Si vous souhaitiez utiliser des réseaux de neurones pour vous aider à écrire du code (appelé codage Vibe) et que vous disposez d’un ordinateur assez puissant, par exemple avec une carte vidéo Nvidia RTX, alors vous pouvez déployer l’ensemble de l’environnement absolument gratuitement sur votre machine. Cela résout les problèmes liés aux abonnements payants et vous permet de travailler en toute sécurité avec des projets sous NDA, puisque votre code n’est envoyé nulle part. Dans cet article, je vais décrire comment assembler un bundle local de LM Studio, VS Code et l’extension Continue.
Outils pour le codage Vibe local
Pour un travail confortable, nous avons besoin de trois composants principaux :
– LM Studio : une application pratique pour télécharger et exécuter des LLM locaux. Il prend en charge toute la complexité du travail avec les modèles GGUF et met en place un serveur local compatible avec l’API OpenAI.
– VS Code : un éditeur de code populaire et familier.
– Continuer : extension pour VS Code qui intègre les réseaux de neurones directement dans l’environnement de travail. Vous permet de discuter, de mettre en évidence le code pour la refactorisation et de prendre en charge la saisie semi-automatique.
Exigences matérielles
Les modèles de langage local sont gourmands en mémoire :
– Carte vidéo (GPU) : Nvidia avec 8 Go de VRAM ou plus (pour un travail confortable avec des modèles avec 7 à 8 milliards de paramètres). Les modèles plus lourds nécessiteront 16 Go de VRAM.
– Espace disque : environ 500 Go pour stocker les différents modèles téléchargés.
Configurer le lien
Le processus de configuration est assez simple et ne nécessite pas de manipulations complexes dans le terminal :
1. Téléchargez et installez LM Studio. Utilisez la recherche intégrée pour trouver un modèle léger tel que Qwen Coder ou gemma3:12b.
2. Dans LM Studio, accédez à l’onglet Serveur local et cliquez sur Démarrer le serveur. Par défaut, il démarrera sur `http://localhost:1234/v1`.
3. Ouvrez VS Code et installez l’extension Continuer à partir du magasin de plugins.
4. Ouvrez le fichier de configuration Continue et ajoutez un nouveau modèle, en spécifiant le fournisseur `openai` et l’adresse de votre serveur local depuis LM Studio.
Vous pouvez ensuite communiquer avec votre LLM local directement dans la barre latérale Continuer, poser des questions sur votre code et générer de nouveaux composants.
Pourquoi est-ce que ça marche ?
Comme je l’ai écrit plus tôt, les LLM réussissent mieux avec une structure plate et du code WET (Write Everything Twice). Les modèles de paramètres locaux peuvent être inférieurs aux géants comme GPT-4 lorsqu’il s’agit de concevoir des architectures complexes, mais ils sont plus que capables de générer du code passe-partout, de refactoriser des fonctions simples et de réaliser un prototypage rapide.
De plus, grâce au codage Vibe local, votre code ne quitte jamais la machine. Cela rend cette combinaison idéale pour le développement d’entreprise et le travail avec des données sensibles.
Sortie
Les réseaux de neurones locaux ne sont pas capables de remplacer complètement un programmeur ou de concevoir un système complexe. Cependant, la combinaison de LM Studio + VS Code + Continue offre une indépendance par rapport aux services cloud et préserve la confidentialité. Il s’agit d’un outil auxiliaire entièrement fonctionnel pour les tâches de routine, si vous êtes prêt à supporter les limitations des petits modèles et à contrôler indépendamment l’architecture du projet.
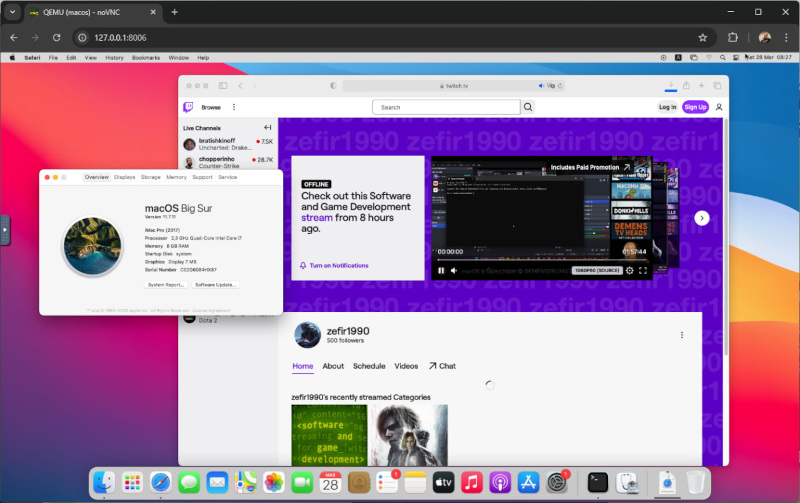
Il est possible d’exécuter macOS dans Docker, malgré les objections de ceux qui disent que c’est impossible, et apparemment macOS dispose d’une sorte de système de protection qui peut résister à cela.
Certaines des méthodes classiques d’exécution de macOS sur des machines PC ont été historiquement :
*Hackintosh
* Virtualisation, par exemple à l’aide de VMWare
Hackintosh suppose la présence d’un matériel similaire ou très proche du Mac d’origine. La virtualisation impose certaines exigences en matière de matériel, mais généralement pas aussi strictes que dans le cas de Hackintosh. Cependant, dans le cas de la virtualisation, il existe des problèmes de performances, car macOS n’est pas optimisé pour travailler dans un environnement virtuel.
Récemment, il est devenu possible d’exécuter macOS dans Docker. Ceci est rendu possible par le projet Docker-OSX, qui fournit des images macOS prêtes à l’emploi à exécuter sur Docker. Il convient de noter que Docker-OSX n’est pas un projet Apple officiel et n’est pas pris en charge par celui-ci. Cependant, il vous permet d’exécuter macOS sur Docker et de l’utiliser pour développer et tester des applications.
Cependant, je n’ai jamais pu le lancer complètement ; après le chargement dans Recovery OS, mon clavier et ma souris sont tout simplement tombés et je n’ai pas pu continuer l’installation. En même temps, dans le premier menu de démarrage, le clavier fonctionne. Le fait est peut-être que ce projet n’est plus aussi activement pris en charge et qu’il existe des problèmes spécifiques lors de l’exécution sous Windows 11 + WSL2 + Ubuntu.
Vous permet d’exécuter macOS dans Docker, l’interface fonctionne via le navigateur via le transfert VNC (?). Après le démarrage, macOS est disponible sur http://localhost:5900
J’ai réussi à exécuter ce projet et à installer macOS Big Sur (minute 2020) sur Windows 11 + WSL2 + Ubuntu, mais uniquement en modifiant le fichier de composition, à savoir :
VERSION : “11” est la version de macOS, dans ce cas Big Sur
RAM_SIZE : “8G” est la quantité de RAM allouée pour macOS
CPU_CORES : “4” est le nombre de cœurs de processeur alloués à macOS
Pour le moment, exécuter macOS tahoe (16) est également possible, mais il existe un certain nombre de problèmes que les développeurs du projet tentent de résoudre vaillamment.
Cette manière originale de lancer macOS vous permet de l’essayer sur votre matériel non Mac et, après avoir assez souffert, d’aller vous acheter un Mac. Cependant, cela peut être utile pour tester des logiciels sur des systèmes plus anciens et pour le développement général.
L’écosystème Swift se développe activement en dehors des plates-formes Apple, et il est aujourd’hui assez confortable d’y écrire sous Windows à l’aide du sous-système Windows pour Linux (WSL2). Il convient de noter que pour les assemblys sous Linux/WSL, une version allégée de Swift est disponible – sans frameworks propriétaires Apple (tels que SwiftUI, UIKit, AppKit, CoreData, CoreML, ARKit, SpriteKit et autres bibliothèques spécifiques à iOS/macOS), mais pour les utilitaires de console et le backend, cela est plus que suffisant. Dans cet article, nous allons parcourir étape par étape le processus de préparation de l’environnement et de construction du compilateur Swift à partir du code source dans WSL2 (en utilisant Ubuntu/Debian comme exemple).
Nous mettons à jour la liste des packages et le système lui-même :
sudo apt update && sudo apt upgrade -y
Installez les dépendances nécessaires pour le build :
Dans le dernier article, nous avons examiné la théorie du modèle Interpreter, appris ce qu’est un arbre AST et comment faire abstraction des expressions terminales et non terminales. Cette fois, éloignons-nous de la théorie et voyons comment ce modèle est appliqué dans des projets commerciaux sérieux que nous utilisons tous au quotidien !
Spoiler : Vous utilisez peut-être le modèle Interpreter en ce moment, simplement en lisant ce texte dans votre navigateur !
L’un des exemples les plus frappants et, peut-être, les plus importants de l’utilisation de ce modèle dans l’industrie est JavaScript. Le langage, qui a été créé à l’origine « sur le genou », fonctionne aujourd’hui sur des milliards d’appareils précisément grâce au concept d’interprétation.
10 jours qui ont changé Internet
L’histoire de JavaScript est pleine de légendes. En 1995, Brendan Eich, alors qu’il travaillait chez Netscape Communications, s’est vu confier la tâche de créer un langage de script simple pouvant s’exécuter directement dans un navigateur (Netscape Navigator) pour rendre les pages Web interactives. La direction voulait quelque chose avec une syntaxe similaire à Java alors très populaire, mais destiné non pas aux ingénieurs professionnels, mais aux concepteurs Web.
Eich n’a eu que 10 jours pour écrire le premier prototype du langage, qui s’appelait alors Mocha (puis LiveScript, et seulement ensuite JavaScript pour des raisons marketing). Cette ruée n’était pas fortuite : Microsoft était sur ses talons, qui préparait en même temps activement son propre langage de script VBScript à intégrer dans le navigateur Internet Explorer. Netscape devait de toute urgence publier sa réponse afin de ne pas perdre dans la guerre imminente des navigateurs.
Nous n’avions tout simplement pas le temps d’écrire un compilateur complexe en code machine. La solution évidente et la plus rapide pour Eich était l’architecture du classique Interpreter.
Le premier interprète (SpiderMonkey) fonctionnait comme ceci :
Il lit le code source du texte du script à partir de la page.
L’analyseur lexical a divisé le texte en jetons.
L’analyseur a construit un arbre de syntaxe abstraite (AST). En termes de modèle Interpreter, cet arbre se composait d’expressions terminales (chaînes, nombres comme 42) et de non-terminaux (appels de fonction, instructions comme If, While).
Ensuite, la machine virtuelle a « parcouru » cet arbre étape par étape, exécutant les instructions qui y sont intégrées à chaque nœud (en appelant une méthode similaire à Interpret()).
Contexte et objets
Vous vous souvenez de l’objet Context que nous avons dû passer à la méthode Interpret(Context context) dans l’implémentation classique ? L’interpréteur en a besoin pour stocker l’état actuel de la mémoire.
Dans le cas de JavaScript, le rôle de ce contexte au niveau supérieur est joué par un Objet global (par exemple, une fenêtre dans un navigateur). Lorsque votre nœud AST essaie, par exemple, d’écrire du texte à l’écran via document.write(“Hello”), l’interpréteur accède à son contexte (l’objet document) et appelle l’API interne du navigateur souhaitée.
C’est grâce à l’interpréteur que JavaScript est capable d’interagir si facilement avec le DOM (Document Object Model) – ce ne sont que des objets dans un contexte accessibles par les nœuds de l’arborescence.
Évolution de l’interpréteur : Compilation JIT
Historiquement, JS dans les navigateurs est longtemps resté un « pur » interprète. Et cela avait un gros inconvénient : une vitesse lente. L’analyse de l’arborescence et la traversée lente de chaque nœud à chaque fois que le script était exécuté ralentissaient les applications Web complexes.
Avec l’avènement du moteur V8 de Google (intégré à Chrome) en 2008, une révolution s’est produite. Les ingénieurs ont réalisé qu’un seul interprète ne suffisait pas pour le Web moderne. Le moteur est devenu plus complexe : il construit toujours l’arborescence AST, mais utilise désormais la compilation JIT (Just-In-Time).
Les moteurs JS modernes (V8, SpiderMonkey) fonctionnent comme un pipeline complexe :
L’interpréteur de base rapide et stupide commence à exécuter votre code JS instantanément, sans même attendre sa compilation (le modèle classique fonctionne toujours ici).
En parallèle, le moteur surveille les sections de code « chaudes » (boucles ou fonctions appelées des milliers de fois).
