modernen Debugging-Funktionen einfügen , das Sahnehäubchen ist die implizite Einbindung von GLES2-Headern, die auf Makros hinweisen GL_GLEXT_PROTOTYPES 1:
Ich habe bei den ersten Starts auch einen schwarzen Bildschirm mit einem Fehler wie „E/libEGL: validate_display:255 error 3008 (EGL_BAD_DISPLAY)“ beobachtet, die Initialisierung des SDL-Fensters und des OpenGL-Profils geändert und alles hat funktioniert:
Auf dem Emulator wird die Anwendung standardmäßig mit dem SDL-Symbol und dem Namen „Spiel“ installiert.
Ich muss nur die Möglichkeit erkunden, Assembly-Dateien automatisch auf Basis von CMake zu generieren oder Assemblys für alle Plattformen nach Gradle zu migrieren; CMake bleibt jedoch de facto die Wahl für die fortlaufende C++-Entwicklung.
Vielleicht ist es erwähnenswert, die Website zu erwähnen, auf der meine Projekte und Neuentwicklungen fast immer beginnen. Dies ist die Website von LazyFoo Productions, auf der Sie Antworten auf ziemlich schwierige Themen finden: Beispiele für die Verwendung komplexer APIs und lernen, wie man scheinbar Inkompatibles kombiniert Systeme (Android/C++) mit einer detaillierten Erläuterung der Funktionsprinzipien und funktionierenden Codebeispielen.
Um ein neues Projekt zu entwickeln, hat Cube Art Project die Test Driven Development-Methodik übernommen. Bei diesem Ansatz wird zunächst ein Test für eine bestimmte Funktionalität der Anwendung durchgeführt und anschließend die spezifische Funktionalität implementiert. Den großen Vorteil dieses Ansatzes sehe ich darin, dass die finalen Schnittstellen möglichst unbeeinflusst von Implementierungsdetails implementiert werden, bevor mit der Entwicklung der Funktionalität begonnen wird. Bei diesem Ansatz bestimmt der Test die weitere Implementierung und bietet alle Vorteile der Vertragsprogrammierung, wenn es sich bei Schnittstellen um Verträge für eine bestimmte Implementierung handelt. Würfelkunstprojekt – Ein 3D-Editor, in dem der Benutzer Figuren aus Würfeln baut; vor nicht allzu langer Zeit war dieses Genre sehr beliebt. Da es sich um eine grafische Anwendung handelt, habe ich beschlossen, Tests mit Screenshot-Validierung hinzuzufügen. Um Screenshots zu validieren, müssen Sie sie aus dem OpenGL-Kontext abrufen. Dies geschieht mit der glReadPixels-Funktion. Die Beschreibung der Funktionsargumente ist einfach – Startposition, Breite, Höhe, Format (RGB/RGBA/usw.), Zeiger auf Ausgabepuffer; jeder, der mit SDL gearbeitet hat oder Erfahrung mit Datenpuffern in C hat, ersetzt einfach die notwendigen Argumente. Ich halte es jedoch für notwendig, eine interessante Funktion des glReadPixels-Ausgabepuffers zu beschreiben: Pixel werden darin von unten nach oben gespeichert, während in SDL_Surface alle grundlegenden Operationen von oben nach unten erfolgen. Das heißt, nachdem ich einen Referenz-Screenshot aus einer PNG-Datei geladen hatte, konnte ich die beiden Puffer nicht direkt vergleichen, da einer von ihnen auf dem Kopf stand. Um den Ausgabepuffer von OpenGL umzudrehen, müssen Sie ihn füllen, indem Sie die Screenshot-Höhe von der Y-Koordinate subtrahieren. Es ist jedoch zu bedenken, dass die Möglichkeit besteht, dass die Puffergrenzen überschritten werden, wenn Sie beim Füllen nichts subtrahieren zu Speicherbeschädigungen führen. Da ich immer versuche, das OOP-Paradigma der „Programmierung durch Schnittstellen“ anstelle des direkten C-ähnlichen Speicherzugriffs durch Zeiger zu verwenden, hat mich das Objekt beim Versuch, Daten außerhalb des Puffers zu schreiben, dank der Grenzvalidierung in der Methode darüber informiert . Der endgültige Code für die Methode zum Erstellen eines Screenshots im Top-Down-Stil:
auto width = params->width;
auto height = params->height;
auto colorComponentsCount = 3;
