Shell Sort – une variante du tri par insertion avec peignage préliminaire d’un tableau de nombres.
Nous devons nous rappeler comment fonctionne le tri par insertion :
1. Une boucle commence de zéro jusqu’à la fin de la boucle, le tableau est donc divisé en deux parties 2. Pour la partie gauche, une deuxième boucle est lancée, comparant les éléments de droite à gauche, le plus petit élément de droite est déposé jusqu’à ce qu’un plus petit élément de gauche soit trouvé 3. A la fin des deux boucles, on obtient une liste triée
Il était une fois l’informaticien Donald Schell qui se demandait comment améliorer l’algorithme de tri par insertion. Il a également eu l’idée de parcourir d’abord le tableau en deux cycles, mais à une certaine distance, en réduisant progressivement le « peigne » jusqu’à ce qu’il se transforme en un algorithme de tri par insertion régulier. Tout est vraiment si simple, pas d’embûches, aux deux cycles ci-dessus on en ajoute un autre, dans lequel on réduit progressivement la taille du « peigne ». La seule chose que vous devez faire est de vérifier la distance lors de la comparaison afin qu’elle ne dépasse pas le tableau.
Un sujet vraiment intéressant est le choix de la séquence permettant de modifier la longueur de comparaison à chaque itération de la première boucle. C’est intéressant car les performances de l’algorithme en dépendent.
Différentes personnes ont participé au calcul de la distance idéale ; apparemment, ce sujet les intéressait beaucoup. Ne pourraient-ils pas simplement exécuter Ruby et appeler l’algorithme sort() le plus rapide ?
En général, ces personnes étranges ont écrit des dissertations sur le thème du calcul de la distance/écart du « peigne » pour l’algorithme Shell. J’ai simplement utilisé les résultats de leurs travaux et vérifié 5 types de séquences, Hibbard, Knuth-Pratt, Chiura, Sedgwick.
import time
import random
from functools import reduce
import math
DEMO_MODE = False
if input("Demo Mode Y/N? ").upper() == "Y":
DEMO_MODE = True
class Colors:
BLUE = '\033[94m'
RED = '\033[31m'
END = '\033[0m'
def swap(list, lhs, rhs):
list[lhs], list[rhs] = list[rhs], list[lhs]
return list
def colorPrintoutStep(numbers: List[int], lhs: int, rhs: int):
for index, number in enumerate(numbers):
if index == lhs:
print(f"{Colors.BLUE}", end = "")
elif index == rhs:
print(f"{Colors.RED}", end = "")
print(f"{number},", end = "")
if index == lhs or index == rhs:
print(f"{Colors.END}", end = "")
if index == lhs or index == rhs:
print(f"{Colors.END}", end = "")
print("\n")
input(">")
def ShellSortLoop(numbers: List[int], distanceSequence: List[int]):
distanceSequenceIterator = reversed(distanceSequence)
while distance:= next(distanceSequenceIterator, None):
for sortArea in range(0, len(numbers)):
for rhs in reversed(range(distance, sortArea + 1)):
lhs = rhs - distance
if DEMO_MODE:
print(f"Distance: {distance}")
colorPrintoutStep(numbers, lhs, rhs)
if numbers[lhs] > numbers[rhs]:
swap(numbers, lhs, rhs)
else:
break
def ShellSort(numbers: List[int]):
global ShellSequence
ShellSortLoop(numbers, ShellSequence)
def HibbardSort(numbers: List[int]):
global HibbardSequence
ShellSortLoop(numbers, HibbardSequence)
def ShellPlusKnuttPrattSort(numbers: List[int]):
global KnuttPrattSequence
ShellSortLoop(numbers, KnuttPrattSequence)
def ShellPlusCiuraSort(numbers: List[int]):
global CiuraSequence
ShellSortLoop(numbers, CiuraSequence)
def ShellPlusSedgewickSort(numbers: List[int]):
global SedgewickSequence
ShellSortLoop(numbers, SedgewickSequence)
def insertionSort(numbers: List[int]):
global insertionSortDistanceSequence
ShellSortLoop(numbers, insertionSortDistanceSequence)
def defaultSort(numbers: List[int]):
numbers.sort()
def measureExecution(inputNumbers: List[int], algorithmName: str, algorithm):
if DEMO_MODE:
print(f"{algorithmName} started")
numbers = inputNumbers.copy()
startTime = time.perf_counter()
algorithm(numbers)
endTime = time.perf_counter()
print(f"{algorithmName} performance: {endTime - startTime}")
def sortedNumbersAsString(inputNumbers: List[int], algorithm) -> str:
numbers = inputNumbers.copy()
algorithm(numbers)
return str(numbers)
if DEMO_MODE:
maximalNumber = 10
numbersCount = 10
else:
maximalNumber = 10
numbersCount = random.randint(10000, 20000)
randomNumbers = [random.randrange(1, maximalNumber) for i in range(numbersCount)]
ShellSequenceGenerator = lambda n: reduce(lambda x, _: x + [int(x[-1]/2)], range(int(math.log(numbersCount, 2))), [int(numbersCount / 2)])
ShellSequence = ShellSequenceGenerator(randomNumbers)
ShellSequence.reverse()
ShellSequence.pop()
HibbardSequence = [
0, 1, 3, 7, 15, 31, 63, 127, 255, 511, 1023, 2047, 4095,
8191, 16383, 32767, 65535, 131071, 262143, 524287, 1048575,
2097151, 4194303, 8388607, 16777215, 33554431, 67108863, 134217727,
268435455, 536870911, 1073741823, 2147483647, 4294967295, 8589934591
]
KnuttPrattSequence = [
1, 4, 13, 40, 121, 364, 1093, 3280, 9841, 29524, 88573, 265720,
797161, 2391484, 7174453, 21523360, 64570081, 193710244, 581130733,
1743392200, 5230176601, 15690529804, 47071589413
]
CiuraSequence = [
1, 4, 10, 23, 57, 132, 301, 701, 1750, 4376,
10941, 27353, 68383, 170958, 427396, 1068491,
2671228, 6678071, 16695178, 41737946, 104344866,
260862166, 652155416, 1630388541
]
SedgewickSequence = [
1, 5, 19, 41, 109, 209, 505, 929, 2161, 3905,
8929, 16001, 36289, 64769, 146305, 260609, 587521,
1045505, 2354689, 4188161, 9427969, 16764929, 37730305,
67084289, 150958081, 268386305, 603906049, 1073643521,
2415771649, 4294770689, 9663381505, 17179475969
]
insertionSortDistanceSequence = [1]
algorithms = {
"Default Python Sort": defaultSort,
"Shell Sort": ShellSort,
"Shell + Hibbard" : HibbardSort,
"Shell + Prat, Knutt": ShellPlusKnuttPrattSort,
"Shell + Ciura Sort": ShellPlusCiuraSort,
"Shell + Sedgewick Sort": ShellPlusSedgewickSort,
"Insertion Sort": insertionSort
}
for name, algorithm in algorithms.items():
measureExecution(randomNumbers, name, algorithm)
reference = sortedNumbersAsString(randomNumbers, defaultSort)
for name, algorithm in algorithms.items():
if sortedNumbersAsString(randomNumbers, algorithm) != reference:
print("Sorting validation failed")
exit(1)
print("Sorting validation success")
exit(0)
Dans mon implémentation, pour un ensemble aléatoire de nombres, les écarts les plus rapides sont Sedgwick et Hibbard.
monpy
Je voudrais également mentionner l’analyseur de typage statique pour Python 3 – mypy. Aide à faire face aux problèmes inhérents aux langages à typage dynamique, à savoir qu’il élimine la possibilité de coller quelque chose là où ce n’est pas nécessaire.