Ces sections sont compilées par le compilateur JIT directement dans un code machine optimisé, en contournant l’interpréteur lent.
C’est cette combinaison du démarrage instantané de l’interpréteur et de la puissance de calcul de la compilation qui a permis à JavaScript de conquérir le monde, devenant le langage des serveurs (Node.js) et des applications mobiles (React Native).
Interprète dans l’industrie du jeu vidéo
Malgré la domination du C++ dans l’informatique lourde, le modèle Interpreter est une norme industrielle en matière de développement de jeux pour la création de logique de jeu. Pour quoi? Pour que les concepteurs de jeux puissent créer des jeux sans risquer de « laisser tomber » le moteur ou sans avoir besoin de le recompiler constamment.
Un excellent exemple historique est UnrealScript – le langage dans lequel la logique des jeux Unreal Tournament et Gears of War a été écrite dans Unreal Engine 1, 2 et 3. Le texte a été compilé en bytecode compact et abstrait, qui a ensuite été (interprété) étape par étape par la machine virtuelle du moteur.
Scripts de graphiques visuels (Blueprints)
Aujourd’hui, le texte a été remplacé par une programmation visuelle – le système Blueprints dans Unreal Engine 4 et 5.
Si vous avez déjà ouvert un Blueprint dans Unreal Engine, vous avez vu de nombreux nœuds connectés par des fils. Sur le plan architectural, l’ensemble du graphique Blueprints est un immense arbre de syntaxe abstraite (AST) dessiné à l’écran :
Expressions terminales : Nœuds constants. Par exemple, un nœud qui stocke simplement le nombre 42 ou une chaîne. Ils renvoient une valeur spécifique lorsqu’ils sont interprétés.
Expressions non-terminales : nœuds de calcul (Ajouter) ou nœuds de contrôle de flux (Branche). Ils ont des entrées d’arguments, que l’interpréteur évalue d’abord de manière récursive avant de produire le résultat sous forme de broche de sortie.
Et le rôle de contexte ici est joué par la mémoire d’une instance d’un objet de jeu spécifique (acteur). La machine d’interprétation « parcourt » ce graphique en toute sécurité, demandant des données et effectuant des transitions.
Où d’autre l’interprète est-il utilisé ?
Le modèle d’interpréteur peut être trouvé dans presque tous les systèmes complexes où des instructions dynamiques doivent être exécutées. Voici quelques exemples de logiciels commerciaux :
Langages de programmation interprétés (Python, Ruby, PHP). L’ensemble de leur exécution est basé sur le modèle classique. Par exemple, l’implémentation de référence CPython analyse d’abord votre script .py dans un AST, le compile en bytecode, puis une énorme machine virtuelle (boucle de calcul) interprète ce bytecode étape par étape.
Machine virtuelle Java (JVM). Initialement, le code Java n’est pas compilé en instructions machine, mais en bytecode. Lorsque vous exécutez l’application, la JVM agit comme un interprète (mais avec une compilation JIT agressive, tout comme dans la V8).
Bases de données et SQL Lorsque vous émettez une requête SQL (utilisateurs SELECT * FROM) dans PostgreSQL ou MySQL, le moteur de base de données agit comme un interpréteur. Il effectue une analyse lexicale, construit un arbre de requêtes AST, génère un plan d’exécution, puis « interprète » littéralement ce plan en itérant sur les lignes des tables.
Expressions régulières (RegEx). Tout moteur d’expression régulière analyse en interne un modèle de chaîne (par exemple, ^\d{3}-\d{2}$) dans un graphe d’état (NFA/DFA Automata), que l’interpréteur interne traverse ensuite, en faisant correspondre chaque caractère d’entrée avec les sommets de ce graphe.
Unity Shader Graph / Unreal Material Editor – interprète les nœuds visuels dans un code de shader modulaire (GLSL/HLSL).
Nœuds géométriques Blender : interprètez les opérations mathématiques et géométriques pour générer de manière procédurale des modèles 3D en temps réel.
Total
Le modèle Interpreter a depuis longtemps dépassé le cadre de « l’écriture de votre propre calculatrice ». Il s’agit de la norme industrielle la plus puissante. Des moteurs JavaScript qui exécutent chaque jour des gigaoctets de code dans les coulisses des navigateurs, aux concepteurs de jeux qui vous permettent de créer une logique complexe sans connaissance du C++, les interpréteurs restent l’un des concepts architecturaux les plus importants du développement informatique moderne.
Le diagramme de blocs est un outil visuel qui aide à transformer un algorithme complexe en une séquence d’actions compréhensible et structurée. De la programmation à la gestion des processus métier, ils servent de langage universel pour la visualisation, l’analyse et l’optimisation des systèmes les plus complexes.
Imaginez une carte où au lieu des routes est logique et au lieu des villes – des actions. Il s’agit d’un schéma de bloc – un outil indispensable pour la navigation dans les processus les plus déroutants.
Exemple 1: Schéma de lancement de jeu simplifié
Pour comprendre le principe du travail, présentons un schéma de lancement de jeu simple.
Ce schéma montre le script parfait lorsque tout se produit sans échecs. Mais dans la vraie vie, tout est beaucoup plus compliqué.
Exemple 2: Schéma élargi pour démarrer le jeu avec le chargement des données
Les jeux modernes nécessitent souvent une connexion Internet pour télécharger les données des utilisateurs, l’enregistrement ou les paramètres. Ajoutons ces étapes à notre schéma.
Ce schéma est déjà plus réaliste, mais que se passera-t-il en cas de problème?
comment était-ce: un jeu qui “s’est cassé” avec la perte d’Internet
Au début du projet, les développeurs n’ont pas pu prendre en compte tous les scénarios possibles. Par exemple, ils se sont concentrés sur la logique principale du jeu et ne pensaient pas ce qui se passerait si le joueur avait une connexion Internet.
Dans une telle situation, le schéma de bloc de leur code ressemblerait à ceci:
Dans ce cas, au lieu d’émettre une erreur ou de fermer correctement, le jeu s’est figé au stade de l’attente des données qu’elle n’a pas reçues en raison de l’absence de connexion. Cela a conduit à “l’écran noir” et au gel de l’application.
comment il est devenu: correction sur les plaintes des utilisateurs
Après les plaintes de nombreux utilisateurs concernant le plan de volant, l’équipe du développeur s’est rendu compte que nous devions corriger l’erreur. Ils ont apporté des modifications au code en ajoutant une unité de traitement d’erreur qui permet à l’application de répondre correctement au manque de connexion.
C’est à quoi ressemble le diagramme de bloc corrigé, où les deux scénarios sont pris en compte:
Grâce à cette approche, le jeu informe désormais correctement l’utilisateur du problème, et dans certains cas, il peut même passer en mode hors ligne, vous permettant de continuer le jeu. Ceci est un bon exemple de la raison pour laquelle les diagrammes de blocs sont si importants : ils font que le développeur réfléchit non seulement à la façon idéale d’exécution, mais aussi à toutes les échecs possibles, ce qui rend le produit final beaucoup plus stable et fiable.
comportement incertain
La suspension et les erreurs ne sont qu’un exemple de comportement imprévisible du programme. En programmation, il existe un concept de comportement incertain (comportement non défini) – Il s’agit d’une situation où la norme du langage ne décrit pas comment le programme devrait se comporter dans un certain cas.
Cela peut conduire à n’importe quoi: des «ordures» aléatoires dans le retrait de l’échec du programme ou même de la vulnérabilité de sécurité sérieuse. Le comportement indéfini se produit souvent lorsque vous travaillez avec la mémoire, par exemple, avec des lignes dans la langue de C.
Un exemple de la langue C:
Imaginez que le développeur a copié la ligne dans le tampon, mais a oublié d’ajouter à la fin le symbole zéro (`\ 0`) , qui marque la fin de la ligne.
Résultat attendu: “Bonjour” Le résultat réel est imprévisible.
Pourquoi cela se produit-il? La fonction `printf` avec le spécificateur ‘% S` s’attend à ce que la ligne se termine par un symbole zéro. S’il ne l’est pas, elle continuera à lire la mémoire en dehors du tampon mis en évidence.
Voici le schéma de bloc de ce processus avec deux résultats possibles:
Ceci est un exemple clair de la raison pour laquelle les diagrammes de bloc sont si importants: ils font réfléchir le développeur non seulement à la manière idéale d’exécution, mais aussi à tous les échecs possibles, y compris des problèmes de niveau de bas niveau, ce qui rend le produit final beaucoup plus stable et fiable.
Dans le monde du développement des interfaces, il existe un concept commun – “Pixel parfait dans le lodge” . Cela implique la reproduction la plus précise de la machine de conception au plus petit pixel. Pendant longtemps, c’était une étalon-or, en particulier à l’ère d’une conception Web classique. Cependant, avec l’arrivée du mile déclarant et la croissance rapide de la variété des appareils, le principe de “Pixel parfait” devient plus éphémère. Essayons de comprendre pourquoi.
Imperial Wysiwyg vs code déclaratif: Quelle est la différence?
Traditionnellement, de nombreuses interfaces, en particulier de bureau, ont été créées en utilisant des approches impératives ou Wysiwyg (ce que vous voyez est ce que vous obtenez) des éditeurs. Dans de tels outils, le concepteur ou le développeur manipule directement avec des éléments, en les plaçant sur toile avec une précision au pixel. Il est similaire à travailler avec un éditeur graphique – vous voyez à quoi ressemble votre élément, et vous pouvez certainement le positionner. Dans ce cas, la réalisation de “Pixel Perfect” était un objectif très réel.
Cependant, le développement moderne est de plus en plus basé sur miles déclaratifs . Cela signifie que vous ne dites pas à l’ordinateur de “mettre ce bouton ici”, mais décrivez ce que vous voulez obtenir. Par exemple, au lieu d’indiquer les coordonnées spécifiques de l’élément, vous décrivez ses propriétés: “Ce bouton doit être rouge, avoir des indentations 16px de tous les côtés et être au centre du conteneur.” Freimvorki comme React, Vue, Swiftui ou Jetpack composent simplement ce principe.
Pourquoi “Pixel Perfect” ne fonctionne pas avec un mile déclaratif pour de nombreux appareils
Imaginez que vous créez une application qui devrait être tout aussi bonne sur l’iPhone 15 Pro Max, Samsung Galaxy Fold, iPad Pro et une résolution 4K. Chacun de ces appareils a une résolution d’écran différente, une densité de pixels, des parties et des tailles physiques.
Lorsque vous utilisez l’approche déclarative, le système lui-même décide comment afficher votre interface décrite sur un appareil particulier, en tenant compte de tous ses paramètres. Vous définissez les règles et les dépendances, pas les coordonnées sévères.
* Adaptabilité et réactivité: L’objectif principal des miles déclaratifs est de créer des interfaces adaptatives et réactives . Cela signifie que votre interface doit s’adapter automatiquement à la taille et à l’orientation de l’écran sans se casser et maintenir la lisibilité. Si nous cherchions à «Pixel parfait» sur chaque appareil, nous devions créer d’innombrables options pour la même interface, ce qui nivellera complètement les avantages de l’approche déclarative.
* densité de pixels (dpi / ppi): Les appareils ont une densité de pixels différente. Le même élément avec la taille de 100 pixels “virtuels” sur un appareil à haute densité sera beaucoup plus petit que sur un dispositif à faible densité, si vous ne prenez pas en compte la mise à l’échelle. Les cadres déclaratifs sont résumés par des pixels physiques, en travaillant avec des unités logiques.
* Contenu dynamique: Le contenu dans les applications modernes est souvent dynamique – son volume et sa structure peuvent varier. Si nous détendions durement les pixels, tout changement de texte ou d’image entraînerait “l’effondrement” de la mise en page.
* diverses plates-formes: En plus de la variété des appareils, il existe différents systèmes d’exploitation (iOS, Android, Web, Desktop). Chaque plate-forme a sa propre conception, ses commandes standard et ses polices. Une tentative de faire une interface parfaite absolument identique et parfaite sur toutes les plates-formes conduirait à un type non naturel et à une mauvaise expérience utilisateur.
Les anciennes approches n’ont pas disparu, mais ont évolué
Il est important de comprendre que l’approche des interfaces n’est pas un choix binaire entre “impératif” et “déclaratif”. Historiquement, pour chaque plate-forme, il y avait ses propres outils et approches de la création d’interfaces.
