Dans cette note, je décrirai mon expérience et celle de mes collègues lorsque j’ai travaillé avec le modèle Singleton (Singleton dans la littérature étrangère), tout en travaillant sur divers projets (réussis et moins réussis). Je décrirai pourquoi je pense personnellement que ce modèle ne peut être utilisé nulle part, et je décrirai également quels facteurs psychologiques dans l’équipe influencent l’intégration de cet anti-modèle. Dédié à tous les développeurs déchus et paralysés qui essayaient de comprendre pourquoi tout a commencé lorsqu’un des membres de l’équipe a amené un petit chiot mignon, facile à manipuler, ne nécessitant pas de soins ni de connaissances particulières pour en prendre soin, et s’est terminé avec la bête élevée. prendre votre projet en otage, nécessite de plus en plus d’heures de travail et ronge les nerfs de l’utilisateur, votre argent et crée des chiffres absolument monstrueux pour évaluer la mise en œuvre de choses apparemment simples des choses.

Wolf in sheep’s clothing by SarahRichterArt
L’histoire se déroule dans un univers alternatif, toutes les coïncidences sont aléatoires…
Carotter un chat à la maison avec Cat@Home
Toute personne, parfois dans la vie, a un désir irrésistible de caresser un chat. Les analystes du monde entier prédisent que la première startup qui a créé une application pour la livraison et la location de chats deviendra extrêmement populaire et sera rachetée dans un avenir proche par Moogle pour des milliards de dollars. Bientôt, cela arrive – un gars de Tioumen crée l’application Cat@Home et devient bientôt un milliardaire, la société Moogle obtient une nouvelle source de profit et des millions de personnes stressées ont l’opportunité de commandez un chat chez eux pour un repassage supplémentaire et calmez-vous.
Attaque des clones
Alexey Goloborodko, un dentiste extrêmement riche de Mourmansk, impressionné par un article de Forbes sur Cat@Home, décide qu’il veut aussi devenir astronomiquement riche. Pour atteindre cet objectif, grâce à ses amis, il trouve une entreprise à Goldfield – un fournisseur de services. Wakeboard DevPops, qui fournit des services de développement de logiciels, leur commande le développement d’un clone Cat@Home.
Équipe gagnante
Le projet s’appelle Fur&Pure, confié à une talentueuse équipe de développement de 20 personnes ; Concentrons-nous ensuite sur une équipe de développement mobile de 5 personnes. Chaque membre de l’équipe obtient sa part du travail, armé d’agile et de Scrum, l’équipe termine le développement dans les délais (en six mois), sans bugs, publie l’application dans l’iStore, où elle est notée 5 par 100 000 utilisateurs, il y en a beaucoup des commentaires sur la qualité de l’application et l’excellence du service (univers alternatif après tout). Les chats sont repassés, l’application est sortie, tout semble bien se passer. Cependant, Moogle n’est pas pressé d’acheter une startup pour des milliards de dollars, car non seulement des chats mais aussi des chiens sont déjà apparus dans Cat@Home.
Le chien aboie, la caravane avance
Le propriétaire de l’application décide qu’il est temps d’ajouter des chiens à l’application, demande une évaluation à l’entreprise et dispose d’environ au moins six mois pour ajouter des chiens à l’application. En fait, l’application sera réécrite à partir de zéro. Pendant ce temps, Moogle ajoutera des serpents, des araignées et des cobayes à l’application, et Fur&Pur ne recevra que des chiens.
Pourquoi est-ce arrivé ? Le manque d’architecture d’application flexible est à l’origine de tout ; l’un des facteurs les plus courants est l’anti-modèle Singleton.
Qu’est-ce qui ne va pas ?
Pour commander un chat à la maison, le consommateur doit créer une demande et l’envoyer au bureau, où le bureau la traitera et enverra un coursier avec le chat, le coursier recevra déjà le paiement du service.
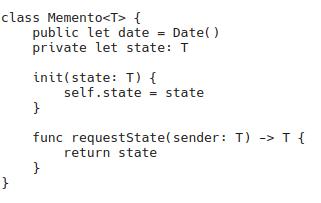
L’un des programmeurs décide de créer une classe « Cat Application » ; avec les champs nécessaires, introduit cette classe dans l’espace d’application global via un singleton. Pourquoi fait-il ça ? Pour gagner du temps (une économie d’un centime d’une demi-heure), car il est plus facile de rendre une application publique que de réfléchir à l’architecture de l’application et d’utiliser l’injection de dépendances. Ensuite, d’autres développeurs récupèrent cet objet global et y lient leurs classes. Par exemple, tous les écrans eux-mêmes accèdent à l’objet global “Cat Request” et afficher les données sur l’application. En conséquence, une telle application monolithique est testée et publiée.
Tout semble aller bien, mais tout à coup, un client apparaît avec l’obligation d’ajouter des demandes de chiens à l’application. L’équipe commence frénétiquement à évaluer combien de composants du système seront affectés par ce changement. A l’issue de l’analyse, il s’avère qu’il faut refaire de 60 à 90% du code afin d’apprendre à l’application à accepter non seulement “Request For Cat” mais aussi “Demande pour un Chien”, il est déjà inutile d’évaluer l’ajout d’autres animaux à ce stade, pour en gérer au moins deux.
Comment empêcher le singleton
Tout d’abord, au stade de la collecte des exigences, indiquez explicitement la nécessité de créer une architecture flexible et extensible. Deuxièmement, il convient de procéder en parallèle à un examen indépendant du code du produit, avec une recherche obligatoire des points faibles. Si vous êtes développeur et que vous aimez les singletons, alors je vous suggère de reprendre vos esprits avant qu’il ne soit trop tard, sinon les nuits blanches et les nerfs à vif sont garantis. Si vous travaillez sur un projet existant comportant de nombreux singletons, essayez de vous en débarrasser le plus rapidement possible, ainsi que du projet.
Vous devez passer de l’anti-modèle d’objets/variables globaux singletons à l’injection de dépendances – le modèle de conception le plus simple dans lequel toutes les données nécessaires sont fournies à une instance d’une classe au stade de l’initialisation, sans qu’il soit nécessaire de les lier à l’espace global.
Sources
https://stackoverflow. com/questions/137975/what-is-so-bad-about-singletons
http://misko.hevery.com/2008/08/17/singletons-are-pathological-liars/
https://blog.ndepend.com/singleton-pattern-costs/