Comme le disent les programmeurs expérimentés, “la saisie statique n’est pas nécessaire lorsque vous avez une équipe de professionnels”, un jour nous deviendrons tous des professionnels, nous écrirons du code en pleine unité et compréhension avec les machines, mais pour l’instant vous pouvez utiliser des utilitaires similaires. et les langages typés statiquement.
Tri par sélection double : un sous-type de tri par sélection, il semble qu’il devrait être deux fois plus rapide. L’algorithme Vanilla effectue une double boucle dans la liste des nombres, trouve le nombre minimum et échange les places avec le numéro actuel pointé par la boucle au niveau supérieur. Le tri par double sélection recherche les nombres minimum et maximum, puis remplace les deux chiffres pointés par la boucle au niveau supérieur à – deux chiffres à gauche et à droite. Toute cette orgie se termine lorsque les curseurs des nombres à remplacer se trouvent au milieu de la liste, et par conséquent, des nombres triés sont obtenus à gauche et à droite du centre visuel. La complexité temporelle de l’algorithme est similaire à celle du tri par sélection – O(n2), mais soi-disant il y a une accélération de 30 %.
État limite
Déjà à ce stade, vous pouvez imaginer le moment d’une collision, par exemple, lorsque le numéro du curseur gauche (le nombre minimum) pointe vers le nombre maximum dans la liste, alors le nombre minimum est réorganisé, le réarrangement du nombre maximum tombe immédiatement en panne. Par conséquent, toutes les implémentations de l’algorithme contiennent la vérification de tels cas et le remplacement des index par des index corrects. Dans mon implémentation, une seule vérification suffisait :
maximalNumberIndex = minimalNumberIndex;
}
Реализация на Cito
Cito – язык либ, язык транслятор. На нем можно писать для C, C++, C#, Java, JavaScript, Python, Swift, TypeScript, OpenCL C, при этом совершенно ничего не зная про эти языки. Исходный код на языке Cito транслируется в исходный код на поддерживаемых языках, далее можно использовать как библиотеку, либо напрямую, исправив сгенеренный код руками. Эдакий Write once – translate to anything.
Double Selection Sort на cito:
{
public static int[] sort(int[]# numbers, int length)
{
int[]# sortedNumbers = new int[length];
for (int i = 0; i < length; i++) {
sortedNumbers[i] = numbers[i];
}
for (int leftCursor = 0; leftCursor < length / 2; leftCursor++) {
int minimalNumberIndex = leftCursor;
int minimalNumber = sortedNumbers[leftCursor];
int rightCursor = length - (leftCursor + 1);
int maximalNumberIndex = rightCursor;
int maximalNumber = sortedNumbers[maximalNumberIndex];
for (int cursor = leftCursor; cursor <= rightCursor; cursor++) { int cursorNumber = sortedNumbers[cursor]; if (minimalNumber > cursorNumber) {
minimalNumber = cursorNumber;
minimalNumberIndex = cursor;
}
if (maximalNumber < cursorNumber) {
maximalNumber = cursorNumber;
maximalNumberIndex = cursor;
}
}
if (leftCursor == maximalNumberIndex) {
maximalNumberIndex = minimalNumberIndex;
}
int fromNumber = sortedNumbers[leftCursor];
int toNumber = sortedNumbers[minimalNumberIndex];
sortedNumbers[minimalNumberIndex] = fromNumber;
sortedNumbers[leftCursor] = toNumber;
fromNumber = sortedNumbers[rightCursor];
toNumber = sortedNumbers[maximalNumberIndex];
sortedNumbers[maximalNumberIndex] = fromNumber;
sortedNumbers[rightCursor] = toNumber;
}
return sortedNumbers;
}
}
If the game doesn’t start with fcntl(5) for /tmp/source_engine_2808995433.lock failed, then try deleting the /tmp/source_engine_2808995433.lock file rm /tmp/source_engine_2808995433.lock
Usually the lock file is left over from the last game session unless the game was closed naturally.
How to check?
The easiest way to check the launch of applications on a discrete Nvidia graphics card is through the nvidia-smi utility:
For games on the Source engine, you can check through the game console using the mat_info command:
Tri du sommeil – sleep sort, un autre représentant des algorithmes de tri étranges déterministes.
Cela fonctionne comme ceci :
Parcourt une liste d’éléments
Un thread distinct est lancé pour chaque boucle
Le fil de discussion est en veille pendant un certain temps – valeur de l’élément et sortie de la valeur après le sommeil
A la fin de la boucle, attendez la fin du sommeil le plus long du thread, affichez la liste triée
Exemple de code pour l’algorithme de tri en veille en C :
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
typedef struct {
int number;
} ThreadPayload;
void *sortNumber(void *args) {
ThreadPayload *payload = (ThreadPayload*) args;
const int number = payload->number;
free(payload);
usleep(number * 1000);
printf("%d ", number);
return NULL;
}
int main(int argc, char *argv[]) {
const int numbers[] = {2, 42, 1, 87, 7, 9, 5, 35};
const int length = sizeof(numbers) / sizeof(int);
int maximal = 0;
pthread_t maximalThreadID;
printf("Sorting: ");
for (int i = 0; i < length; i++) { pthread_t threadID; int number = numbers[i]; printf("%d ", number); ThreadPayload *payload = malloc(sizeof(ThreadPayload)); payload->number = number;
pthread_create(&threadID, NULL, sortNumber, (void *) payload);
if (maximal < number) {
maximal = number;
maximalThreadID = threadID;
}
}
printf("\n");
printf("Sorted: ");
pthread_join(maximalThreadID, NULL);
printf("\n");
return 0;
}
Dans cette implémentation, j’ai utilisé la fonction usleep sur les microsecondes avec la valeur multipliée par 1000, c’est-à-dire en millisecondes. Complexité temporelle de l’algorithme – O(très long)
Le tri de Staline – ; trier, un des algorithmes de tri avec perte de données. L’algorithme est très productif et efficace, complexité temporelle O(n).
Cela fonctionne comme ceci :
Parcourez le tableau en comparant l’élément actuel avec le suivant
Si l’élément suivant est plus petit que l’élément actuel, supprimez-le
En conséquence, nous obtenons un tableau trié en O(n)
Exemple de sortie de l’algorithme :
Gulag: [1, 3, 2, 4, 6, 42, 4, 8, 5, 0, 35, 10]
Element 2 sent to Gulag
Element 4 sent to Gulag
Element 8 sent to Gulag
Element 5 sent to Gulag
Element 0 sent to Gulag
Element 35 sent to Gulag
Element 10 sent to Gulag
Numbers: [1, 3, 4, 6, 42]
Gulag: [2, 4, 8, 5, 0, 35, 10]
Code Python 3 :
gulag = []
print(f"Numbers: {numbers}")
print(f"Gulag: {numbers}")
i = 0
maximal = numbers[0]
while i < len(numbers):
element = numbers[i]
if maximal > element:
print(f"Element {element} sent to Gulag")
gulag.append(element)
del numbers[i]
else:
maximal = element
i += 1
print(f"Numbers: {numbers}")
print(f"Gulag: {gulag}")
Les inconvénients incluent la perte de données, mais si nous nous dirigeons vers une liste utopique, idéale et triée en O(n), alors comment faire autrement ?