* Fichiers d’interface natif: Pour iOS, c’était XIB / storyboards, pour les fichiers de marquage Android-XML. Ces fichiers sont une disposition WYSIWYG parfaite avec pixel, qui est ensuite affichée à la radio comme dans l’éditeur. Cette approche n’a disparu nulle part, elle continue de se développer, s’intégrant à des cadres déclaratifs modernes. Par exemple, Swiftui dans Apple et Jetpack composent dans Android se déroulent sur le chemin d’un code purement déclaratif, mais en même temps, a conservé l’opportunité d’utiliser une disposition classique.
* Solutions hybrides: Souvent dans les projets réels, une combinaison d’approches est utilisée. Par exemple, la structure de base de l’application peut être mise en œuvre de manière déclarative et, pour un positionnement précis des éléments, des méthodes impératives de niveau inférieur peuvent être utilisées ou des composants natifs développés en tenant compte des spécificités de la plate-forme.
du monolithe à l’adaptabilité: comment l’évolution des appareils a formé un mile déclaratif
Le monde des interfaces numériques a subi d’énormes changements au cours des dernières décennies. Des ordinateurs stationnaires avec des permis fixes, nous sommes arrivés à l’ère de la croissance exponentielle de la variété des appareils utilisateur . Aujourd’hui, nos applications devraient fonctionner aussi bien sur:
* Smartphones de tous les facteurs de forme et tailles d’écran.
* tablettes avec leurs modes d’orientation uniques et un écran séparé.
* ordinateurs portables et ordinateurs de bureau avec divers permis de moniteurs.
* TVS et centres de médias , contrôlés à distance. Il est à noter que même pour les téléviseurs, dont les remarques peuvent être simples en tant que Apple TV Remote avec un minimum de boutons, ou vice versa, surchargée de nombreuses fonctions, les exigences modernes pour les interfaces sont telles que le code ne doit pas nécessiter une adaptation spécifique pour ces caractéristiques d’entrée. L’interface doit fonctionner “comme si elle-même”, sans une description supplémentaire de ce que “comment” interagir avec une télécommande spécifique.
* montres intelligentes et appareils portables avec des écrans minimalistes.
* Casques de réalité virtuelle (VR) , nécessitant une approche complètement nouvelle d’une interface spatiale.
* Dispositifs de réalité augmentés (AR) , appliquant des informations sur le monde réel.
* Informations automobiles et systèmes de divertissement .
* Et même appareils ménagers : des réfrigérateurs avec des écrans sensoriels et des machines à laver avec des écrans interactifs aux fours et systèmes intelligents de la maison intelligente.
Chacun de ces appareils a ses propres fonctionnalités uniques: dimensions physiques, rapport des parties, densité de pixels, méthodes d’entrée (écran tactile, souris, contrôleurs, gestes, commandes vocales) et, surtout, les subtilités de l’environnement utilisateur . Par exemple, un VR Shlesh nécessite une immersion profonde, et un travail rapide et intuitif pour les smartphones en déplacement, tandis que l’interface du réfrigérateur doit être aussi simple et grande pour une navigation rapide.
Approche classique: le fardeau de soutenir les interfaces individuelles
À l’ère de la domination des ordinateurs de bureau et des premiers appareils mobiles, l’activité habituelle était la création et la prise en charge de de fichiers d’interface individuels ou même un code d’interface complètement séparé pour chaque plate-forme .
* Développement sous iOS nécessite souvent l’utilisation de storyboards ou de fichiers XIB dans Xcode, en écrivant du code sur objectif-c ou Swift.
* Pour Android Les fichiers de marquage XML et le code sur Java ou Kotlin ont été créés.
* Les interfaces Web activées sur HTML / CSS / JavaScript.
* Pour les applications C ++ sur diverses plates-formes de bureau, leurs cadres et outils spécifiques ont été utilisés:
* Dans Windows il s’agissait de MFC (classes Microsoft Foundation), de l’API WIN32 avec des éléments de dessin manuel ou à l’aide de fichiers de ressources pour les fenêtres de dialogue et les éléments de contrôle.
* Le cacao (objectif-c / swift) ou l’ancienne API carbone pour le contrôle direct de l’interface graphique a été utilisé dans macOS .
* Dans Systems de type Linux / Unix , des bibliothèques comme GTK + ou QT ont souvent été utilisées, ce qui a fourni leur ensemble de widgets et de mécanismes pour créer des interfaces, souvent via des fichiers de marquage de type XML (par exemple, des fichiers .UI dans le concepteur QT) ou une création de logiciels directs d’éléments.
Cette approche a assuré un contrôle maximal sur chaque plate-forme, vous permettant de prendre en compte toutes ses caractéristiques spécifiques et ses éléments indigènes. Cependant, il a eu un énorme inconvénient: duplication des efforts et des coûts énormes de soutien . Le moindre changement de conception ou de fonctionnalité a nécessité l’introduction d’un droit à plusieurs bases de code indépendantes, en fait. Cela s’est transformé en un vrai cauchemar pour les équipes de développeurs, ralentissant la sortie des nouvelles fonctions et augmentant la probabilité d’erreurs.
Miles déclaratifs: une seule langue pour la diversité
C’est en réponse à cette complication rapide que les miles déclaratifs sont apparus comme le paradigme dominant. Les framws comme react, vue, swiftui, jetpack compose et d’autres ne sont pas seulement une nouvelle façon d’écrire du code, mais un changement fondamental dans la pensée.
L’idée principale de l’approche déclarative : Au lieu de dire que le système «comment» de dessiner chaque élément (impératif), nous décrivons «ce que« nous voulons voir (déclaratif). Nous définissons les propriétés et l’état de l’interface, et le cadre décide comment l’afficher au mieux sur un appareil particulier.
Cela est devenu possible grâce aux principaux avantages suivants:
1. L’abstraction des détails de la plate-forme: Les Fraimvorki déclaratifs sont spécialement conçus pour oublier les détails de bas niveau de chaque plate-forme. Le développeur décrit les composants et leurs relations à un niveau d’abstraction plus élevé, en utilisant un seul code transféré.
2. Adaptation et réactivité automatique: Freimvorki assumez la responsabilité de la mise à l’échelle automatique, de la mise en page et de l’adaptation des éléments en différentes tailles d’écrans, de densité de pixels et de méthodes d’entrée. Ceci est réalisé grâce à l’utilisation de systèmes de disposition flexibles, tels que Flexbox ou Grid, et des concepts similaires aux “pixels logiques” ou “DP”.
3. Cohérence de l’expérience utilisateur: Malgré les différences externes, l’approche déclarative vous permet de maintenir une seule logique de comportement et d’interaction dans toute la famille des appareils. Cela simplifie le processus de test et offre une expérience utilisateur plus prévisible.
4. Accélération du développement et réduction des coûts: Avec le même code capable de travailler sur de nombreuses plateformes, est considérablement réduit par le temps et le coût de développement et de soutien . Les équipes peuvent se concentrer sur la fonctionnalité et la conception, et non sur la réécriture répétée de la même interface.
5. Prépité pour l’avenir: La capacité de résumer des spécificités des appareils actuels rend le code déclaratif plus plus résistant à l’émergence de nouveaux types de dispositifs et de facteurs de forme . Freimvorki peut être mis à jour pour prendre en charge les nouvelles technologies, et votre code déjà écrit recevra ce support relativement transparent.
Conclusion
Le mile déclaratif n’est pas seulement une tendance de la mode, mais l’étape évolutive nécessaire causée par le développement rapide des appareils utilisateur, y compris la sphère l’Internet des objets (IoT) et les appareils de ménage intelligents. Il permet aux développeurs et aux concepteurs de créer des interfaces complexes, adaptatives et uniformes, sans se noyer dans des implémentations spécifiques sans fin pour chaque plate-forme. La transition du contrôle impératif de chaque pixel à la description déclarative de l’état souhaité est une reconnaissance que dans le monde des futures interfaces devrait être flexible, transféré et intuitif quel que soit l’écran qu’ils sont affichés.
Les programmeurs, les concepteurs et les utilisateurs doivent apprendre à vivre dans ce nouveau monde. Les détails supplémentaires du Pixel Perfect, conçu pour un appareil ou une résolution particulière, conduisent à des coûts de temps inutiles pour le développement et le support. De plus, de telles dispositions sévères peuvent tout simplement ne pas fonctionner sur des appareils avec des interfaces non standard, telles que les téléviseurs d’entrée limités, les changements VR et AR, ainsi que d’autres appareils du futur, que nous ne connaissons même pas aujourd’hui. Flexibilité et adaptabilité – Ce sont les clés de la création d’interfaces réussies dans le monde moderne.
Avec le développement de modèles de grandes langues (LLM), tels que Chatgpt, de plus en plus de développeurs les utilisent pour générer du code, une architecture de conception et une intégration accélérée. Cependant, avec une application pratique, elle devient perceptible: les principes classiques de l’architecture – solide, sec, propre – s’entendent mal avec les particularités de la codgendation LLM.
Cela ne signifie pas que les principes sont obsolètes – au contraire, ils fonctionnent parfaitement avec le développement manuel. Mais avec LLM, l’approche doit être adaptée.
Pourquoi LLM ne peut pas faire face aux principes architecturaux
Encapsulation
L’incapsulation nécessite de comprendre les frontières entre parties du système, des connaissances sur les intentions du développeur, ainsi que des restrictions d’accès strictes. LLM simplifie souvent la structure, rend les champs publics sans raison ou dupliquent la mise en œuvre. Cela rend le code plus vulnérable aux erreurs et viole les limites architecturales.
Résumé et interfaces
Les modèles de conception, tels qu’une usine abstraite ou une stratégie, nécessitent une vision holistique du système et la compréhension de sa dynamique. Les modèles peuvent créer une interface sans objectif clair sans assurer sa mise en œuvre ou violer la connexion entre les couches. Le résultat est une architecture excessive ou non fonctionnelle.
sec (donolt répétez-vous)
LLM ne cherchez pas à minimiser le code de répétition – au contraire, il leur est plus facile de dupliquer des blocs que de faire une logique générale. Bien qu’ils puissent offrir une refactorisation sur demande, par défaut, les modèles ont tendance à générer des fragments «auto-suffisants», même si cela conduit à une redondance.
Architecture propre
Clean implique une hiérarchie stricte, une indépendance des cadres, une dépendance dirigée et une connectivité minimale entre les couches. La génération d’une telle structure nécessite une compréhension globale du système – et du travail LLM au niveau de la probabilité de mots, et non de l’intégrité architecturale. Par conséquent, le code est mitigé, avec violation des directions de dépendance et une division simplifiée en niveaux.
ce qui fonctionne mieux lorsque vous travaillez avec LLM
Mouillé au lieu de sec
L’approche humide (écrivez tout deux fois) est plus pratique pour travailler avec LLM. La duplication du code ne nécessite pas de contexte du modèle de rétention, ce qui signifie que le résultat est prévisible et est plus facile à corriger correctement. Il réduit également la probabilité de connexions et de bogues non évidents.
De plus, la duplication aide à compenser la mémoire courte du modèle: si un certain fragment de logique se trouve à plusieurs endroits, LLM est plus susceptible de le prendre en compte avec une génération plus approfondie. Cela simplifie l’accompagnement et augmente la résistance à “l’oubli”.
Structures simples au lieu de l’encapsulation
Éviter l’encapsulation complexe et s’appuyer sur la transmission directe des données entre les parties du code, vous pouvez considérablement simplifier à la fois la génération et le débogage. Cela est particulièrement vrai avec un développement itératif rapide ou une création de MVP.
Architecture simplifiée
Une structure simple et plate du projet avec une quantité minimale de dépendances et d’abstractions donne un résultat plus stable pendant la génération. Le modèle adapte un tel code plus facile et moins souvent viole les connexions attendues entre les composants.
Intégration du SDK – fiable manuellement
La plupart des modèles linguistiques sont formés sur des versions obsolètes de la documentation. Par conséquent, lors de la génération d’instructions pour l’installation du SDK, les erreurs apparaissent souvent: commandes obsolètes, paramètres non pertinents ou liens vers des ressources inaccessibles. La pratique montre: il est préférable d’utiliser la documentation officielle et le réglage manuel, laissant LLM un rôle auxiliaire – par exemple, générer un code de modèle ou une adaptation des configurations.
Pourquoi les principes fonctionnent-ils toujours – mais avec le développement manuel
Il est important de comprendre que les difficultés de solides, sèches et propres concernent la codhégénération par LLM. Lorsque le développeur écrit le code manuellement, ces principes continuent de démontrer leur valeur: ils réduisent la connectivité, simplifient le soutien, augmentent la lisibilité et la flexibilité du projet.
Cela est dû au fait que la pensée humaine est sujette à la généralisation. Nous recherchons des modèles, nous apportons une logique répétitive dans des entités individuelles, créons des modèles. Ce comportement a probablement des racines évolutives: la réduction de la quantité d’informations permet d’économiser des ressources cognitives.
