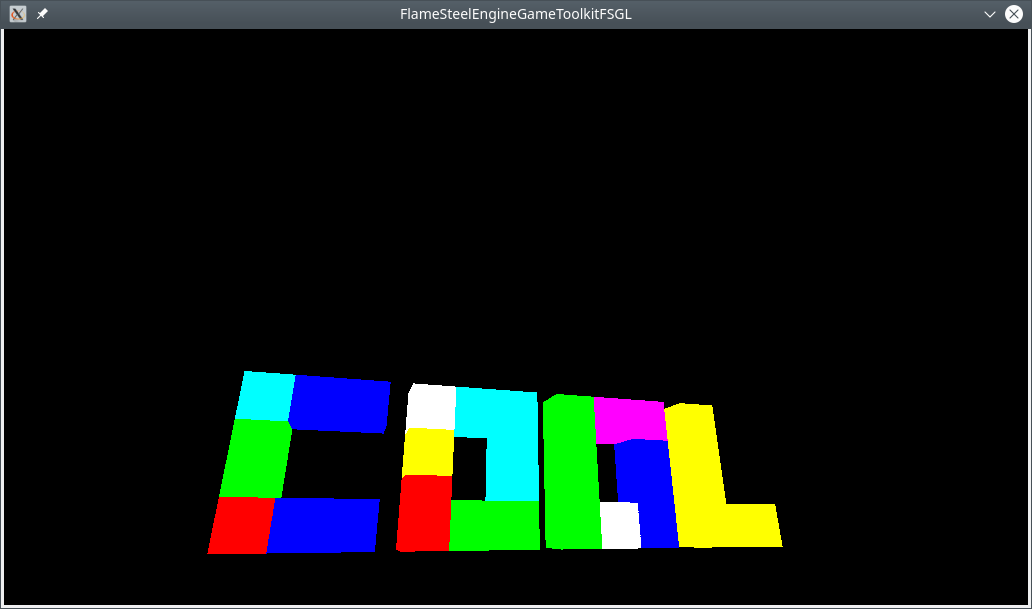
Esse post bobo é dedicado ao desenvolvimento de um jogo para o antigo computador ZX Spectrum em C. Vamos dar uma olhada no bonitão:

Iniciou a produção em 1982 e foi produzido até 1992. Características técnicas da máquina: processador Z80 de 8 bits, 16-128kb de memória e outras extensões, como o chip de som AY-3-8910.
Como parte da competição Yandex Retro Games Battle 2019 para esta máquina, escrevi um jogo chamado Interceptor 2020. Como não tive tempo de aprender linguagem assembly para o Z80, resolvi desenvolvê-lo em C. Como conjunto de ferramentas, escolhi um conjunto pronto – z88dk, que contém compiladores C e diversas bibliotecas auxiliares para agilizar a implementação de aplicações para o Spectrum. Ele também suporta muitas outras máquinas Z80, como MSX e calculadoras Texas Instruments.
A seguir, descreverei meu voo superficial sobre a arquitetura do computador, o conjunto de ferramentas z88dk, e mostrarei como consegui implementar a abordagem OOP e usar padrões de design.
Recursos de instalação
A instalação do z88dk deve ser realizada de acordo com o manual do repositório, porém, para usuários do Ubuntu, gostaria de destacar um recurso – Se você já possui compiladores para Z80 instalados a partir de pacotes deb, então você deve removê-los, já que z88dk os acessará da pasta bin por padrão devido à incompatibilidade das versões do compilador do conjunto de ferramentas, você provavelmente não conseguirá compilar nada.< /p>
Olá, mundo
Escrever Hello World é muito fácil:
#include
void main()
{
printf("Hello World");
}
É ainda mais fácil compilar um arquivo tap:
zcc +zx -lndos -create-app -o helloworld helloworld.c
Para rodar, use qualquer emulador ZX Spectrum com suporte a arquivo tap, por exemplo online:
http://jsspeccy.zxdemo.org/
Desenhe na imagem em tela cheia
tl;dr As imagens são desenhadas em blocos, blocos de tamanho 8×8 pixels, os próprios blocos são incorporados na fonte Spectrum e, em seguida, a imagem é impressa como uma linha a partir dos índices.