GLubyte *bytes = (GLubyte *)malloc(colorComponentsCount * width * height);
glReadPixels(0, 0, width, height, GL_RGB, GL_UNSIGNED_BYTE, bytes);
auto screenshot = make_shared(width, height);
for (auto y = 0; y < height; y++) {
for (auto x = 0; x < width; x++) {
auto byteX = x * colorComponentsCount;
auto byteIndex = byteX + (y * (width * colorComponentsCount));
auto redColorByte = bytes[byteIndex];
auto greenColorByte = bytes[byteIndex + 1];
auto blueColorByte = bytes[byteIndex + 2];
auto color = make_shared(redColorByte, greenColorByte, blueColorByte, 255);
screenshot->setColorAtXY(color, x, height - y - 1);
}
}
free(bytes);
In diesem Beitrag beschreibe ich einen Algorithmus zur Lösung des größten häufigen Teilstringproblems. Nehmen wir an, wir versuchen, verschlüsselte Binärdaten zu entschlüsseln. Versuchen wir zunächst, gemeinsame Muster zu finden, indem wir nach der größten Teilzeichenfolge suchen. Beispiel-Eingabezeichenfolge: adasDATAHEADER??jpjjwerthhkjbcvkDATAHEADER??kkasdf Wir suchen nach einer Zeichenfolge, die sich zweimal wiederholt: DATAHEADER??
Präfixe
Schreiben wir zunächst eine Methode zum Vergleichen der Präfixe zweier Zeichenfolgen und lassen Sie sie die resultierende Zeichenfolge zurückgeben, in der die Zeichen des linken Präfixes den Zeichen des rechten Präfixes entsprechen. Zum Beispiel für die Zeilen:
val lhs = "asdfWUKI"
val rhs = "asdfIKUW"
Ergebniszeichenfolge – asdf Beispiel in Kotlin:
fun longestPrefix(lhs: String, rhs: String): String {
val maximalLength = min(lhs.length-1, rhs.length -1)
for (i in 0..maximalLength) {
val xChar = lhs.take(i)
val yChar = rhs.take(i)
if (xChar != yChar) {
return lhs.substring(0, i-1)
}
}
return lhs.substring(0,maximalLength)
}
Brute Force
Wenn etwas nicht klappt, sollten Sie zu roher Gewalt greifen. Mit der longestPrefix-Methode durchlaufen wir die Zeichenfolge in zwei Schleifen. Die erste Schleife nimmt die Zeichenfolge von i bis zum Ende, die zweite von i + 1 bis zum Ende und gibt sie weiter, um nach dem größten Präfix zu suchen. Die zeitliche Komplexität dieses Algorithmus beträgt ungefähr O(n^2) ~ O(n*^3). Beispiel in Kotlin:
fun searchLongestRepeatedSubstring(searchString: String): String {
var longestRepeatedSubstring = ""
for (x in 0..searchString.length-1) {
val lhs = searchString.substring(x)
for (y in x+1..searchString.length-1) {
val rhs = searchString.substring(y)
val longestPrefix = longestPrefix(lhs, rhs)
if (longestRepeatedSubstring.length < longestPrefix.length) {
longestRepeatedSubstring = longestPrefix
}
}
}
return longestRepeatedSubstring
}
Suffix-Array
Für eine elegantere Lösung benötigen wir ein Werkzeug – eine Datenstruktur namens „Suffix Array“. Diese Datenstruktur ist ein Array von Teilzeichenfolgen, die in einer Schleife gefüllt werden, wobei jede Teilzeichenfolge vom nächsten Zeichen der Zeile bis zum Ende beginnt. Zum Beispiel für die Zeile:
Sortieren wir das Suffix-Array, gehen wir dann alle Elemente in einer Schleife durch, wobei sich das aktuelle Element in der linken Hand (links) und das nächste in der rechten Hand (rechts) befindet, und berechnen wir das längste Präfix mithilfe des longestPrefix Methode. Beispiel in Kotlin:
fun searchLongestRepeatedSubstring(searchString: String): String {
val suffixTree = suffixArray(searchString)
val sortedSuffixTree = suffixTree.sorted()
var longestRepeatedSubstring = ""
for (i in 0..sortedSuffixTree.count() - 2) {
val lhs = sortedSuffixTree[i]
val rhs = sortedSuffixTree[i+1]
val longestPrefix = longestPrefix(lhs, rhs)
if (longestRepeatedSubstring.length < longestPrefix.length) {
longestRepeatedSubstring = longestPrefix
}
}
return longestRepeatedSubstring
}
Die zeitliche Komplexität des Algorithmus beträgt O(N log N), was viel besser ist als eine einfache Lösung.