LLM agit différemment: ils ne ressentent pas de charges du volume de données et ne visent pas d’économies. Au contraire, il leur est plus facile de travailler avec des informations fragmentées en double que de construire et de maintenir des abstractions complexes. C’est pourquoi il leur est plus facile de faire face au code sans encapsulation, avec des structures répétitives et une gravité architecturale minimale.
Conclusion
Les modèles de grandes langues sont un outil utile en développement, en particulier dans les premiers stades ou lors de la création d’un code auxiliaire. Mais il est important de s’adapter à l’approche: pour simplifier l’architecture, limiter l’abstraction, éviter les dépendances complexes et ne pas compter sur eux lors de la configuration du SDK.
Les principes du solide, du sec et de la propreté sont toujours pertinents, mais ils donnent le meilleur effet entre les mains d’une personne. Lorsque vous travaillez avec LLM, il est raisonnable d’utiliser un style simplifié et pratique qui vous permet d’obtenir un code fiable et compréhensible qui est facile à finaliser manuellement. Et où LLM oublie – la duplication du code l’aide à se souvenir.
Dans cet article, je décrirai comment j’ai porté le moteur de jeu Surreal Engine vers WebAssembly.
Moteur surréaliste – ; un moteur de jeu qui implémente la plupart des fonctionnalités de l’Unreal Engine 1, des jeux célèbres sur ce moteur – Unreal Tournament 99, Unreal, Deus Ex, Undying. Il fait référence aux moteurs classiques qui fonctionnaient principalement dans un environnement d’exécution monothread.
Au départ, j’ai eu l’idée de me lancer dans un projet que je ne pouvais pas réaliser dans un délai raisonnable, montrant ainsi à mes abonnés Twitch qu’il y a des projets que même moi je ne peux pas réaliser. Lors de mon premier stream, j’ai soudainement réalisé que la tâche de porter Surreal Engine C++ vers WebAssembly à l’aide d’Emscripten était réalisable.
Le contrôle, comme dans l’original, s’effectue à l’aide des flèches du clavier. Ensuite, je prévois de l’adapter au contrôle mobile (tachi), en ajoutant un éclairage correct et d’autres fonctionnalités graphiques du rendu Unreal Tournament 99.
Par où commencer ?
La première chose que je veux dire est que n’importe quel projet peut être porté de C++ vers WebAssembly en utilisant Emscripten, la seule question est de savoir dans quelle mesure la fonctionnalité sera complète. Choisissez un projet dont les ports de bibliothèque sont déjà disponibles pour Emscripten ; dans le cas de Surreal Engine, vous avez beaucoup de chance, car le moteur utilise les bibliothèques SDL 2, OpenAL – ils sont tous deux portés sur Emscripten. Cependant, Vulkan est utilisé comme API graphique, qui n’est actuellement pas disponible pour HTML5, des travaux sont en cours pour implémenter WebGPU, mais il est également au stade de projet, et on ne sait pas non plus à quel point le port ultérieur de Vulkan vers WebGPU sera simple. , une fois qu’il est entièrement standardisé. Par conséquent, j’ai dû écrire mon propre rendu de base OpenGL-ES/WebGL pour Surreal Engine.
Construire le projet
Construire un système dans Surreal Engine – CMake, qui simplifie également le portage, car Emscripten fournit à ses constructeurs natifs – emcmake, emmake.
Le portage de Surreal Engine était basé sur le code de mon dernier jeu en WebGL/OpenGL ES et C++ appelé Death-Mask, de ce fait le développement était beaucoup plus simple, j’avais tous les indicateurs de build nécessaires avec moi et des exemples de code.
L’un des points les plus importants de CMakeLists.txt concerne les indicateurs de build pour Emscripten. Vous trouverez ci-dessous un exemple tiré du fichier de projet :
Ensuite, nous préparerons l’index .html , qui inclut le préchargeur du système de fichiers du projet. Pour télécharger sur le Web, j’ai utilisé Unreal Tournament Demo version 338. Comme vous pouvez le voir sur le fichier CMake, le dossier du jeu décompressé a été ajouté au répertoire de construction et lié en tant que fichier de préchargement pour Emscripten.
Modifications du code principal
Ensuite, il a fallu changer la boucle de jeu du jeu, vous ne pouvez pas exécuter une boucle sans fin, cela conduit au gel du navigateur, vous devez plutôt utiliser emscripten_set_main_loop, j’ai écrit à propos de cette fonctionnalité dans ma note de 2017 « < a href="https://demensdeum.com /blog/ru/2017/03/29/porting-sdl-c-game-to-html5-emscripten/" rel="noopener" target="_blank">Porter le jeu SDL C++ vers HTML5 (Emscripten)”
Nous modifions le code pour quitter la boucle while en if, puis nous affichons la classe principale du moteur de jeu, qui contient la boucle de jeu, dans la portée globale, et écrivons une fonction globale qui appellera l’étape de boucle de jeu à partir de l’objet global :
Après cela, vous devez vous assurer qu’il n’y a pas de threads d’arrière-plan dans l’application ; s’il y en a, préparez-vous à les réécrire pour une exécution monothread, ou utilisez la bibliothèque phtread dans Emscripten.
Le fil d’arrière-plan dans Surreal Engine est utilisé pour lire de la musique, les données proviennent du fil du moteur principal concernant la piste en cours, la nécessité de jouer de la musique ou son absence, puis le fil d’arrière-plan reçoit un nouvel état via un mutex et commence à jouer de la nouvelle musique. , ou le met en pause. Le flux d’arrière-plan est également utilisé pour mettre la musique en mémoire tampon pendant la lecture.
Mes tentatives de création de Surreal Engine pour Emscripten avec pthread ont échoué, car les ports SDL2 et OpenAL ont été construits sans le support de pthread, et je ne voulais pas les reconstruire pour le plaisir de la musique. Par conséquent, j’ai transféré la fonctionnalité du flux de musique de fond vers une exécution monothread à l’aide d’une boucle. En supprimant les appels pthread du code C++, j’ai déplacé la mise en mémoire tampon et la lecture de musique vers le thread principal, afin qu’il n’y ait pas de retard, j’ai augmenté la mémoire tampon de quelques secondes.
Ensuite, je décrirai des implémentations spécifiques des graphiques et du son.
Vulkan n’est pas pris en charge !
Oui, Vulkan n’est pas pris en charge en HTML5, bien que toutes les brochures marketing présentent le support multiplateforme et large plate-forme comme le principal avantage de Vulkan. Pour cette raison, j’ai dû écrire mon propre moteur de rendu graphique de base pour un type OpenGL simplifié – – ES, il est utilisé sur les appareils mobiles, parfois il ne contient pas les fonctionnalités à la mode de l’OpenGL moderne, mais il se porte très bien sur WebGL, ce qui est exactement ce qu’Emscripten implémente. L’écriture du rendu de tuiles de base, du rendu bsp, pour l’affichage GUI le plus simple et du rendu des modèles + cartes a été achevée en deux semaines. C’était peut-être la partie la plus difficile du projet. Il reste encore beaucoup de travail à faire pour implémenter toutes les fonctionnalités du rendu Surreal Engine, donc toute aide des lecteurs est la bienvenue sous forme de code et de demandes d’extraction.
OpenAL pris en charge !
La grande chance est que Surreal Engine utilise OpenAL pour la sortie audio. Après avoir écrit un simple hello world dans OpenAL et l’avoir assemblé dans WebAssembly à l’aide d’Emscripten, il m’est devenu clair à quel point tout était simple et j’ai décidé de porter le son.
Après plusieurs heures de débogage, il est devenu évident que l’implémentation OpenAL d’Emscripten avait plusieurs bugs, par exemple, lors de l’initialisation de la lecture du nombre de canaux mono, la méthode a renvoyé un nombre infini, et après avoir essayé d’initialiser un vecteur de taille infinie, C++ plante avec l’exception vector::length_error.
Nous avons réussi à contourner ce problème en codant en dur le nombre de canaux mono à 2 048 :
Surreal Engine ne prend actuellement pas en charge le jeu en ligne, jouer avec des robots est pris en charge, mais nous avons besoin de quelqu’un pour écrire l’IA pour ces robots. Théoriquement, vous pouvez implémenter un jeu en réseau sur WebAssembly/Emscripten à l’aide de Websockets.
Conclusion
En conclusion, je voudrais dire que le portage de Surreal Engine s’est avéré assez fluide grâce à l’utilisation de bibliothèques pour lesquelles il existe des ports Emscripten, ainsi que mon expérience passée dans l’implémentation d’un jeu en C++ pour WebAssembly. sur Emscripten. Vous trouverez ci-dessous des liens vers des sources de connaissances et des référentiels sur le sujet. M-M-M-MONSTER KILL !
De plus, si vous souhaitez aider le projet, de préférence avec le code de rendu WebGL/OpenGL ES, alors écrivez-moi dans Telegram : https://t.me/demenscave
J’ai récemment acheté un clavier USB Getorix GK-45X très bon marché avec rétroéclairage RVB. Après l’avoir connecté à un MacBook Pro équipé d’un processeur M1, il est devenu évident que le rétroéclairage RVB ne fonctionnait pas. Même en appuyant sur la combinaison magique Fn + Scroll Lock, seul le niveau de rétroéclairage de l’écran du MacBook a changé. Il existe plusieurs solutions à ce problème, à savoir OpenRGB (ne fonctionne pas), HID LED Test (ne fonctionne pas). Seul l’utilitaire kvmswitch a fonctionné : https://github.com/stoutput/OSX-KVM
Vous devez le télécharger depuis GitHub et l’autoriser à s’exécuter à partir du terminal dans le panneau de sécurité des paramètres système. Si je comprends bien de la description, après avoir lancé l’utilitaire, il envoie une pression Fn + Scroll Lock, allumant/éteignant ainsi le rétroéclairage du clavier.
Tri par arbre : tri à l’aide d’un arbre de recherche binaire. Complexité temporelle – O(n²). Dans un tel arbre, chaque nœud à gauche a des nombres inférieurs au nœud, à droite il y en a plus que le nœud, en venant de la racine et en imprimant les valeurs de gauche à droite, on obtient une liste triée de nombres . Surprenant, non ?
Essayez de lire manuellement les nombres en partant de l’avant-dernier nœud gauche du coin inférieur gauche, pour chaque nœud à gauche – un nœud – à droite.
Cela ressemblera à ceci :
Avant-dernier nœud en bas à gauche – 3.
Il a une branche gauche – 1.
Prenez ce numéro (1)
Ensuite, nous prenons le sommet 3 (1, 3)
À droite se trouve la branche 6, mais elle contient des branches. Par conséquent, nous le lisons de la même manière.
Branche gauche du nœud 6 numéro 4 (1, 3, 4)
Le nœud lui-même est 6 (1, 3, 4, 6)
Droite 7 (1, 3, 4, 6, 7)
Montez jusqu’au nœud racine – 8 (1,3, 4,6, 7, 8)
Nous imprimons tout à droite par analogie
Nous obtenons la liste finale – 1, 3, 4, 6, 7, 8, 10, 13, 14
Pour implémenter l’algorithme dans le code, vous aurez besoin de deux fonctions :
Assembler un arbre de recherche binaire
Imprimer l’arbre de recherche binaire dans le bon ordre
L’arbre binaire de recherche est assemblé de la même manière qu’il est lu, un numéro est attaché à chaque nœud à gauche ou à droite, selon qu’il est inférieur ou supérieur.
Exemple en Lua :
function Node:new(value, lhs, rhs)
output = {}
setmetatable(output, self)
self.__index = self
output.value = value
output.lhs = lhs
output.rhs = rhs
output.counter = 1
return output
end
function Node:Increment()
self.counter = self.counter + 1
end
function Node:Insert(value)
if self.lhs ~= nil and self.lhs.value > value then
self.lhs:Insert(value)
return
end
if self.rhs ~= nil and self.rhs.value < value then
self.rhs:Insert(value)
return
end
if self.value == value then
self:Increment()
return
elseif self.value > value then
if self.lhs == nil then
self.lhs = Node:new(value, nil, nil)
else
self.lhs:Insert(value)
end
return
else
if self.rhs == nil then
self.rhs = Node:new(value, nil, nil)
else
self.rhs:Insert(value)
end
return
end
end
function Node:InOrder(output)
if self.lhs ~= nil then
output = self.lhs:InOrder(output)
end
output = self:printSelf(output)
if self.rhs ~= nil then
output = self.rhs:InOrder(output)
end
return output
end
function Node:printSelf(output)
for i=0,self.counter-1 do
output = output .. tostring(self.value) .. " "
end
return output
end
function PrintArray(numbers)
output = ""
for i=0,#numbers do
output = output .. tostring(numbers[i]) .. " "
end
print(output)
end
function Treesort(numbers)
rootNode = Node:new(numbers[0], nil, nil)
for i=1,#numbers do
rootNode:Insert(numbers[i])
end
print(rootNode:InOrder(""))
end
numbersCount = 10
maxNumber = 9
numbers = {}
for i=0,numbersCount-1 do
numbers[i] = math.random(0, maxNumber)
end
PrintArray(numbers)
Treesort(numbers)
Важный нюанс что для чисел которые равны вершине придумано множество интересных механизмов подцепления к ноде, я же просто добавил счетчик к классу вершины, при распечатке числа возвращаются по счетчику.