N’ayant pas trouvé d’implémentation Objective-C sur le Rosetta Code , je me suis écrit :
#include <Foundation/Foundation.h>
@implementation SelectionSort
- (void)performSort:(NSMutableArray *)numbers
{
NSLog(@"%@", numbers);
for (int startIndex = 0; startIndex < numbers.count-1; startIndex++) {
int minimalNumberIndex = startIndex;
for (int i = startIndex + 1; i < numbers.count; i++) {
id lhs = [numbers objectAtIndex: minimalNumberIndex];
id rhs = [numbers objectAtIndex: i];
if ([lhs isGreaterThan: rhs]) {
minimalNumberIndex = i;
}
}
id temporary = [numbers objectAtIndex: minimalNumberIndex];
[numbers setObject: [numbers objectAtIndex: startIndex]
atIndexedSubscript: minimalNumberIndex];
[numbers setObject: temporary
atIndexedSubscript: startIndex];
}
NSLog(@"%@", numbers);
}
@end
Собрать и запустить можно либо на MacOS/Xcode, либо на любой операционной системе поддерживающей GNUstep, например у меня собирается Clang на Arch Linux.
Скрипт сборки:
Tri par comptage – algorithme de tri par comptage. En termes de? Oui! Juste comme ça !
L’algorithme implique au moins deux tableaux, le premier – liste d’entiers à trier, seconde – un tableau de taille = (nombre maximum – nombre minimum) + 1, ne contenant initialement que des zéros. Ensuite, les nombres sont triés du premier tableau et l’élément numérique est utilisé pour obtenir un index dans le deuxième tableau, qui est incrémenté de un. Après avoir parcouru toute la liste, nous obtiendrons un deuxième tableau complètement rempli avec le nombre de répétitions des nombres du premier. L’algorithme entraîne une surcharge importante : le deuxième tableau contient également des zéros pour les nombres qui ne figurent pas dans la première liste, ce qu’on appelle. surcharge de la mémoire
Après avoir reçu le deuxième tableau, nous le parcourons et écrivons la version triée du nombre par index, en décrémentant le compteur à zéro. Initialement, un compteur zéro est ignoré.
Un exemple de fonctionnement non optimisé de l’algorithme de tri par comptage :
Tableau d’entrée 1,9,1,4,6,4,4
Alors le tableau à compter sera 0,1,2,3,4,5,6,7,8,9 (nombre minimum 0, maximum 9)
Avec un total de compteurs 0,2,0,0,3,0,1,0,0,1
Total du tableau trié 1,1,4,4,4,6,9
Code d’algorithme en Python 3 :
numbers = [42, 89, 69, 777, 22, 35, 42, 69, 42, 90, 777]
minimal = min(numbers)
maximal = max(numbers)
countListRange = maximal - minimal
countListRange += 1
countList = [0] * countListRange
print(numbers)
print(f"Minimal number: {minimal}")
print(f"Maximal number: {maximal}")
print(f"Count list size: {countListRange}")
for number in numbers:
index = number - minimal
countList[index] += 1
replacingIndex = 0
for index, count in enumerate(countList):
for i in range(count):
outputNumber = minimal + index
numbers[replacingIndex] = outputNumber
replacingIndex += 1
print(numbers)
Из-за использования двух массивов, временная сложность алгоритма O(n + k)
Pseudo-tri ou tri par marais, l’un des algorithmes de tri les plus inutiles.
Cela fonctionne comme ceci : 1. L’entrée est un tableau de nombres 2. Un tableau de nombres est mélangé au hasard (shuffle) 3. Vérifie si le tableau est trié 4. S’il n’est pas trié, le tableau est à nouveau mélangé 5. Toute cette action est répétée jusqu’à ce que le tableau soit trié de manière aléatoire.
Comme vous pouvez le constater, les performances de cet algorithme sont terribles, les gens intelligents croient que même O(n * n!) c’est-à-dire il y a une chance que vous restiez coincé à lancer des dés pour la gloire du dieu du chaos pendant de nombreuses années, le tableau ne sera jamais trié, ou peut-être qu’il le sera ?
Mise en œuvre
Pour l’implémenter dans TypeScript, je devais implémenter les fonctions suivantes : 1. Mélangez un tableau d’objets 2. Comparaison de tableaux 3. Générer un nombre aléatoire compris entre zéro et un nombre (sic !) 4. Imprimez la progression, car il semble que le tri continue sans fin
Vous trouverez ci-dessous le code d’implémentation de TypeScript :
const randomInteger = (maximal: number) => Math.floor(Math.random() * maximal);
const isEqual = (lhs: any[], rhs: any[]) => lhs.every((val, index) => val === rhs[index]);
const shuffle = (array: any[]) => {
for (var i = 0; i < array.length; i++) { var destination = randomInteger(array.length-1); var temp = array[i]; array[i] = array[destination]; array[destination] = temp; } } let numbers: number[] = Array.from({length: 10}, ()=>randomInteger(10));
const originalNumbers = [...numbers];
const sortedNumbers = [...numbers].sort();
let numberOfRuns = 1;
do {
if (numberOfRuns % 1000 == 0) {
printoutProcess(originalNumbers, numbers, numberOfRuns);
}
shuffle(numbers);
numberOfRuns++;
} while (isEqual(numbers, sortedNumbers) == false)
console.log(`Success!`);
console.log(`Run number: ${numberOfRuns}`)
console.log(`Original numbers: ${originalNumbers}`);
console.log(`Current numbers: ${originalNumbers}`);
console.log(`Sorted numbers: ${sortedNumbers}`);
Для отладки можно использовать VSCode и плагин TypeScript Debugger от kakumei.
Как долго
Вывод работы алгоритма:
src/bogosort.ts:1
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 8,7,0,2,4,7,2,5,9,5, try number: 145000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 7,5,2,4,9,8,0,5,2,7, try number: 146000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 0,2,7,4,9,5,7,5,8,2, try number: 147000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 5,9,7,8,5,4,2,7,0,2, try number: 148000
src/bogosort.ts:2
Success!
src/bogosort.ts:24
Run number: 148798
src/bogosort.ts:25
Original numbers: 5,4,8,7,5,0,2,9,7,2
src/bogosort.ts:26
Current numbers: 5,4,8,7,5,0,2,9,7,2
src/bogosort.ts:27
Sorted numbers: 0,2,2,4,5,5,7,7,8,9
Для массива из 10 чисел Богосорт перемешивал исходный массив 148798 раз, многовато да?
Алгоритм можно использовать как учебный, для понимания возможностей языка с которым предстоит работать на рынке. Лично я был удивлен узнав что в ванильных JS и TS до сих пор нет своего алгоритма перемешивания массивов, генерации целого числа в диапазоне, доступа к хэшам объектов для быстрого сравнения.
Le modèle Interpreter fait référence aux modèles de conception comportementale. Ce modèle vous permet d’implémenter votre propre langage de programmation en travaillant avec un arbre AST dont les sommets sont des expressions terminales et non terminales qui implémentent la méthode Interpret, qui fournit les fonctionnalités du langage.
