Dans cet article, je décrirai l’utilisation du classificateur de texte fasttext.
Fasttext – bibliothèque d’apprentissage automatique pour la classification de texte. Essayons de lui apprendre à identifier un groupe de métal par le titre de la chanson. Pour ce faire, nous utilisons l’apprentissage supervisé à l’aide d’un ensemble de données.
Créons un ensemble de données de chansons avec des noms de groupe :
__label__metallica fuel
__label__metallica escape
__label__black_sabbath gypsy
__label__black_sabbath snowblind
__label__black_sabbath am i going insane
__label__anthrax anthrax
__label__anthrax i'm alive
__label__anthrax antisocial
[и т.д.]Формат обучающей выборки:
Обучим fasttext и сохраним модель:
model.save_model("model.bin")
Chargez le modèle entraîné et demandez à identifier le groupe par le nom de la chanson :
predictResult = model.predict("Bleed")
print(predictResult)
В результате мы получим список классов на которые похож данный пример, с указанием уровня похожести цифрой, в нашем случае похожесть названия песни Bleed на одну из групп датасета.
Для того чтобы модель fasttext умела работать с датасетом выходящим за границы обучающей выборки, используют режим autotune с использованием файла валидации (файл тест). Во время автотюна fasttext подбирает оптимальные гиперпараметры модели, проводя валидацию результата на выборке из тест файла. Время автотюна ограничивается пользователем в самостоятельно, с помощью передачи аргумента autotuneDuration.
Пример создания модели с использованием файла тест:
Источники
https://fasttext.cc
https://gosha20777.github.io/tutorial/2018/04/12/fasttext-for-windows
Исходный код
https://gitlab.com/demensdeum/MachineLearning/-/tree/master/6bandClassifier
DeMrensplay # 8 DOOM ÉTERNAL: DIEUX ANCIENS
x86_64 Assembleur + C = Un Amour
Dans cette note, je décrirai le processus d’appel de fonctions C depuis l’assembleur.
Essayons d’appeler printf(“Hello World!\n”); et quitter(0);
message: db "Hello, world!", 10, 0
section .text
extern printf
extern exit
global main
main:
xor rax, rax
mov rdi, message
call printf
xor rdi, rdi
call exit
Tout est beaucoup plus simple qu’il n’y paraît, dans la section .rodata nous décrirons les données statiques, dans ce cas la ligne “Hello, world!”, 10 est un caractère de nouvelle ligne, et nous n’oublions pas non plus de l’annuler.
Dans la section code nous déclarerons les fonctions externes printf, exit des bibliothèques stdio, stdlib, et nous déclarerons également la fonction d’entrée main :
extern printf
extern exit
global main
Nous passons 0 au registre de retour depuis la fonction rax, vous pouvez utiliser mov rax, 0; mais pour accélérer, ils utilisent xor rax, rax ; Ensuite, nous passons un pointeur vers la chaîne au premier argument :
Далее вызываем внешнюю функцию Си printf:
xor rax, rax
mov rdi, message
call printf
xor rdi, rdi
call exit
Par analogie, on passe 0 au premier argument et on appelle exit :
call exit
Comme disent les Américains :
Qui n'écoute personne
Ce pilaf est en train de manger @ Alexandre Pelevin
Sources
https://www.devdungeon. com/content/how-mix-c-and-assembly
https://nekosecurity.com/x86-64-assembly/part-3-nasm-anatomy-syscall-passing-argument
https://www.cs.uaf.edu/2017/fall/cs301/reference/x86_64.html
Code source
https://gitlab.com/demensdeum/assembly-playground
Assembleur Hello World x86_64
Dans cet article, je décrirai le processus de configuration de l’EDI, en écrivant le premier Hello World en assembleur x86_64 pour le système d’exploitation Ubuntu Linux.
Commençons par installer l’IDE SASM, l’assembleur nasm :
Далее запустим SASM и напишем Hello World:
section .text
main:
mov rbp, rsp ; for correct debugging
mov rax, 1 ; write(
mov rdi, 1 ; STDOUT_FILENO,
mov rsi, msg ; "Hello, world!\n",
mov rdx, msglen ; sizeof("Hello, world!\n")
syscall ; );
mov rax, 60 ; exit(
mov rdi, 0 ; EXIT_SUCCESS
syscall ; );
section .rodata
msg: db "Hello, world!"
msglen: equ $-msg
Code Hello World extrait du blog James Fisher, adapté pour l'assemblage et le débogage dans SASM. La documentation SASM indique que le point d'entrée doit être une fonction nommée main, sinon le débogage et la compilation du code seront incorrects.
Qu'avons-nous fait dans ce code ? J'ai passé un appel système – accès au noyau du système d'exploitation Linux avec des arguments corrects dans les registres, un pointeur vers une chaîne dans la section données.
Sous une loupe
Regardons le code plus en détail :
global – директива ассемблера позволяющая задавать глобальные символы со строковыми именами. Хорошая аналогия – интерфейсы заголовочных файлов языков C/C++. В данном случае мы задаем символ main для функции входа.
section – директива ассемблера позволяющая задавать секции (сегменты) кода. Директивы section или segment равнозначны. В секции .text помещается код программы.
Обьявляем начало функции main. В ассемблере функции называются подпрограммами (subroutine)
Первая машинная команда mov – помещает значение из аргумента 1 в аргумент 2. В данном случае мы переносим значение регистра rbp в rsp. Из комментария можно понять что эту строку добавил SASM для упрощения отладки. Видимо это личные дела между SASM и дебаггером gdb.
Далее посмотрим на код до сегмента данных .rodata, два вызова syscall, первый выводит строку Hello World, второй обеспечивает выход из приложения с корректным кодом 0.
Представим себе что регистры это переменные с именами rax, rdi, rsi, rdx, r10, r8, r9. По аналогии с высокоуровневыми языками, перевернем вертикальное представление ассемблера в горизонтальное, тогда вызов syscall будет выглядеть так:
Тогда вызов печати текста:
Вызов exit с корректным кодом 0:
Рассмотрим аргументы подробнее, в заголовочном файле asm/unistd_64.h находим номер функции __NR_write – 1, далее в документации смотрим аргументы для write:
ssize_t write(int fd, const void *buf, size_t count);
Первый аргумент – файловый дескриптор, второй – буфер с данными, третий – счетчик байт для записи в дескриптор. Ищем номер файлового дескриптора для стандартного вывода, в мануале по stdout находим код 1. Далее дело за малым, передать указатель на буфер строки Hello World из секции данных .rodata – msg, счетчик байт – msglen, передать в регистры rax, rdi, rsi, rdx корректные аргументы и вызвать syscall.
Обозначение константных строк и длины описывается в мануале nasm:
msglen equ $-message
Достаточно просто да?
Источники
https://github.com/Dman95/SASM
https://www.nasm.us/xdoc/2.15.05/html/nasmdoc0.html
http://acm.mipt.ru/twiki/bin/view/Asm/HelloNasm
https://jameshfisher.com/2018/03/10/linux-assembly-hello-world/
http://www.ece.uah.edu/~milenka/cpe323-10S/labs/lab3.pdf
https://c9x.me/x86/html/file_module_x86_id_176.html
https://www.recurse.com/blog/7-understanding-c-by-learning-assembly
https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%BE%D0%BB%D0%BE%D0%B3_%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D0%B4%D1%83%D1%80%D1%8B
https://www.tutorialspoint.com/assembly_programming/assembly_basic_syntax.html
https://nekosecurity.com/x86-64-assembly/part-3-nasm-anatomy-syscall-passing-argument
https://man7.org/linux/man-pages/man2/syscall.2.html
https://en.wikipedia.org/wiki/Write_(system_call)
Исходный код
https://gitlab.com/demensdeum/assembly-playground
DemensPlay #7 Chrome flamboyant
Caractéristiques du RPG d’action Space Jaguar
Le premier article sur le jeu en développement, Space Jaguar Action RPG. Dans cet article, je décrirai la fonctionnalité de gameplay de la Jaguar – Caractéristiques.
De nombreux RPG utilisent un système de statistiques de personnage statique, comme les statistiques de DnD (Force, Constitution, Dextérité, Intelligence, Sagesse, Charisme) ou Fallout – S.P.E.C.I.A.L (Force, Perception, Endurance, Charisme, Intelligence, Dextérité, Chance). ).
Dans Space Jaguar, je prévois d’implémenter un système dynamique de caractéristiques, par exemple, le personnage principal du jeu Jag au début n’a que trois caractéristiques – ; Maîtrise d’une lame (demi-sabre), opérations louches (faire des affaires dans le monde criminel), capacités de voyous (crochetage de serrures, vol). Au cours du jeu, les personnages se verront attribuer et privés de caractéristiques dynamiques dans le cadre du module de jeu, tous les contrôles seront effectués en fonction du niveau de certaines caractéristiques nécessaires à une situation de jeu donnée. Par exemple, Jag ne pourra pas gagner une partie d’échecs s’il n’a pas la caractéristique de jouer aux échecs, ou s’il n’a pas un niveau suffisant pour passer le contrôle.
Pour simplifier la logique des contrôles, chaque caractéristique reçoit un code à 6 chiffres en lettres anglaises, un nom et une description. Par exemple, pour posséder une lame :
bladeFightingAbility.name = "BLADFG";
bladeFightingAbility.description = "Blade fighting ability";
bladeFightingAbility.points = 3;
Перед стартом игрового модуля можно будет просмотреть список публичных проверок необходимых для прохождения, также создатель может скрыть часть проверок для создания интересных игровых ситуаций.
Ноу-хау? Будет ли интересно? Лично я нахожу такую систему интересной, позволяющей одновременно обеспечить свободу творчества создателям игровых модулей, и возможность переноса персонажей из разных, но похожих по характеристикам, модулей для игроков.
Table de hachage
La table de hachage vous permet d’implémenter une structure de données de tableau associatif (dictionnaire) avec des performances moyennes O(1) pour les opérations d’insertion, de suppression et de recherche.
Vous trouverez ci-dessous un exemple de l’implémentation la plus simple d’une carte de hachage dans nodeJS :
Comment ça marche ? Surveillez vos mains :
- À l’intérieur de la carte de hachage se trouve un tableau
- À l’intérieur de l’élément du tableau se trouve un pointeur vers le premier nœud de la liste chaînée
- La mémoire est allouée à un tableau de pointeurs (par exemple, 65 535 éléments)
- Ils implémentent une fonction de hachage, la clé du dictionnaire est l’entrée, et en sortie elle peut tout faire, mais à la fin elle renvoie l’index de l’élément du tableau
Comment fonctionne l’enregistrement :
- A l’entrée, il y a une paire de clés – valeur
- La fonction de hachage renvoie l’index par clé
- Obtenir un nœud de liste chaînée à partir d’un tableau par index
- Vérifiez si cela correspond à la clé
- Si cela correspond, remplacez la valeur
- S’il ne correspond pas, passez au nœud suivant jusqu’à ce que nous trouvions ou trouvions un nœud avec la clé requise.
