Для отладки можно использовать VSCode и плагин TypeScript Debugger от kakumei.
src/bogosort.ts:1
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 8,7,0,2,4,7,2,5,9,5, try number: 145000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 7,5,2,4,9,8,0,5,2,7, try number: 146000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 0,2,7,4,9,5,7,5,8,2, try number: 147000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 5,9,7,8,5,4,2,7,0,2, try number: 148000
src/bogosort.ts:2
Success!
src/bogosort.ts:24
Run number: 148798
src/bogosort.ts:25
Original numbers: 5,4,8,7,5,0,2,9,7,2
src/bogosort.ts:26
Current numbers: 5,4,8,7,5,0,2,9,7,2
src/bogosort.ts:27
Sorted numbers: 0,2,2,4,5,5,7,7,8,9
Для массива из 10 чисел Богосорт перемешивал исходный массив 148798 раз, многовато да?
Алгоритм можно использовать как учебный, для понимания возможностей языка с которым предстоит работать на рынке. Лично я был удивлен узнав что в ванильных JS и TS до сих пор нет своего алгоритма перемешивания массивов, генерации целого числа в диапазоне, доступа к хэшам объектов для быстрого сравнения.
Ссылки
https://gitlab.com/demensdeum/algorithms/-/tree/master/sortAlgorithms/bogosort
https://www.typescriptlang.org/
https://marketplace.visualstudio.com/items?itemName=kakumei.ts-debug
Источники
https://www.youtube.com/watch?v=r2N3scbd_jg
https://en.wikipedia.org/wiki/Bogosort
包含什么
解释器模式是指行为设计模式。此模式允许您通过使用 AST 树来实现您自己的编程语言,该树的顶点是实现 Interpret 方法的终端和非终端表达式,该方法提供了该语言的功能。
- 终端表达式 – 例如,字符串常量 – “你好世界”
- 非终端表达式 – 例如 Print(“Hello World”),包含 Print 和来自终端表达式“Hello World”的参数
有什么区别?不同之处在于,解释在终端表达式上结束,但对于非终端表达式,它会在所有传入的顶点/参数上继续深入。如果 AST 树仅由非终结符表达式组成,那么应用程序将永远无法完成,因为任何过程都需要一定的有限性,这种有限性就是终端表达式,它们通常包含数据,例如字符串。
AST 树的示例如下:
Dcoetzee,CC0,来自维基共享资源
如您所见,终端表达式是常量和变量,其余的是非终端表达式。
不包括什么
解释器实现不包括解析输入到 AST 树中的语言字符串。实现终结符和非终结符表达式的类、在输入处使用 Context 参数的 Interpret 方法、创建表达式的 AST 树并在根表达式处运行 Interpret 方法就足够了。上下文可用于在运行时存储应用程序状态。
实施
该模式涉及:
- Client – 返回 AST 树并为根节点(Client)运行 Interpret(context)
- 上下文 – 包含应用程序的状态,在解释时传递给表达式(上下文)
- 抽象表达式 – 包含 Interpret(context) (Expression) 方法的抽象类
- 终端表达式是最终表达式,是抽象表达式 (TerminalExpression) 的后代
- 非终结表达式不是有限表达式;它包含指向 AST 树深处顶点的指针;下级顶点通常会影响非终结表达式 (NonTerminalExpression) 的解释结果
C# 中的客户端示例
static void Main(string[] args)
{
var context = new Context();
var initialProgram = new PerformExpression(
new IExpression[] {
new SetExpression("alpha", "1"),
new GetExpression("alpha"),
new PrintExpression(
new IExpression[] {
new ConstantExpression("Hello Interpreter Pattern")
}
)
}
);
System.Console.WriteLine(initialProgram.interpret(context));
}
}
C# 中的抽象表达式示例
{
String interpret(Context context);
}
C# 中的终端表达式示例(字符串常量)
{
private String constant;
public ConstantExpression(String constant) {
this.constant = constant;
}
override public String interpret(Context context) {
return constant;
}
}
C# 中非终结符表达式的示例(使用分隔符“;”开始并连接从属顶点的结果
{
public PerformExpression(IExpression[] leafs) : base(leafs) {
this.leafs = leafs;
}
override public String interpret(Context context) {
var output = "";
foreach (var leaf in leafs) {
output += leaf.interpret(context) + ";";
}
return output;
}
}
你能从功能上做到这一点吗?
众所周知,所有图灵完备的语言都是等价的。是否可以将面向对象模式转移到函数式编程语言?
作为实验,我们采用一种名为 Elm 的 FP 网络语言。 Elm中没有类,但是有Records和Types,因此实现中涉及到以下记录和类型:
- 表达式 – 列出所有可能的语言表达式(Expression)
- 从属表达式 – 从属于非终结符表达式 (ExpressionLeaf) 的表达式
- Context – 存储应用程序状态的记录(Context)
- 实现 Interpret(context) 方法的函数 – 实现终端和非终端表达式功能的所有必要函数
- 解释器状态的辅助记录 – 解释器正确操作所必需的,它们存储解释器状态、上下文
在 Elm 中实现对整个可能表达式集的解释的函数示例:
case input.expression of
Constant text ->
{
output = text,
context = input.context
}
Perform leafs ->
let inputs = List.map (\leaf -> { expressionLeaf = leaf, context = input.context } ) leafs in
let startLeaf = { expressionLeaf = (Node (Constant "")), context = { variables = Dict.empty } } in
let outputExpressionInput = List.foldl mergeContextsAndRunLeafs startLeaf inputs in
{
output = (runExpressionLeaf outputExpressionInput).output,
context = input.context
}
Print printExpression ->
run
{
expression = printExpression,
context = input.context
}
Set key value ->
let variables = Dict.insert key value input.context.variables in
{
output = "OK",
context = { variables = variables }
}
Get key ->
{
output = Maybe.withDefault ("No value for key: " ++ key) (Dict.get key input.context.variables),
context = input.context
}
解析怎么样?
解释器模式中不包含将源代码解析为 AST 树;有多种解析源代码的方法,稍后会详细介绍。
在Elm解释器的实现中,我在AST树中编写了一个简单的解析器,由两个函数组成——解析顶点,解析从属顶点。
parseLeafs state =
let tokensQueue = state.tokensQueue in
let popped = pop state.tokensQueue in
let tokensQueueTail = tail state.tokensQueue in
if popped == "Nothing" then
state
else if popped == "Perform(" then
{
tokensQueue = tokensQueue,
result = (state.result ++ [Node (parse tokensQueue)])
}
else if popped == ")" then
parseLeafs {
tokensQueue = tokensQueueTail,
result = state.result
}
else if popped == "Set" then
let key = pop tokensQueueTail in
let value = pop (tail tokensQueueTail) in
parseLeafs {
tokensQueue = tail (tail tokensQueueTail),
result = (state.result ++ [Node (Set key value)])
}
else if popped == "Get" then
let key = pop tokensQueueTail in
parseLeafs {
tokensQueue = tail tokensQueueTail,
result = (state.result ++ [Node (Get key)])
}
else
parseLeafs {
tokensQueue = tokensQueueTail,
result = (state.result ++ [Node (Constant popped)])
}
parse tokensQueue =
let popped = pop tokensQueue in
let tokensQueueTail = tail tokensQueue in
if popped == "Perform(" then
Perform (
parseLeafs {
tokensQueue = tokensQueueTail,
result = []
}
).result
else if popped == "Set" then
let key = pop tokensQueueTail in
let value = pop (tail tokensQueueTail) in
Set key value
else if popped == "Print" then
Print (parse tokensQueueTail)
else
Constant popped
链接
https://gitlab.com/demensdeum /patterns/-/tree/master/interpreter/elm
https://gitlab.com/demensdeum/patterns/-/tree/master/interpreter/csharp
来源
https://en.wikipedia.org/wiki/Interpreter_pattern
https://elm-lang.org/
https://docs.microsoft.com/en-us/dotnet/csharp/
在这篇文章中,我将描述将 RGB 缓冲区转换为灰度(灰度)的算法。
这样做非常简单,缓冲区的每个像素颜色通道都根据一定的公式进行转换,输出是灰度图像。
平均法:
red = average;
green = average;
blue = average;
Складываем 3 цветовых канала и делим на 3.