Einfügesortierung – Jedes Element wird mit den vorherigen Elementen in der Liste verglichen und das Element wird mit dem größeren ausgetauscht, falls vorhanden, andernfalls die innere Vergleichsschleife stoppt. Da die Elemente vom ersten bis zum letzten sortiert werden, wird jedes Element mit einer bereits sortierten Liste verglichen, was *möglicherweise* die Gesamtlaufzeit verkürzt. Die zeitliche Komplexität des Algorithmus beträgt O(n^2), also identisch mit der Blasenvariante.
Sortierung zusammenführen
Sortierung zusammenführen – Die Liste wird in Gruppen eines Elements unterteilt. Anschließend werden die Gruppen paarweise „zusammengeführt“ und gleichzeitig verglichen. In meiner Implementierung werden beim Zusammenführen von Paaren die Elemente auf der linken Seite mit den Elementen auf der rechten Seite verglichen und dann in die resultierende Liste verschoben. Wenn die Elemente auf der linken Seite nicht mehr vorhanden sind, werden alle Elemente auf der rechten Seite zur Ergebnisliste hinzugefügt Liste (ihr zusätzlicher Vergleich ist unnötig, da alle Elemente in den Gruppen Sortieriterationen durchlaufen)< br />Die Arbeit dieses Algorithmus lässt sich sehr einfach parallelisieren; die Phase der Zusammenführung von Paaren kann in Threads durchgeführt werden, wobei auf das Ende der Iterationen im Dispatcher gewartet wird. Ausgabe des Algorithmus für Single-Threaded-Ausführung:
Bubble Sort ist ziemlich langweilig, aber es wird interessanter, wenn Sie versuchen, es in einer funktionalen Sprache für die Telekommunikation zu implementieren – Erlang.
Wir haben eine Liste mit Zahlen, wir müssen sie sortieren. Der Blasensortierungsalgorithmus durchläuft die gesamte Liste und iteriert und vergleicht die Zahlen paarweise. Bei der Prüfung geschieht Folgendes: Eine kleinere Zahl wird zur Ausgabeliste hinzugefügt, oder die Zahlen werden in der aktuellen Liste vertauscht, wenn rechts weniger vorhanden sind, wird die Suche mit der nächsten Zahl in der Iteration fortgesetzt. Dieser Durchlauf wird wiederholt, bis die Liste keine Ersetzungen mehr enthält.
In der Praxis lohnt sich der Einsatz aufgrund der hohen zeitlichen Komplexität des Algorithmus nicht – O(n^2); Ich habe es in Erlang im Imperativstil implementiert, aber wenn Sie interessiert sind, können Sie nach besseren Optionen suchen:
In Ubuntu ist Erlang sehr einfach zu installieren; geben Sie einfach sudo apt install erlang in das Terminal ein. In dieser Sprache muss jede Datei ein Modul sein, mit einer Liste von Funktionen, die extern verwendet werden können – Export. Zu den interessanten Merkmalen der Sprache gehören das Fehlen von Variablen, nur Konstanten, das Fehlen einer Standardsyntax für OOP (was die Verwendung von OOP-Techniken nicht verhindert) und natürlich parallele Berechnungen ohne Sperren basierend auf dem Akteurmodell.