- Si le nœud n’est toujours pas trouvé, créez-le à la fin de la liste chaînée
Fonctionnement de la recherche par clé :
- A l’entrée, il y a une paire de clés – valeur
- La fonction de hachage renvoie l’index par clé
- Obtenir un nœud de liste chaînée à partir d’un tableau par index
- Vérifiez si cela correspond à la clé
- Si cela correspond, renvoyez la valeur
- S’il ne correspond pas, passez au nœud suivant jusqu’à ce que nous trouvions ou trouvions un nœud avec la clé requise.
Pourquoi avons-nous besoin d’une liste chaînée dans un tableau ? En raison de collisions possibles lors du calcul de la fonction de hachage. Dans ce cas, plusieurs paires clé-valeur différentes seront situées au même index dans le tableau, auquel cas la liste chaînée est parcourue pour trouver la clé requise.
Sources
https://ru.wikipedia.org/wiki/Hash table
https://www.youtube.com/watch?v=wg8hZxMRwcw
Code source
https://gitlab.com/demensdeum/datastructures
Travailler avec des ressources dans Android C++
Pour travailler avec des ressources sous Android via ndk – En C++, il existe plusieurs options :
- Utiliser l’accès aux ressources à partir d’un fichier apk à l’aide d’AssetManager
- Téléchargez les ressources depuis Internet et décompressez-les dans le répertoire de l’application, utilisez-les à l’aide des méthodes C++ standard
- Méthode combinée – accédez à l’archive avec les ressources dans l’apk via AssetManager, décompressez-les dans le répertoire de l’application, puis utilisez-les à l’aide des méthodes C++ standard
Ensuite, je décrirai la méthode d’accès combinée utilisée dans le moteur de jeu Flame Steel Engine.
Lorsque vous utilisez SDL, vous pouvez simplifier l’accès aux ressources à partir d’un apk ; la bibliothèque encapsule les appels à AssetManager, offrant des interfaces similaires à stdio (fopen, fread, fclose, etc.)
SDL_RWops *io = SDL_RWFromFile("files.fschest", "r");
Après avoir téléchargé l’archive de l’apk vers le tampon, vous devez remplacer le répertoire de travail actuel par le répertoire de l’application, il est disponible pour l’application sans obtenir d’autorisations supplémentaires. Pour ce faire, nous utiliserons un wrapper SDL :
chdir(SDL_AndroidGetInternalStoragePath());
Ensuite, écrivez l’archive du tampon vers le répertoire de travail actuel en utilisant fopen, fwrite, fclose. Une fois l’archive dans un répertoire accessible en C++, décompressez-la. Les archives Zip peuvent être décompressées à l’aide d’une combinaison de deux bibliothèques : minizip et zlib, le premier peut travailler avec la structure des archives, tandis que le second décompresse les données.
Pour gagner plus de contrôle et faciliter le portage, j’ai implémenté mon propre format d’archive sans compression appelé FSChest (Flame Steel Chest). Ce format prend en charge l’archivage d’un répertoire avec des fichiers et le déballage ; La hiérarchie des dossiers n’est pas prise en charge ; vous pouvez uniquement travailler avec des fichiers.
On connecte l’en-tête de la bibliothèque FSChest, on décompresse l’archive :
#include "fschest.h"
FSCHEST_extractChestToDirectory(archivePath, SDL_AndroidGetInternalStoragePath());
Après le déballage, les interfaces C/C++ auront accès aux fichiers de l’archive. Ainsi, je n’ai pas eu à réécrire tout le travail avec les fichiers dans le moteur, mais j’ai seulement ajouté le déballage des fichiers au stade du lancement.
Sources
https://developer.android.com/ndk/ référence/groupe/actif
Code source
https://gitlab.com/demensdeum/space- jaguar-action-rpg
https://gitlab.com/demensdeum/fschest
Machine à empiler et RPN
Supposons que nous devions implémenter un simple interpréteur de bytecode, quelle approche pour implémenter cette tâche devrions-nous choisir ?
Structure des données La pile offre la possibilité d’implémenter une machine de bytecode simple. Les fonctionnalités et les implémentations des machines à pile sont décrites dans de nombreux articles sur l’Internet occidental et national ; je mentionnerai simplement que la machine virtuelle Java est un exemple de machine à pile.
Le principe de fonctionnement de la machine est simple, un programme contenant des données et des codes d’opération (opcodes) est fourni à l’entrée, et les opérations nécessaires sont mises en œuvre à l’aide de manipulations avec la pile. Regardons un exemple de programme de bytecode de ma machine à pile :
пMVkcatS olleHП
En sortie, nous recevrons la chaîne « Hello StackVM ». La machine à pile lit le programme de gauche à droite, chargeant les données caractère par caractère sur la pile lorsqu’un opcode apparaît dans le symbole – implémente la commande en utilisant la pile.
Exemple d’implémentation d’une stack machine dans nodejs :
Notation polonaise inversée (RPN)
Les machines Stack sont également faciles à utiliser pour mettre en œuvre des calculatrices, pour cela elles utilisent la notation polonaise inversée (notation suffixe).
Exemple de notation infixe régulière :
2*2+3*4
Convertit en RPN :
22*34*+
Pour compter l’enregistrement postfix, nous utilisons une machine à pile :
2– en haut de la pile (pile : 2)
2– en haut de la pile (pile : 2,2)
*– obtenir le haut de la pile deux fois, multiplier le résultat, l’envoyer en haut de la pile (pile : 4)
3– en haut de la pile (pile : 4, 3)
4– en haut de la pile (pile : 4, 3, 4)
*– obtenir le haut de la pile deux fois, multiplier le résultat, l’envoyer en haut de la pile (pile : 4, 12)
+– récupérez deux fois le haut de la pile, ajoutez le résultat, envoyez-le en haut de la pile (pile : 16)
Comme vous pouvez le voir – le résultat des opérations 16 reste sur la pile, il peut être imprimé en implémentant des opcodes d’impression de pile, par exemple :
p22*34*+P
P – Opcode de démarrage de l’impression de la pile, p – opcode pour terminer l’impression de la pile et envoyer la ligne finale pour le rendu.
Pour convertir les opérations arithmétiques d’infixe en suffixe, l’algorithme d’Edsger Dijkstra appelé « Sorting Yard » est utilisé. Un exemple d’implémentation peut être vu ci-dessus, ou dans le référentiel du projet de pile de machines nodejs ci-dessous.
Sources
https:/ /tech.badoo.com/ru/article/579/interpretatory-bajt-kodov-svoimi-rukami/
https://ru.wikipedia.org/wiki/Обратная_польская_запись
Code source
https://gitlab.com/demensdeum/stackvm/< /p>
Animation squelettique (partie 2 & # 8211; hiérarchie de nœuds, interpolation)
Je continue à décrire l’algorithme d’animation squelettique tel qu’il est implémenté dans Flame Steel Engine.
Étant donné que l’algorithme est le plus complexe de tous ceux que j’ai implémentés, des erreurs peuvent apparaître dans les notes sur le processus de développement. Dans l’article précédent sur cet algorithme, j’ai commis une erreur : le réseau d’os est transféré au shader pour chaque maillage séparément, et non pour l’ensemble du modèle.
Hiérarchie des nœuds
Pour que l’algorithme fonctionne correctement, il est nécessaire que le modèle contienne une connexion entre les os entre eux (graphique). Imaginons une situation dans laquelle deux animations sont jouées simultanément – sautez et levez la main droite. L’animation de saut doit soulever le modèle le long de l’axe Y, tandis que l’animation de lever de bras doit en tenir compte et monter avec le modèle au fur et à mesure qu’il saute, sinon le bras restera en place tout seul.
Nous décrirons la connexion des nœuds pour ce cas – le corps contient la main. Lors de l’élaboration de l’algorithme, le graphique osseux sera lu, toutes les animations seront prises en compte avec les connexions correctes. Dans la mémoire du modèle, le graphique est stocké séparément de toutes les animations, uniquement pour refléter la connectivité des os du modèle.
Interpolation sur CPU
Dans le dernier article, j’ai décrit le principe du rendu de l’animation squelettique : “Les matrices de transformation sont transférées du CPU au shader à chaque image de rendu.”
Chaque image de rendu est traitée sur le processeur ; pour chaque os de maillage, le moteur reçoit la matrice de transformation finale en utilisant l’interpolation de position, la rotation et le zoom. Lors de l’interpolation de la matrice osseuse finale, un passage est effectué à travers l’arborescence des nœuds pour toutes les animations de nœuds actives, la matrice finale est multipliée par celles parent, puis envoyée pour rendu au vertex shader.
Les vecteurs sont utilisés pour l’interpolation de position et le grossissement ; les quaternions sont utilisés pour la rotation, car ils sont très faciles à interpoler (SLERP), contrairement aux angles d’Euler, et ils sont également très faciles à représenter sous forme de matrice de transformation.
Comment simplifier la mise en œuvre
Pour faciliter le débogage du vertex shader, j’ai ajouté une simulation du vertex shader sur le CPU à l’aide de la macro FSGLOGLNEWAGERENDERER_CPU_BASED_VERTEX_MODS_ENABLED. Le fabricant de la carte vidéo NVIDIA dispose d’un utilitaire de débogage du code de shader Nsight, peut-être qu’il peut aussi simplifier le développement d’algorithmes complexes de shader de sommets/pixels, mais je n’ai jamais pu tester sa fonctionnalité sur le CPU, c’était suffisant.
Dans le prochain article, je prévois de décrire le mélange de plusieurs animations et de combler les lacunes restantes.
Sources
https://www.youtube.com/watch?v= f3Cr8Yx3GGA
DemensPlay #6 Rues de Rage 4
DemensPlay Doom Eternal
Ajout de la prise en charge des scripts JavaScript en C++
Dans cet article, je décrirai une manière d’ajouter la prise en charge des scripts JavaScript à une application C++ à l’aide de la bibliothèque Tiny-JS.
Tiny-JS est une bibliothèque à intégrer en C++, permettant l’exécution de code JavaScript, avec prise en charge des liaisons (possibilité d’appeler du code C++ à partir de scripts)
Au début, je voulais utiliser les bibliothèques populaires ChaiScript, Duktape ou connect Lua, mais en raison des dépendances et des éventuelles difficultés de portabilité vers différentes plates-formes, il a été décidé de trouver une bibliothèque MIT JS simple, minimale mais puissante ; JS répond à ces critères. Le seul inconvénient de cette bibliothèque est le manque de support/développement par l’auteur, mais son code est assez simple, ce qui permet de prendre en charge le support si nécessaire.
Téléchargez Tiny-JS depuis le référentiel :
https://github.com/gfwilliams/tiny-js
Ensuite, ajoutez les en-têtes Tiny-JS au code responsable des scripts :
#include "tiny-js/TinyJS.h"
#include "tiny-js/TinyJS_Functions.h"
Ajoutez les fichiers TinyJS .cpp à l’étape de construction, vous pourrez alors commencer à écrire des scripts de chargement et d’exécution.