Однако существует еще один метод – метод средневзвешенный, он учитывает цветовосприятие человека:
red = luminance;
green = luminance;
blue = luminance;

Какой метод лучше использовать? Да какой вам больше подходит для конкретной задачи. Далее сравнение методов с помощью тестовой цветовой сетки:



Пример реализации на JavaScript + HTML 5
image,
canvas,
weightedAverage
) {
const context = canvas.getContext('2d');
const imageWeight = image.width;
const imageHeight = image.height;
canvas.width = imageWeight;
canvas.height = imageHeight;
context.drawImage(image, 0, 0);
let pixels = context
.getImageData(
0,
0,
imageWeight,
imageHeight
);
for (let y = 0; y & lt; pixels.height; y++) {
for (let x = 0; x & lt; pixels.width; x++) {
const i = (y * 4) * pixels.width + x * 4;
let red = pixels.data[i];
let green = pixels.data[i + 1];
let blue = pixels.data[i + 2]
const average = (red + green + blue) / 3;
const luminance = 0.2126 * red +
0.7152 * green +
0.0722 * blue;
red = weightedAverage ? luminance : average;
green = weightedAverage ? luminance : average;
blue = weightedAverage ? luminance : average;
pixels.data[i] = red;
pixels.data[i + 1] = green;
pixels.data[i + 2] = blue;
}
}
context
.putImageData(
pixels,
0,
0,
0,
0,
pixels.width,
pixels.height
);
}
Источники
https://www.baeldung.com/cs/convert-rgb-to-grayscale
https://twitter.com/mudasobwa/status/1528046455587495940
https://rosettacode.org/wiki/Grayscale_image
Ссылки
http://papugi.demensdeum.repl.co/
Благодарности
Спасибо Aleksei Matiushkin (https://twitter.com/mudasobwa) за наводку на Rosetta Code
如果您在启动 CSGO 时在 Macbook M1 上收到 SDL_GetDesktopDisplayMode_REAL 错误,请按照以下说明进行操作。
1.为CSGO添加Steam启动选项:
-w 1440 -h 900 -全屏
2.通过Steam启动CSGO
3. 单击“忽略”或“始终忽略”错误 SDL_GetDesktopDisplayMode_REAL
4.享受
https://www.youtube.com/watch?v=_DtsufsNUa0
我向您展示了艾伦·图灵文章《世界》第一页的翻译。 “关于可计算数字及其解决问题的应用” 1936年。第一章包含对计算机的描述,后来成为现代计算的基础。
文章的全文翻译和解释可以在美国普及者查尔斯·佩措尔德(Charles Petzold)所著的《读图灵》一书中阅读。浏览图灵关于可计算性和图灵机的里程碑式论文—— (ISBN 978-5-97060-231-7、978-0-470-22905-7)
原文:
https://www.astro.puc.cl/~rparra/tools/PAPERS/turing_1936.pdf
—
关于应用于解决问题的可计算数字
A. M·图灵
[1936 年 5 月 28 日收到 – 1936 年 11 月 12 日阅读]
可计算数可以简单地描述为实数,其小数形式的表达式可以通过有限多种方式计算。尽管乍一看本文将数字视为可计算的,但定义和探索整数变量、实数变量、可计算变量、可计算谓词等的可计算函数几乎同样容易。然而,与这些可计算对象相关的基本问题在每种情况下都是相同的。为了详细考虑,我选择可计算数字作为可计算对象,因为考虑它们的方法是最不麻烦的。我希望尽快描述可计算数与可计算函数的关系等等。同时,将在以可计算数表示的实变量函数理论领域进行研究。根据我的定义,如果机器可以写出小数形式的实数,那么该实数就是可计算的。
在第 9 段和第 10 段中,我给出了一些论据来表明可计算数包括所有自然被认为是可计算的数。特别是,我证明了一些大类数字是可计算的。例如,它们包括所有代数数的实部、贝塞尔函数零点的实部、数字 π、e 等。但是,可计算数并不包括所有可定义数,如以下不可计算的可定义数示例所示。
尽管可计算数的类别非常大,并且在许多方面与实数的类别相似,但它仍然是可枚举的。在第 8 节中,我考虑了某些看似相反的论点。当其中一个论证得到正确应用时,乍一看,得出的结论与哥德尔*的结论相似。这些结果具有极其重要的应用。特别是如下图(§11)所示,分辨率问题无法解决。
Alonzo Church**在他最近的文章中介绍了“有效可计算性”的想法,这与我的“可计算性”的想法相当,但定义完全不同。关于解决问题,丘奇也得出了类似的结论。本文附录中给出了“可计算性”和“有效计算能力”等价性的证明。
1.计算机
我们已经说过,可计算数是那些小数位数可以通过有限方式计算的数。这里需要一个更清晰的定义。在我们到达第 9 节之前,本文不会真正尝试证明此处给出的定义的合理性。现在,我只想指出(这样做的)(逻辑)基本原理是人类的记忆必然是有限的。
让我们将计算实数的过程中的人与只能满足有限数量的条件 q1, q2, …, qR; 的机器进行比较。我们将这些条件称为“m 配置”。这台(即如此定义的)机器配备有“胶带”(类似于纸)。穿过机器的皮带被分成几段。我们称它们为“正方形”。每个这样的方块都可以包含某种“符号”。在任何时刻,只有一个这样的正方形,比如第 r 个,包含“在这台机器中”的符号。我们将这样的正方形称为“扫描符号”。可以说,“扫描字符”是机器“直接感知”的唯一字符。然而,通过改变它的 m 配置,机器可以有效地记住它之前“看到”(扫描过)的一些字符。机器在任何时刻可能的行为由 m 配置 qn 和扫描的符号***决定。我们将这对符号称为 qn,“配置”。由此指定的配置决定了给定机器的可能行为。在其中所扫描的方块是空白的(即,不包含字符)的一些配置中,机器在所扫描的方块上写入新字符,而在这些配置中的其他配置中,机器擦除所扫描的字符。这台机器也能够移动来扫描另一个方格,但这样它只能移动到右侧或左侧的相邻方格。除了这些操作之外,还可以更改机器的 m 配置。在这种情况下,一些写入的字符将形成一个数字序列,这是正在计算的实数的小数部分。其余的无非是为了“帮助记忆”而做的不准确的标记。这种情况下,只能擦除上述不准确的标记。
我声称这里考虑的操作包括所有计算中使用的操作。对于了解机器理论的读者来说,这种说法的基本原理更容易理解。因此,在下一节中,我将在理解“机器”、“磁带”、“扫描”等术语的基础上继续发展相关理论。
*哥德尔“论数学原理中的形式上不可判定的句子(由怀特海和罗素于 1910 年、1912 年和 1913 年出版)和相关系统,第一部分”,《数学杂志》。物理学,德文月刊第 38 期(1931 年,第 173-198 页。
** Alonzo Church,“初等数论中的一个不可判定问题”,American J. of Math.,第 58 期 (1936),第 345-363 页。
*** Alonzo Church,“关于解决问题的注释”,J. of Symbolic Logic,第 1 期(1936 年),第 40-41 页
https://youtube.com/playlist?list=PLJLxLMyDiWkrlV-NuWXWe7t404_fhoDsV
https://youtube.com/playlist?list=PLJLxLMyDiWkqwaWqHJQWiy7a2e9c5MyQO
1936 年,科学家艾伦·图灵在他的出版物《论可计算数,及其在解决问题中的应用》中描述了通用计算机的使用,它可以解决数学中的可解性问题。结果,他得出的结论是,如果这种机器的工作结果被颠倒并循环回自身,那么它就无法正确解决任何问题。事实证明,不可能创建一个“理想的”防病毒软件、一个“理想的”磁贴设置器、一个为您的崩溃建议理想短语的程序等等。悖论!
然而,这种通用计算机可以用来实现任何算法,英国情报部门利用了这一点,雇佣了图灵并允许创建“Bombe”机器来破译第二次世界大战期间的德国信息。
以下是基于原始文档,使用 Dart 语言对单磁带计算机进行 OOP 建模。
图灵机由分成多个部分的薄膜组成,每个部分包含一个符号,这些符号可以读取或写入。电影类示例:
final _map = Map<int, String>();
String read({required int at}) {
return _map[at] ?? "";
}
void write({required String symbol, required int at}) {
_map[at] = symbol;
}
}
还有一个“扫描方块”,它可以在胶片上移动,读取或写入信息,用现代语言来说就是——磁头。磁头类示例:
int _index = 0;
InfiniteTape _infiniteTape;
TapeHead(this._infiniteTape) {}
String next() {
_index += 1;
move(to: _index);
final output = read();
return output;
}
String previous() {
_index -= 1;
move(to: _index);
final output = read();
return output;
}
void move({required int to}) {
this._index = to;
}
String read() {
return _infiniteTape.read(at: this._index);
}
void write(String symbol) {
_infiniteTape.write(symbol: symbol, at: this._index);
}
int index() {
return _index;
}
}
机器包含“m-configurations”,通过它可以决定下一步做什么。用现代语言来说——状态和状态处理程序。状态处理程序示例:
FiniteStateControlDelegate? delegate = null;
void handle({required String symbol}) {
if (symbol == OPCODE_PRINT) {
final argument = delegate?.nextSymbol();
print(argument);
}
else if (symbol == OPCODE_GENERATE_RANDOM_NUMBER_FROM_ZERO_TO_AND_WRITE_AFTER) {
final to = int.tryParse(delegate!.nextSymbol())!;
final value = new Random().nextInt(to);
delegate!.nextSymbol();
delegate!.write(value.toString());
}
else if (symbol == OPCODE_INPUT_TO_NEXT) {
final input = stdin.readLineSync()!;
delegate?.nextSymbol();
delegate?.write(input);
}
else if (symbol == OPCODE_COPY_FROM_TO) {
final currentIndex = delegate!.index();
и т.д.