Expression de terminal : par exemple, constante de chaîne – “Bonjour tout le monde”
Expression non terminale : par exemple Print(“Hello World”), contient Print et un argument de l’expression terminale “Hello World”
Quelle est la différence ? La différence est que l’interprétation se termine sur les expressions terminales, mais pour les expressions non terminales, elle se poursuit en profondeur sur tous les sommets/arguments entrants. Si l’arborescence AST était constituée uniquement d’expressions non terminales, l’application ne se terminerait jamais, car une certaine finitude de tout processus est requise, cette finitude est ce que sont les expressions terminales, elles contiennent généralement des données, par exemple des chaînes.
Un exemple d’arborescence AST est ci-dessous :
Dcoetzee, CC0, via Wikimedia Commons
Comme vous pouvez le voir, les expressions terminales sont constantes et variables, les expressions non terminales sont le reste.
Ce qui n’est pas inclus
L’implémentation de l’Interpreter n’inclut pas l’analyse de la chaîne de langue entrée dans l’arborescence AST. Il suffit d’implémenter des classes d’expressions terminales et non terminales, des méthodes Interpret avec l’argument Context en entrée, de créer un arbre d’expressions AST et d’exécuter la méthode Interpret au niveau de l’expression racine. Un contexte peut être utilisé pour stocker l’état de l’application au moment de l’exécution.
Mise en œuvre
Le modèle implique :
Client – renvoie l’arborescence AST et exécute Interpret(context) pour le nœud racine (Client)
Contexte : contient l’état de l’application, transmis aux expressions lorsqu’elles sont interprétées (Contexte)
Expression abstraite : une classe abstraite contenant la méthode Interpret(context) (Expression)
L’expression terminale est une expression finale, descendante d’une expression abstraite (TerminalExpression)
Une expression non terminale n’est pas une expression finie ; elle contient des pointeurs vers des sommets profonds dans l’arborescence AST ; les sommets subordonnés affectent généralement le résultat de l’interprétation de l’expression non terminale (NonTerminalExpression)
Exemple client en C#
static void Main(string[] args)
{
var context = new Context();
var initialProgram = new PerformExpression(
new IExpression[] {
new SetExpression("alpha", "1"),
new GetExpression("alpha"),
new PrintExpression(
new IExpression[] {
new ConstantExpression("Hello Interpreter Pattern")
}
)
}
);
System.Console.WriteLine(initialProgram.interpret(context));
}
}
Exemple d’expression abstraite en C#
{
String interpret(Context context);
}
Exemple d’expression de terminal en C# (constante de chaîne)
Exemple d’expression non terminale en C# (démarrage et concaténation des résultats des sommets subordonnés, en utilisant le délimiteur « ; »
{
public PerformExpression(IExpression[] leafs) : base(leafs) {
this.leafs = leafs;
}
override public String interpret(Context context) {
var output = "";
foreach (var leaf in leafs) {
output += leaf.interpret(context) + ";";
}
return output;
}
}
Pouvez-vous le faire fonctionnellement ?
Comme on le sait, tous les langages Turing-complets sont équivalents. Est-il possible de transférer le modèle orienté objet vers le langage de programmation fonctionnel ?
Pour une expérience, prenons un langage FP pour le Web appelé Elm. Il n’y a pas de classes dans Elm, mais il y a des enregistrements et des types, donc les enregistrements et types suivants sont impliqués dans l’implémentation :
Expression : liste de toutes les expressions linguistiques possibles (Expression)
Expression subordonnée : expression subordonnée à l’expression non terminale (ExpressionLeaf)
Contexte : un enregistrement stockant l’état de l’application (Contexte)
Fonctions qui implémentent les méthodes Interpret(context) : toutes les fonctions nécessaires qui implémentent les fonctionnalités des expressions terminales et non terminales
Enregistrements auxiliaires de l’état de l’interprète – nécessaires au bon fonctionnement de l’interprète, ils stockent l’état de l’interprète, le contexte
Un exemple de fonction qui implémente l’interprétation pour l’ensemble des expressions possibles dans Elm :
case input.expression of
Constant text ->
{
output = text,
context = input.context
}
Perform leafs ->
let inputs = List.map (\leaf -> { expressionLeaf = leaf, context = input.context } ) leafs in
let startLeaf = { expressionLeaf = (Node (Constant "")), context = { variables = Dict.empty } } in
let outputExpressionInput = List.foldl mergeContextsAndRunLeafs startLeaf inputs in
{
output = (runExpressionLeaf outputExpressionInput).output,
context = input.context
}
Print printExpression ->
run
{
expression = printExpression,
context = input.context
}
Set key value ->
let variables = Dict.insert key value input.context.variables in
{
output = "OK",
context = { variables = variables }
}
Get key ->
{
output = Maybe.withDefault ("No value for key: " ++ key) (Dict.get key input.context.variables),
context = input.context
}
Et l’analyse syntaxique ?
L’analyse du code source dans une arborescence AST n’est pas incluse dans le modèle Interpreter ; il existe plusieurs approches pour analyser le code source, mais nous y reviendrons une autre fois. Dans l’implémentation de l’Interpreter for Elm, j’ai écrit un analyseur simple dans l’arborescence AST, composé de deux fonctions : analyser un sommet et analyser les sommets subordonnés.
parseLeafs state =
let tokensQueue = state.tokensQueue in
let popped = pop state.tokensQueue in
let tokensQueueTail = tail state.tokensQueue in
if popped == "Nothing" then
state
else if popped == "Perform(" then
{
tokensQueue = tokensQueue,
result = (state.result ++ [Node (parse tokensQueue)])
}
else if popped == ")" then
parseLeafs {
tokensQueue = tokensQueueTail,
result = state.result
}
else if popped == "Set" then
let key = pop tokensQueueTail in
let value = pop (tail tokensQueueTail) in
parseLeafs {
tokensQueue = tail (tail tokensQueueTail),
result = (state.result ++ [Node (Set key value)])
}
else if popped == "Get" then
let key = pop tokensQueueTail in
parseLeafs {
tokensQueue = tail tokensQueueTail,
result = (state.result ++ [Node (Get key)])
}
else
parseLeafs {
tokensQueue = tokensQueueTail,
result = (state.result ++ [Node (Constant popped)])
}
parse tokensQueue =
let popped = pop tokensQueue in
let tokensQueueTail = tail tokensQueue in
if popped == "Perform(" then
Perform (
parseLeafs {
tokensQueue = tokensQueueTail,
result = []
}
).result
else if popped == "Set" then
let key = pop tokensQueueTail in
let value = pop (tail tokensQueueTail) in
Set key value
else if popped == "Print" then
Print (parse tokensQueueTail)
else
Constant popped
Dans cet article, je décrirai l’algorithme de conversion d’un tampon RVB en gris (Niveaux de gris). Et cela se fait tout simplement, chaque canal de couleur de pixel du tampon est converti selon une certaine formule et le résultat est une image grise. Méthode moyenne :
red = average;
green = average;
blue = average;
Складываем 3 цветовых канала и делим на 3.