Sie können das Modul entweder über die interaktive ERL-Konsole ausführen, indem Sie einen Befehl nach dem anderen ausführen, oder einfacher über escript bubbleSort.erl; In verschiedenen Fällen sieht die Datei anders aus, zum Beispiel müssen Sie für escript eine Hauptfunktion erstellen, von der aus sie gestartet wird.
Der lexikografische String-Vergleichsalgorithmus funktioniert sehr einfach; die Zeichencodes werden in einer Schleife verglichen und das Ergebnis wird zurückgegeben, wenn die Zeichen nicht gleich sind.
Es sollte berücksichtigt werden, dass Sie Zeichen in einer einzigen statischen Codierung vergleichen müssen, zum Beispiel habe ich in Swift den zeichenweisen Vergleich in UTF-32 verwendet. Die Array-Sortieroption mit memcmp funktioniert genau für Einzelbyte-Zeichen. In anderen Fällen (Codierungen mit variabler Länge) ist die Reihenfolge möglicherweise falsch. Ich schließe die Möglichkeit einer Implementierung auf Basis von Codierungen mit variabler Länge nicht aus, aber höchstwahrscheinlich wird es um eine Größenordnung komplizierter sein.
Die zeitliche Komplexität des Algorithmus beträgt im besten Fall O(1), im Durchschnitt und im schlechtesten Fall O(n)
Dieser Nonsens-Beitrag ist der Entwicklung eines Spiels für den alten ZX Spectrum-Computer in C gewidmet. Werfen wir einen Blick auf den hübschen Kerl:
Die Produktion begann 1982 und wurde bis 1992 produziert. Technische Eigenschaften der Maschine: 8-Bit-Z80-Prozessor, 16-128 KB Speicher und weitere Erweiterungen, wie der AY-3-8910-Soundchip.
Im Rahmen des Wettbewerbs Yandex Retro Games Battle 2019 für diese Maschine habe ich ein Spiel geschrieben namens Interceptor 2020. Da ich keine Zeit hatte, die Assemblersprache für den Z80 zu lernen, beschloss ich, sie in C zu entwickeln. Als Toolchain habe ich ein fertiges Set gewählt – z88dk, das C-Compiler und viele Hilfsbibliotheken enthält, um die Implementierung von Anwendungen für das Spectrum zu beschleunigen. Es unterstützt auch viele andere Z80-Geräte, wie z. B. Taschenrechner von MSX und Texas Instruments.
Als nächstes beschreibe ich meinen oberflächlichen Flug über die Computerarchitektur, die z88dk-Toolchain, und zeige, wie ich es geschafft habe, den OOP-Ansatz zu implementieren und Designmuster zu verwenden.
Installationsfunktionen
Die Installation von z88dk sollte gemäß der Anleitung aus dem Repository erfolgen, für Ubuntu-Benutzer möchte ich jedoch eine Funktion anmerken – Wenn Sie bereits Compiler für Z80 aus Deb-Paketen installiert haben, sollten Sie diese entfernen, da z88dk aufgrund der Inkompatibilität der Toolchain-Compiler-Versionen standardmäßig auf sie zugreift.< /p>
Hallo Welt
Hello World zu schreiben ist sehr einfach:
#include
void main()
{
printf("Hello World");
}
Es ist noch einfacher, eine Tap-Datei zu kompilieren:
Verwenden Sie zum Ausführen einen beliebigen ZX Spectrum-Emulator mit Tap-Datei-Unterstützung, zum Beispiel online: http://jsspeccy.zxdemo.org/
Zeichnen Sie im Vollbildmodus auf das Bild
tl;dr Bilder werden in Kacheln gezeichnet, Kacheln mit einer Größe von 8×8 Pixeln, die Kacheln selbst sind in die Schriftart Spectrum eingebaut, dann wird das Bild als Linie aus den Indizes gedruckt.