之后,您需要创建“配置”,用现代语言来说,这些是操作代码(操作码)及其处理程序。操作码示例:
const OPCODE_PRINT = "print";
const OPCODE_INCREMENT_NEXT = "increment next";
const OPCODE_DECREMENT_NEXT = "decrement next";
const OPCODE_IF_PREVIOUS_NOT_EQUAL = "if previous not equal";
const OPCODE_MOVE_TO_INDEX = "move to index";
const OPCODE_COPY_FROM_TO = "copy from index to index";
const OPCODE_INPUT_TO_NEXT = "input to next";
const OPCODE_GENERATE_RANDOM_NUMBER_FROM_ZERO_TO_AND_WRITE_AFTER = "generate random number from zero to next and write after";
不要忘记创建操作码和停止处理程序,否则您将无法证明或无法证明(原文如此!)解决问题。
现在,使用“中介者”模式,我们连接图灵机类中的所有类,创建该类的实例,通过磁带录音机录制程序,加载磁带就可以使用它了!
对我个人来说,什么是主要的问题仍然很有趣——“什么是主要的”?创建通用计算器或“Entscheidungsproblem”的证明,作为副产品,计算器出现了。
盒式磁带
为了好玩,我为我的机器版本录制了几个盒式磁带节目。
你好世界
hello world
stop
Считаем до 16-ти
在这篇文章中,我将描述读取操纵杆、更改精灵位置、水平翻转、Sega Genesis 模拟器以及可能的控制台本身的过程。
读取点击并处理将棋操纵杆的“事件”按照以下方案进行:
- 请求按下按钮的位组合
- 读取按下的按钮的位
- 游戏逻辑级别的处理
要移动骨架精灵,我们需要存储当前位置的变量。
内存
游戏逻辑变量存储在RAM中;到目前为止人们还没有想出更好的办法。让我们声明变量地址并更改渲染代码:
skeletonYpos = $FF0002
frameCounter = $FF0004
skeletonHorizontalFlip = $FF0006
move.w #$0100,skeletonXpos
move.w #$0100,skeletonYpos
move.w #$0001,skeletonHorizontalFlip
FillSpriteTable:
move.l #$70000003,vdp_control_port
move.w skeletonYpos,vdp_data_port
move.w #$0F00,vdp_data_port
move.w skeletonHorizontalFlip,vdp_data_port
move.w skeletonXpos,vdp_data_port
如您所见,可用于工作的地址从 0xFF0000 开始,到 0xFFFFFF 结束,总共有 64 KB 的内存可供我们使用。骨架位置在 sculptureXpos、sculptureYpos 处声明,水平翻转在 sculptureHorizontalFlip 处声明。
手柄
与 VDP 类比,游戏手柄的工作分别通过两个端口进行:控制端口和数据端口,第一个为0xA10009和0xA10003共号。使用游戏手柄时有一个有趣的功能——首先,您需要请求用于轮询的按钮组合,然后在等待总线上的更新后,读取所需的按键。对于 C/B 和 D-pad 按钮,这是 0x40,示例如下:
move.b #$40,joypad_one_control_port; C/B/Dpad
nop ; bus sync
nop ; bus sync
move.b joypad_one_data_port,d2
rts
在寄存器 d2 中,按钮按下或未按下的状态将保留,一般来说,通过日期端口请求的内容将保留。之后,转到您最喜欢的模拟器的 Motorola 68000 寄存器查看器,根据击键查看 d2 寄存器等于什么。您可以通过聪明的方式在手册中找到答案,但我们并不相信他们的话。进一步处理 d2
寄存器中按下的按钮
cmp #$FFFFFF7B,d2; handle left
beq MoveLeft
cmp #$FFFFFF77,d2; handle right
beq MoveRight
cmp #$FFFFFF7E,d2; handle up
beq MoveUp
cmp #$FFFFFF7D,d2; handle down
beq MoveDown
rts
Проверять нужно конечно отдельные биты, а не целыми словами, но пока и так сойдет. Теперь осталось самое простое – написать обработчики всех событий перемещения по 4-м направлениям. Для этого меняем переменные в RAM, и запускаем процедуру перерисовки.
Пример для перемещения влево + изменение горизонтального флипа:
move.w skeletonXpos,d0
sub.w #1,d0
move.w d0,skeletonXpos
move.w #$0801,skeletonHorizontalFlip
jmp FillSpriteTable
После добавления всех обработчиков и сборки, вы увидите как скелет перемещается и поворачивается по экрану, но слишком быстро, быстрее самого ежа Соника.
Не так быстро!
Чтобы замедлить скорость игрового цикла, существуют несколько техник, я выбрал самую простую и не затрагивающую работу с внешними портами – подсчет цифры через регистр пока она не станет равна нулю.
Пример замедляющего цикла и игрового цикла:
move.w #512,frameCounter
WaitFrame:
move.w frameCounter,d0
sub.w #1,d0
move.w d0,frameCounter
dbra d0,WaitFrame
GameLoop:
jsr ReadJoypad
jsr HandleJoypad
jmp GameLoop
此后,骨架运行速度变慢,这正是所需要的。据我所知,“放慢速度”的最常见选项是计算垂直同步标志;您可以计算屏幕被绘制的次数,从而与特定的 fps 相关联。
链接
https://gitlab .com/demensdeum/segagenesisamples/-/blob/main/8Joypad/vasm/main.asm
来源
https://www.chibiakumas.com/68000/platform2.php
https://huguesjohnson.com/programming/genesis/tiles-sprites/
在这篇文章中,我将介绍如何使用 Sega Genesis 控制台的 VDP 模拟器绘制精灵。
渲染精灵的过程与渲染图块非常相似:
- 将颜色加载到 CRAM
- 将部分精灵 8×8 上传到 VRAM
- 在 VRAM 中填充精灵表
例如,让我们取一个带有剑的骷髅精灵,大小为 32×32 像素

Skeleton Guy [Animated] by Disthorn
CRAM
使用 ImaGenesis,我们将其转换为用于汇编程序的 CRAM 颜色和 VRAM 模式。之后,我们将得到两个asm格式的文件,然后我们将颜色重写为字大小,并且图块必须按照正确的顺序放置才能绘制。
有趣的信息:您可以通过 0xF 寄存器将 VDP 自动递增切换为字大小,这将从 CRAM 颜色填充代码中删除地址增量。
显存
将棋手册对于大精灵有正确的图块顺序,但我们更聪明,所以我们将从博客中获取索引ChibiAkumas,让我们从索引 0 开始计数:
0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
为什么一切都是颠倒的?你想要什么,控制台是日本的!甚至可以从右到左!
让我们手动更改 asm sprite 文件中的顺序:
dc.l $11111111 ; Tile #0
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111 ; Tile #4
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111 ; Tile #8
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111122
dc.l $11111122
dc.l $11111166
dc.l $11111166 ; Tile #12
dc.l $11111166
dc.l $11111166
и т.д.