Tri par seaux : tri par seaux. L’algorithme est similaire au tri par comptage, à la différence que les nombres sont collectés dans des plages de « seaux », puis les seaux sont triés à l’aide de tout autre algorithme de tri suffisamment productif, et l’étape finale consiste à déplier les « seaux » par un, ce qui donne une liste triée
La complexité temporelle de l’algorithme est O(nk). L’algorithme fonctionne en temps linéaire pour des données obéissant à une loi de distribution uniforme. Pour faire simple, les éléments doivent être dans une certaine plage, sans « pointes », par exemple des nombres de 0,0 à 1,0. Si parmi ces nombres il y en a 4 ou 999, alors selon les lois de la cour, une telle rangée n’est plus considérée comme « paire ».
Exemple d’implémentation dans Julia :
buckets = Vector{Vector{Int}}()
for i in 0:bucketsCount - 1
bucket = Vector{Int}()
push!(buckets, bucket)
end
maxNumber = maximum(numbers)
for i in 0:length(numbers) - 1
bucketIndex = 1 + Int(floor(bucketsCount * numbers[1 + i] / (maxNumber + 1)))
push!(buckets[bucketIndex], numbers[1 + i])
end
for i in 0:length(buckets) - 1
bucketIndex = 1 + i
buckets[bucketIndex] = sort(buckets[bucketIndex])
end
flat = [(buckets...)...]
print(flat, "\n")
end
numbersCount = 10
maxNumber = 10
numbers = rand(1:maxNumber, numbersCount)
print(numbers,"\n")
bucketsCount = 10
bucketSort(numbers, bucketsCount)
На производительность алгоритма также влияет число ведер, для большего количества чисел лучше взять большее число ведер (Algorithms in a nutshell by George T. Heineman)
Tri Radix – tri par base. L’algorithme est similaire au tri par comptage dans la mesure où il n’y a pas de comparaison des éléments ; à la place, les éléments sont regroupés *caractère par caractère* dans des *buckets* (buckets), le bucket est sélectionné par l’index du numéro-caractère actuel. Complexité temporelle – O(nd).
Cela fonctionne comme ceci :
L’entrée sera les nombres 6, 12, 44, 9
Nous allons créer 10 groupes de listes (0 à 9), dans lesquels nous ajouterons/trierons des nombres petit à petit.
Suivant :
Démarrer une boucle avec le compteur i jusqu’au nombre maximum de caractères du nombre
Par l’index i de droite à gauche, nous obtenons un symbole pour chaque nombre ; s’il n’y a pas de symbole, alors nous supposons qu’il est nul
Convertir le symbole en nombre
Sélectionnez un bucket par numéro d’index et insérez-y le numéro entier
Après avoir terminé la recherche parmi les nombres, reconvertissez tous les compartiments en une liste de nombres
Obtenir des chiffres triés par rang
Répétez jusqu’à ce que tous les chiffres aient disparu
Exemple de tri Radix dans Scala :
import scala.util.Random.nextInt
object RadixSort {
def main(args: Array[String]) = {
var maxNumber = 200
var numbersCount = 30
var maxLength = maxNumber.toString.length() - 1
var referenceNumbers = LazyList.continually(nextInt(maxNumber + 1)).take(numbersCount).toList
var numbers = referenceNumbers
var buckets = List.fill(10)(ListBuffer[Int]())
for( i <- 0 to maxLength) { numbers.foreach( number => {
var numberString = number.toString
if (numberString.length() > i) {
var index = numberString.length() - i - 1
var character = numberString.charAt(index).toString
var characterInteger = character.toInt
buckets.apply(characterInteger) += number
}
else {
buckets.apply(0) += number
}
}
)
numbers = buckets.flatten
buckets.foreach(x => x.clear())
}
println(referenceNumbers)
println(numbers)
println(s"Validation result: ${numbers == referenceNumbers.sorted}")
}
}
L’algorithme dispose également d’une version pour une exécution parallèle, par exemple sur un GPU ; Il y a aussi une petite option de tri, qui doit êtretrès intéressante et vraiment époustouflante !
Heapsort – tri pyramidal. Complexité temporelle de l’algorithme – O(n log n), vite, non ? J’appellerais ce tri le tri des cailloux qui tombent. Il me semble que la façon la plus simple de l’expliquer est visuellement.
L’entrée est une liste de nombres, par exemple :
5, 0, 7, 2, 3, 9, 4
De gauche à droite, une structure de données est créée : un arbre binaire, ou comme je l’appelle : un arbre binaire. pyramide. Les éléments pyramidaux peuvent avoir un maximum de deux éléments enfants, mais un seul élément supérieur.
Créons un arbre binaire :
⠀⠀5
⠀0⠀7
2 3 9 4
Si vous regardez la pyramide pendant longtemps, vous pouvez voir que ce ne sont que des nombres provenant d’un tableau, se succédant les uns après les autres, le nombre d’éléments dans chaque étage est multiplié par deux.
Ensuite, le plaisir commence : trions la pyramide de bas en haut en utilisant la méthode des cailloux tombants (tassifier). Le tri pourrait être lancé depuis le dernier étage (2 3 9 4), mais cela ne sert à rien car il n’y a pas d’étage en dessous où vous pourriez tomber.
Par conséquent, nous commençons à supprimer les éléments de l’avant-dernier étage (0 7)
⠀⠀5
⠀0⠀7
2 3 9 4
Le premier élément à tomber est sélectionné à droite, dans notre cas c’est 7, puis nous regardons ce qu’il y a en dessous, et en dessous se trouvent 9 et 4, neuf est supérieur à quatre, et neuf est également supérieur à Sept! Nous déposons 7 sur 9 et soulevons 9 à la place 7.
⠀⠀5
⠀0⠀9
2 3 7 4
Ensuite, on comprend que sept n’a nulle part où descendre plus bas, on passe au chiffre 0, qui se situe à l’avant-dernier étage à gauche :
⠀⠀5
⠀0⠀9
2 3 7 4
Voyons ce qu’il y a en dessous – 2 et 3, deux est inférieur à trois, trois est supérieur à zéro, donc on échange zéro et trois :
⠀⠀5
⠀3⠀9
2 0 7 4
Lorsque vous atteignez le bout de l’étage, allez à l’étage supérieur et déposez tout là-bas si vous le pouvez.
Le résultat est une structure de données – un tas, à savoir max tas, car en haut se trouve le plus grand élément :
⠀⠀9
⠀3⠀7
2 0 5 4
Si vous le renvoyez à une représentation matricielle, vous obtenez une liste :
[9, 3, 7, 2, 0, 5, 4]
De là, nous pouvons conclure qu’en échangeant le premier et le dernier élément, nous obtenons le premier nombre dans la position triée finale, à savoir que 9 doit être à la fin de la liste triée, échangez les places :
[4, 3, 7, 2, 0, 5, 9]
Regardons un arbre binaire :
⠀⠀4
⠀3⠀7
2 0 5 9
Le résultat est une situation dans laquelle la partie inférieure de l’arbre est triée, il suffit d’en déposer 4 à la bonne position, de répéter l’algorithme, mais de ne pas prendre en compte les nombres déjà triés, à savoir 9 :
⠀⠀4
⠀3⠀7
2 0 5 9
⠀⠀7
⠀3⠀4
2 0 5 9
⠀⠀7
⠀3⠀5
2 0 4 9
Il s’est avéré que nous, après avoir perdu 4, avons soulevé le deuxième plus grand nombre après 9 – 7. Échangez le dernier numéro non trié (4) et le plus grand nombre (7)
⠀⠀4
⠀3⠀5
2 0 7 9
Il s’avère que nous avons maintenant deux nombres dans la bonne position finale :
4, 3, 5, 2, 0, 7, 9
Ensuite, nous répétons l’algorithme de tri, en ignorant ceux déjà triés, à la fin nous obtenons un tas :
⠀⠀0
⠀2⠀3
4 5 7 9
Ou sous forme de liste :
0, 2, 3, 4, 5, 7, 9
Mise en œuvre
L’algorithme est généralement divisé en trois fonctions :
Créer un tas
Algorithme de tamisage (heapify)
Remplacement du dernier élément non trié et du premier
Le tas est créé en parcourant l’avant-dernière ligne de l’arbre binaire à l’aide de la fonction heapify, de droite à gauche, jusqu’à la fin du tableau. Ensuite dans le cycle, le premier remplacement des nombres est effectué, après quoi le premier élément tombe/reste en place, à la suite de quoi le plus grand élément tombe à la première place, le cycle se répète avec une diminution du nombre de participants d’un, car après chaque passage, les nombres triés restent à la fin de la liste.
Exemple de tri par tas dans Ruby :
module Colors
BLUE = "\033[94m"
RED = "\033[31m"
STOP = "\033[0m"
end
def heapsort(rawNumbers)
numbers = rawNumbers.dup
def swap(numbers, from, to)
temp = numbers[from]
numbers[from] = numbers[to]
numbers[to] = temp
end
def heapify(numbers)
count = numbers.length()
lastParentNode = (count - 2) / 2
for start in lastParentNode.downto(0)
siftDown(numbers, start, count - 1)
start -= 1
end
if DEMO
puts "--- heapify ends ---"
end
end
def siftDown(numbers, start, rightBound)
cursor = start
printBinaryHeap(numbers, cursor, rightBound)
def calculateLhsChildIndex(cursor)
return cursor * 2 + 1
end
def calculateRhsChildIndex(cursor)
return cursor * 2 + 2
end
while calculateLhsChildIndex(cursor) <= rightBound
lhsChildIndex = calculateLhsChildIndex(cursor)
rhsChildIndex = calculateRhsChildIndex(cursor)
lhsNumber = numbers[lhsChildIndex]
biggerChildIndex = lhsChildIndex
if rhsChildIndex <= rightBound
rhsNumber = numbers[rhsChildIndex]
if lhsNumber < rhsNumber
biggerChildIndex = rhsChildIndex
end
end
if numbers[cursor] < numbers[biggerChildIndex]
swap(numbers, cursor, biggerChildIndex)
cursor = biggerChildIndex
else
break
end
printBinaryHeap(numbers, cursor, rightBound)
end
printBinaryHeap(numbers, cursor, rightBound)
end
def printBinaryHeap(numbers, nodeIndex = -1, rightBound = -1)
if DEMO == false
return
end
perLineWidth = (numbers.length() * 4).to_i
linesCount = Math.log2(numbers.length()).ceil()
xPrinterCount = 1
cursor = 0
spacing = 3
for y in (0..linesCount)
line = perLineWidth.times.map { " " }
spacing = spacing == 3 ? 4 : 3
printIndex = (perLineWidth / 2) - (spacing * xPrinterCount) / 2
for x in (0..xPrinterCount - 1)
if cursor >= numbers.length
break
end
if nodeIndex != -1 && cursor == nodeIndex
line[printIndex] = "%s%s%s" % [Colors::RED, numbers[cursor].to_s, Colors::STOP]
elsif rightBound != -1 && cursor > rightBound
line[printIndex] = "%s%s%s" % [Colors::BLUE, numbers[cursor].to_s, Colors::STOP]
else
line[printIndex] = numbers[cursor].to_s
end
cursor += 1
printIndex += spacing
end
print line.join()
xPrinterCount *= 2
print "\n"
end
end
heapify(numbers)
rightBound = numbers.length() - 1
while rightBound > 0
swap(numbers, 0, rightBound)
rightBound -= 1
siftDown(numbers, 0, rightBound)
end
return numbers
end
numbersCount = 14
maximalNumber = 10
numbers = numbersCount.times.map { Random.rand(maximalNumber) }
print numbers
print "\n---\n"
start = Time.now
sortedNumbers = heapsort(numbers)
finish = Time.now
heapSortTime = start - finish
start = Time.now
referenceSortedNumbers = numbers.sort()
finish = Time.now
referenceSortTime = start - finish
print "Reference sort: "
print referenceSortedNumbers
print "\n"
print "Reference sort time: %f\n" % referenceSortTime
print "Heap sort: "
print sortedNumbers
print "\n"
if DEMO == false
print "Heap sort time: %f\n" % heapSortTime
else
print "Disable DEMO for performance measure\n"
end
if sortedNumbers != referenceSortedNumbers
puts "Validation failed"
exit 1
else
puts "Validation success"
exit 0
end
Cet algorithme n’est pas facile à comprendre sans visualisation, donc la première chose que je recommande est d’écrire une fonction qui imprimera la vue actuelle de l’arbre binaire.