Un exemple d’utilisation de la bibliothèque est disponible dans le dépôt :
https://github.com/gfwilliams/tiny-js/blob/master/Script.cpp
https://github.com/gfwilliams/tiny-js/blob/wiki/CodeExamples.md
Un exemple d’implémentation de la classe handler peut être trouvé dans le projet SpaceJaguar :
https://gitlab.com/demensdeum/space-jaguar-action-rpg/-/blob/master/project/src/Controllers/SpaceJaguarScriptController/SpaceJaguarScriptController.h
https://gitlab.com/demensdeum/space-jaguar-action-rpg/-/blob/master/project/src/Controllers/SpaceJaguarScriptController/SpaceJaguarScriptController.cpp
Exemple de script de jeu ajouté à l’application :
https://gitlab.com/demensdeum/space-jaguar-action-rpg/-/blob/master/project/resources/com.demensdeum.spacejaguaractionrpg.scripts.sceneController.js
Sources
https://github.com/gfwilliams/tiny-js
https://github.com/dbohdan/embedded-scripting-languages
https://github.com/AlexKotik/embeddable-scripting-languages
Création d’une application C++ SDL pour iOS sous Linux
Dans cet article, je décrirai la procédure pour créer une application C++ SDL pour iOS sous Linux, signer une archive ipa sans abonnement Apple Developer payant et l’installer sur un appareil propre (iPad) utilisant macOS sans Jailbreak.< /p>
Tout d’abord, installons la chaîne d’outils de build pour Linux :
https://github.com/tpoechtrager/cctools-port
La chaîne d’outils doit être téléchargée depuis le référentiel, puis suivez les instructions sur le site Web Godot Engine pour terminer l’installation :
https://docs.godotengine.org/ru/latest/development/compiling/cross-compiling_for_ios_on_linux.html
Pour le moment, vous devez télécharger Xcode dmg et copier le SDK à partir de là pour créer le port cctools. Cette étape est plus facile à réaliser sur macOS ; copiez simplement les fichiers SDK nécessaires à partir du Xcode installé. Après un assemblage réussi, le terminal contiendra le chemin d’accès à la chaîne d’outils du compilateur croisé.
Vous pouvez ensuite commencer à créer l’application SDL pour iOS. Ouvrons cmake et ajoutons les modifications nécessaires pour construire le code C++ :
SET(CMAKE_SYSTEM_NAME Darwin)
SET(CMAKE_C_COMPILER arm-apple-darwin11-clang)
SET(CMAKE_CXX_COMPILER arm-apple-darwin11-clang++)
SET(CMAKE_LINKER arm-apple-darwin11-ld)
Vous pouvez maintenant compiler en utilisant cmake et make, mais n’oubliez pas d’ajouter $PATH à la chaîne d’outils du compilateur croisé :
PATH=$PATH:~/Sources/cctools-port/usage_examples/ios_toolchain/target/bin
Pour une liaison correcte avec les frameworks et SDL, nous les écrivons en cmake, dépendances du jeu Space Jaguar par exemple :
target_link_libraries(
${FSEGT_PROJECT_NAME}
${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/libclang_rt.ios.a
${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/libSDL2.a
${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/libSDL2_mixer.a
${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/libSDL2_image.a
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/CoreServices.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/ImageIO.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/Metal.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/AVFoundation.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/GameController.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/CoreMotion.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/CoreGraphics.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/AudioToolbox.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/CoreAudio.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/QuartzCore.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/OpenGLES.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/UIKit.framework"
"${FLAME_STEEL_PROJECT_ROOT_DIRECTORY}/scripts/buildScripts/ios/resources/libs/Foundation.framework"
)
Dans mon cas, les bibliothèques SDL, SDL_Image et SDL_mixer sont compilées à l’avance dans Xcode sur macOS pour les liaisons statiques ; Frameworks copiés depuis Xcode. La bibliothèque libclang_rt.ios.a a également été ajoutée, qui inclut des appels d’exécution spécifiques à iOS, par exemple isOSVersionAtLeast. Une macro est incluse pour travailler avec OpenGL ES, désactivant les fonctions non prises en charge dans la version mobile, similaire à Android.
Après avoir résolu tous les problèmes de construction, vous devriez obtenir le binaire assemblé pour arm. Ensuite, envisageons d’exécuter le binaire assemblé sur un appareil sans Jailbreak.
Sur macOS, installez Xcode, inscrivez-vous sur le portail Apple, sans payer pour le programme développeur. Ajouter un compte dans Xcode -> Préférences -> Comptes, créez une application vierge et construisez sur un appareil réel. Lors de l’assemblage, l’appareil sera ajouté au compte développeur gratuit. Après l’assemblage et le lancement, vous devez créer l’archive ; pour ce faire, sélectionnez Appareil et produit iOS génériques -> Archive. Une fois l’archive créée, extrayez-en les fichiersembedded.mobileprovision et PkgInfo. Depuis le journal de build vers l’appareil, recherchez la ligne de codedesign avec la clé de signature correcte, le chemin d’accès au fichier de droits avec l’extension app.xcent, copiez-le.
Copiez le dossier .app de l’archive, remplacez le binaire de l’archive par un compilé par un compilateur croisé sous Linux (par exemple SpaceJaguar.app/SpaceJaguar), puis ajoutez les ressources nécessaires au .app, vérifiez le intégrité des fichiers PkgInfo et Embedded.mobileprovision dans le .app à partir de l’archive, copiez à nouveau si nécessaire. Nous re-signons le .app à l’aide de la commande codesign – le codedesign nécessite une clé d’entrée pour la signature, le chemin d’accès au fichier de droits (peut être renommé avec une extension .plist)
Après la re-signature, créez un dossier Payload, déplacez-y le dossier avec l’extension .app, créez une archive zip avec Payload à la racine, renommez l’archive avec l’extension .ipa. Après cela, dans Xcode, ouvrez la liste des appareils et faites glisser le nouvel ipa vers la liste des applications de l’appareil ; L’installation via Apple Configurator 2 ne fonctionne pas pour cette méthode. Si la re-signature est effectuée correctement, alors l’application avec le nouveau binaire sera installée sur un appareil iOS (par exemple iPad) avec un certificat de 7 jours, cela suffit pour la période de test.
Sources
https://github.com/tpoechtrager/cctools-port
https://docs.godotengine.org/ru/latest/development/compiling/cross-compiling_for_ios_on_linux.html
https://jonnyzzz.com/blog/2018/06/13/link-error-3/
https://stackoverflow.com/questions/6896029/re-sign-ipa-iphone
https://developer.apple.com/library/archive/documentation/Security/Conceptual/CodeSigningGuide/Procedures/Procedures.html
Vision des jeux #4
La quatrième édition d’une chronique très incohérente sur les jeux Games Vision.
World Of Horror (multiplateforme, panstasz) – jeu roguelike à accès anticipé dans le style euh quoi ? Une aventure d’horreur textuelle avec des éléments RPG ? Rappelant graphiquement les jeux des années 80, vous pouvez choisir parmi une palette 1 bit ou 2 bits avec des variations.
Les commandes semblent étranges au début, mais avec le temps, on s’y habitue, car c’est pour cela que c’est un roguelike : surprendre et être original dans tous les aspects. Musique chiptune époustouflante, esthétique japonaise de la fin des années 80, visuels inspirés de l’œuvre de Junji Ito, histoires étranges à la manière de Lovecraft, rejouabilité presque infinie.
De quoi d’autre avez-vous besoin ?
Note : 9/10
Château éternel [REMASTERIÉ] (PC, Daniele Vicinanzo, Giulio Perrone, Leonard Menchiari) – un jeu moderne dans le style d’Another World, Flashback. La palette a été spécialement réduite aux couleurs CGA. La description de ce jeu doit commencer par la légende de sa création : vers 1987, l’un des enfants des développeurs d’Eternal Castle a vu le jeu et s’en est souvenu toute sa vie. En conséquence, le jeu n’est jamais sorti, mais. le code source a été trouvé et restauré en 2019, publiant une version améliorée. Cependant, la description sur Steam contient des informations selon lesquelles il s’agit d’un remaster d’un best-seller de 1987, mais cette année-là, aucun jeu portant ce nom n’est sorti, ce qui est vrai et ce qui ne l’est pas, c’est à vous de décider.
Les graphismes et le gameplay sont clairement adaptés à ceux qui aiment être nostalgiques du bon vieux temps ; très souvent, il y a des moments où il semble que le jeu s’est figé, mais en fait il suffit d’appuyer sur les boutons de mouvement ou d’action pour voir ce qui se passe. se passe à l’écran. Ce gadget crée un sentiment de maladresse et de perte de contrôle qui était souvent utilisé dans les jeux plus anciens, mais qui a été complètement abandonné dans les jeux modernes.
Note : 8/10
Mort et amp; Taxes (PC, Placeholder Gameworks) – Avez-vous déjà rêvé de travailler comme une seule personne en tant que juge et bourreau ? Aimez-vous les longues robes noires, les tresses métalliques et le fait de faire craquer vos jointures ? Alors c’est le jeu parfait pour vous car “Les deux seules choses que vous ne pouvez pas éviter sont la mort et les impôts.”
Il s’agit d’un simulateur unique en son genre de l’ange de la mort, vous devez choisir qui vit et qui meurt. En plus de tuer ou de donner la vie, vous pouvez lire le fil d’actualité sur votre smartphone et voir comment votre choix affecte le monde terrestre. Vous devez également communiquer avec votre patron immédiat nommé Faith (Destin), acheter des objets et toutes sortes d’ustensiles pour la table, par exemple, je me suis acheté un cactus brutal. N’oubliez pas de parler au miroir, c’est très excitant. Parmi les inconvénients, il convient de noter l’intimité générale de ce qui se passe ; au bout de quelques jours de jeu, le jeu devient un peu monotone.
Note : 8/10
Réparer un disque dur lent sous Windows 10
Cette note est dédiée à tous les utilisateurs de disques durs qui n’abandonnent pas.
Après 1 an et demi d’utilisation de l’ordinateur portable HP Pavilion avec un double disque dur (Windows 10) et SSD (Ubuntu), j’ai commencé à remarquer des temps de chargement très longs pour les applications, une absence de réponse générale de l’interface et des blocages sur les opérations les plus simples. sous Windows 10. Le problème a été minimisé dans la mesure où il est devenu possible d’utiliser à nouveau l’ordinateur portable. Ensuite, je décrirai les étapes que j’ai suivies pour résoudre le problème.
Diagnostic
Pour commencer la recherche, nous devons éliminer tout type de canular ; commençons par déterminer les principales causes des pannes de disque dur. Qu’est-ce qui peut mal se passer lorsque l’on travaille avec un disque dur ? Des problèmes peuvent survenir au niveau physique de l’électronique et au niveau des données logiques et logicielles.