像常规图块/图案一样加载精灵:
lea Sprite,a0
move.l #$40200000,vdp_control_port; write to VRAM command
move.w #128,d0 ; (16*8 rows of sprite) counter
SpriteVRAMLoop:
move.l (a0)+,vdp_data_port;
dbra d0,SpriteVRAMLoop
要绘制精灵,剩下的就是填写精灵表
精灵表
精灵表被填充在VRAM中,其所在位置的地址被输入到VDP寄存器0x05中,这个地址又很棘手,你可以在手册中看到它,地址F000的例子:
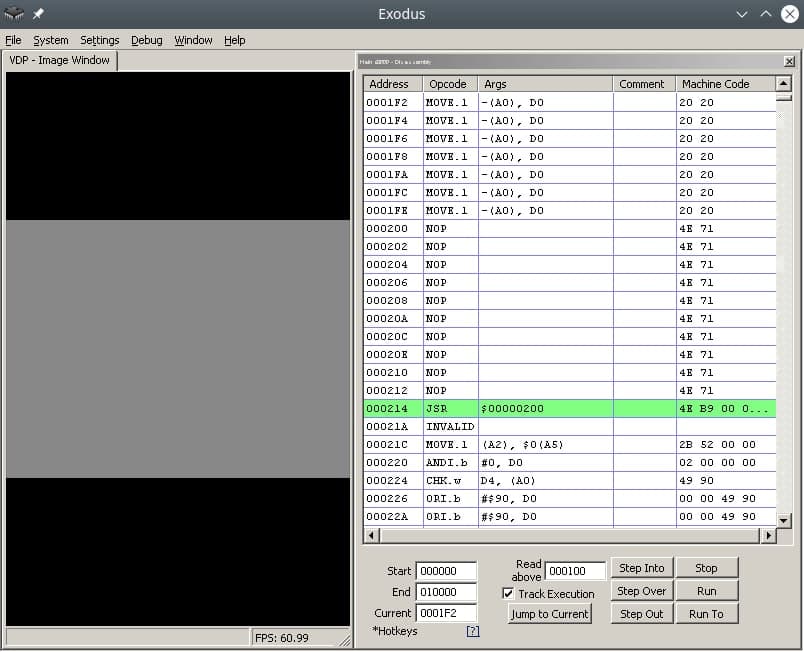
Ок, теперь запишем наш спрайт в таблицу. Для этого нужно заполнить “структуру” данных состоящую из четырех word. Бинарное описание структуры вы можете найти в мануале. Лично я сделал проще, таблицу спрайтов можно редактировать вручную в эмуляторе Exodus.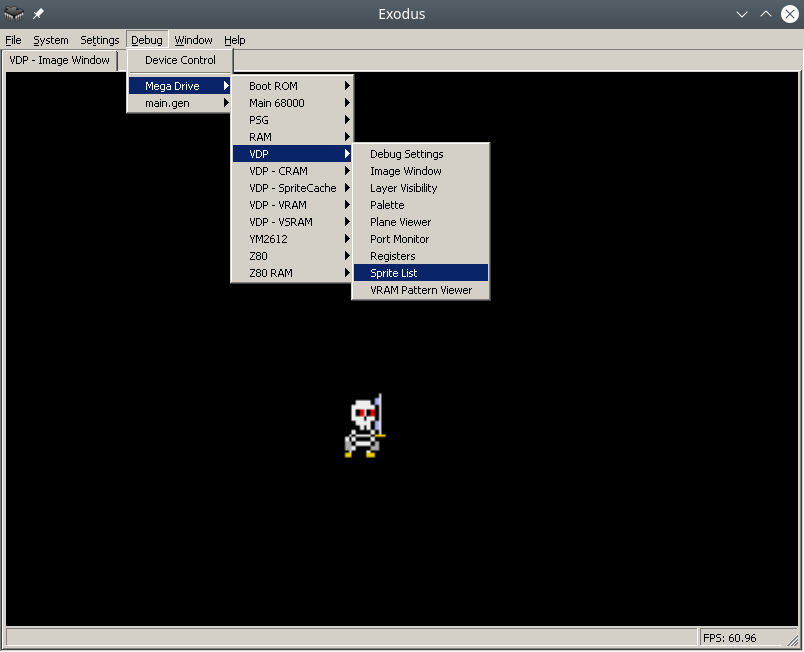
结构体参数从名字上就很明显了,例如XPos、YPos–坐标,瓷砖&#8211;绘制起始图块的编号、HSize、VSize –精灵尺寸通过添加第 8×8、HFlip、VFlip– 部分来实现。精灵水平和垂直的硬件旋转。
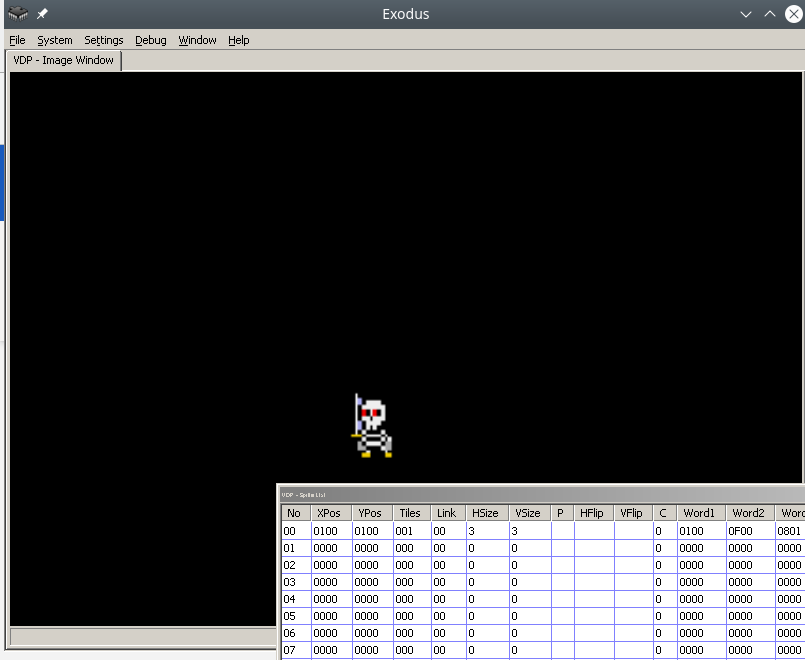
记住精灵可以离开屏幕非常重要,这是正确的行为,因为……从内存中卸载离屏精灵 –相当耗费资源的活动。
模拟器中填充数据后,需要从VRAM复制到地址0xF000,Exodus也支持此功能。
类比绘制图块,我们首先访问VDP控制端口从地址0xF000开始写入,然后将结构体写入数据端口。
让我提醒您,VRAM寻址的描述可以在手册或博客中阅读 无名算法 .
简而言之,VDP 寻址的工作原理如下:
[..DC BA98 7654 3210 …. …。 …。 ..FE]
其中 hex 是所需地址中的位位置。前两位是请求的命令类型,例如 01 –写入 VRAM。那么对于地址 0XF000 结果是:
0111 0000 0000 0000 0000 0000 0000 0011 (70000003)
结果我们得到代码:
move.l #$70000003,vdp_control_port
move.w #$0100,vdp_data_port
move.w #$0F00,vdp_data_port
move.w #$0001,vdp_data_port
move.w #$0100,vdp_data_port
之后,骨骼精灵将显示在坐标 256, 256 处。很酷吧?
链接
https://gitlab.com/demensdeum /segagenesissamples/-/tree/main/7Sprite/vasm
https://opengameart.org/content/skeleton-guy-animated
来源
https://namelessalgorithm.com/genesis/blog/vdp/
https://www.chibiakumas.com/68000/platform3.php#LessonP27
https://plutiedev.com/sprites
在这篇文章中,我将描述如何使用汇编程序在 Sega Genesis 模拟器上显示图块中的图像。
Exodus 模拟器中的 Demens Deum 初始图像将如下所示:
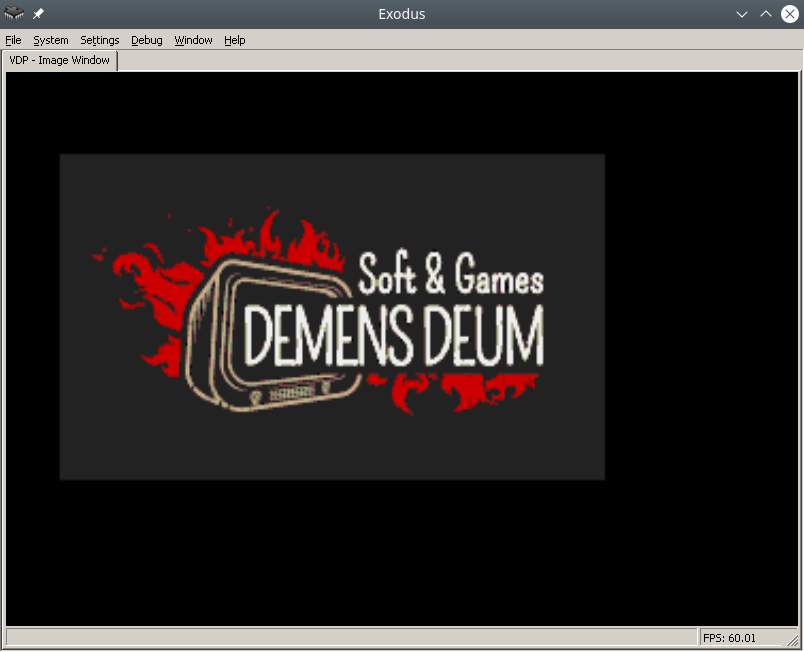
使用图块输出PNG图像的过程是逐步完成的:
- 将图像缩小到将棋屏幕的大小
- 将 PNG 转换为汇编数据代码,分为颜色和图块
- 将调色板加载到 CRAM
- 将图块/图案加载到 VRAM
- 加载 VRAM 中平面 A/B 地址处的切片索引
- 您可以使用您最喜欢的图形编辑器(例如 Blender)将图像缩小到将棋屏幕的大小。
PNG 转换
要转换图像,可以使用ImaGenesis工具在wine下工作;需要Visual Basic 6库,可以使用winetricks (winetricks vb6run)安装,或者可以从网上下载RICHTX32.OCX并放在正确操作的应用程序文件夹。
在 ImaGenesis 中,您需要选择 4 位颜色,将颜色和图块导出到两个汇编格式文件。接下来,在带有颜色的文件中,您需要将每种颜色放入一个单词(2 个字节)中,为此您使用 dc.w 操作码。
例如 CRAM 启动屏幕:
dc.w $0000
dc.w $0000
dc.w $0222
dc.w $000A
dc.w $0226
dc.w $000C
dc.w $0220
dc.w $08AA
dc.w $0446
dc.w $0EEE
dc.w $0244
dc.w $0668
dc.w $0688
dc.w $08AC
dc.w $0200
dc.w $0000
保持图块文件不变,它已经包含了正确的加载格式。部分图块文件的示例:
dc.l $11111111 ; Tile #0
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111 ; Tile #1
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
dc.l $11111111
正如您从上面的示例中看到的,图块是由 CRAM 调色板索引组成的 8×8 网格。
CRAM 中的颜色
通过将颜色加载命令设置到控制端口(vdp 控制)中的特定 CRAM 地址来完成加载到 CRAM 中。命令格式在Sega Genesis软件手册(1989)中有描述,我只是补充一下,您只需在地址中添加0x20000即可移动到下一个颜色。
接下来需要将颜色加载到数据端口(vdp数据);理解加载的最简单方法是使用下面的示例:
lea Colors,a0 ; pointer to Colors label
move.l #15,d7; colors counter
VDPCRAMFillLoopStep:
move.l d0,vdp_control_port ;
move.w (a0)+,d1;
move.w d1,(vdp_data_port);
add.l #$20000,d0 ; increment CRAM address
dbra d7,VDPCRAMFillLoopStep
VRAM 中的图块
接下来是将图块/图案加载到 VRAM 视频内存中。为此,请在 VRAM 中选择一个地址,例如 0x00000000。与 CRAM 类比,我们通过命令联系 VDP 控制端口以写入 VRAM 和起始地址。