A biblioteca de saída de sprites e blocos sp1 produz blocos usando UDG. A imagem é traduzida em um conjunto de UDGs (blocos) individuais e depois montados na tela usando índices. Deve ser lembrado que UDG é usado para exibir texto, e se sua imagem contiver um conjunto muito grande de blocos (por exemplo, mais de 128 blocos), você terá que ir além dos limites do conjunto e apagar o Spectrum padrão fonte. Para contornar essa limitação, utilizei uma base de 128 – 255 simplificando as imagens, deixando a fonte original no lugar. Sobre simplificar as imagens abaixo.
Para desenhar imagens em tela cheia você precisa se munir de três utilitários:
Gimp
img2spec
png2c-z88dk
Existe uma maneira para verdadeiros homens ZX, verdadeiros guerreiros retrô, é abrir um editor gráfico usando a paleta Spectrum, conhecendo os recursos de saída da imagem, prepará-la manualmente e carregá-la usando png2c-z88dk ou png2scr.< /p>
A maneira mais fácil – pegue uma imagem de 32 bits, mude o número de cores para 3-4 no Gimp, edite-a levemente e importe-a para img2spec para não trabalhar com restrições de cores manualmente, exporte png e converta-a em um array C usando png2c- z88dk.
Lembre-se de que, para uma exportação bem-sucedida, cada bloco não pode conter mais de duas cores.
Como resultado, você receberá um arquivo h que contém o número de blocos únicos, se houver mais de ~128, simplifique a imagem no Gimp (aumente a repetibilidade) e execute o procedimento de exportação sobre um novo .
Após a exportação, você literalmente carrega a “fonte” dos blocos e imprime o “texto” dos índices dos blocos na tela. Abaixo está um exemplo da “classe” de renderização:
// грузим шрифт в память
unsigned char *pt = fullscreenImage->tiles;
for (i = 0; i < fullscreenImage->tilesLength; i++, pt += 8) {
sp1_TileEntry(fullscreenImage->tilesBase + i, pt);
}
// ставим курсор в 0,0
sp1_SetPrintPos(&ps0, 0, 0);
// печатаем строку
sp1_PrintString(&ps0, fullscreenImage->ptiles);
Desenhando sprites na tela
A seguir descreverei um método para desenhar sprites de 16×16 pixels na tela. Não cheguei na animação e na mudança de cores, porque… É trivial que já nesta fase, presumo, tenha ficado sem memória. Portanto, o jogo contém apenas sprites monocromáticos transparentes.
Desenhamos uma imagem png monocromática 16×16 no Gimp, depois usando png2sp1sprite a traduzimos em um arquivo assembly asm, em código C declaramos arrays do arquivo assembly e adicionamos o arquivo na fase de montagem.< /p>
Após a etapa de declaração do recurso sprite, ele deve ser adicionado na tela na posição desejada, segue abaixo um exemplo do código da “classe” do objeto do jogo:
struct sp1_ss *bubble_sprite = sp1_CreateSpr(SP1_DRAW_MASK2LB, SP1_TYPE_2BYTE, 3, 0, 0);
sp1_AddColSpr(bubble_sprite, SP1_DRAW_MASK2, SP1_TYPE_2BYTE, col2-col1, 0);
sp1_AddColSpr(bubble_sprite, SP1_DRAW_MASK2RB, SP1_TYPE_2BYTE, 0, 0);
sp1_IterateSprChar(bubble_sprite, initialiseColour);
A partir dos nomes das funções você pode entender aproximadamente o significado de – aloque memória para o sprite, adicione duas colunas 8×8, adicione uma cor para o sprite.
A posição do sprite é indicada em cada quadro:
sp1_MoveSprPix(gameObject->gameObjectSprite, Renderer_fullScreenRect, gameObject->sprite_col, gameObject->x, gameObject->y);
Emulando OOP
Não existe sintaxe para OOP em C. O que você deve fazer se ainda quiser? Você precisa conectar sua mente e ser iluminado pela ideia de que não existe equipamento OOP; em última análise, tudo se resume a uma das arquiteturas de máquina, na qual simplesmente não existe o conceito de objeto e outras abstrações associadas a ele.< /p>
Esse fato me impediu por muito tempo de entender por que OOP é necessário, por que é necessário usá-lo se no final tudo se trata de código de máquina.