Les problèmes électroniques incluent des éléments tels que : une alimentation électrique d’ordinateur/ordinateur portable qui ne fonctionne pas, des problèmes avec la batterie de l’ordinateur portable ; usure des composants du disque dur, problèmes dans les circuits et puces des composants internes du disque, erreurs de micrologiciel, conséquences de chocs/chutes du disque ou problèmes similaires avec d’autres appareils qui affectent son fonctionnement.
L’usure critique d’un disque dur est considérée comme le moment où un tel nombre de secteurs défectueux (bloc défectueux) apparaît qu’un fonctionnement ultérieur du disque est impossible. Ces blocs sont bloqués par le firmware du disque dur, les données sont transférées automatiquement vers d’autres secteurs et ne devraient affecter le fonctionnement du disque qu’à un certain moment critique.
Les problèmes de logique du programme incluent des erreurs dans le système de fichiers dues à un fonctionnement incorrect des applications, aux actions de l’utilisateur : éteindre l’appareil lorsqu’il est chaud, terminer les processus d’enregistrement sans arrêter correctement les applications, des erreurs dans les pilotes, les services du système d’exploitation.
Sans outils de diagnostic électronique spécialisés, nous ne pouvons que vérifier l’exactitude du niveau du logiciel ; ce faisant, des problèmes électroniques peuvent être découverts, qui sont généralement éliminés par la méthode de réparation en bloc (remplacement de composants/puces) ; Ensuite, nous examinerons les méthodes de diagnostic logiciel utilisant des utilitaires de diagnostic. Il convient de noter que tous les utilitaires doivent être lancés sur le système avec la priorité maximale, car d’autres applications peuvent interférer avec les mesures de performances et bloquer la lecture/écriture du disque, ce qui entraînera des résultats de diagnostic incorrects.
INTELLIGENT
S.M.A.R.T. système de surveillance de l’état des périphériques de stockage – HDD, SDD, eMMC, etc. Vous permet d’évaluer l’usure de l’appareil, d’afficher le nombre de blocs défectueux et de prendre d’autres actions en fonction des données. Vous pouvez afficher SMART dans différentes applications pour travailler avec des disques ; je préfère utiliser les utilitaires du fabricant. Pour mon disque dur Seagate, j’ai utilisé l’utilitaire SeaTools, pour lequel l’état était affiché comme BON, c’est-à-dire que le micrologiciel du disque pense que tout va bien.
Utilitaires du fabricant
Les utilitaires du fabricant du disque proposent des tests pour vérifier son fonctionnement. SeaTools propose plusieurs types de tests, vous pouvez tous les utiliser pour localiser le problème. Des tests simples et rapides peuvent ne révéler aucun problème, préférez donc les tests longs. Dans mon cas, seul Long Test a trouvé des erreurs.
Slowride
Pour vérifier l’exactitude de la lecture, trouver des blocs lents ou morts, j’ai écrit une application slowride, cela fonctionne sur un principe très simple – ouvre un descripteur de périphérique de bloc, avec les paramètres utilisateur spécifiés, lit les données de l’ensemble du périphérique, avec des mesures de temps, la sortie de blocs lents. Le programme s’arrête à la première erreur ; dans ce cas, vous devrez passer à des utilitaires de suppression de données plus sérieux, car il n’est pas possible de lire les données du disque avec des méthodes simples.
Dans mon cas, la lecture de l’intégralité du disque s’est effectuée correctement, avec une légère baisse de vitesse – 90 Mo/s (5 400 tr/min) en une seconde, sur certaines zones du disque. D’où on pourrait conclure que j’avais affaire à un problème logiciel.
Analyse acoustique
Cette méthode ne s’applique pas aux méthodes de diagnostic logiciel, mais il est très important de résoudre le problème. Par exemple, si l’alimentation électrique fonctionne partiellement, le disque dur peut geler/geler et émettre un clic fort.
Dans mon cas, lorsque je travaillais avec un disque sous Windows 10, j’ai entendu quelque chose de familier à tous les propriétaires de disque dur, bruit de craquement fort de la tête du disque qui va et vient lorsque vous essayez de faire quelque chose dans le système d’exploitation, mais le son était presque constant, cela m’a fait penser qu’il y avait trop de fragmentation disque, surcharge du disque avec les services en arrière-plan.
Réparer
Aucun problème électronique n’a été détecté lors des diagnostics logiciels ; la lecture bloc par bloc de l’intégralité du disque s’est terminée correctement, mais SeaTools a montré des erreurs lors du test long.
Utilitaires du fabricant
En plus des diagnostics, le logiciel du fabricant du disque fournit des procédures de correction des erreurs. Dans SeaTools, le bouton Réparer tout en est responsable ; après avoir confirmé votre consentement à la perte potentielle de données, le processus de correction commencera. Ce correctif a-t-il été utile dans mon cas ? Non, le disque a continué à fonctionner bruyamment et lentement, mais le test long n’a plus montré d’erreurs.
CHKDSK
CHKSDK est un utilitaire Microsoft permettant de dépanner les erreurs logicielles des systèmes de fichiers Windows. Au fil du temps, ces erreurs s’accumulent sur le disque et peuvent grandement interférer avec le travail, conduisant notamment à l’impossibilité de lire/écrire des données. Vous pouvez trouver des instructions d’utilisation de l’utilitaire sur le site Web de Microsoft, mais je vous recommande d’utiliser tous les indicateurs possibles pour corriger les erreurs (au moment de la rédaction, il s’agit de /r /b /f) ; Vous devez exécuter l’analyse avec les droits d’administrateur via le terminal Windows (cmd), pour la partition système, elle aura lieu au démarrage du système, et cela peut prendre très longtemps, dans mon cas, cela a pris 12 heures.
Ce correctif a-t-il été utile dans mon cas ? Non.
Défragmentation de disque
Les données sur le disque sont traitées en blocs ; les fichiers volumineux sont généralement écrits en plusieurs blocs/fragments. Au fil du temps, de nombreux fichiers supprimés créent des blocs vides qui ne sont pas à proximité, de ce fait, lors de l’écriture de fichiers, ils remplissent ces vides et la tête de disque doit parcourir physiquement de longues distances. Ce problème est appelé fragmentation et seuls les utilisateurs de disques durs en sont confrontés. Lors de plusieurs correctifs, la fragmentation de mon disque dur était de 41%, visuellement cela ressemblait à ceci :

Autrement dit, tout va mal. Vous pouvez voir la fragmentation et la défragmenter à l’aide de l’utilitaire Defragger ou du défragmenteur intégré. Vous pouvez également activer le service « Optimiser les lecteurs ». sous Windows 10, planifiez la défragmentation dans le panneau de configuration. Seuls les disques durs nécessitent une défragmentation ; il n’est pas conseillé de l’activer pour les disques SSD, car cela entraînerait une usure accélérée du disque, apparemment pour cette raison, la défragmentation en arrière-plan est désactivée par défaut.
Une autre option de défragmentation est également connue : transférer des données sur un autre disque, formater le disque et recopier les données. Dans ce cas, les données seront écrites dans des secteurs complètement vides, tout en conservant la structure logique correcte pour le fonctionnement du système. Cette option pose de nombreux problèmes lors de la réinitialisation des métadonnées potentiellement critiques qui peuvent ne pas bouger lors d’une copie normale.
Désactiver les services
À l’aide de l’utilitaire Process Monitor vous pouvez suivre les processus qui chargent le disque dur avec leur travail, activez simplement les colonnes IO Write/Read. Après avoir recherché cette chronique, j’ai désactivé le service Xbox Game Bar, le service d’accélération en arrière-plan bien connu pour les programmes Superfetch sous le nouveau nom SysMain, via le panneau des services du panneau de configuration. Superfetch doit constamment analyser les applications que l’utilisateur utilise et accélérer leur lancement en les mettant en cache dans la RAM ; dans mon cas, cela a conduit au chargement en arrière-plan de l’ensemble du disque et à l’incapacité de travailler.
Nettoyer le disque
J’ai également supprimé les anciennes applications et les fichiers inutiles, libérant ainsi des secteurs pour une fragmentation correcte, simplifiant le fonctionnement du système d’exploitation, réduisant le nombre de services et de programmes inutiles et lourds.
Total
Qu’est-ce qui a le plus aidé ? Une différence notable de performances a été obtenue après la défragmentation du disque ; les blocages spontanés ont été éliminés en désactivant les services Xbox et Superfetch. Ces problèmes ne se produiraient-ils pas si j’avais utilisé un SSD ? Il n’y aurait certainement aucun problème de fonctionnement lent dû à la fragmentation, les problèmes de services devraient de toute façon être résolus et les erreurs logicielles ne dépendent pas du type de lecteur. Dans un avenir proche, je prévois une transition complète vers le SSD, mais pour l’instant « Vive les crêpes, les crêpes pour toujours ! »
Liens
http://www.outsidethebox.ms/why-windows-8-defragments-your-ssd-and-how-you-can-avoid-this/
https://channel9.msdn.com/Shows/The-Defrag-Show
https://www.seagate.com/ru/ru/support/downloads/seatools/
https://www.ccleaner.com/defraggler/download
https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/chkdsk
https://gitlab.com/demensdeum/slowride/
Benchmark Slowride des appareils en bloc
Slowride – utilitaire permettant de vérifier la vitesse de lecture des périphériques de bloc pour les systèmes d’exploitation compatibles POSIX avec un accès root à /dev/sd*. Vous pouvez tester les performances de lecture des appareils en mode bloc à l’aide d’un seuil de temps pour diagnostiquer les performances de lecture.
Commande pour lire des blocs de 100 Mo sur l’ensemble de l’appareil, en produisant des blocs au-dessus du seuil de 2 secondes :
sudo ./slowride /dev/sda 100 2000
Code source
https://gitlab.com/demensdeum/slowride
RPG d’action 3D Space Jaguar
Je n’ai pas annoncé de nouveaux projets depuis longtemps) Le prochain projet sur lequel je commence à travailler – RPG d’action 3D appelé Space Jaguar Une histoire dans un décor de science-fiction sur un dur à cuire nommé Jag et sa difficile aventure à la recherche de son père disparu. Il y aura des graphismes 3D sur le Flame Steel Engine (ou éventuellement sur tout autre moteur populaire), utilisant les développements de projets antérieurs (Death Mask, Cube Art Project), une intrigue comique avec de nombreuses références, des batailles d’arcade et des boss. Je ne suis pas prêt à parler de la date de sortie de la version complète ; je prévois de sortir le jeu en plusieurs parties.
Dépôt du projet :
https://gitlab.com/demensdeum/space-jaguar-action-rpg
Écrire un serveur backend en C++ FCGI
Une brève note sur la façon dont j’ai écrit la partie serveur pour l’éditeur 3D Cube Art Project, le serveur doit enregistrer et afficher le travail des utilisateurs de la version Web, en leur donnant des URL courtes à l’aide du bouton Enregistrer. Au début, je voulais utiliser Swift/PHP/Ruby/JS ou un langage moderne similaire pour le backend, mais après avoir examiné les caractéristiques de mon VPS, j’ai décidé d’écrire le serveur en C/C++.