Recently, it turned out that users of modern Nvidia GPUs under Arch Linux do not need to use the bumblebee package at all, for example, for me it did not detect an external monitor when connected. I recommend removing the bumblebee package and all related packages, and installing prime using the instructions on the Arch Wiki.
Next, to launch all games on Steam and 3D applications, add prime-run, for Steam this is done like this prime-run %command% in additional launch options.
To check the correctness, you can use glxgears, prime-run glxgears. https://bbs.archlinux.org/viewtopic.php? pid=2048195#p2048195
Quicksort est un algorithme de tri diviser pour régner. De manière récursive, pièce par pièce, nous analysons le tableau de nombres, en plaçant les nombres dans un ordre de plus en plus grand à partir de l’élément de référence sélectionné, et insérons l’élément de référence lui-même dans la coupure entre eux. Après plusieurs itérations récursives, vous vous retrouverez avec une liste triée. Complexité temporelle O(n2).
Schéma :
Nous commençons par obtenir une liste d’éléments de l’extérieur, les limites de tri. Dans un premier temps, les limites de tri s’étendront du début à la fin.
Vérifiez que les limites de début et de fin ne se croisent pas ; si cela se produit, il est temps de terminer
Sélectionnez un élément dans la liste et appelez-le pivot
Déplacez-le vers la droite jusqu’à la fin du dernier index afin qu’il ne gêne pas
Créez un compteur de *nombres plus petits* toujours égaux à zéro
Parcourez la liste de gauche à droite, jusqu’au dernier index inclus où se trouve l’élément de référence
Nous comparons chaque élément avec celui de référence
S’il est inférieur à celui de référence, alors nous l’échangeons en fonction de l’index du compteur des nombres plus petits. Incrémentez le compteur des nombres plus petits.
Lorsque la boucle atteint l’élément de support, nous nous arrêtons et échangeons l’élément de support avec l’élément en fonction du compteur de nombres plus petits.
Nous exécutons l’algorithme séparément pour la plus petite partie gauche de la liste et séparément pour la plus grande partie droite de la liste.
Par conséquent, toutes les itérations récursives commenceront à s’arrêter en raison de l’enregistrement au point 2
Obtenir une liste triée
Quicksort a été inventé par le scientifique Charles Anthony Richard Hoare de l’Université d’État de Moscou. Ayant appris le russe, il a étudié la traduction informatique ainsi que la théorie des probabilités à l’école Kolmogorov. En 1960, en raison de la crise politique, il quitte l’Union soviétique.
Exemple d’implémentation dans Rust :
use rand::Rng;
fn swap(numbers: &mut [i64], from: usize, to: usize) {
let temp = numbers[from];
numbers[from] = numbers[to];
numbers[to] = temp;
}
fn quicksort(numbers: &mut [i64], left: usize, right: usize) {
if left >= right {
return
}
let length = right - left;
if length <= 1 {
return
}
let pivot_index = left + (length / 2);
let pivot = numbers[pivot_index];
let last_index = right - 1;
swap(numbers, pivot_index, last_index);
let mut less_insert_index = left;
for i in left..last_index {
if numbers[i] < pivot {
swap(numbers, i, less_insert_index);
less_insert_index += 1;
}
}
swap(numbers, last_index, less_insert_index);
quicksort(numbers, left, less_insert_index);
quicksort(numbers, less_insert_index + 1, right);
}
fn main() {
let mut numbers = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0];
let mut reference_numbers = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0];
let mut rng = rand::thread_rng();
for i in 0..numbers.len() {
numbers[i] = rng.gen_range(-10..10);
reference_numbers[i] = numbers[i];
}
reference_numbers.sort();
println!("Numbers {:?}", numbers);
let length = numbers.len();
quicksort(&mut numbers, 0, length);
println!("Numbers {:?}", numbers);
println!("Reference numbers {:?}", reference_numbers);
if numbers != reference_numbers {
println!("Validation failed");
std::process::exit(1);
}
else {
println!("Validation success!");
std::process::exit(0);
}
}
Si rien n’est clair, je vous suggère de regarder la vidéo de Rob Edwards de l’Université de San Diego https://www.youtube.com/watch?v=ZHVk2blR45Q il montre très simplement, étape par étape, l’essence et la mise en œuvre de l’algorithme.
Le tri par insertion binaire est une variante du tri par insertion dans laquelle la position d’insertion est déterminée à l’aide d’une recherche binaire. La complexité temporelle de l’algorithme est O(n2)
L’algorithme fonctionne comme ceci :
Une boucle commence de zéro jusqu’à la fin de la liste
Dans la boucle, un nombre est sélectionné pour le tri, le nombre est stocké dans une variable distincte
La recherche binaire recherche l’index pour insérer ce numéro par rapport aux chiffres de gauche
Une fois l’index trouvé, les nombres de gauche sont décalés d’une position vers la droite, en commençant à l’index d’insertion. Au cours du processus, le numéro à trier sera effacé.
Le numéro précédemment enregistré est inséré à l’index d’insertion
A la fin de la boucle, toute la liste sera triée
Lors d’une recherche binaire, il est possible que le numéro ne soit pas trouvé et que l’index ne soit pas renvoyé. En raison de la particularité de la recherche binaire, le nombre le plus proche de celui recherché sera trouvé, puis pour renvoyer l’index il faudra le comparer avec celui recherché, si celui recherché est inférieur, alors celui recherché doit être à l’index à gauche, et s’il est supérieur ou égal, alors à droite.
Allez code :
import (
"fmt"
"math/rand"
"time"
)
const numbersCount = 20
const maximalNumber = 100
func binarySearch(numbers []int, item int, low int, high int) int {
for high > low {
center := (low + high) / 2
if numbers[center] < item { low = center + 1 } else if numbers[center] > item {
high = center - 1
} else {
return center
}
}
if numbers[low] < item {
return low + 1
} else {
return low
}
}
func main() {
rand.Seed(time.Now().Unix())
var numbers [numbersCount]int
for i := 0; i < numbersCount; i++ {
numbers[i] = rand.Intn(maximalNumber)
}
fmt.Println(numbers)
for i := 1; i < len(numbers); i++ { searchAreaLastIndex := i - 1 insertNumber := numbers[i] insertIndex := binarySearch(numbers[:], insertNumber, 0, searchAreaLastIndex) for x := searchAreaLastIndex; x >= insertIndex; x-- {
numbers[x+1] = numbers[x]
}
numbers[insertIndex] = insertNumber
}
fmt.Println(numbers)
}
Shell Sort – une variante du tri par insertion avec peignage préliminaire d’un tableau de nombres.
Nous devons nous rappeler comment fonctionne le tri par insertion :
1. Une boucle commence de zéro jusqu’à la fin de la boucle, le tableau est donc divisé en deux parties 2. Pour la partie gauche, une deuxième boucle est lancée, comparant les éléments de droite à gauche, le plus petit élément de droite est déposé jusqu’à ce qu’un plus petit élément de gauche soit trouvé 3. A la fin des deux boucles, on obtient une liste triée
Il était une fois l’informaticien Donald Schell qui se demandait comment améliorer l’algorithme de tri par insertion. Il a également eu l’idée de parcourir d’abord le tableau en deux cycles, mais à une certaine distance, en réduisant progressivement le « peigne » jusqu’à ce qu’il se transforme en un algorithme de tri par insertion régulier. Tout est vraiment si simple, pas d’embûches, aux deux cycles ci-dessus on en ajoute un autre, dans lequel on réduit progressivement la taille du « peigne ». La seule chose que vous devez faire est de vérifier la distance lors de la comparaison afin qu’elle ne dépasse pas le tableau.
Un sujet vraiment intéressant est le choix de la séquence permettant de modifier la longueur de comparaison à chaque itération de la première boucle. C’est intéressant car les performances de l’algorithme en dépendent.
Différentes personnes ont participé au calcul de la distance idéale ; apparemment, ce sujet les intéressait beaucoup. Ne pourraient-ils pas simplement exécuter Ruby et appeler l’algorithme sort() le plus rapide ?
En général, ces personnes étranges ont écrit des dissertations sur le thème du calcul de la distance/écart du « peigne » pour l’algorithme Shell. J’ai simplement utilisé les résultats de leurs travaux et vérifié 5 types de séquences, Hibbard, Knuth-Pratt, Chiura, Sedgwick.
import time
import random
from functools import reduce
import math
DEMO_MODE = False
if input("Demo Mode Y/N? ").upper() == "Y":
DEMO_MODE = True
class Colors:
BLUE = '\033[94m'
RED = '\033[31m'
END = '\033[0m'
def swap(list, lhs, rhs):
list[lhs], list[rhs] = list[rhs], list[lhs]
return list
def colorPrintoutStep(numbers: List[int], lhs: int, rhs: int):
for index, number in enumerate(numbers):
if index == lhs:
print(f"{Colors.BLUE}", end = "")
elif index == rhs:
print(f"{Colors.RED}", end = "")
print(f"{number},", end = "")
if index == lhs or index == rhs:
print(f"{Colors.END}", end = "")
if index == lhs or index == rhs:
print(f"{Colors.END}", end = "")
print("\n")
input(">")
def ShellSortLoop(numbers: List[int], distanceSequence: List[int]):
distanceSequenceIterator = reversed(distanceSequence)
while distance:= next(distanceSequenceIterator, None):
for sortArea in range(0, len(numbers)):
for rhs in reversed(range(distance, sortArea + 1)):
lhs = rhs - distance
if DEMO_MODE:
print(f"Distance: {distance}")
colorPrintoutStep(numbers, lhs, rhs)
if numbers[lhs] > numbers[rhs]:
swap(numbers, lhs, rhs)
else:
break
def ShellSort(numbers: List[int]):
global ShellSequence
ShellSortLoop(numbers, ShellSequence)
def HibbardSort(numbers: List[int]):
global HibbardSequence
ShellSortLoop(numbers, HibbardSequence)
def ShellPlusKnuttPrattSort(numbers: List[int]):
global KnuttPrattSequence
ShellSortLoop(numbers, KnuttPrattSequence)
def ShellPlusCiuraSort(numbers: List[int]):
global CiuraSequence
ShellSortLoop(numbers, CiuraSequence)
def ShellPlusSedgewickSort(numbers: List[int]):
global SedgewickSequence
ShellSortLoop(numbers, SedgewickSequence)
def insertionSort(numbers: List[int]):
global insertionSortDistanceSequence
ShellSortLoop(numbers, insertionSortDistanceSequence)
def defaultSort(numbers: List[int]):
numbers.sort()
def measureExecution(inputNumbers: List[int], algorithmName: str, algorithm):
if DEMO_MODE:
print(f"{algorithmName} started")
numbers = inputNumbers.copy()
startTime = time.perf_counter()
algorithm(numbers)
endTime = time.perf_counter()
print(f"{algorithmName} performance: {endTime - startTime}")
def sortedNumbersAsString(inputNumbers: List[int], algorithm) -> str:
numbers = inputNumbers.copy()
algorithm(numbers)
return str(numbers)
if DEMO_MODE:
maximalNumber = 10
numbersCount = 10
else:
maximalNumber = 10
numbersCount = random.randint(10000, 20000)
randomNumbers = [random.randrange(1, maximalNumber) for i in range(numbersCount)]
ShellSequenceGenerator = lambda n: reduce(lambda x, _: x + [int(x[-1]/2)], range(int(math.log(numbersCount, 2))), [int(numbersCount / 2)])
ShellSequence = ShellSequenceGenerator(randomNumbers)
ShellSequence.reverse()
ShellSequence.pop()
HibbardSequence = [
0, 1, 3, 7, 15, 31, 63, 127, 255, 511, 1023, 2047, 4095,
8191, 16383, 32767, 65535, 131071, 262143, 524287, 1048575,
2097151, 4194303, 8388607, 16777215, 33554431, 67108863, 134217727,
268435455, 536870911, 1073741823, 2147483647, 4294967295, 8589934591
]
KnuttPrattSequence = [
1, 4, 13, 40, 121, 364, 1093, 3280, 9841, 29524, 88573, 265720,
797161, 2391484, 7174453, 21523360, 64570081, 193710244, 581130733,
1743392200, 5230176601, 15690529804, 47071589413
]
CiuraSequence = [
1, 4, 10, 23, 57, 132, 301, 701, 1750, 4376,
10941, 27353, 68383, 170958, 427396, 1068491,
2671228, 6678071, 16695178, 41737946, 104344866,
260862166, 652155416, 1630388541
]
SedgewickSequence = [
1, 5, 19, 41, 109, 209, 505, 929, 2161, 3905,
8929, 16001, 36289, 64769, 146305, 260609, 587521,
1045505, 2354689, 4188161, 9427969, 16764929, 37730305,
67084289, 150958081, 268386305, 603906049, 1073643521,
2415771649, 4294770689, 9663381505, 17179475969
]
insertionSortDistanceSequence = [1]
algorithms = {
"Default Python Sort": defaultSort,
"Shell Sort": ShellSort,
"Shell + Hibbard" : HibbardSort,
"Shell + Prat, Knutt": ShellPlusKnuttPrattSort,
"Shell + Ciura Sort": ShellPlusCiuraSort,
"Shell + Sedgewick Sort": ShellPlusSedgewickSort,
"Insertion Sort": insertionSort
}
for name, algorithm in algorithms.items():
measureExecution(randomNumbers, name, algorithm)
reference = sortedNumbersAsString(randomNumbers, defaultSort)
for name, algorithm in algorithms.items():
if sortedNumbersAsString(randomNumbers, algorithm) != reference:
print("Sorting validation failed")
exit(1)
print("Sorting validation success")
exit(0)
Dans mon implémentation, pour un ensemble aléatoire de nombres, les écarts les plus rapides sont Sedgwick et Hibbard.