Die Sprite- und Kachelausgabebibliothek SP1 gibt Kacheln mithilfe von UDG aus. Das Bild wird in eine Reihe einzelner UDGs (Kacheln) übersetzt und dann mithilfe von Indizes auf dem Bildschirm zusammengesetzt. Beachten Sie, dass UDG zum Anzeigen von Text verwendet wird. Wenn Ihr Bild einen sehr großen Satz von Kacheln enthält (z. B. mehr als 128 Kacheln), müssen Sie über die Grenzen des Satzes hinausgehen und das Standardspektrum löschen Schriftart. Um diese Einschränkung zu umgehen, habe ich eine Basis von 128 – 255 durch Vereinfachung der Bilder, wobei die ursprüngliche Schriftart erhalten bleibt. Über die Vereinfachung der Bilder unten.
Um Vollbildbilder zu zeichnen, müssen Sie sich mit drei Dienstprogrammen ausrüsten: Gimp img2spec png2c-z88dk
Für echte ZX-Männer, echte Retro-Krieger gibt es eine Möglichkeit: Öffnen Sie einen Grafikeditor mit der Spectrum-Palette, kennen Sie die Funktionen der Bildausgabe, bereiten Sie sie manuell vor und laden Sie sie mit png2c-z88dk oder png2scr hoch.< /p>
Der einfachere Weg – Nehmen Sie ein 32-Bit-Bild, ändern Sie die Anzahl der Farben in Gimp auf 3-4, bearbeiten Sie es leicht und importieren Sie es dann in img2spec, um nicht manuell mit Farbbeschränkungen zu arbeiten. Exportieren Sie PNG und konvertieren Sie es mit PNG2C in ein C-Array. z88dk.
Sie sollten bedenken, dass für einen erfolgreichen Export jede Kachel nicht mehr als zwei Farben enthalten darf.
Als Ergebnis erhalten Sie eine h-Datei, die die Anzahl der eindeutigen Kacheln enthält. Wenn es mehr als ~128 sind, vereinfachen Sie das Bild in Gimp (erhöhen Sie die Wiederholbarkeit) und führen Sie den Exportvorgang über ein neues aus .
Nach dem Export laden Sie buchstäblich die „Schriftart“ aus den Kacheln und drucken den „Text“ aus den Kachelindizes auf den Bildschirm. Unten ist ein Beispiel aus der Render-„Klasse“:
// грузим шрифт в память
unsigned char *pt = fullscreenImage->tiles;
for (i = 0; i < fullscreenImage->tilesLength; i++, pt += 8) {
sp1_TileEntry(fullscreenImage->tilesBase + i, pt);
}
// ставим курсор в 0,0
sp1_SetPrintPos(&ps0, 0, 0);
// печатаем строку
sp1_PrintString(&ps0, fullscreenImage->ptiles);
Sprites auf dem Bildschirm zeichnen
Als nächstes beschreibe ich eine Methode zum Zeichnen von Sprites mit 16 x 16 Pixeln auf dem Bildschirm. Ich bin nicht zur Animation und zum Ändern der Farben gekommen, weil… Es ist trivial, dass mir schon zu diesem Zeitpunkt, wie ich annehme, der Speicher ausgegangen ist. Daher enthält das Spiel nur transparente monochrome Sprites.
Wir zeichnen ein monochromes PNG-Bild 16×16 in Gimp, dann übersetzen wir es mit png2sp1sprite in eine ASM-Assembly-Datei, im C-Code deklarieren wir Arrays aus der Assembly-Datei und fügen die Datei in der Assembly-Phase hinzu.< /p>
Nach der Deklaration der Sprite-Ressource muss diese an der gewünschten Position zum Bildschirm hinzugefügt werden. Nachfolgend finden Sie ein Beispiel für den Code für die „Klasse“ des Spielobjekts:
Anhand der Namen der Funktionen können Sie die Bedeutung von – Weisen Sie dem Sprite Speicher zu, fügen Sie zwei 8×8 Spalten hinzu und fügen Sie eine Farbe für das Sprite hinzu.