Porém, após trabalhar no desenvolvimento de produtos, descobri as delícias desse paradigma de programação, principalmente, é claro, flexibilidade de desenvolvimento, mecanismos de proteção de código, com abordagem correta, reduzindo entropia, simplificando o trabalho em equipe. Todos os benefícios acima decorrem de três pilares – polimorfismo, encapsulamento, herança.
Vale ressaltar também a simplificação da resolução de questões relacionadas à arquitetura de aplicações, pois 80% dos problemas de arquitetura foram resolvidos por cientistas da computação no século passado e descritos na literatura sobre padrões de projeto. A seguir, descreverei maneiras de adicionar sintaxe semelhante a OOP em C.
É mais conveniente tomar estruturas C como base para armazenar dados de uma instância de classe. Claro, você pode usar um buffer de bytes, criar sua própria estrutura para classes, métodos, mas por que reinventar a roda? Afinal, já estamos reinventando a sintaxe.
Dados da turma
Exemplo de campos de dados de “classe” do GameObject:
struct GameObjectStruct {
struct sp1_ss *gameObjectSprite;
unsigned char *sprite_col;
unsigned char x;
unsigned char y;
unsigned char referenceCount;
unsigned char beforeHideX;
unsigned char beforeHideY;
};
typedef struct GameObjectStruct GameObject;
Salve nossa classe como “GameObject.h”, faça #include “GameObject.h” no lugar certo e use-a.
Métodos de classe
Levando em consideração a experiência dos desenvolvedores da linguagem Objective-C, a assinatura de um método de classe serão funções em escopo global, o primeiro argumento será sempre a estrutura de dados, seguido dos argumentos do método. Abaixo está um exemplo de “método” da “classe” GameObject:
void GameObject_hide(GameObject *gameObject) {
gameObject->beforeHideX = gameObject->x;
gameObject->beforeHideY = gameObject->y;
gameObject->y = 200;
}
A chamada do método é semelhante a esta:
GameObject_hide(gameObject);
Construtores e destruidores são implementados da mesma maneira. É possível implementar um construtor como alocador e inicializador de campo, mas prefiro controlar a alocação e inicialização de objetos separadamente.
Trabalhando com memória
Gerenciamento manual de memória do formulário usando malloc e free agrupados em macros novas e de exclusão para corresponder ao C++:
#define new(X) (X*)malloc(sizeof(X))
#define delete(X) free(X)
Para objetos que são usados por várias classes ao mesmo tempo, o gerenciamento de memória semi-manual é implementado com base na contagem de referências, à imagem e semelhança do antigo mecanismo ARC do Objective-C Runtime:
void GameObject_retain(GameObject *gameObject) {
gameObject->referenceCount++;
}
void GameObject_release(GameObject *gameObject) {
gameObject->referenceCount--;
if (gameObject->referenceCount < 1) { sp1_MoveSprAbs(gameObject->gameObjectSprite, &Renderer_fullScreenRect, NULL, 0, 34, 0, 0);
sp1_DeleteSpr(gameObject->gameObjectSprite);
delete(gameObject);
}
}
Assim, cada classe deve declarar o uso de um objeto compartilhado usando reter, liberando propriedade por meio de release. A versão moderna do ARC usa chamadas automáticas de retenção/liberação.
Som!
O Spectrum possui um tweeter capaz de reproduzir música de 1 bit; os compositores da época conseguiam reproduzir nele até 4 canais de som simultaneamente.
O Spectrum 128k contém um chip de som separado AY-3-8910, que pode reproduzir música rastreada.
Uma biblioteca é oferecida para usar o tweeter no z88dk
O que resta aprender
Eu estava interessado em conhecer o Spectrum, implementar o jogo usando o z88dk e aprender muitas coisas interessantes. Ainda tenho muito que aprender, por exemplo, o montador Z80, pois ele me permite usar toda a potência do Spectrum, trabalhar com bancos de memória e trabalhar com o chip de som AY-3-8910. Espero participar da competição no próximo ano!
Links
https://rgb.yandex
https://vk.com/sinc_lair
https://www.z88dk.org/forum/
Código fonte
https://gitlab.com/demensdeum/ zx-projects/tree/master/interceptor2020