Vous devez d’abord installer libfcgi sur le serveur et le module de support fcgi pour votre serveur Web, exemple pour Ubuntu et Apache :
sudo apt install libfcgi libapache2-mod-fcgid
Ensuite, nous configurons le module dans la configuration :
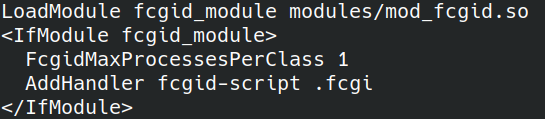
FcgidMaxProcessesPerClass – nombre maximum de processus par classe, je l’ai défini sur 1 processus car je ne m’attends pas à une charge importante.
AddHandler fcgid-script .fcgi – extension de fichier avec laquelle le module fcgi doit démarrer.
Ajoutez à la config le dossier à partir duquel les applications cgi seront lancées :

Ensuite, nous écrivons une application en C/C++ avec le support fcgi, l’assemblons et la copions dans le dossier /var/www/html/cgi-bin.
Exemples de code et de script de build :
https://gitlab.com/demensdeum/cube-art-project-server/-/blob/master/src/cubeArtProjectServer.cpp
https://gitlab.com/demensdeum/cube-art-project-server/-/blob/master/src/build.sh
Après cela, vous devrez redémarrer votre serveur Web :
systemctl restart apache2
Ensuite, entrez les autorisations nécessaires pour exécuter le dossier cgi-bin via chmod.
Après cela, votre programme cgi devrait fonctionner via un navigateur en utilisant le lien, exemple pour le serveur Cube Art Project :
http://192.243.103.70/cgi-bin/cubeArtProject/cubeArtProjectServer.fcgi
Si quelque chose ne fonctionne pas, consultez les journaux du serveur Web ou connectez-vous avec un débogueur au processus en cours ; le processus de débogage ne doit pas différer du processus de débogage d’une application client standard.
Sources
https://habr.com/ru/post/154187/
http://chriswu.me/blog/writing-hello-world-in-fcgi-with-c-plus-plus/
Code source
https://gitlab.com/demensdeum/cube-art -serveur-de-projet
Projet artistique cubique
Projet d’art cubique – ; éditeur 3D cubique.
Vous avez une incroyable opportunité de vous déplacer sur la scène, de créer et de supprimer des cubes à l’aide des boutons WSAD + E, de faire tourner la molette de la souris pour changer la couleur du cube. Actuellement, seules 16 couleurs sont prises en charge, mais de nombreuses améliorations sont prévues dans le futur.
Version Web
https://demensdeum.com/games/CubeArtProjectWEB/
Windows
https://demensdeum.com/games/CubeArtProjectReleases/CubeArtProjectWin32.zip
macOS
https://demensdeum.com/games/CubeArtProjectReleases/CubeArtProjectMacOS.zip
Linux (x86-64)
https://demensdeum.com/games/CubeArtProjectReleases/CubeArtProjectLinux86_64.zip
Android
(Concept, nécessite une souris USB)
https://demensdeum.com/games/CubeArtProjectReleases/CubeArtProject.apk
Code source
https://gitlab.com/demensdeum/cube-art-project-bootstrap
https://gitlab.com/demensdeum/cube-art-project-server
Technologies : SDL, Emscripten, MinGW, Glew, GLM, Cpp-JSON
Portage d’une application C++ SDL sur Android
Dans cet article, je décrirai mon expérience de portage d’un prototype d’éditeur 3D Cube Art Projectsur Android.
Tout d’abord, regardons le résultat : un éditeur avec un curseur cubique 3D rouge est exécuté dans l’émulateur :

Pour réussir l’assemblage, vous deviez procéder comme suit :
- Installez les derniers SDK et NDK Android (plus la version du NDK est récente, mieux c’est).
- Téléchargez le code source SDL2, puis prenez le modèle à partir de là pour créer l’application Android.
- Ajoutez une image SDL et un mélangeur SDL à l’assemblage.
- Ajouter les bibliothèques de mon moteur de jeu et de mon kit d’outils, leurs dépendances (GLM, JSON pour Modern C++)
- Adapter les fichiers d’assemblage pour Gradle.
- Adapter le code C++ pour la compatibilité avec Android, modifications affectées aux composants dépendants de la plate-forme (OpenGL ES, initialisation du contexte graphique)
- Créez et testez le projet sur l’émulateur.
Modèle de projet
Chargement des sources SDL, SDL Image, SDL Mixer :
https://www.libsdl.org/download-2.0.php
Le dossier docs contient des instructions détaillées pour travailler avec le modèle de projet Android ; copiez le répertoire du projet Android dans un dossier séparé, créez un lien symbolique ou copiez le dossier SDL dans Android-project/app/jni.
Nous substituons l’identifiant correct au drapeau avd, lançons l’émulateur Android depuis le répertoire Sdk :
cd ~/Android/Sdk/emulator
./emulator -avd Pixel_2_API_24
Spécifiez les chemins dans le script, assemblez le projet :
rm -rf app/build || true
export ANDROID_HOME=/home/demensdeum/Android/Sdk/
export ANDROID_NDK_HOME=/home/demensdeum/Android/android-ndk-r21-beta2/
./gradlew clean build
./gradlew installDebug
Le modèle de projet SDL avec le code C du fichier doit être assemblé
android-sdl-test-app/cube-art-project-android/app/jni/src/YourSourceHere.c
Dépendances
Téléchargez le code source dans les archives pour SDL_image, SDL_mixer :
https://www.libsdl.org/projects/SDL_image/
https://www.libsdl.org/projects/SDL_mixer/
Chargement des dépendances de votre projet, par exemple mes bibliothèques partagées :
https://gitlab.com/demensdeum/FlameSteelCore/
https://gitlab.com/demensdeum/FlameSteelCommonTraits
https://gitlab.com/demensdeum/FlameSteelBattleHorn
https://gitlab.com/demensdeum/FlameSteelEngineGameToolkit/
https://gitlab.com/demensdeum/FlameSteelEngineGameToolkitFSGL
https://gitlab.com/demensdeum/FSGL
https://gitlab.com/demensdeum/cube-art-project
Nous téléchargeons tout cela dans app/jni, chaque « module » dans un dossier séparé, par exemple app/jni/FSGL. Ensuite, vous avez la possibilité de trouver des générateurs fonctionnels pour les fichiers Application.mk et Android.mk, je ne les ai pas trouvés, mais il existe peut-être une solution simple basée sur CMake. Suivez les liens et commencez à vous familiariser avec le format de fichier d’assemblage pour Android NDK :
https://developer.android.com/ndk/guides/application_mk
https://developer.android.com/ndk/guides/android_mk
Vous devriez également en savoir plus sur les différentes implémentations d’APP_STL dans NDK :
https://developer.android.com/ndk/guides/cpp-support.html
Après familiarisation, nous créons un fichier Android.mk pour chaque « module », suivi d’un exemple de fichier d’assemblage de la bibliothèque partagée Cube-Art-Project :
LOCAL_PATH := $(call my-dir)
include $(CLEAR_VARS)
APP_STL := c++_static
APP_CPPFLAGS := -fexceptions
LOCAL_MODULE := CubeArtProject
LOCAL_C_INCLUDES := $(LOCAL_PATH)/src $(LOCAL_PATH)/../include $(LOCAL_PATH)/../include/FlameSteelCommonTraits/src/FlameSteelCommonTraits
LOCAL_EXPORT_C_INCLUDES = $(LOCAL_PATH)/src/
define walk
$(wildcard $(1)) $(foreach e, $(wildcard $(1)/*), $(call walk, $(e)))
endef
ALLFILES = $(call walk, $(LOCAL_PATH)/src)
FILE_LIST := $(filter %.cpp, $(ALLFILES))
$(info CubeArtProject source code files list)
$(info $(FILE_LIST))
LOCAL_SRC_FILES := $(FILE_LIST:$(LOCAL_PATH)/%=%)
LOCAL_SHARED_LIBRARIES += FlameSteelCore
LOCAL_SHARED_LIBRARIES += FlameSteelBattleHorn
LOCAL_SHARED_LIBRARIES += FlameSteelCommonTraits
LOCAL_SHARED_LIBRARIES += FlameSteelEngineGameToolkit
LOCAL_SHARED_LIBRARIES += FlameSteelEngineGameToolkitFSGL
LOCAL_SHARED_LIBRARIES += FSGL
LOCAL_SHARED_LIBRARIES += SDL2
LOCAL_SHARED_LIBRARIES += SDL2_image
LOCAL_LDFLAGS := -static-libstdc++
include $(BUILD_SHARED_LIBRARY)
Tout utilisateur expérimenté de CMake comprendra cette configuration dès les premières lignes, les formats sont très similaires, Android.mk n’a pas GLOB_RECURSIVE, vous devez donc rechercher de manière récursive les fichiers sources à l’aide de la fonction walk.
Nous modifions Application.mk, Android.mk pour créer du code C++ et non C :
APP_ABI := armeabi-v7a arm64-v8a x86 x86_64
APP_PLATFORM=android-16
APP_STL := c++_static
APP_CPPFLAGS := -fexceptions
Renommer YourSourceHere.c -> YourSourceHere.cpp, récupérer les entrées, modifier le chemin dans l’assembly, par exemple :
app/jni/src/Android.mk:LOCAL_SRC_FILES := YourSourceHere.cpp
Ensuite, essayez de construire le projet, si vous voyez des erreurs du compilateur concernant l’absence d’en-têtes, puis vérifiez l’exactitude des chemins dans Android.mk ; S’il y a des erreurs de l’éditeur de liens comme « référence non définie », vérifiez que les fichiers de code source dans les assemblys sont correctement spécifiés ; les listes peuvent être tracées en spécifiant $(info $(FILE_LIST)) dans le fichier Android.mk. N’oubliez pas le mécanisme de double liaison, en utilisant des modules dans la clé LOCAL_SHARED_LIBRARIES et en corrigeant la liaison via LD, par exemple pour FSGL :
LOCAL_LDLIBS := -lEGL -lGLESv2
Adaptation et lancement
J’ai dû modifier certaines choses, par exemple supprimer GLEW des versions pour iOS et Android, renommer certains appels OpenGL, ajouter le suffixe EOS (glGenVertexArrays -> glGenVertexArraysOES), inclure une macro pour les fonctions de débogage modernes manquantes , la cerise sur le gâteau est l’inclusion implicite des en-têtes GLES2 indiquant la macro GL_GLEXT_PROTOTYPES 1 :
#define GL_GLEXT_PROTOTYPES 1
#include "SDL_opengles2.h"
J’ai aussi observé un écran noir aux premiers lancements avec une erreur du type “E/libEGL: validate_display:255 error 3008 (EGL_BAD_DISPLAY)”, j’ai changé l’initialisation de la fenêtre SDL, le profil OpenGL et tout a fonctionné :
SDL_DisplayMode mode;
SDL_GetDisplayMode(0,0,&mode);
int width = mode.w;
int height = mode.h;
window = SDL_CreateWindow(
title,
0,
0,
width,
height,
SDL_WINDOW_OPENGL | SDL_WINDOW_FULLSCREEN | SDL_WINDOW_RESIZABLE
);
SDL_GL_SetAttribute( SDL_GL_CONTEXT_PROFILE_MASK, SDL_GL_CONTEXT_PROFILE_ES );
Sur l’émulateur, l’application est installée par défaut avec l’icône SDL et le nom « Jeu ».