Однако существует еще один метод – метод средневзвешенный, он учитывает цветовосприятие человека:
red = luminance;
green = luminance;
blue = luminance;
Какой метод лучше использовать? Да какой вам больше подходит для конкретной задачи. Далее сравнение методов с помощью тестовой цветовой сетки:
Пример реализации на JavaScript + HTML 5
image,
canvas,
weightedAverage
) {
const context = canvas.getContext('2d');
const imageWeight = image.width;
const imageHeight = image.height;
canvas.width = imageWeight;
canvas.height = imageHeight;
context.drawImage(image, 0, 0);
let pixels = context
.getImageData(
0,
0,
imageWeight,
imageHeight
);
for (let y = 0; y & lt; pixels.height; y++) {
for (let x = 0; x & lt; pixels.width; x++) {
const i = (y * 4) * pixels.width + x * 4;
let red = pixels.data[i];
let green = pixels.data[i + 1];
let blue = pixels.data[i + 2]
const average = (red + green + blue) / 3;
const luminance = 0.2126 * red +
0.7152 * green +
0.0722 * blue;
red = weightedAverage ? luminance : average;
green = weightedAverage ? luminance : average;
blue = weightedAverage ? luminance : average;
pixels.data[i] = red;
pixels.data[i + 1] = green;
pixels.data[i + 2] = blue;
}
}
context
.putImageData(
pixels,
0,
0,
0,
0,
pixels.width,
pixels.height
);
}
Si vous obtenez l’erreur SDL_GetDesktopDisplayMode_REAL sur un Macbook M1 lors du lancement de CSGO, procédez comme décrit ci-dessous. 1. Ajoutez des options de lancement à Steam pour CSGO : -w 1440 -h 900 -plein écran 2. Lancez CSGO via Steam 3. Cliquez sur Ignorer ou Toujours ignorer l’erreur SDL_GetDesktopDisplayMode_REAL 4. Profitez-en
Je présente à votre attention une traduction des premières pages de l’article d’Alan Turing – « SUR LES NUMÉROS INFORMATIQUES AVEC APPLICATION AU PROBLÈME DE RÉSOLUTION » 1936. Les premiers chapitres contiennent une description des ordinateurs, qui sont devenus plus tard la base de l’informatique moderne.
La traduction complète de l’article et l’explication peuvent être lues dans le livre du vulgarisateur américain Charles Petzold, intitulé « Reading Turing ». Un voyage à travers l’article historique de Turing sur la calculabilité et les machines de Turing” ; (ISBN 978-5-97060-231-7, 978-0-470-22905-7)
À PROPOS DES NOMBRES CALCULABLES AVEC APPLICATION AU PROBLÈME DE RÉSOLUTION
A. M. TURING
[Reçu le 28 mai 1936 – Lu le 12 novembre 1936]
Les nombres calculables peuvent être brièvement décrits comme des nombres réels dont les expressions sous forme de fractions décimales sont calculables d’un nombre fini de façons. Bien qu’à première vue cet article traite les nombres comme calculables, il est presque aussi simple de définir et d’explorer les fonctions calculables d’une variable entière, d’une variable réelle, d’une variable calculable, de prédicats calculables, etc. Cependant, les problèmes fondamentaux associés à ces objets calculables sont les mêmes dans chaque cas. Pour une considération détaillée, j’ai choisi les nombres calculables comme objet calculable car la méthode pour les considérer est la moins lourde. J’espère décrire bientôt la relation entre les nombres calculables et les fonctions calculables, etc. Parallèlement, des recherches seront menées dans le domaine de la théorie des fonctions d’une variable réelle exprimée en termes de nombres calculables. Selon ma définition, un nombre réel est calculable si sa représentation sous forme de fraction décimale peut être écrite par une machine.
Dans les paragraphes 9 et 10, je donne quelques arguments pour montrer que les nombres calculables incluent tous les nombres qui sont naturellement considérés comme calculables. En particulier, je montre que certaines grandes classes de nombres sont calculables. Ils comprennent, par exemple, les parties réelles de tous les nombres algébriques, les parties réelles des zéros des fonctions de Bessel, les nombres π, e et autres. Cependant, les nombres calculables n’incluent pas tous les nombres définissables, comme en témoigne l’exemple suivant d’un nombre définissable qui n’est pas calculable.
Bien que la classe des nombres calculables soit très vaste et similaire à bien des égards à la classe des nombres réels, elle reste néanmoins dénombrable. Au §8, je considère certains arguments qui semblent soutenir le contraire. Lorsqu’un de ces arguments est correctement appliqué, on en tire des conclusions qui, à première vue, sont similaires à celles de Gödel*. Ces résultats ont des applications extrêmement importantes. En particulier, comme indiqué ci-dessous (§11), le problème de résolution ne peut pas être résolu.
Dans son récent article, Alonzo Church** a introduit l’idée de « calculabilité efficace », qui est équivalente à mon idée de « calculabilité » mais a une définition complètement différente. Church arrive également à des conclusions similaires concernant le problème de la résolution. La preuve de l’équivalence de la « calculabilité » et de la « capacité à être effectivement comptée » est présentée en annexe de cet article.
1. Ordinateurs
Nous avons déjà dit que les nombres calculables sont les nombres dont les décimales sont dénombrables par des moyens finis. Une définition plus claire est nécessaire ici. Cet article ne tentera pas réellement de justifier les définitions données ici avant d’arriver au §9. Pour l’instant, je noterai simplement que la justification (logique) (de cela) est que la mémoire humaine est, par nécessité, limitée.
Comparons une personne en train de calculer un nombre réel avec une machine capable de remplir seulement un nombre fini de conditions q1, q2, …, qR ; Appelons ces conditions « m-configurations ». Cette machine (c’est-à-dire ainsi définie) est équipée d’un « ruban » (analogue au papier). Cette courroie traversant la machine est divisée en tronçons. Appelons-les « carrés ». Chacun de ces carrés peut contenir une sorte de « symbole ». À tout moment, il n’existe qu’un seul carré de ce type, disons le ième, contenant le symbole qui se trouve « dans cette machine ». Appelons un tel carré un « symbole numérisé ». Un “caractère scanné” est le seul caractère dont la machine est, pour ainsi dire, “directement consciente”. Cependant, en modifiant sa configuration m, la machine peut effectivement mémoriser certains des caractères qu’elle a “vus” (numérisés) précédemment. Le comportement possible de la machine à tout moment est déterminé par la configuration m qn et le symbole scanné***. Appelons cette paire de symboles qn, « configuration ». La configuration ainsi désignée détermine le comportement possible d’une machine donnée. Dans certaines de ces configurations dans lesquelles le carré scanné est vide (c’est-à-dire ne contient pas de caractère), la machine écrit un nouveau caractère sur le carré scanné, et dans d’autres de ces configurations, elle efface le caractère scanné. Cette machine est également capable de se déplacer pour scanner une autre case, mais de cette manière elle ne peut se déplacer que vers la case adjacente à droite ou à gauche. En plus de chacune de ces opérations, la configuration m de la machine peut être modifiée. Dans ce cas, certains des caractères écrits formeront une séquence de chiffres, qui constitue la partie décimale du nombre réel calculé. Le reste ne sera que des notes inexactes destinées à « aider la mémoire ». Dans ce cas, seules les marques inexactes mentionnées ci-dessus pourront être effacées.