monpy
Je voudrais également mentionner l’analyseur de typage statique pour Python 3 – mypy. Aide à faire face aux problèmes inhérents aux langages à typage dynamique, à savoir qu’il élimine la possibilité de coller quelque chose là où ce n’est pas nécessaire.
Comme le disent les programmeurs expérimentés, “la saisie statique n’est pas nécessaire lorsque vous avez une équipe de professionnels”, un jour nous deviendrons tous des professionnels, nous écrirons du code en pleine unité et compréhension avec les machines, mais pour l’instant vous pouvez utiliser des utilitaires similaires. et les langages typés statiquement.
Tri par sélection double : un sous-type de tri par sélection, il semble qu’il devrait être deux fois plus rapide. L’algorithme Vanilla effectue une double boucle dans la liste des nombres, trouve le nombre minimum et échange les places avec le numéro actuel pointé par la boucle au niveau supérieur. Le tri par double sélection recherche les nombres minimum et maximum, puis remplace les deux chiffres pointés par la boucle au niveau supérieur à – deux chiffres à gauche et à droite. Toute cette orgie se termine lorsque les curseurs des nombres à remplacer se trouvent au milieu de la liste, et par conséquent, des nombres triés sont obtenus à gauche et à droite du centre visuel. La complexité temporelle de l’algorithme est similaire à celle du tri par sélection – O(n2), mais soi-disant il y a une accélération de 30 %.
État limite
Déjà à ce stade, vous pouvez imaginer le moment d’une collision, par exemple, lorsque le numéro du curseur gauche (le nombre minimum) pointe vers le nombre maximum dans la liste, alors le nombre minimum est réorganisé, le réarrangement du nombre maximum tombe immédiatement en panne. Par conséquent, toutes les implémentations de l’algorithme contiennent la vérification de tels cas et le remplacement des index par des index corrects. Dans mon implémentation, une seule vérification suffisait :
maximalNumberIndex = minimalNumberIndex;
}
Реализация на Cito
Cito – язык либ, язык транслятор. На нем можно писать для C, C++, C#, Java, JavaScript, Python, Swift, TypeScript, OpenCL C, при этом совершенно ничего не зная про эти языки. Исходный код на языке Cito транслируется в исходный код на поддерживаемых языках, далее можно использовать как библиотеку, либо напрямую, исправив сгенеренный код руками. Эдакий Write once – translate to anything.
Double Selection Sort на cito:
{
public static int[] sort(int[]# numbers, int length)
{
int[]# sortedNumbers = new int[length];
for (int i = 0; i < length; i++) {
sortedNumbers[i] = numbers[i];
}
for (int leftCursor = 0; leftCursor < length / 2; leftCursor++) {
int minimalNumberIndex = leftCursor;
int minimalNumber = sortedNumbers[leftCursor];
int rightCursor = length - (leftCursor + 1);
int maximalNumberIndex = rightCursor;
int maximalNumber = sortedNumbers[maximalNumberIndex];
for (int cursor = leftCursor; cursor <= rightCursor; cursor++) { int cursorNumber = sortedNumbers[cursor]; if (minimalNumber > cursorNumber) {
minimalNumber = cursorNumber;
minimalNumberIndex = cursor;
}
if (maximalNumber < cursorNumber) {
maximalNumber = cursorNumber;
maximalNumberIndex = cursor;
}
}
if (leftCursor == maximalNumberIndex) {
maximalNumberIndex = minimalNumberIndex;
}
int fromNumber = sortedNumbers[leftCursor];
int toNumber = sortedNumbers[minimalNumberIndex];
sortedNumbers[minimalNumberIndex] = fromNumber;
sortedNumbers[leftCursor] = toNumber;
fromNumber = sortedNumbers[rightCursor];
toNumber = sortedNumbers[maximalNumberIndex];
sortedNumbers[maximalNumberIndex] = fromNumber;
sortedNumbers[rightCursor] = toNumber;
}
return sortedNumbers;
}
}
If the game doesn’t start with fcntl(5) for /tmp/source_engine_2808995433.lock failed, then try deleting the /tmp/source_engine_2808995433.lock file rm /tmp/source_engine_2808995433.lock
Usually the lock file is left over from the last game session unless the game was closed naturally.
How to check?
The easiest way to check the launch of applications on a discrete Nvidia graphics card is through the nvidia-smi utility:
For games on the Source engine, you can check through the game console using the mat_info command:
Tri du sommeil – sleep sort, un autre représentant des algorithmes de tri étranges déterministes.
Cela fonctionne comme ceci :
Parcourt une liste d’éléments
Un thread distinct est lancé pour chaque boucle
Le fil de discussion est en veille pendant un certain temps – valeur de l’élément et sortie de la valeur après le sommeil
A la fin de la boucle, attendez la fin du sommeil le plus long du thread, affichez la liste triée
Exemple de code pour l’algorithme de tri en veille en C :
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
typedef struct {
int number;
} ThreadPayload;
void *sortNumber(void *args) {
ThreadPayload *payload = (ThreadPayload*) args;
const int number = payload->number;
free(payload);
usleep(number * 1000);
printf("%d ", number);
return NULL;
}
int main(int argc, char *argv[]) {
const int numbers[] = {2, 42, 1, 87, 7, 9, 5, 35};
const int length = sizeof(numbers) / sizeof(int);
int maximal = 0;
pthread_t maximalThreadID;
printf("Sorting: ");
for (int i = 0; i < length; i++) { pthread_t threadID; int number = numbers[i]; printf("%d ", number); ThreadPayload *payload = malloc(sizeof(ThreadPayload)); payload->number = number;
pthread_create(&threadID, NULL, sortNumber, (void *) payload);
if (maximal < number) {
maximal = number;
maximalThreadID = threadID;
}
}
printf("\n");
printf("Sorted: ");
pthread_join(maximalThreadID, NULL);
printf("\n");
return 0;
}
Dans cette implémentation, j’ai utilisé la fonction usleep sur les microsecondes avec la valeur multipliée par 1000, c’est-à-dire en millisecondes. Complexité temporelle de l’algorithme – O(très long)
Le tri de Staline – ; trier, un des algorithmes de tri avec perte de données. L’algorithme est très productif et efficace, complexité temporelle O(n).
Cela fonctionne comme ceci :
Parcourez le tableau en comparant l’élément actuel avec le suivant
Si l’élément suivant est plus petit que l’élément actuel, supprimez-le
En conséquence, nous obtenons un tableau trié en O(n)
Exemple de sortie de l’algorithme :
Gulag: [1, 3, 2, 4, 6, 42, 4, 8, 5, 0, 35, 10]
Element 2 sent to Gulag
Element 4 sent to Gulag
Element 8 sent to Gulag
Element 5 sent to Gulag
Element 0 sent to Gulag
Element 35 sent to Gulag
Element 10 sent to Gulag
Numbers: [1, 3, 4, 6, 42]
Gulag: [2, 4, 8, 5, 0, 35, 10]
Code Python 3 :
gulag = []
print(f"Numbers: {numbers}")
print(f"Gulag: {numbers}")
i = 0
maximal = numbers[0]
while i < len(numbers):
element = numbers[i]
if maximal > element:
print(f"Element {element} sent to Gulag")
gulag.append(element)
del numbers[i]
else:
maximal = element
i += 1
print(f"Numbers: {numbers}")
print(f"Gulag: {gulag}")
Les inconvénients incluent la perte de données, mais si nous nous dirigeons vers une liste utopique, idéale et triée en O(n), alors comment faire autrement ?
N’ayant pas trouvé d’implémentation Objective-C sur le Rosetta Code , je me suis écrit :
#include <Foundation/Foundation.h>
@implementation SelectionSort
- (void)performSort:(NSMutableArray *)numbers
{
NSLog(@"%@", numbers);
for (int startIndex = 0; startIndex < numbers.count-1; startIndex++) {
int minimalNumberIndex = startIndex;
for (int i = startIndex + 1; i < numbers.count; i++) {
id lhs = [numbers objectAtIndex: minimalNumberIndex];
id rhs = [numbers objectAtIndex: i];
if ([lhs isGreaterThan: rhs]) {
minimalNumberIndex = i;
}
}
id temporary = [numbers objectAtIndex: minimalNumberIndex];
[numbers setObject: [numbers objectAtIndex: startIndex]
atIndexedSubscript: minimalNumberIndex];
[numbers setObject: temporary
atIndexedSubscript: startIndex];
}
NSLog(@"%@", numbers);
}
@end
Собрать и запустить можно либо на MacOS/Xcode, либо на любой операционной системе поддерживающей GNUstep, например у меня собирается Clang на Arch Linux.
Скрипт сборки:
Tri par comptage – algorithme de tri par comptage. En termes de? Oui! Juste comme ça !
L’algorithme implique au moins deux tableaux, le premier – liste d’entiers à trier, seconde – un tableau de taille = (nombre maximum – nombre minimum) + 1, ne contenant initialement que des zéros. Ensuite, les nombres sont triés du premier tableau et l’élément numérique est utilisé pour obtenir un index dans le deuxième tableau, qui est incrémenté de un. Après avoir parcouru toute la liste, nous obtiendrons un deuxième tableau complètement rempli avec le nombre de répétitions des nombres du premier. L’algorithme entraîne une surcharge importante : le deuxième tableau contient également des zéros pour les nombres qui ne figurent pas dans la première liste, ce qu’on appelle. surcharge de la mémoire
Après avoir reçu le deuxième tableau, nous le parcourons et écrivons la version triée du nombre par index, en décrémentant le compteur à zéro. Initialement, un compteur zéro est ignoré.
Un exemple de fonctionnement non optimisé de l’algorithme de tri par comptage :
Tableau d’entrée 1,9,1,4,6,4,4
Alors le tableau à compter sera 0,1,2,3,4,5,6,7,8,9 (nombre minimum 0, maximum 9)
Avec un total de compteurs 0,2,0,0,3,0,1,0,0,1
Total du tableau trié 1,1,4,4,4,6,9
Code d’algorithme en Python 3 :
numbers = [42, 89, 69, 777, 22, 35, 42, 69, 42, 90, 777]
minimal = min(numbers)
maximal = max(numbers)
countListRange = maximal - minimal
countListRange += 1
countList = [0] * countListRange
print(numbers)
print(f"Minimal number: {minimal}")
print(f"Maximal number: {maximal}")
print(f"Count list size: {countListRange}")
for number in numbers:
index = number - minimal
countList[index] += 1
replacingIndex = 0
for index, count in enumerate(countList):
for i in range(count):
outputNumber = minimal + index
numbers[replacingIndex] = outputNumber
replacingIndex += 1
print(numbers)
Из-за использования двух массивов, временная сложность алгоритма O(n + k)
Pseudo-tri ou tri par marais, l’un des algorithmes de tri les plus inutiles.