此后,您可以将长字上传到VRAM;与CRAM相比,您不需要为每个长字指定地址,因为有VRAM自动递增模式。您可以使用 VDP 寄存器标志 0x0F (dc.b $02) 启用它
lea Tiles,a0
move.l #$40200000,vdp_control_port; write to VRAM command
move.w #6136,d0 ; (767 tiles * 8 rows) counter
TilesVRAMLoop:
move.l (a0)+,vdp_data_port;
dbra d0,TilesVRAMLoop
平面 A/B 中的平铺索引
现在我们必须根据瓷砖的索引来填充屏幕。为此,VRAM 被填充到平面 A/B 地址,该地址被输入到 VDP 寄存器(0x02、0x04)中。有关棘手寻址的更多信息,请参见 Sega 的手册;在我的示例中,VRAM 地址是 0xC000,让我们将索引上传到那里。
无论如何,您的图像都会填充屏幕外的 VRAM 空间,因此在绘制屏幕空间后,您的渲染器应该停止绘制,并在光标移动到新行时再次继续。如何实现这一点有很多选择;我使用了最简单的版本,即对图像宽度计数器和光标位置计数器的两个寄存器进行计数。
代码示例:
move.w #0,d0 ; column index
move.w #1,d1 ; tile index
move.l #$40000003,(vdp_control_port) ; initial drawing location
move.l #2500,d7 ; how many tiles to draw (entire screen ~2500)
imageWidth = 31
screenWidth = 64
FillBackgroundStep:
cmp.w #imageWidth,d0
ble.w FillBackgroundStepFill
FillBackgroundStep2:
cmp.w #imageWidth,d0
bgt.w FillBackgroundStepSkip
FillBackgroundStep3:
add #1,d0
cmp.w #screenWidth,d0
bge.w FillBackgroundStepNewRow
FillBackgroundStep4:
dbra d7,FillBackgroundStep ; loop to next tile
Stuck:
nop
jmp Stuck
FillBackgroundStepNewRow:
move.w #0,d0
jmp FillBackgroundStep4
FillBackgroundStepFill:
move.w d1,(vdp_data_port) ; copy the pattern to VPD
add #1,d1
jmp FillBackgroundStep2
FillBackgroundStepSkip:
move.w #0,(vdp_data_port) ; copy the pattern to VPD
jmp FillBackgroundStep3
之后,剩下的就是使用 vasm 组装 rom,启动模拟器,然后查看图片。
调试
并不是所有事情都能立即解决,所以我想推荐以下 Exodus 模拟器工具:
- M68k 处理器调试器
- 更改 m68k 处理器周期数(针对调试器中的慢动作模式)
- 查看器 CRAM、VRAM、平面 A/B
- 仔细阅读 m68k 的文档、所使用的操作码(并非所有内容都像乍一看那么明显)
- 在 github 上查看游戏代码/反汇编示例
- 实现处理器异常的子例程并进行处理
指向处理器异常子例程的指针放置在 ROM 标头中;GitHub 上还有一个带有 Sega 交互式运行时调试器的项目,称为 genesis-debugger。
使用所有可用的工具,进行良好的老式编码,并且Blast Processing可能会与您同在!
链接
https://gitlab.com/demensdeum /segagenesisamples/-/tree/main/6Image/vasm
http://devster.monkeeh.com/sega/imagenesis/
https://github.com/flamewing/genesis-debugger
来源
https://www.chibiakumas.com/68000/helloworld .php#LessonH5
https://huguesjohnson.com/programming/genesis/tiles-sprites/
在这篇文章中,我将描述如何使用汇编语言将颜色加载到将棋调色板中。
Exodus 模拟器中的最终结果将如下所示:
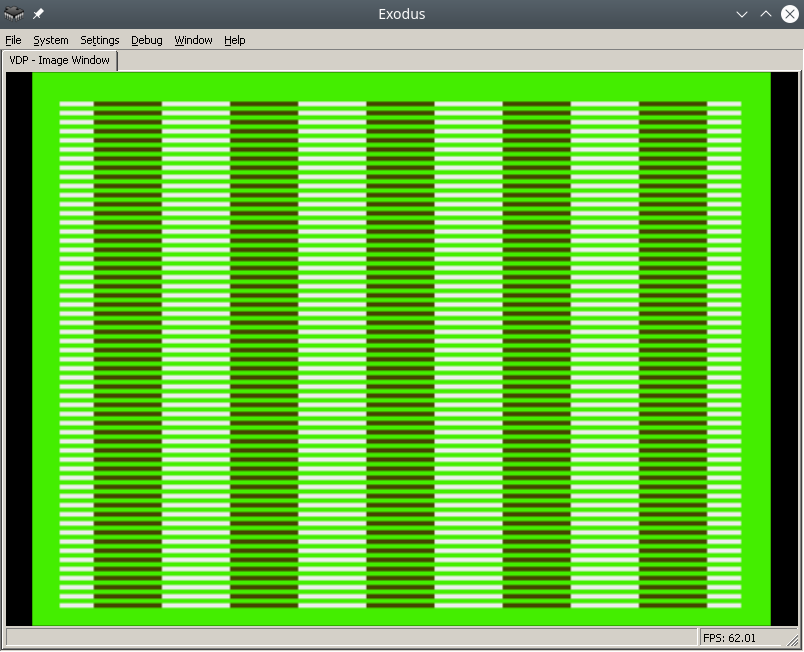
为了让这个过程更简单,在网上找到了一个pdf,叫做Genesis Software Manual (1989),它非常详细地描述了整个过程,实际上,这个说明是对原始手册的注释。< /p>
为了将颜色写入Sega模拟器的VDP芯片,您需要执行以下操作:
- 停用 TMSS 保护
- 将正确的参数写入VDP寄存器
- 将所需的颜色写入CRAM
对于组装,我们将使用 vasmm68k_mot 和最喜欢的文本编辑器,例如 echo。使用以下命令进行组装:
Порты VDP
VDP чип общается с M68K через два порта в оперативной памяти – порт контроля и порт данных.
По сути:
- Через порт контроля можно выставлять значения регистрам VDP.
- Также порт контроля является указателем на ту часть VDP (VRAM, CRAM, VSRAM etc.) через которую передаются данные через порт данных
Интересная информация: Сега сохранила совместимость с играми Master System, на что указывает MODE 4 из мануала разработчика, в нем VDP переключается в режим Master System.
Объявим порты контроля и данных:
vdp_data_port = $C00000
Отключить систему защиты TMSS
Защита от нелицензионных игр TMSS имеет несколько вариантов разблокировки, например требуется чтобы до обращения к VDP в адресном регистре A1 лежала строка “SEGA”.