J’affirme que les opérations considérées ici incluent toutes les opérations utilisées dans le calcul. La justification de cette affirmation est plus facile à comprendre pour le lecteur qui comprend la théorie des machines. Par conséquent, dans la section suivante, je continuerai à développer la théorie en question, basée sur une compréhension de la signification des termes « machine », « bande », « scanné », etc. *Gödel « Sur les phrases formellement indécidables des Principia Mathematics (publié par Whitehead et Russell en 1910, 1912 et 1913) et des systèmes associés, partie I », Journal of Mathematics. Physique, bulletin mensuel en allemand n° 38 (pour 1931, pp. 173-198. ** Alonzo Church, « An Undecidable Problem in Elementary Number Theory », American J. of Math., n° 58 (1936), pp. 345-363. *** Alonzo Church, « Une note sur le problème de la résolution », J. of Symbolic Logic, n° 1 (1936), pp. 40-41
En 1936, le scientifique Alan Turing, dans sa publication « On Computable Numbers, With An Application to Entscheidungsproblem » décrit l’utilisation d’une machine informatique universelle qui pourrait mettre fin au problème de solvabilité en mathématiques. En conséquence, il arrive à la conclusion qu’une telle machine ne serait pas en mesure de résoudre quoi que ce soit correctement si le résultat de son travail était inversé et bouclé sur lui-même. Il s’avère qu’il est impossible de créer un antivirus *idéal*, un poseur de tuiles *idéal*, un programme qui suggère des phrases idéales pour votre crash, etc. Paradoxe !
Cependant, cette machine informatique universelle peut être utilisée pour mettre en œuvre n’importe quel algorithme, dont les services secrets britanniques ont profité en embauchant Turing et en permettant la création d’une machine « Bombe » pour déchiffrer les messages allemands pendant la Seconde Guerre mondiale.
Ce qui suit est la modélisation POO d’un ordinateur à bande unique dans le langage Dart, basée sur le document original.
Une machine de Turing est constituée d’un film divisé en sections, chaque section contient un symbole, les symboles peuvent être lus ou écrits. Exemple de cours de cinéma :
final _map = Map<int, String>();
String read({required int at}) {
return _map[at] ?? "";
}
void write({required String symbol, required int at}) {
_map[at] = symbol;
}
}
Il existe également un “carré de numérisation”, qui permet de se déplacer sur le film, de lire ou d’écrire des informations, en langage moderne – tête magnétique. Exemple de classe de tête magnétique :
La machine contient des « m-configurations » grâce auxquelles elle peut décider quoi faire ensuite. En langage moderne – États et gestionnaires d’État. Exemple de gestionnaire d’état :
FiniteStateControlDelegate? delegate = null;
void handle({required String symbol}) {
if (symbol == OPCODE_PRINT) {
final argument = delegate?.nextSymbol();
print(argument);
}
else if (symbol == OPCODE_GENERATE_RANDOM_NUMBER_FROM_ZERO_TO_AND_WRITE_AFTER) {
final to = int.tryParse(delegate!.nextSymbol())!;
final value = new Random().nextInt(to);
delegate!.nextSymbol();
delegate!.write(value.toString());
}
else if (symbol == OPCODE_INPUT_TO_NEXT) {
final input = stdin.readLineSync()!;
delegate?.nextSymbol();
delegate?.write(input);
}
else if (symbol == OPCODE_COPY_FROM_TO) {
final currentIndex = delegate!.index();
и т.д.
Après cela, vous devez créer des « configurations ». En langage moderne, ce sont des codes d’opération (opcodes) et leurs gestionnaires. Exemples d’opcodes :
const OPCODE_PRINT = "print";
const OPCODE_INCREMENT_NEXT = "increment next";
const OPCODE_DECREMENT_NEXT = "decrement next";
const OPCODE_IF_PREVIOUS_NOT_EQUAL = "if previous not equal";
const OPCODE_MOVE_TO_INDEX = "move to index";
const OPCODE_COPY_FROM_TO = "copy from index to index";
const OPCODE_INPUT_TO_NEXT = "input to next";
const OPCODE_GENERATE_RANDOM_NUMBER_FROM_ZERO_TO_AND_WRITE_AFTER = "generate random number from zero to next and write after";
N’oubliez pas de créer un opcode et un gestionnaire d’arrêt, sinon vous ne pourrez pas prouver ou échouer (sic !) le problème de résolution.
Maintenant, en utilisant le modèle « médiateur », nous connectons toutes les classes de la classe Turing Machine, créons une instance de la classe, enregistrons le programme via un magnétophone, chargeons la bande et vous pouvez l’utiliser !
Pour moi personnellement, la question de savoir ce qui était primaire restait intéressante : création d’une calculatrice universelle ou preuve du “Entscheidungsproblem” à la suite de laquelle, comme sous-produit, une calculatrice est apparue.
Cassettes
Pour m’amuser, j’ai enregistré plusieurs programmes cassettes pour ma version de la machine.
Bonjour tout le monde
hello world
stop
Считаем до 16-ти
0
if previous not equal
16
copy from index to index
1
8
print
?
move to index
0
else
copy from index to index
1
16
print
?
print
Finished!
stop
Самой интересной задачей было написание Quine программы, которая печатает свой исходный код, для одноленточной машины. Первые 8 часов мне казалось что эта задача не решаема с таким малым количеством опкодов, однако всего через 16 часов оказалось что я был не прав.
Dans cette note, je décrirai le processus de lecture du joystick, de changement de position du sprite, de retournement horizontal, de l’émulateur Sega Genesis et potentiellement de la console elle-même.
La lecture des clics et le traitement des « événements » d’un joystick shogi se déroulent selon le schéma suivant :
Demande de combinaison de bits de boutons enfoncés
Lecture de morceaux de boutons enfoncés
Traitement au niveau de la logique du jeu
Pour déplacer le sprite squelette, nous devons stocker les variables de la position actuelle.
RAM
Les variables logiques du jeu sont stockées dans la RAM ; jusqu’à présent, les gens n’ont rien trouvé de mieux. Déclarons les adresses de variables et modifions le code de rendu :
Comme vous pouvez le constater, l’adresse disponible pour le travail commence à 0xFF0000 et se termine à 0xFFFFFF, au total 64 Ko de mémoire sont à notre disposition. Les positions des squelettes sont déclarées à skeletonXpos, skeletonYpos, flip horizontal à skeletonHorizontalFlip.
Joypad
Par analogie avec VDP, le travail avec les joypads s’effectue via deux ports séparément – ; port de contrôle et port de données, pour le premier 0xA10009 et 0xA10003 co-no. Il y a une fonctionnalité intéressante lorsque l’on travaille avec un joypad : Vous devez d’abord demander une combinaison de boutons pour l’interrogation, puis, après avoir attendu une mise à jour sur le bus, lire les pressions requises. Pour les boutons C/B et D-pad, il s’agit de 0x40, exemple ci-dessous :
move.b #$40,joypad_one_control_port; C/B/Dpad
nop ; bus sync
nop ; bus sync
move.b joypad_one_data_port,d2
rts
Dans le registre d2, l’état des boutons enfoncés ou non enfoncés restera, en général, ce qui a été demandé via le port date restera. Après cela, accédez à la visionneuse de registre Motorola 68000 de votre émulateur préféré, voyez à quoi est égal le registre d2, en fonction des frappes au clavier. De manière intelligente, vous pouvez le découvrir dans le manuel, mais nous ne les croyons pas sur parole. Traitement ultérieur des boutons enfoncés dans le registre d2
cmp #$FFFFFF7B,d2; handle left
beq MoveLeft
cmp #$FFFFFF77,d2; handle right
beq MoveRight
cmp #$FFFFFF7E,d2; handle up
beq MoveUp
cmp #$FFFFFF7D,d2; handle down
beq MoveDown
rts
Проверять нужно конечно отдельные биты, а не целыми словами, но пока и так сойдет. Теперь осталось самое простое – написать обработчики всех событий перемещения по 4-м направлениям. Для этого меняем переменные в RAM, и запускаем процедуру перерисовки.