Il me reste juste à explorer la possibilité de générer automatiquement des fichiers d’assembly basés sur CMake, ou de migrer des assemblys pour toutes les plateformes vers Gradle ; cependant, CMake reste le choix de facto pour le développement C++ en cours.
Code source
https://gitlab.com/demensdeum/android- sdl-test-app
https://gitlab.com/demensdeum/android-sdl-test-app/tree/master/cube-art-project-android
Sources
https://developer.android.com/ ndk/guides/cpp-support.html
https://developer.android.com/ndk/guides/application_mk
https://developer.android.com/ndk/guides/android_mk
https://lazyfoo.net/tutorials/SDL/52_hello_mobile/android_windows/index.php
https://medium.com/androiddevelopers/getting-started-with-c-and-android-native-activities-2213b402ffff
Site Internet de LazyFoo Productions
Peut-être vaut-il la peine de mentionner le site Web à partir duquel mes projets et nouveaux développements commencent presque toujours, il s’agit du site Web de LazyFoo Productions, où vous pouvez trouver des réponses à des sujets assez hardcore : des exemples d’utilisation d’API complexes, apprendre à combiner des API apparemment incompatibles systèmes (Android/C++) avec une explication détaillée des principes de fonctionnement, des exemples de code de travail.
Monde à l’envers
Pour développer un nouveau projet, Cube Art Project a adopté la méthodologie Test Driven Development. Dans cette approche, un test pour une fonctionnalité spécifique de l’application est d’abord implémenté, puis la fonctionnalité spécifique est implémentée. Je considère que le gros avantage de cette approche réside dans la mise en œuvre des interfaces finales, qui sont aussi peu impliquées que possible dans les détails de mise en œuvre, avant le début du développement des fonctionnalités. Avec cette approche, le test dicte la poursuite de l’implémentation, ajoutant tous les avantages de la programmation contractuelle, lorsque les interfaces sont des contrats pour une implémentation spécifique.
Projet d’art cubique – Un éditeur 3D dans lequel l’utilisateur construit des figures à partir de cubes ; il n’y a pas si longtemps, ce genre était très populaire. Puisqu’il s’agit d’une application graphique, j’ai décidé d’ajouter des tests avec validation de capture d’écran.
Pour valider les captures d’écran, vous devez les récupérer depuis le contexte OpenGL, cela se fait à l’aide de la fonction glReadPixels. La description des arguments de la fonction est simple : position de départ, largeur, hauteur, format (RGB/RGBA/etc.), pointeur vers le tampon de sortie ; toute personne ayant travaillé avec SDL ou ayant de l’expérience avec les tampons de données en C remplacera simplement les arguments nécessaires. Cependant, je pense qu’il est nécessaire de décrire une fonctionnalité intéressante du tampon de sortie glReadPixels : les pixels y sont stockés de bas en haut, tandis que dans SDL_Surface, toutes les opérations de base se déroulent de haut en bas.
Autrement dit, après avoir chargé une capture d’écran de référence à partir d’un fichier png, je n’ai pas pu comparer directement les deux tampons, car l’un d’eux était à l’envers.
Pour retourner le tampon de sortie d’OpenGL, vous devez le remplir en soustrayant la hauteur de la capture d’écran pour la coordonnée Y. Cependant, il convient de considérer qu’il y a une chance d’aller au-delà des limites du tampon si vous n’en soustrayez pas une lors du remplissage, ce qui le fera. conduire à une corruption de la mémoire.
Comme j’essaie toujours d’utiliser le paradigme POO de « programmation par interfaces », au lieu d’un accès direct à la mémoire de type C par pointeur, lorsque j’ai essayé d’écrire des données en dehors du tampon, l’objet m’en a informé grâce à la validation des limites dans la méthode. .
Le code final pour la méthode permettant d’obtenir une capture d’écran de haut en bas :
auto width = params->width;
auto height = params->height;
auto colorComponentsCount = 3;
GLubyte *bytes = (GLubyte *)malloc(colorComponentsCount * width * height);
glReadPixels(0, 0, width, height, GL_RGB, GL_UNSIGNED_BYTE, bytes);
auto screenshot = make_shared(width, height);
for (auto y = 0; y < height; y++) {
for (auto x = 0; x < width; x++) {
auto byteX = x * colorComponentsCount;
auto byteIndex = byteX + (y * (width * colorComponentsCount));
auto redColorByte = bytes[byteIndex];
auto greenColorByte = bytes[byteIndex + 1];
auto blueColorByte = bytes[byteIndex + 2];
auto color = make_shared(redColorByte, greenColorByte, blueColorByte, 255);
screenshot->setColorAtXY(color, x, height - y - 1);
}
}
free(bytes);
Sources
https://community.khronos.org/ t/glreadpixels-fliped-image/26561
https://stackoverflow.com/questions/8346115/why-are-bmps-stored-upside-down
Code source
https://gitlab.com/demensdeum/cube- art-project-bootstrap
Sous-chaîne commune la plus longue
Dans cet article, je décrirai un algorithme permettant de résoudre le plus grand problème de sous-chaîne courant. Supposons que nous essayions de décrypter des données binaires chiffrées. Essayons d’abord de trouver des modèles communs en recherchant la plus grande sous-chaîne.
Exemple de chaîne d’entrée :
adasDATAHEADER??jpjjwerthhkjbcvkDATAHEADER??kkasdf
Nous recherchons une chaîne qui se répète deux fois :
EN-TÊTE DE DONNÉES ??
Préfixes
Tout d’abord, écrivons une méthode pour comparer les préfixes de deux chaînes, laissons-la renvoyer la chaîne résultante dans laquelle les caractères du préfixe de gauche sont égaux aux caractères du préfixe de droite.
Par exemple, pour les lignes :
val lhs = "asdfWUKI"
val rhs = "asdfIKUW"
Chaîne de résultat – asdf
Exemple en Kotlin :
fun longestPrefix(lhs: String, rhs: String): String {
val maximalLength = min(lhs.length-1, rhs.length -1)
for (i in 0..maximalLength) {
val xChar = lhs.take(i)
val yChar = rhs.take(i)
if (xChar != yChar) {
return lhs.substring(0, i-1)
}
}
return lhs.substring(0,maximalLength)
}
Force Brute
Lorsque les choses ne fonctionnent pas bien, vous devriez recourir à la force brute. En utilisant la méthode longestPrefix, nous allons parcourir la chaîne en deux boucles, la première prend la chaîne de i à la fin, la seconde de i + 1 à la fin, les transmet pour rechercher le plus grand préfixe. La complexité temporelle de cet algorithme est d’environ O(n^2) ~ O(n*^3).
Exemple en Kotlin :
fun searchLongestRepeatedSubstring(searchString: String): String {
var longestRepeatedSubstring = ""
for (x in 0..searchString.length-1) {
val lhs = searchString.substring(x)
for (y in x+1..searchString.length-1) {
val rhs = searchString.substring(y)
val longestPrefix = longestPrefix(lhs, rhs)
if (longestRepeatedSubstring.length < longestPrefix.length) {
longestRepeatedSubstring = longestPrefix
}
}
}
return longestRepeatedSubstring
}
Tableau de suffixes
Pour une solution plus élégante, nous avons besoin d'un outil : une structure de données appelée "Suffix Array". Cette structure de données est un tableau de sous-chaînes remplies dans une boucle, où chaque sous-chaîne commence du caractère suivant de la ligne jusqu'à la fin.
Par exemple, pour la ligne :
adasDATAHEADER??
Le tableau de suffixes ressemble à ceci :
adasDATAHEADER??
dasDATAHEADER??
asDATAHEADER??
sDATAHEADER??
DATAHEADER??
ATAHEADER??
TAHEADER??
AHEADER??
HEADER??
EADER??
ADER??
DER??
ER??
R??
??
?
On résout en triant
Trions le tableau de suffixes, puis parcourons tous les éléments dans une boucle où l'élément actuel est dans la main gauche (à gauche), le suivant est dans la main droite (à droite) et calculons le préfixe le plus long en utilisant le plus longPrefix méthode.
Exemple en Kotlin :
fun searchLongestRepeatedSubstring(searchString: String): String {
val suffixTree = suffixArray(searchString)
val sortedSuffixTree = suffixTree.sorted()
var longestRepeatedSubstring = ""
for (i in 0..sortedSuffixTree.count() - 2) {
val lhs = sortedSuffixTree[i]
val rhs = sortedSuffixTree[i+1]
val longestPrefix = longestPrefix(lhs, rhs)
if (longestRepeatedSubstring.length < longestPrefix.length) {
longestRepeatedSubstring = longestPrefix
}
}
return longestRepeatedSubstring
}
La complexité temporelle de l'algorithme est O(N log N), ce qui est bien meilleur qu'une solution simple.
Sources
https://en.wikipedia.org/wiki/Longest_common_substring_problem
Code source
https://gitlab.com/demensdeum/algorithms
Tri par insertion, tri par fusion
Tri par insertion
Tri par insertion – chaque élément est comparé aux précédents de la liste et l’élément est échangé avec le plus grand, le cas échéant, sinon la boucle de comparaison interne s’arrête. Étant donné que les éléments sont triés du premier au dernier, chaque élément est comparé à une liste déjà triée, ce qui *éventuellement* réduit le temps d’exécution global. La complexité temporelle de l’algorithme est O(n^2), c’est-à-dire identique à la variété des bulles.
Fusionner le tri
Tri par fusion – la liste est divisée en groupes d’un élément, puis les groupes sont « fusionnés » par paires avec comparaison simultanée. Dans mon implémentation, lors de la fusion de paires, les éléments de gauche sont comparés aux éléments de droite, puis déplacés vers la liste résultante si les éléments de gauche ont disparu, alors tous les éléments de droite sont ajoutés à la liste résultante ; liste (leur comparaison supplémentaire est inutile, puisque tous les éléments des groupes passent par des itérations de tri)< br />Le travail de cet algorithme est très simple à paralléliser ; l’étape de fusion des paires peut être effectuée en threads, en attendant la fin des itérations dans le répartiteur.