MOVE.B A1,D0; Получаем версию хардвары цифрой из A1 в регистр D0
ANDI.B 0x0F,D0; По маске берем последние биты, чтобы ничего не сломать
BEQ.B SkipTmss; Если версия равна 0, скорее всего это японка или эмулятор без включенного TMSS, тогда идем в сабрутину SkipTmss
MOVE.L "SEGA",A1; Или записываем строку SEGA в A1
将正确的参数写入VDP寄存器
为什么要在 VDP 寄存器中设置正确的参数?我们的想法是,VDP 可以做很多事情,因此在渲染之前,您需要使用必要的功能对其进行初始化,否则它根本无法理解他们想要从中得到什么。
每个寄存器负责特定的设置/操作模式。 Segov 手册指出了 24 个寄存器中每个寄存器的所有位/标志,以及寄存器本身的描述。
让我们采用现成的参数以及来自 bigevilcorporation 博客的评论:
VDPReg0: dc.b $14 ; 0: H interrupt on, palettes on
VDPReg1: dc.b $74 ; 1: V interrupt on, display on, DMA on, Genesis mode on
VDPReg2: dc.b $30 ; 2: Pattern table for Scroll Plane A at VRAM $C000
; (bits 3-5 = bits 13-15)
VDPReg3: dc.b $00 ; 3: Pattern table for Window Plane at VRAM $0000
; (disabled) (bits 1-5 = bits 11-15)
VDPReg4: dc.b $07 ; 4: Pattern table for Scroll Plane B at VRAM $E000
; (bits 0-2 = bits 11-15)
VDPReg5: dc.b $78 ; 5: Sprite table at VRAM $F000 (bits 0-6 = bits 9-15)
VDPReg6: dc.b $00 ; 6: Unused
VDPReg7: dc.b $00 ; 7: Background colour - bits 0-3 = colour,
; bits 4-5 = palette
VDPReg8: dc.b $00 ; 8: Unused
VDPReg9: dc.b $00 ; 9: Unused
VDPRegA: dc.b $FF ; 10: Frequency of Horiz. interrupt in Rasters
; (number of lines travelled by the beam)
VDPRegB: dc.b $00 ; 11: External interrupts off, V scroll fullscreen,
; H scroll fullscreen
VDPRegC: dc.b $81 ; 12: Shadows and highlights off, interlace off,
; H40 mode (320 x 224 screen res)
VDPRegD: dc.b $3F ; 13: Horiz. scroll table at VRAM $FC00 (bits 0-5)
VDPRegE: dc.b $00 ; 14: Unused
VDPRegF: dc.b $02 ; 15: Autoincrement 2 bytes
VDPReg10: dc.b $01 ; 16: Vert. scroll 32, Horiz. scroll 64
VDPReg11: dc.b $00 ; 17: Window Plane X pos 0 left
; (pos in bits 0-4, left/right in bit 7)
VDPReg12: dc.b $00 ; 18: Window Plane Y pos 0 up
; (pos in bits 0-4, up/down in bit 7)
VDPReg13: dc.b $FF ; 19: DMA length lo byte
VDPReg14: dc.b $FF ; 20: DMA length hi byte
VDPReg15: dc.b $00 ; 21: DMA source address lo byte
VDPReg16: dc.b $00 ; 22: DMA source address mid byte
VDPReg17: dc.b $80 ; 23: DMA source address hi byte,
; memory-to-VRAM mode (bits 6-7)
好的,现在让我们进入控制端口并将所有标志写入 VDP 寄存器:
move.l #VDPRegisters,a0 ; Пишем адрес таблицы параметров в A1
move.l #$18,d0 ; Счетчик цикла - 24 = 18 (HEX) в D0
move.l #$00008000,d1 ; Готовим команду на запись в регистр VDP по индексу 0, по мануалу - 1000 0000 0000 0000 (BIN) = 8000 (HEX)
FillInitialStateForVDPRegistersLoop:
move.b (a0)+,d1 ; Записываем в D1 итоговое значение регистра VDP из таблицы параметров, на отправку в порт контроля VDP
move.w d1,vdp_control_port ; Отправляем итоговую команду + значение из D1 в порт контроля VDP
add.w #$0100,d1 ; Поднимаем индекс регистра VDP на 1 (бинарное сложение +1 к индексу по мануалу Сеги)
dbra d0,FillInitialStateForVDPRegistersLoop ; Уменьшаем счетчик регистров, продолжаем цикл если необходимо
Самое сложное это прочитать мануал и понять в каком формате подаются данные на порт контроля, опытные разработчики разберутся сразу, а вот неопытные… Немного подумают и поймут, что синтаксис для записи регистров такой:
0B100(5 бит – индекс регистра)(8 бит/байт – значение)
0B1000001001000101 – записать в регистр VDP 2 (00010), значение флажков 01000101.
Записать нужные цвета в CRAM
Далее идем писать два цвета в память цветов CRAM (Color RAM). Для этого пишем в порт контроля команду на доступ к цвету по индексу 0 в CRAM и отправляем по дата порту цвет. Все!
Пример:
move.l #$C0000000,vdp_control_port ; Доступ к цвету по индексу 0 в CRAM через порт контроля
move.w #228,d0; Цвет в D0
move.w d0,vdp_data_port; Отправляем цвет в порт данных
在 Exodus 的模拟器中构建并运行后,您的屏幕应填充颜色 228。
让我们根据最后一个字节 127 用第二种颜色填充它。
<代码>
move.l #$C07f0000,vdp_control_port ; Доступ к цвету по байту 127 в CRAM через порт контроля
move.w #69,d0; Цвет в D0
move.w d0,vdp_data_port; Отправляем цвет в порт данных
链接
https://gitlab.com/demensdeum/segagenesissamples
https://www.exodusemulator.com/
http://sun.hasenbraten.de/vasm/
https://tomeko.net/online_tools/bin_to_32bit_hex.php?lang=en
来源
https://namelessalgorithm.com/genesis/blog/genesis/
https://plutiedev.com/vdp-commands
https://huguesjohnson.com/programming/genesis/palettes/
https://www.chibiakumas.com/68000/helloworld.php#LessonH5
https://blog.bigevilcorporation.co.uk/2012/03/09/sega-megadrive-3-awaking-the-beast/
第一篇专门为 Motorola 68000 Assembly 中的经典 Sega Genesis 控制台编写游戏的文章。
让我们为 Sega 编写最简单的无限循环。为此,我们需要:一个汇编器、一个带有反汇编器的模拟器、一个最喜欢的文本编辑器、对 Sega rum 结构的基本了解。
对于开发,我使用自己的汇编器/反汇编器 Gen68KryBaby:
https://gitlab.com/demensdeum/gen68krybaby/
该工具是用 Python 3 开发的,用于汇编时提供扩展名为 .asm 或 .gen68KryBabyDisasm 的文件作为输入,输出是扩展名为 .gen68KryBabyAsm.bin 的文件,该文件可以在模拟器或计算机上运行一个真正的控制台(小心,走开,控制台可能会爆炸!)
还支持反汇编 rom,为此您需要提交一个 rom 文件作为输入,不带 .asm 或 .gen68KryBabyDisasm 扩展名。操作码支持将根据我对该主题的兴趣和贡献者的参与而增加或减少。
结构
Sega ROM 标头占据前 512 个字节。它包含有关游戏、名称、支持的外围设备、校验和以及其他系统标志的信息。我认为如果没有标题,控制台甚至不会看朗姆酒,认为它是不正确的,并说“你在这里给我什么?”
标头之后是子例程/重置子例程,这是 m68K 处理器开始工作的地方。好吧,这是一件小事……查找操作码(操作码),即什么都不做(!)并切换到内存中地址处的子程序。通过谷歌搜索,您可以找到 NOP 操作码,它不执行任何操作,以及 JSR 操作码,它执行无条件跳转到参数地址,也就是说,它只是将回车移动到我们要求的位置,没有任何突发奇想。
将它们放在一起
ROM 的标头捐赠者是 Beta 版本中的游戏之一,目前记录为十六进制数据。
00 ff 2b 52 00 00 02 00 00 00 49 90 00 00 49 90 00 00 49 90 00...и т.д.
Код программы со-но представляет из себя объявление сабрутины Reset/EntryPoint в 512 (0x200) байте, NOP, возврат каретки к 0x00000200, таким образом мы получим бесконечный цикл.