Пример для перемещения влево + изменение горизонтального флипа:
После добавления всех обработчиков и сборки, вы увидите как скелет перемещается и поворачивается по экрану, но слишком быстро, быстрее самого ежа Соника.
Не так быстро!
Чтобы замедлить скорость игрового цикла, существуют несколько техник, я выбрал самую простую и не затрагивающую работу с внешними портами – подсчет цифры через регистр пока она не станет равна нулю.
Après cela, le squelette fonctionne plus lentement, ce qui était nécessaire. Comme je le sais, l’option la plus courante pour « ralentir » consiste à compter le drapeau de synchronisation verticale ; vous pouvez compter combien de fois l’écran a été dessiné, étant ainsi lié à un fps spécifique.
Dans cet article, je vais décrire comment dessiner des sprites à l’aide de l’émulateur VDP de la console Sega Genesis. Le processus de rendu des sprites est très similaire au rendu des tuiles :
Chargement des couleurs dans CRAM
Importation de parties de sprites 8×8 dans la VRAM
À l’aide d’ImaGenesis, convertissons-le en couleurs CRAM et modèles VRAM pour l’assembleur. Après cela, nous obtiendrons deux fichiers au format asm, puis nous réécrirons les couleurs à la taille du mot et les carreaux devront être placés dans le bon ordre pour le dessin. Information intéressante : vous pouvez basculer l’auto-incrémentation VDP via le registre 0xF sur la taille des mots, cela supprimera l’incrément d’adresse du code de remplissage de couleur CRAM.
VRAM
Le manuel Shogi a le bon ordre des tuiles pour les grands sprites, mais nous sommes plus intelligents, nous prendrons donc les index du blog ChibiAkumas, commençons à compter à partir de l’index 0 :
0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
Pourquoi tout est à l’envers ? Que veux-tu, la console est japonaise ! Cela pourrait même être de droite à gauche ! Modifions manuellement l’ordre dans le fichier de sprite asm :
Pour dessiner un sprite, il ne reste plus qu’à remplir la Table des Sprites
Tableau des Sprites
La table des sprites est remplie en VRAM, l’adresse de son emplacement est inscrite dans le registre VDP 0x05, l’adresse est encore une fois délicate, vous pouvez la voir dans le manuel, un exemple pour l’adresse F000 :
Ок, теперь запишем наш спрайт в таблицу. Для этого нужно заполнить “структуру” данных состоящую из четырех word. Бинарное описание структуры вы можете найти в мануале. Лично я сделал проще, таблицу спрайтов можно редактировать вручную в эмуляторе Exodus.
Les paramètres de structure ressortent clairement du nom, par exemple XPos, YPos – coordonnées, Tuiles – numéro de la tuile de départ pour le dessin, HSize, VSize – tailles de sprite en ajoutant les parties 8×8, HFlip, VFlip – rotation matérielle du sprite horizontalement et verticalement. Il est très important de se rappeler que les sprites peuvent être hors écran, c’est un comportement correct, car… décharger les sprites hors écran de la mémoire – une activité assez gourmande en ressources. Après avoir rempli les données dans l’émulateur, elles doivent être copiées de la VRAM à l’adresse 0xF000, Exodus prend également en charge cette fonctionnalité. Par analogie avec le dessin des tuiles, on accède d’abord au port de contrôle VDP pour commencer l’écriture à l’adresse 0xF000, puis on écrit la structure sur le port de données. Je vous rappelle que la description de l’adressage VRAM peut être lue dans le manuel ou dans le blog Algorithme sans nom .
En résumé, l’adressage VDP fonctionne comme ceci : [..DC BA98 7654 3210…. …. …. ..FE] Où hex est la position du bit dans l’adresse souhaitée. Les deux premiers bits correspondent au type de commande demandé, par exemple 01 – écrire dans la VRAM. Ensuite, pour l’adresse 0XF000, il s’avère : 0111 0000 0000 0000 0000 0000 0000 0011 (70000003)
Dans cet article, je vais décrire comment afficher une image à partir de tuiles sur l’émulateur Sega Genesis à l’aide de l’assembleur. L’image de démarrage Demens Deum dans l’émulateur Exodus ressemblera à ceci :
Le processus de sortie d’une image PNG à l’aide de tuiles se fait étape par étape :
Réduire l’image à la taille de l’écran Shogi
Convertir le format PNG en code de données d’assemblage, séparé en couleurs et en mosaïques
Charger une palette de couleurs dans CRAM
Chargement de tuiles/motifs dans la VRAM
Chargement des index de tuiles aux adresses du plan A/B dans la VRAM
Vous pouvez réduire l’image à la taille de l’écran Shogi à l’aide de votre éditeur graphique préféré, tel que Blender.
Conversion PNG
Pour convertir des images, vous pouvez utiliser l’outil ImaGenesis ; pour travailler sous wine, les bibliothèques Visual Basic 6 sont requises, elles peuvent être installées à l’aide de winetricks (winetricks vb6run), ou RICHTX32.OCX peut être téléchargé depuis Internet et placé dans le dossier de l’application pour un fonctionnement correct.< /p>
Dans ImaGenesis, vous devez sélectionner une couleur 4 bits, exporter les couleurs et les tuiles vers deux fichiers au format assembleur. Ensuite, dans le fichier avec les couleurs, vous devez mettre chaque couleur dans un mot (2 octets), pour cela vous utilisez l’opcode dc.w.
Comme vous pouvez le voir dans l’exemple ci-dessus, les tuiles sont une grille 8×8 composée d’indices de palette de couleurs CRAM.
Couleurs dans CRAM
Le chargement dans la CRAM s’effectue en définissant une commande de chargement de couleur sur une adresse CRAM spécifique dans le port de contrôle (contrôle vdp). Le format de commande est décrit dans le manuel du logiciel Sega Genesis (1989), j’ajouterai juste qu’il suffit d’ajouter 0x20000 à l’adresse pour passer à la couleur suivante.
Ensuite, vous devez charger la couleur dans le port de données (données vdp) ; La façon la plus simple de comprendre le chargement est d’utiliser l’exemple ci-dessous :
Vient ensuite le chargement des tuiles/motifs dans la mémoire vidéo VRAM. Pour cela, sélectionnez une adresse dans la VRAM, par exemple 0x00000000. Par analogie avec la CRAM, nous contactons le port de contrôle VDP avec une commande pour écrire dans la VRAM et l’adresse de départ.