Résultat de l’algorithme pour l’exécution monothread :
["John", "Alice", "Mike", "#1", "Артем", "20", "60", "60", "DoubleTrouble"]
[["John"], ["Alice"], ["Mike"], ["#1"], ["Артем"], ["20"], ["60"], ["60"], ["DoubleTrouble"]]
[["Alice", "John"], ["#1", "Mike"], ["20", "Артем"], ["60", "60"], ["DoubleTrouble"]]
[["#1", "Alice", "John", "Mike"], ["20", "60", "60", "Артем"], ["DoubleTrouble"]]
[["#1", "20", "60", "60", "Alice", "John", "Mike", "Артем"], ["DoubleTrouble"]]
["#1", "20", "60", "60", "Alice", "DoubleTrouble", "John", "Mike", "Артем"]
Sortie de l’algorithme pour l’exécution multithread :
["John", "Alice", "Mike", "#1", "Артем", "20", "60", "60", "DoubleTrouble"]
[["John"], ["Alice"], ["Mike"], ["#1"], ["Артем"], ["20"], ["60"], ["60"], ["DoubleTrouble"]]
[["20", "Артем"], ["Alice", "John"], ["60", "60"], ["#1", "Mike"], ["DoubleTrouble"]]
[["#1", "60", "60", "Mike"], ["20", "Alice", "John", "Артем"], ["DoubleTrouble"]]
[["DoubleTrouble"], ["#1", "20", "60", "60", "Alice", "John", "Mike", "Артем"]]
["#1", "20", "60", "60", "Alice", "DoubleTrouble", "John", "Mike", "Артем"]
La complexité temporelle de l’algorithme est O(n*log(n)), ce qui est légèrement meilleur que O(n^2)
Sources
https://en.wikipedia.org/wiki/Insertion_sort
https://en.wikipedia.org/wiki/Merge_sort
Code source
https://gitlab.com/demensdeum /algorithms/-/tree/master/sortAlgorithms/insertionSort
https://gitlab.com/demensdeum/algorithms/-/tree/master/sortAlgorithms/mergeSort
Tri à bulles à Erlang
Le tri par bulles est assez ennuyeux, mais il devient plus intéressant si vous essayez de l’implémenter dans un langage fonctionnel pour les télécommunications – c’est à dire. Erlang.
Nous avons une liste de numéros, nous devons la trier. L’algorithme de tri à bulles parcourt toute la liste, en itérant et en comparant les nombres par paires. Lors de la vérification, ce qui suit se produit : un nombre plus petit est ajouté à la liste de sortie, ou les nombres sont intervertis dans la liste actuelle s’il y en a moins à droite, la recherche continue avec le numéro suivant dans l’itération ; Ce parcours est répété jusqu’à ce qu’il n’y ait plus de remplacements dans la liste.
En pratique, cela ne vaut pas la peine d’être utilisé en raison de la grande complexité temporelle de l’algorithme – O(n^2); Je l’ai implémenté en Erlang, dans le style impératif, mais si vous êtes intéressé, vous pouvez rechercher de meilleures options :
-module(bubbleSort).
-export([main/1]).
startBubbleSort([CurrentHead|Tail]) ->
compareHeads(CurrentHead, Tail, [], [CurrentHead|Tail]).
compareHeads(CurrentHead, [NextHead|Tail], [], OriginalList) ->
if
CurrentHead < NextHead ->
compareHeads(NextHead, Tail, [CurrentHead], OriginalList);
true ->
compareHeads(CurrentHead, Tail, [NextHead], OriginalList)
end;
compareHeads(CurrentHead, [NextHead|Tail], OriginalOutputList, OriginalList) ->
if
CurrentHead < NextHead ->
OutputList = OriginalOutputList ++ [CurrentHead],
compareHeads(NextHead, Tail, OutputList, OriginalList);
true ->
OutputList = OriginalOutputList ++ [NextHead],
compareHeads(CurrentHead, Tail, OutputList, OriginalList)
end;
compareHeads(CurrentHead, [], OriginalOutputList, OriginalList) ->
OutputList = OriginalOutputList ++ [CurrentHead],
if
OriginalList == OutputList ->
io:format("OutputList: ~w~n", [OutputList]);
true ->
startBubbleSort(OutputList)
end.
main(_) ->
UnsortedList = [69,7,4,44,2,9,10,6,26,1],
startBubbleSort(UnsortedList).
Installation et lancement
Dans Ubuntu, Erlang est très facile à installer ; il suffit de taper sudo apt install erlang dans le terminal. Dans ce langage, chaque fichier doit être un module, avec une liste de fonctions pouvant être utilisées en externe – exporter. Les fonctionnalités intéressantes du langage incluent l’absence de variables, uniquement des constantes, l’absence de syntaxe standard pour la POO (ce qui n’empêche pas l’utilisation de techniques de POO), et bien sûr des calculs parallèles sans verrous basés sur le modèle d’acteur.
Vous pouvez exécuter le module soit via la console erl interactive, en exécutant une commande après l’autre, soit plus simplement via l’escript bubbleSort.erl ; Dans différents cas, le fichier aura un aspect différent, par exemple, pour escript, vous devez créer une fonction principale à partir de laquelle il démarrera.
Sources
https://www.erlang.org/
https://habr.com/ru/post/197364/
Code source
https://gitlab.com/ demensdeum/algorithms/blob/master/bubbleSort/bubbleSort.erl
Algorithme de comparaison lexicographique
L’algorithme de comparaison de chaînes lexicographiques fonctionne très simplement : les codes de caractères sont comparés en boucle et le résultat est renvoyé si les caractères ne sont pas égaux.
Un exemple pour le langage C peut être trouvé ici :
https://github.com/gcc-mirror/gcc/blob/master/libiberty/memcmp.c
Il convient de prendre en compte le fait que vous devez comparer les caractères dans un seul encodage statique, par exemple dans Swift, j’ai utilisé la comparaison caractère par caractère en UTF-32. L’option de tri de tableau utilisant memcmp fonctionnera exactement pour les caractères à un octet, dans d’autres cas (codages de longueur variable), l’ordre peut être incorrect. Je n’exclus pas la possibilité d’une implémentation basée sur des encodages de longueur variable, mais ce sera très probablement un ordre de grandeur plus compliqué.
La complexité temporelle de l’algorithme est O(1) dans le meilleur des cas, O(n) dans la moyenne et le pire des cas
Sources
https://ru.wikipedia.org/wiki/Lexicographic_order
Sources
https://gitlab.com/demensdeum /algorithms/blob/master/lexiCompare/lexiCompare.swift
Développement de jeux pour ZX Spectrum en C
Cet article absurde est dédié au développement d’un jeu pour l’ancien ordinateur ZX Spectrum en C. Jetons un coup d’œil au beau mec :

Sa production a commencé en 1982 et a été produite jusqu’en 1992. Caractéristiques techniques de la machine : processeur Z80 8 bits, 16-128 Ko de mémoire et autres extensions, comme la puce sonore AY-3-8910.
Dans le cadre du concours Yandex Retro Games Battle 2019 pour cette machine, j’ai écrit un jeu appelé Interceptor 2020. Comme je n’ai pas eu le temps d’apprendre le langage assembleur pour le Z80, j’ai décidé de le développer en C. En tant que chaîne d’outils, j’ai choisi un ensemble prêt à l’emploi – z88dk, qui contient des compilateurs C et de nombreuses bibliothèques auxiliaires pour accélérer la mise en œuvre des applications pour Spectrum. Il prend également en charge de nombreuses autres machines Z80, telles que les calculatrices MSX et Texas Instruments.
Ensuite, je décrirai mon survol superficiel de l’architecture informatique, la chaîne d’outils z88dk, et montrerai comment j’ai réussi à mettre en œuvre l’approche POO et à utiliser des modèles de conception.
Fonctionnalités d’installation
L’installation de z88dk doit être effectuée conformément au manuel du référentiel, cependant, pour les utilisateurs d’Ubuntu, je voudrais noter une fonctionnalité – Si vous avez déjà installé des compilateurs pour Z80 à partir de packages deb, vous devez les supprimer, puisque z88dk y accédera à partir du dossier bin par défaut en raison de l’incompatibilité des versions du compilateur de la chaîne d’outils, vous ne pourrez probablement rien compiler.< /p>
Bonjour tout le monde
Écrire Hello World est très simple :
#include
void main()
{
printf("Hello World");
}
Il est encore plus simple de compiler un fichier tap :
zcc +zx -lndos -create-app -o helloworld helloworld.c
Pour l’exécuter, utilisez n’importe quel émulateur ZX Spectrum prenant en charge les fichiers Tap, par exemple en ligne :
http://jsspeccy.zxdemo.org/
Dessinez sur l’image en plein écran
tl;dr Les images sont dessinées en tuiles, des tuiles de taille 8×8 pixels, les tuiles elles-mêmes sont intégrées dans la police Spectrum, puis l’image est imprimée sous forme de ligne à partir des index.
La bibliothèque de sortie de sprites et de tuiles sp1 génère des tuiles en utilisant UDG. L’image est traduite en un ensemble d’UDG individuels (tuiles), puis assemblés sur l’écran à l’aide d’indices. Il ne faut pas oublier que UDG est utilisé pour afficher du texte, et si votre image contient un très grand ensemble de tuiles (par exemple, plus de 128 tuiles), alors vous devrez dépasser les limites de l’ensemble et effacer le spectre par défaut. fonte. Pour contourner cette limitation, j’ai utilisé une base de 128 – 255 en simplifiant les images tout en laissant la police d’origine en place. À propos de la simplification des images ci-dessous.
Pour dessiner des images en plein écran, vous devez vous armer de trois utilitaires :
Gimp
img2spec
png2c-z88dk
Il existe un moyen pour les vrais hommes ZX, les vrais guerriers rétro, celui-ci consiste à ouvrir un éditeur graphique à l’aide de la palette Spectrum, connaissant les caractéristiques de la sortie de l’image, à la préparer manuellement et à la télécharger en utilisant png2c-z88dk ou png2scr.< /p>
Le moyen le plus simple – prenez une image 32 bits, changez le nombre de couleurs sur 3-4 dans Gimp, modifiez-la légèrement, puis importez-la dans img2spec afin de ne pas travailler manuellement avec les restrictions de couleur, exportez png et convertissez-la en tableau C en utilisant png2c- z88dk.
N’oubliez pas que pour une exportation réussie, chaque vignette ne peut pas contenir plus de deux couleurs.
En conséquence, vous recevrez un fichier h contenant le nombre de tuiles uniques, s’il y en a plus de ~128, alors simplifiez l’image dans Gimp (augmentez la répétabilité) et effectuez la procédure d’exportation sur une nouvelle. .
Après l’exportation, vous chargez littéralement la « police » des vignettes et imprimez le « texte » des index des vignettes sur l’écran. Vous trouverez ci-dessous un exemple de la « classe » de rendu :
// грузим шрифт в память
unsigned char *pt = fullscreenImage->tiles;
for (i = 0; i < fullscreenImage->tilesLength; i++, pt += 8) {
sp1_TileEntry(fullscreenImage->tilesBase + i, pt);
}
// ставим курсор в 0,0
sp1_SetPrintPos(&ps0, 0, 0);
// печатаем строку
sp1_PrintString(&ps0, fullscreenImage->ptiles);
Dessiner des sprites sur l’écran
Ensuite, je décrirai une méthode pour dessiner des sprites de 16 à 16 pixels sur l’écran. Je n’ai pas abordé l’animation et le changement de couleurs, parce que… C’est trivial qu’à ce stade déjà, comme je suppose, j’ai manqué de mémoire. Par conséquent, le jeu ne contient que des sprites monochromes transparents.