Ассемблерный код сабрутины Reset/EntryPoint:
NOP
NOP
NOP
NOP
NOP
JSR 0x00000200
完整示例以及 rom 标头:
https://gitlab.com /demensdeum/segagenesisamples/-/blob/main/1InfiniteLoop/1infiniteloop.asm
我们接下来收集:
我向您介绍火焰钢发动机转轮&#8211;用于启动基于 Flame Steel Engine 工具包的多媒体应用程序的平台。支持的平台有 Windows、MacOS、Linux、Android、iOS、HTML 5。应用程序代码开发的重点已转向脚本编写目前,已经使用TinyJS添加了对JavaScript的支持;工具包和引擎本身将继续使用接近硬件的语言(C、C++、Rust等)进行开发

在下面的页面上,您可以旋转立方体,用 JavaScript 编写代码,使用“上传文件”按钮上传模型、声音、音乐和代码,并使用“运行”按钮从 main.js 文件开始。
https://demensdeum.com/demos/FlameSteelEngineRunner/
我向您展示一个用于合并脚本文件的实用程序– KleyMoment,也是一个用于将文件重新粘在一起的反向实用程序。该实用程序可用于将 JavaScript 文件合并为一个。
该工具是用 Python 3 实现的,有一个简单的命令行界面,如:
<前>python3 KleyMoment.py 文件扩展目录ContainingFiles 输出文件
例如,递归地将scripts目录下的js文件合并到output.js文件中
<前>python3 KleyMoment.py js脚本output.js
AntiKleyMoment 也是一个用于将文件粘贴在一起的实用程序,它采用粘合文件作为输入,例如:
<前>python3 AntiKleyMoment.py 输出.js
存储库:
https://gitlab.com/demensdeum/kleymoment/
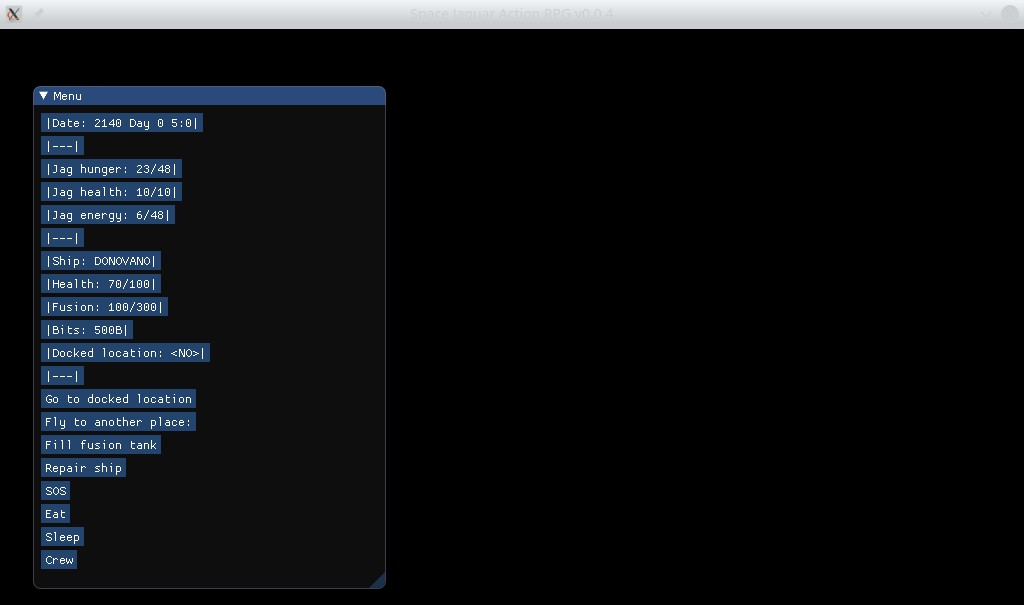
Web assembly 的 Space Jaguar 动作 RPG 游戏的第一个原型:

加载时间较长(53MB)且没有加载指示。
太空美洲虎动作角色扮演游戏太空海盗的生活模拟器。目前,可以使用最简单的游戏机制:
- 遨游太空
- 死
- 吃
- 睡觉
- 聘请团队
- 看那不停歇、飞逝的时间流
由于网页版3D场景渲染优化不佳,无法在3D环境中行走。后续版本会增加优化。
引擎、游戏和脚本的源代码可根据 MIT 许可证获得。所有改进建议都得到了非常积极的回应:
https://gitlab.com/demensdeum/space-jaguar -动作RPG
Linux 本机版本的屏幕截图:
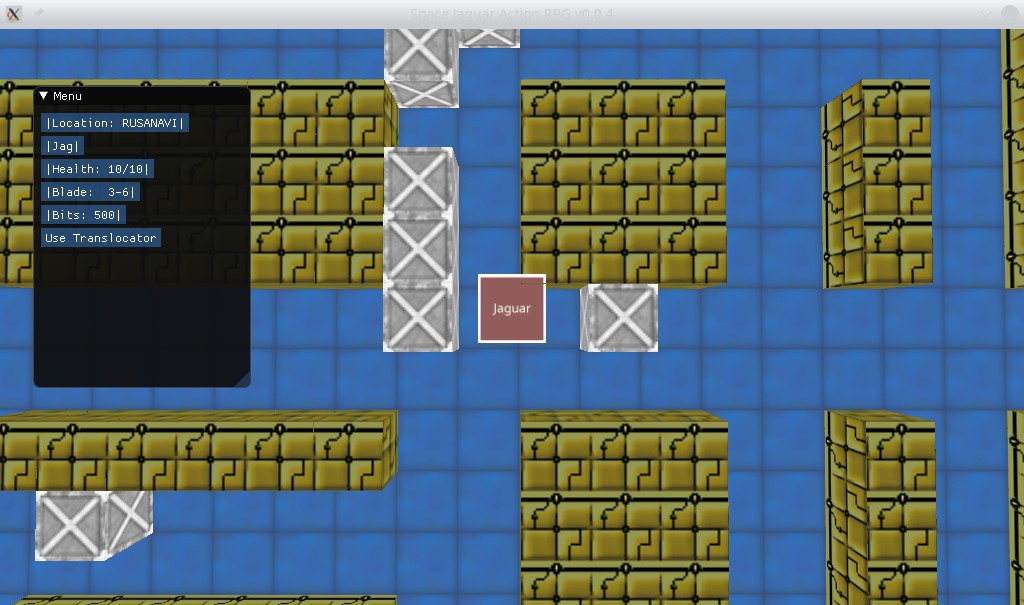
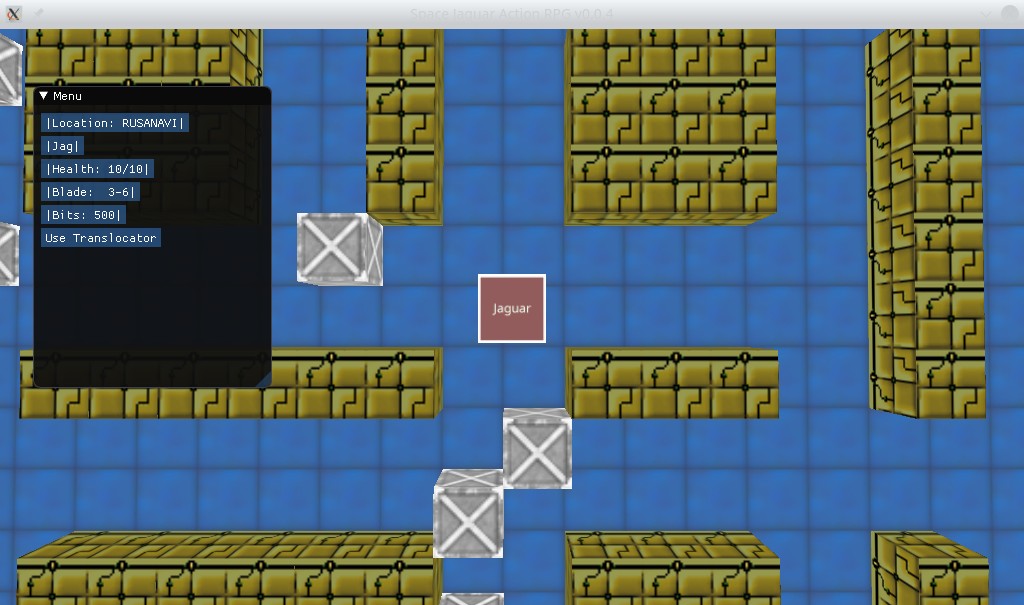
在这篇文章中,我将阐述在开发、支持应用程序以及在团队开发环境中架构决策的重要性。

自助手术餐巾 Lucifer Gorgonzola 教授。鲁布·戈德堡
在我年轻的时候,我曾开发过一个出租车叫车应用程序。在该程序中,您可以选择上车点、下车点,计算行程成本、关税类型,甚至预订出租车。我在预发布的最后阶段收到了该应用程序;在添加了一些修复后,该应用程序已在 AppStore 中发布。到了那个阶段,整个团队就明白它的实现很差,没有使用设计模式,系统的所有组件都是紧密相连的,一般来说,可以把它写成一个大的连续类(上帝对象),一切都不会改变,所以阶级如何混淆了它们的责任界限,并且在它们的总体质量上,彼此重叠,形成死耦合。后来,管理层决定使用正确的架构从头开始编写应用程序,最终产品已实现并应用于数十个 B2B 客户。
但是,我会描述过去建筑中的一个奇怪的事件,我有时会在半夜惊醒一身冷汗,或者在中午突然想起并开始歇斯底里地大笑。问题是我第一次没能击中杆子上的家伙,这导致了大部分应用程序的失败,但首先是最重要的事情。
这是一个普通的工作日,其中一位客户收到了一项任务,需要稍微完善应用程序设计–将接送地址选择屏幕中心的图标向上移动几个像素很简单。好吧,在专业地估计了 10 分钟的任务后,我将图标向上提升了 20 像素,完全没有怀疑,我决定检查出租车订单。
什么?该应用不再显示订单按钮?这是怎么发生的?