Die Position des Sprites wird in jedem Frame angezeigt:
In C gibt es keine Syntax für OOP. Was sollten Sie tun, wenn Sie es trotzdem wirklich wollen? Sie müssen Ihren Geist verbinden und sich darüber im Klaren sein, dass es so etwas wie OOP-Ausrüstung nicht gibt; letztendlich kommt es auf eine der Maschinenarchitekturen an, in denen es einfach kein Konzept eines Objekts und andere damit verbundene Abstraktionen gibt.< /p>
Diese Tatsache hat mich sehr lange daran gehindert zu verstehen, warum OOP überhaupt benötigt wird, warum es notwendig ist, es zu verwenden, wenn am Ende alles auf Maschinencode hinausläuft.
Nachdem ich jedoch in der Produktentwicklung gearbeitet hatte, entdeckte ich die Vorzüge dieses Programmierparadigmas, vor allem natürlich die Entwicklungsflexibilität, Code-Schutzmechanismen mit dem richtigen Ansatz, die Reduzierung der Entropie und die Vereinfachung der Teamarbeit. Alle oben genannten Vorteile basieren auf drei Säulen: Polymorphismus, Kapselung, Vererbung.
Bemerkenswert ist auch die Vereinfachung der Lösung von Problemen im Zusammenhang mit der Anwendungsarchitektur, da 80 % der Architekturprobleme im letzten Jahrhundert von Informatikern gelöst und in der Literatur zu Entwurfsmustern beschrieben wurden. Als Nächstes beschreibe ich Möglichkeiten, C eine OOP-ähnliche Syntax hinzuzufügen.
Es ist bequemer, C-Strukturen als Grundlage für die Speicherung von Daten einer Klasseninstanz zu verwenden. Natürlich können Sie einen Bytepuffer verwenden und Ihre eigene Struktur für Klassen und Methoden erstellen, aber warum das Rad neu erfinden? Schließlich erfinden wir die Syntax bereits neu.
Speichern Sie unsere Klasse als „GameObject.h“, fügen Sie „GameObject.h“ an der richtigen Stelle ein und verwenden Sie sie.
Klassenmethoden
Unter Berücksichtigung der Erfahrung der Entwickler der Objective-C-Sprache besteht die Signatur einer Klassenmethode aus Funktionen in einem globalen Bereich. Das erste Argument ist immer die Datenstruktur, gefolgt von den Methodenargumenten. Unten finden Sie ein Beispiel für eine „Methode“ der „Klasse“ GameObject:
Konstruktoren und Destruktoren werden auf die gleiche Weise implementiert. Es ist möglich, einen Konstruktor als Allokator und Feldinitialisierer zu implementieren, aber ich bevorzuge es, die Objektzuweisung und -initialisierung separat zu steuern.
Mit dem Gedächtnis arbeiten
Manuelle Speicherverwaltung des Formulars mit malloc und frei in neue und gelöschte Makros eingebunden, passend zu C++:
Für Objekte, die von mehreren Klassen gleichzeitig verwendet werden, wird eine halbmanuelle Speicherverwaltung basierend auf Referenzzählung implementiert, nach dem Vorbild und der Ähnlichkeit des alten Objective-C Runtime ARC-Mechanismus:
Daher muss jede Klasse die Verwendung eines gemeinsam genutzten Objekts mithilfe von „Retain“ deklarieren und das Eigentum durch „Release“ freigeben. Die moderne Version von ARC verwendet automatische Aufbewahrungs-/Freigabeaufrufe.
Ton!
Der Spectrum verfügt über einen Hochtöner, der 1-Bit-Musik wiedergeben kann; damalige Komponisten konnten bis zu 4 Tonkanäle gleichzeitig wiedergeben.
Spectrum 128k enthält einen separaten Soundchip AY-3-8910, der Tracker-Musik abspielen kann.
Für die Nutzung des Hochtöners im z88dk wird eine Bibliothek angeboten
Was noch gelernt werden muss
Ich war daran interessiert, das Spectrum kennenzulernen, das Spiel mit dem z88dk zu implementieren und viele interessante Dinge zu lernen. Ich muss noch viel lernen, zum Beispiel den Z80-Assembler, da er mir ermöglicht, die volle Leistung des Spectrum zu nutzen, mit Speicherbänken zu arbeiten und mit dem Soundchip AY-3-8910 zu arbeiten. Ich hoffe, nächstes Jahr am Wettbewerb teilnehmen zu können!
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.

.gif)