Cela fonctionne comme ceci : 1. L’entrée est un tableau de nombres 2. Un tableau de nombres est mélangé au hasard (shuffle) 3. Vérifie si le tableau est trié 4. S’il n’est pas trié, le tableau est à nouveau mélangé 5. Toute cette action est répétée jusqu’à ce que le tableau soit trié de manière aléatoire.
Comme vous pouvez le constater, les performances de cet algorithme sont terribles, les gens intelligents croient que même O(n * n!) c’est-à-dire il y a une chance que vous restiez coincé à lancer des dés pour la gloire du dieu du chaos pendant de nombreuses années, le tableau ne sera jamais trié, ou peut-être qu’il le sera ?
Mise en œuvre
Pour l’implémenter dans TypeScript, je devais implémenter les fonctions suivantes : 1. Mélangez un tableau d’objets 2. Comparaison de tableaux 3. Générer un nombre aléatoire compris entre zéro et un nombre (sic !) 4. Imprimez la progression, car il semble que le tri continue sans fin
Vous trouverez ci-dessous le code d’implémentation de TypeScript :
const randomInteger = (maximal: number) => Math.floor(Math.random() * maximal);
const isEqual = (lhs: any[], rhs: any[]) => lhs.every((val, index) => val === rhs[index]);
const shuffle = (array: any[]) => {
for (var i = 0; i < array.length; i++) { var destination = randomInteger(array.length-1); var temp = array[i]; array[i] = array[destination]; array[destination] = temp; } } let numbers: number[] = Array.from({length: 10}, ()=>randomInteger(10));
const originalNumbers = [...numbers];
const sortedNumbers = [...numbers].sort();
let numberOfRuns = 1;
do {
if (numberOfRuns % 1000 == 0) {
printoutProcess(originalNumbers, numbers, numberOfRuns);
}
shuffle(numbers);
numberOfRuns++;
} while (isEqual(numbers, sortedNumbers) == false)
console.log(`Success!`);
console.log(`Run number: ${numberOfRuns}`)
console.log(`Original numbers: ${originalNumbers}`);
console.log(`Current numbers: ${originalNumbers}`);
console.log(`Sorted numbers: ${sortedNumbers}`);
Для отладки можно использовать VSCode и плагин TypeScript Debugger от kakumei.
Как долго
Вывод работы алгоритма:
src/bogosort.ts:1
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 8,7,0,2,4,7,2,5,9,5, try number: 145000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 7,5,2,4,9,8,0,5,2,7, try number: 146000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 0,2,7,4,9,5,7,5,8,2, try number: 147000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 5,9,7,8,5,4,2,7,0,2, try number: 148000
src/bogosort.ts:2
Success!
src/bogosort.ts:24
Run number: 148798
src/bogosort.ts:25
Original numbers: 5,4,8,7,5,0,2,9,7,2
src/bogosort.ts:26
Current numbers: 5,4,8,7,5,0,2,9,7,2
src/bogosort.ts:27
Sorted numbers: 0,2,2,4,5,5,7,7,8,9
Для массива из 10 чисел Богосорт перемешивал исходный массив 148798 раз, многовато да?
Алгоритм можно использовать как учебный, для понимания возможностей языка с которым предстоит работать на рынке. Лично я был удивлен узнав что в ванильных JS и TS до сих пор нет своего алгоритма перемешивания массивов, генерации целого числа в диапазоне, доступа к хэшам объектов для быстрого сравнения.
Le modèle Interpreter fait référence aux modèles de conception comportementale. Ce modèle vous permet d’implémenter votre propre langage de programmation en travaillant avec un arbre AST dont les sommets sont des expressions terminales et non terminales qui implémentent la méthode Interpret, qui fournit les fonctionnalités du langage.
Expression de terminal : par exemple, constante de chaîne – “Bonjour tout le monde”
Expression non terminale : par exemple Print(“Hello World”), contient Print et un argument de l’expression terminale “Hello World”
Quelle est la différence ? La différence est que l’interprétation se termine sur les expressions terminales, mais pour les expressions non terminales, elle se poursuit en profondeur sur tous les sommets/arguments entrants. Si l’arborescence AST était constituée uniquement d’expressions non terminales, l’application ne se terminerait jamais, car une certaine finitude de tout processus est requise, cette finitude est ce que sont les expressions terminales, elles contiennent généralement des données, par exemple des chaînes.
Un exemple d’arborescence AST est ci-dessous :
Dcoetzee, CC0, via Wikimedia Commons
Comme vous pouvez le voir, les expressions terminales sont constantes et variables, les expressions non terminales sont le reste.
Ce qui n’est pas inclus
L’implémentation de l’Interpreter n’inclut pas l’analyse de la chaîne de langue entrée dans l’arborescence AST. Il suffit d’implémenter des classes d’expressions terminales et non terminales, des méthodes Interpret avec l’argument Context en entrée, de créer un arbre d’expressions AST et d’exécuter la méthode Interpret au niveau de l’expression racine. Un contexte peut être utilisé pour stocker l’état de l’application au moment de l’exécution.
Mise en œuvre
Le modèle implique :
Client – renvoie l’arborescence AST et exécute Interpret(context) pour le nœud racine (Client)
Contexte : contient l’état de l’application, transmis aux expressions lorsqu’elles sont interprétées (Contexte)
Expression abstraite : une classe abstraite contenant la méthode Interpret(context) (Expression)
L’expression terminale est une expression finale, descendante d’une expression abstraite (TerminalExpression)
Une expression non terminale n’est pas une expression finie ; elle contient des pointeurs vers des sommets profonds dans l’arborescence AST ; les sommets subordonnés affectent généralement le résultat de l’interprétation de l’expression non terminale (NonTerminalExpression)
Exemple client en C#
static void Main(string[] args)
{
var context = new Context();
var initialProgram = new PerformExpression(
new IExpression[] {
new SetExpression("alpha", "1"),
new GetExpression("alpha"),
new PrintExpression(
new IExpression[] {
new ConstantExpression("Hello Interpreter Pattern")
}
)
}
);
System.Console.WriteLine(initialProgram.interpret(context));
}
}
Exemple d’expression abstraite en C#
{
String interpret(Context context);
}
Exemple d’expression de terminal en C# (constante de chaîne)
Exemple d’expression non terminale en C# (démarrage et concaténation des résultats des sommets subordonnés, en utilisant le délimiteur « ; »
{
public PerformExpression(IExpression[] leafs) : base(leafs) {
this.leafs = leafs;
}
override public String interpret(Context context) {
var output = "";
foreach (var leaf in leafs) {
output += leaf.interpret(context) + ";";
}
return output;
}
}
Pouvez-vous le faire fonctionnellement ?
Comme on le sait, tous les langages Turing-complets sont équivalents. Est-il possible de transférer le modèle orienté objet vers le langage de programmation fonctionnel ?
Pour une expérience, prenons un langage FP pour le Web appelé Elm. Il n’y a pas de classes dans Elm, mais il y a des enregistrements et des types, donc les enregistrements et types suivants sont impliqués dans l’implémentation :
Expression : liste de toutes les expressions linguistiques possibles (Expression)
Expression subordonnée : expression subordonnée à l’expression non terminale (ExpressionLeaf)
Contexte : un enregistrement stockant l’état de l’application (Contexte)
Fonctions qui implémentent les méthodes Interpret(context) : toutes les fonctions nécessaires qui implémentent les fonctionnalités des expressions terminales et non terminales
Enregistrements auxiliaires de l’état de l’interprète – nécessaires au bon fonctionnement de l’interprète, ils stockent l’état de l’interprète, le contexte
Un exemple de fonction qui implémente l’interprétation pour l’ensemble des expressions possibles dans Elm :
case input.expression of
Constant text ->
{
output = text,
context = input.context
}
Perform leafs ->
let inputs = List.map (\leaf -> { expressionLeaf = leaf, context = input.context } ) leafs in
let startLeaf = { expressionLeaf = (Node (Constant "")), context = { variables = Dict.empty } } in
let outputExpressionInput = List.foldl mergeContextsAndRunLeafs startLeaf inputs in
{
output = (runExpressionLeaf outputExpressionInput).output,
context = input.context
}
Print printExpression ->
run
{
expression = printExpression,
context = input.context
}
Set key value ->
let variables = Dict.insert key value input.context.variables in
{
output = "OK",
context = { variables = variables }
}
Get key ->
{
output = Maybe.withDefault ("No value for key: " ++ key) (Dict.get key input.context.variables),
context = input.context
}
Et l’analyse syntaxique ?
L’analyse du code source dans une arborescence AST n’est pas incluse dans le modèle Interpreter ; il existe plusieurs approches pour analyser le code source, mais nous y reviendrons une autre fois. Dans l’implémentation de l’Interpreter for Elm, j’ai écrit un analyseur simple dans l’arborescence AST, composé de deux fonctions : analyser un sommet et analyser les sommets subordonnés.
parseLeafs state =
let tokensQueue = state.tokensQueue in
let popped = pop state.tokensQueue in
let tokensQueueTail = tail state.tokensQueue in
if popped == "Nothing" then
state
else if popped == "Perform(" then
{
tokensQueue = tokensQueue,
result = (state.result ++ [Node (parse tokensQueue)])
}
else if popped == ")" then
parseLeafs {
tokensQueue = tokensQueueTail,
result = state.result
}
else if popped == "Set" then
let key = pop tokensQueueTail in
let value = pop (tail tokensQueueTail) in
parseLeafs {
tokensQueue = tail (tail tokensQueueTail),
result = (state.result ++ [Node (Set key value)])
}
else if popped == "Get" then
let key = pop tokensQueueTail in
parseLeafs {
tokensQueue = tail tokensQueueTail,
result = (state.result ++ [Node (Get key)])
}
else
parseLeafs {
tokensQueue = tokensQueueTail,
result = (state.result ++ [Node (Constant popped)])
}
parse tokensQueue =
let popped = pop tokensQueue in
let tokensQueueTail = tail tokensQueue in
if popped == "Perform(" then
Perform (
parseLeafs {
tokensQueue = tokensQueueTail,
result = []
}
).result
else if popped == "Set" then
let key = pop tokensQueueTail in
let value = pop (tail tokensQueueTail) in
Set key value
else if popped == "Print" then
Print (parse tokensQueueTail)
else
Constant popped
Dans cet article, je décrirai l’algorithme de conversion d’un tampon RVB en gris (Niveaux de gris). Et cela se fait tout simplement, chaque canal de couleur de pixel du tampon est converti selon une certaine formule et le résultat est une image grise. Méthode moyenne :
red = average;
green = average;
blue = average;
Складываем 3 цветовых канала и делим на 3.
Однако существует еще один метод – метод средневзвешенный, он учитывает цветовосприятие человека:
red = luminance;
green = luminance;
blue = luminance;
Какой метод лучше использовать? Да какой вам больше подходит для конкретной задачи. Далее сравнение методов с помощью тестовой цветовой сетки:
Пример реализации на JavaScript + HTML 5
image,
canvas,
weightedAverage
) {
const context = canvas.getContext('2d');
const imageWeight = image.width;
const imageHeight = image.height;
canvas.width = imageWeight;
canvas.height = imageHeight;
context.drawImage(image, 0, 0);
let pixels = context
.getImageData(
0,
0,
imageWeight,
imageHeight
);
for (let y = 0; y & lt; pixels.height; y++) {
for (let x = 0; x & lt; pixels.width; x++) {
const i = (y * 4) * pixels.width + x * 4;
let red = pixels.data[i];
let green = pixels.data[i + 1];
let blue = pixels.data[i + 2]
const average = (red + green + blue) / 3;
const luminance = 0.2126 * red +
0.7152 * green +
0.0722 * blue;
red = weightedAverage ? luminance : average;
green = weightedAverage ? luminance : average;
blue = weightedAverage ? luminance : average;
pixels.data[i] = red;
pixels.data[i + 1] = green;
pixels.data[i + 2] = blue;
}
}
context
.putImageData(
pixels,
0,
0,
0,
0,
pixels.width,
pixels.height
);
}
Si vous obtenez l’erreur SDL_GetDesktopDisplayMode_REAL sur un Macbook M1 lors du lancement de CSGO, procédez comme décrit ci-dessous. 1. Ajoutez des options de lancement à Steam pour CSGO : -w 1440 -h 900 -plein écran 2. Lancez CSGO via Steam 3. Cliquez sur Ignorer ou Toujours ignorer l’erreur SDL_GetDesktopDisplayMode_REAL 4. Profitez-en
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.