我简直不敢相信自己的眼睛;在将图标提高 20 像素后,应用程序停止显示继续订购按钮。回滚更改后,我再次看到了按钮。这里出了点问题。在调试器中花了 20 分钟后,我有点厌倦了对重叠类的调用的意大利面条,但我发现*移动图像确实改变了应用程序的逻辑*
这一切都是关于中心的图标–一个人在一根杆子上,当移动卡片时,他跳起来以动画相机的运动,这个动画之后底部的按钮消失了。显然程序认为移动了20像素的人是在跳跃,所以根据其内部逻辑隐藏了确认按钮。
怎么会发生这种事?屏幕的 *状态 *是否真的取决于状态机的模式,而是在杆上的位置 *表示?
事实证明,每次绘制地图时,应用程序 *目视戳*在屏幕中间,检查那里有什么,如果杆子上有一个人,则说明地图移动动画已经结束,需要显示按钮。如果该人不在那里,则地图会移动,并且该按钮必须被隐藏。
在上面的例子中,一切都很好,首先,它是 Goldberg Machines(深奥的机器)的一个例子,其次,这是一个开发人员不愿意以某种方式与团队中其他开发人员交互的例子(尝试在没有我),第三,您可以根据 SOLID、模式(代码异味)、MVC 违规等列出所有问题。
尽量不要这样做,向各个可能的方向发展,帮助同事的工作。大家新年快乐)
链接
https://ru.wikipedia.org/wiki/Goldberg_Machine
https://ru.wikipedia.org/wiki/SOLID
https://refactoring.guru/ru/refactoring/smells
https://ru.wikipedia.org/wiki/Model -视图控制器
https://refactoring.guru/ru/design-patterns/state
在这篇文章中,我将描述如何使用 fasttext 文本分类器。
快速文本–用于文本分类的机器学习库。让我们试着教她通过歌曲的标题来识别金属乐队。为此,我们使用数据集进行监督学习。
让我们创建一个包含团体名称的歌曲数据集:
__label__metallica fuel
__label__metallica escape
__label__black_sabbath gypsy
__label__black_sabbath snowblind
__label__black_sabbath am i going insane
__label__anthrax anthrax
__label__anthrax i'm alive
__label__anthrax antisocial
[и т.д.]
Формат обучающей выборки:
Обучим fasttext и сохраним модель:
model.save_model("model.bin")
加载经过训练的模型并要求通过歌曲名称来识别组:
predictResult = model.predict("Bleed")
print(predictResult)
В результате мы получим список классов на которые похож данный пример, с указанием уровня похожести цифрой, в нашем случае похожесть названия песни Bleed на одну из групп датасета.
Для того чтобы модель fasttext умела работать с датасетом выходящим за границы обучающей выборки, используют режим autotune с использованием файла валидации (файл тест). Во время автотюна fasttext подбирает оптимальные гиперпараметры модели, проводя валидацию результата на выборке из тест файла. Время автотюна ограничивается пользователем в самостоятельно, с помощью передачи аргумента autotuneDuration.
Пример создания модели с использованием файла тест:
https://www.youtube.com/watch?v=llvjvmh3dlk
在这篇笔记中我将描述从汇编程序调用 C 函数的过程。
让我们尝试调用 printf(“Hello World!\n”);并退出(0);
message: db "Hello, world!", 10, 0
section .text
extern printf
extern exit
global main
main:
xor rax, rax
mov rdi, message
call printf
xor rdi, rdi
call exit
一切都比看起来简单得多,在 .rodata 部分我们将描述静态数据,在本例中为“Hello, world!”行,10 是换行符,我们也不要忘记将其设为 null。
在代码部分,我们将声明外部函数 printf、stdio、stdlib 库的 exit,并且我们还将声明输入函数 main:
extern printf
extern exit
global main
我们从rax函数中将0传递给返回寄存器,您可以使用mov rax, 0;但为了加快速度,他们使用 xor rax, rax;接下来,我们将指向字符串的指针传递给第一个参数:
在这篇文章中,我将描述设置 IDE 的过程,为 Ubuntu Linux 操作系统在 x86_64 汇编程序中编写第一个 Hello World。
让我们从安装 SASM IDE、nasm 汇编器开始:
Далее запустим SASM и напишем Hello World:
section .text
main:
mov rbp, rsp ; for correct debugging
mov rax, 1 ; write(
mov rdi, 1 ; STDOUT_FILENO,
mov rsi, msg ; "Hello, world!\n",
mov rdx, msglen ; sizeof("Hello, world!\n")
syscall ; );
mov rax, 60 ; exit(
mov rdi, 0 ; EXIT_SUCCESS
syscall ; );
section .rodata
msg: db "Hello, world!"
msglen: equ $-msg
Hello World 代码取自博客 James Fisher,适用于 SASM 中的汇编和调试。 SASM文档规定,入口点必须是名为main的函数,否则代码的调试和编译将不正确。
我们在这段代码中做了什么?拨打了系统调用–使用寄存器中的正确参数、指向数据部分中的字符串的指针来访问 Linux 操作系统内核。
放大镜下
让我们更详细地看一下代码:
global – директива ассемблера позволяющая задавать глобальные символы со строковыми именами. Хорошая аналогия – интерфейсы заголовочных файлов языков C/C++. В данном случае мы задаем символ main для функции входа.
section – директива ассемблера позволяющая задавать секции (сегменты) кода. Директивы section или segment равнозначны. В секции .text помещается код программы.
Обьявляем начало функции main. В ассемблере функции называются подпрограммами (subroutine)
Первая машинная команда mov – помещает значение из аргумента 1 в аргумент 2. В данном случае мы переносим значение регистра rbp в rsp. Из комментария можно понять что эту строку добавил SASM для упрощения отладки. Видимо это личные дела между SASM и дебаггером gdb.
Далее посмотрим на код до сегмента данных .rodata, два вызова syscall, первый выводит строку Hello World, второй обеспечивает выход из приложения с корректным кодом 0.
Представим себе что регистры это переменные с именами rax, rdi, rsi, rdx, r10, r8, r9. По аналогии с высокоуровневыми языками, перевернем вертикальное представление ассемблера в горизонтальное, тогда вызов syscall будет выглядеть так:
Тогда вызов печати текста:
Вызов exit с корректным кодом 0:
Рассмотрим аргументы подробнее, в заголовочном файле asm/unistd_64.h находим номер функции __NR_write – 1, далее в документации смотрим аргументы для write:
ssize_t write(int fd, const void *buf, size_t count);
Первый аргумент – файловый дескриптор, второй – буфер с данными, третий – счетчик байт для записи в дескриптор. Ищем номер файлового дескриптора для стандартного вывода, в мануале по stdout находим код 1. Далее дело за малым, передать указатель на буфер строки Hello World из секции данных .rodata – msg, счетчик байт – msglen, передать в регистры rax, rdi, rsi, rdx корректные аргументы и вызвать syscall.
Обозначение константных строк и длины описывается в мануале nasm:
第一篇关于正在开发的游戏《Space Jaguar Action RPG》的文章。在这篇文章中,我将描述捷豹的游戏功能–特征。
许多 RPG 使用静态角色统计系统,例如 DnD(力量、体质、敏捷、智力、智慧、魅力)或 Fallout – S.P.E.C.I.A.L(力量、感知、耐力、魅力、智力、敏捷、运气)的统计数据)。
在Space Jaguar中,我计划实现一个动态的特征系统,例如,游戏的主角Jag一开始只有三个特征–精通刀刃(半刀)、阴暗行动(在犯罪世界中进行交易)、流氓能力(撬锁、盗窃)。在游戏过程中,角色将在游戏模块的框架内被赋予和剥夺动态特征,所有检查将根据给定游戏情况所需的某些特征的级别进行。例如,如果 Jag 不具备下棋的特性,或者没有足够的等级来通过检查,那么他将无法赢得国际象棋比赛。
为了简化检查逻辑,每个特征都有一个6位英文字母代码、名称和描述。例如,拥有一把刀片:
bladeFightingAbility.name = "BLADFG";
bladeFightingAbility.description = "Blade fighting ability";
bladeFightingAbility.points = 3;
Перед стартом игрового модуля можно будет просмотреть список публичных проверок необходимых для прохождения, также создатель может скрыть часть проверок для создания интересных игровых ситуаций.
Ноу-хау? Будет ли интересно? Лично я нахожу такую систему интересной, позволяющей одновременно обеспечить свободу творчества создателям игровых модулей, и возможность переноса персонажей из разных, но похожих по характеристикам, модулей для игроков.
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
Manage consent
.gif)