Nous dessinons une image png monochrome 16×16 dans Gimp, puis en utilisant png2sp1sprite nous la traduisons en un fichier d’assemblage asm, en code C nous déclarons des tableaux à partir du fichier d’assemblage et ajoutons le fichier au stade de l’assemblage.< /p>
Après l’étape de déclaration de la ressource sprite, celle-ci doit être ajoutée à l’écran à la position souhaitée, ci-dessous un exemple de code pour la « classe » de l’objet du jeu :
struct sp1_ss *bubble_sprite = sp1_CreateSpr(SP1_DRAW_MASK2LB, SP1_TYPE_2BYTE, 3, 0, 0);
sp1_AddColSpr(bubble_sprite, SP1_DRAW_MASK2, SP1_TYPE_2BYTE, col2-col1, 0);
sp1_AddColSpr(bubble_sprite, SP1_DRAW_MASK2RB, SP1_TYPE_2BYTE, 0, 0);
sp1_IterateSprChar(bubble_sprite, initialiseColour);
À partir des noms des fonctions, vous pouvez comprendre approximativement la signification de « – allouez de la mémoire pour le sprite, ajoutez deux colonnes 8×8, ajoutez une couleur pour le sprite.
La position du sprite est indiquée dans chaque image :
sp1_MoveSprPix(gameObject->gameObjectSprite, Renderer_fullScreenRect, gameObject->sprite_col, gameObject->x, gameObject->y);
Émulation de la POO
Il n’y a pas de syntaxe pour la POO en C, que devez-vous faire si vous le souhaitez toujours ? Vous devez connecter votre esprit et être éclairé par l’idée qu’il n’existe pas d’équipement POO ; tout revient finalement à l’une des architectures de machines, dans lesquelles il n’y a tout simplement aucun concept d’objet et d’autres abstractions qui lui sont associées.< /p>
Ce fait m’a empêché pendant très longtemps de comprendre pourquoi la POO est nécessaire, pourquoi il est nécessaire de l’utiliser si en fin de compte tout se résume au code machine.
Cependant, après avoir travaillé dans le développement de produits, j’ai découvert les plaisirs de ce paradigme de programmation, principalement, bien sûr, la flexibilité du développement, les mécanismes de protection du code, avec la bonne approche, la réduction de l’entropie, la simplification du travail d’équipe. Tous les avantages ci-dessus découlent de trois piliers : polymorphisme, encapsulation, héritage.
Il convient également de noter la simplification de la résolution des problèmes liés à l’architecture des applications, car 80 % des problèmes architecturaux ont été résolus par des informaticiens au siècle dernier et décrits dans la littérature sur les modèles de conception. Ensuite, je décrirai les façons d’ajouter une syntaxe de type POO au C.
Il est plus pratique de prendre des structures C comme base pour stocker les données d’une instance de classe. Bien sûr, vous pouvez utiliser un tampon d’octets, créer votre propre structure pour les classes, les méthodes, mais pourquoi réinventer la roue ? Après tout, nous réinventons déjà la syntaxe.
Données de classe
Exemple de champs de données « classe » GameObject :
struct GameObjectStruct {
struct sp1_ss *gameObjectSprite;
unsigned char *sprite_col;
unsigned char x;
unsigned char y;
unsigned char referenceCount;
unsigned char beforeHideX;
unsigned char beforeHideY;
};
typedef struct GameObjectStruct GameObject;
Enregistrez notre classe sous « GameObject.h », faites #include « GameObject.h » au bon endroit et utilisez-la.
Méthodes de classe
Compte tenu de l’expérience des développeurs du langage Objective-C, la signature d’une méthode de classe sera constituée de fonctions dans une portée globale, le premier argument sera toujours la structure des données, suivi des arguments de la méthode. Vous trouverez ci-dessous un exemple de « méthode » de la « classe » GameObject :
void GameObject_hide(GameObject *gameObject) {
gameObject->beforeHideX = gameObject->x;
gameObject->beforeHideY = gameObject->y;
gameObject->y = 200;
}
L’appel de méthode ressemble à ceci :
GameObject_hide(gameObject);
Les constructeurs et les destructeurs sont implémentés de la même manière. Il est possible d’implémenter un constructeur en tant qu’allocateur et initialiseur de champ, mais je préfère contrôler l’allocation et l’initialisation des objets séparément.
Travailler avec la mémoire
Gestion manuelle de la mémoire du formulaire à l’aide de malloc et free enveloppé dans des macros new et delete pour correspondre à C++ :
#define new(X) (X*)malloc(sizeof(X))
#define delete(X) free(X)
Pour les objets utilisés par plusieurs classes à la fois, une gestion semi-manuelle de la mémoire est implémentée sur la base d’un comptage de références, à l’image et à la ressemblance de l’ancien mécanisme Objective-C Runtime ARC :
void GameObject_retain(GameObject *gameObject) {
gameObject->referenceCount++;
}
void GameObject_release(GameObject *gameObject) {
gameObject->referenceCount--;
if (gameObject->referenceCount < 1) { sp1_MoveSprAbs(gameObject->gameObjectSprite, &Renderer_fullScreenRect, NULL, 0, 34, 0, 0);
sp1_DeleteSpr(gameObject->gameObjectSprite);
delete(gameObject);
}
}
Ainsi, chaque classe doit déclarer l’utilisation d’un objet partagé en utilisant retention, libérant ainsi la propriété via release. La version moderne d’ARC utilise des appels automatiques de rétention/libération.
Le son !
Le Spectrum dispose d’un tweeter capable de reproduire de la musique 1 bit ; les compositeurs de l’époque étaient capables de reproduire jusqu’à 4 canaux sonores simultanément.
Le Spectrum 128k contient une puce sonore distincte AY-3-8910, qui peut lire de la musique de suivi.
Une bibliothèque est proposée pour utiliser le tweeter dans le z88dk
Ce qui reste à apprendre
Je souhaitais me familiariser avec Spectrum, implémenter le jeu à l’aide du z88dk et apprendre beaucoup de choses intéressantes. J’ai encore beaucoup à apprendre, par exemple l’assembleur Z80, car il me permet d’utiliser toute la puissance du Spectrum, de travailler avec des banques de mémoire et de travailler avec la puce sonore AY-3-8910. J’espère participer au concours l’année prochaine !
Liens
https://rgb.yandex
https://vk.com/sinc_lair
https://www.z88dk.org/forum/
Code source
https://gitlab.com/demensdeum/ zx-projects/tree/master/interceptor2020
Recherche binaire
Supposons que nous ayons besoin de savoir si l’adresse e-mail « demensdeum@gmail.com » est incluse dans la liste des adresses e-mail autorisées pour la réception de lettres. .
Parcourons toute la liste du premier au dernier élément, en vérifiant si l’élément est égal à l’adresse spécifiée – Implémentons un algorithme de recherche linéaire. Mais cela prendra beaucoup de temps, n’est-ce pas ?
Pour répondre à cette question, utilisez la notation « Complexité temporelle des algorithmes », « O ». Le temps de fonctionnement de la recherche linéaire dans le pire des cas est égal au nième nombre d’éléments du tableau, écrivons cela en notation « O » – Sur). Ensuite, nous devons expliquer que pour tout algorithme connu, il existe trois indicateurs de performance : temps d’exécution dans le meilleur des cas, le pire des cas et la moyenne. Par exemple, l’adresse mail « demensdeum@gmail.com » est dans le premier index du tableau, elle sera alors trouvée dans la première étape de l’algorithme, il s’ensuit que le temps d’exécution est au mieux – O(1); et si à la fin de la liste, alors c’est le pire des cas – O(n)

Mais qu’en est-il des détails de la mise en œuvre logicielle et des performances matérielles ? Ils devraient influencer Big O ? Maintenant, respirez et imaginez que le calcul de la complexité temporelle soit calculé pour une machine idéale abstraite, dans laquelle il n’y a que cet algorithme et rien d’autre.
Algorithme
Ok, il s’avère que la recherche linéaire est assez lente, essayons d’utiliser la recherche binaire. Pour commencer, il convient de préciser que nous ne travaillerons pas avec des données binaires ; ce nom a été donné à cette méthode en raison des particularités de son travail. Initialement, nous trions le tableau en ordre lexicographique, puis l’algorithme prend la plage de l’ensemble du tableau, obtient l’élément central de la plage, le compare lexicographiquement, et en fonction du résultat de la comparaison, décide quelle plage utiliser pour poursuivre la recherche – la moitié supérieure du courant ou la moitié inférieure. Autrement dit, à chaque étape de recherche, une décision est prise parmi deux options possibles : logique binaire. Cette étape est répétée jusqu’à ce que le mot soit trouvé ou non (l’intersection des indices inférieur et supérieur de la plage se produit).
Performances de cet algorithme – le meilleur des cas est lorsqu’un élément est immédiatement trouvé au milieu du tableau O(1), le pire des cas d’énumération est O(log n)
Pièges
Lors de l’implémentation de la recherche binaire, j’ai non seulement rencontré le problème intéressant du manque de standardisation de la comparaison lexicographique dans les bibliothèques de langages de programmation, mais j’ai même découvert l’absence d’un standard unifié pour l’implémentation localeCompare dans JavaScript. La norme ECMAScript permet différentes implémentations de cette fonction, c’est pourquoi lors du tri à l’aide de localeCompare, des résultats complètement différents peuvent être observés sur différents moteurs JavaScript.
Par conséquent, pour que l’algorithme fonctionne correctement, il faut trier et utiliser uniquement le même algorithme de comparaison lexicographique, sinon rien ne fonctionnera. Co-mais si, par exemple, vous essayez de trier un tableau dans Scala et d’effectuer une recherche à l’aide de nodejs, sans implémenter votre propre tri/tri d’une implémentation, alors rien ne vous attend sauf une déception humaine.
Sources
Qu’est-ce que la comparaison lexicographique et que représente-t-elle ?
Почему для вычисления сложности алгоритмов используется log N вместо lb N?
Двоичный поиск
Знай сложности алгоритмов
https://stackoverflow.com/questions/52941016/sorting-in-localecompare-in-javascript
Code source
https://gitlab.com/demensdeum/algorithms
Façade à motifs

La façade fait référence aux modèles de conception structurelle. Il fournit une interface unique qui permet de travailler avec des systèmes complexes, permettant aux clients de ne pas avoir de détails d’implémentation sur ces systèmes, simplifiant ainsi leur code et implémentant un couplage lâche entre les clients et les systèmes de niveau inférieur. GoF a un bon exemple de façade – un compilateur de langage de programmation qui offre à différents clients poursuivant différents objectifs la possibilité d’assembler du code via une interface de façade de compilateur unique.
Sources
https://refactoring.guru/ru/design-patterns/facade
https://www.amazon.com/Design-Patterns-Elements-Reusable-Object-Oriented/dp/0201633612