Après cela, vous pouvez télécharger des mots longs vers la VRAM ; par rapport à la CRAM, vous n’avez pas besoin de spécifier l’adresse pour chaque mot long, car il existe un mode d’incrémentation automatique de la VRAM. Vous pouvez l’activer en utilisant l’indicateur de registre VDP 0x0F (dc.b $02)
Maintenant, nous devons remplir l’écran avec des tuiles en fonction de leur index. Pour ce faire, la VRAM est remplie à l’adresse Plane A/B, qui est inscrite dans les registres VDP (0x02, 0x04). Plus d’informations sur l’adressage délicat se trouvent dans le manuel de Sega ; dans mon exemple, l’adresse VRAM est 0xC000, téléchargeons les index ici.
Votre image remplira de toute façon l’espace VRAM hors écran, donc après avoir dessiné l’espace de l’écran, votre moteur de rendu devrait arrêter de dessiner et continuer lorsque le curseur se déplace vers une nouvelle ligne. Il existe de nombreuses options pour implémenter cela ; j’ai utilisé la version la plus simple de comptage sur deux registres du compteur de largeur d’image et du compteur de position du curseur.
Exemple de code :
move.w #0,d0 ; column index
move.w #1,d1 ; tile index
move.l #$40000003,(vdp_control_port) ; initial drawing location
move.l #2500,d7 ; how many tiles to draw (entire screen ~2500)
imageWidth = 31
screenWidth = 64
FillBackgroundStep:
cmp.w #imageWidth,d0
ble.w FillBackgroundStepFill
FillBackgroundStep2:
cmp.w #imageWidth,d0
bgt.w FillBackgroundStepSkip
FillBackgroundStep3:
add #1,d0
cmp.w #screenWidth,d0
bge.w FillBackgroundStepNewRow
FillBackgroundStep4:
dbra d7,FillBackgroundStep ; loop to next tile
Stuck:
nop
jmp Stuck
FillBackgroundStepNewRow:
move.w #0,d0
jmp FillBackgroundStep4
FillBackgroundStepFill:
move.w d1,(vdp_data_port) ; copy the pattern to VPD
add #1,d1
jmp FillBackgroundStep2
FillBackgroundStepSkip:
move.w #0,(vdp_data_port) ; copy the pattern to VPD
jmp FillBackgroundStep3
Après cela, il ne reste plus qu’à assembler la rom à l’aide de vasm, lancer le simulateur et voir l’image.
Débogage
Tout ne fonctionnera pas tout de suite, c’est pourquoi je voudrais recommander les outils d’émulation Exodus suivants :
Débogueur de processeur M68k
Modification du nombre de cycles du processeur m68k (pour le mode ralenti dans le débogueur)
Visionneuses CRAM, VRAM, plan A/B
Lisez attentivement la documentation de m68k, les opcodes utilisés (tout n’est pas aussi évident qu’il y paraît à première vue)
Afficher des exemples de code de jeu/démontage sur github
Implémenter des sous-programmes d’exceptions de processeur et les traiter
Les pointeurs vers les sous-programmes d’exception du processeur sont placés dans l’en-tête de la rom ; il existe également un projet sur GitHub avec un débogueur d’exécution interactif pour Sega, appelé genesis-debugger.
Utilisez tous les outils disponibles, ayez un bon codage à l’ancienne et que Blast Processing soit avec vous !
Dans cet article, je vais décrire comment charger des couleurs dans la palette Shogi en langage assembleur. Le résultat final dans l’émulateur Exodus ressemblera à ceci :
Pour faciliter le processus, trouvez un pdf sur Internet appelé Genesis Software Manual (1989), il décrit l’ensemble du processus de manière très détaillée, en fait, cette note est un commentaire sur le manuel original.Genesis Software Manual (1989). /p>
Pour écrire des couleurs sur la puce VDP de l’émulateur Sega, vous devez effectuer les opérations suivantes :
Désactiver la protection TMSS
Écrire les paramètres corrects dans les registres VDP
Écrivez les couleurs souhaitées dans CRAM
Pour l’assemblage, nous utiliserons vasmm68k_mot et un éditeur de texte préféré, par exemple echo. Le montage s’effectue avec la commande :
Порты VDP
VDP чип общается с M68K через два порта в оперативной памяти – порт контроля и порт данных.
По сути:
Через порт контроля можно выставлять значения регистрам VDP.
Также порт контроля является указателем на ту часть VDP (VRAM, CRAM, VSRAM etc.) через которую передаются данные через порт данных
Интересная информация: Сега сохранила совместимость с играми Master System, на что указывает MODE 4 из мануала разработчика, в нем VDP переключается в режим Master System.
Объявим порты контроля и данных:
vdp_data_port = $C00000
Отключить систему защиты TMSS
Защита от нелицензионных игр TMSS имеет несколько вариантов разблокировки, например требуется чтобы до обращения к VDP в адресном регистре A1 лежала строка “SEGA”.
MOVE.B A1,D0; Получаем версию хардвары цифрой из A1 в регистр D0
ANDI.B 0x0F,D0; По маске берем последние биты, чтобы ничего не сломать
BEQ.B SkipTmss; Если версия равна 0, скорее всего это японка или эмулятор без включенного TMSS, тогда идем в сабрутину SkipTmss
MOVE.L "SEGA",A1; Или записываем строку SEGA в A1
Écrire les paramètres corrects dans les registres VDP
Pourquoi définir les paramètres corrects dans les registres VDP ? L'idée est que VDP peut faire beaucoup de choses, donc avant le rendu, vous devez l'initialiser avec les fonctionnalités nécessaires, sinon il ne comprendra tout simplement pas ce qu'il attend de lui.
Chaque registre est responsable d'un réglage/mode de fonctionnement spécifique. Le manuel Segov indique tous les bits/drapeaux pour chacun des 24 registres, une description des registres eux-mêmes.
Prenons des paramètres prêts à l'emploi avec les commentaires du blog bigevilcorporation :
VDPReg0: dc.b $14 ; 0: H interrupt on, palettes on
VDPReg1: dc.b $74 ; 1: V interrupt on, display on, DMA on, Genesis mode on
VDPReg2: dc.b $30 ; 2: Pattern table for Scroll Plane A at VRAM $C000
; (bits 3-5 = bits 13-15)
VDPReg3: dc.b $00 ; 3: Pattern table for Window Plane at VRAM $0000
; (disabled) (bits 1-5 = bits 11-15)
VDPReg4: dc.b $07 ; 4: Pattern table for Scroll Plane B at VRAM $E000
; (bits 0-2 = bits 11-15)
VDPReg5: dc.b $78 ; 5: Sprite table at VRAM $F000 (bits 0-6 = bits 9-15)
VDPReg6: dc.b $00 ; 6: Unused
VDPReg7: dc.b $00 ; 7: Background colour - bits 0-3 = colour,
; bits 4-5 = palette
VDPReg8: dc.b $00 ; 8: Unused
VDPReg9: dc.b $00 ; 9: Unused
VDPRegA: dc.b $FF ; 10: Frequency of Horiz. interrupt in Rasters
; (number of lines travelled by the beam)
VDPRegB: dc.b $00 ; 11: External interrupts off, V scroll fullscreen,
; H scroll fullscreen
VDPRegC: dc.b $81 ; 12: Shadows and highlights off, interlace off,
; H40 mode (320 x 224 screen res)
VDPRegD: dc.b $3F ; 13: Horiz. scroll table at VRAM $FC00 (bits 0-5)
VDPRegE: dc.b $00 ; 14: Unused
VDPRegF: dc.b $02 ; 15: Autoincrement 2 bytes
VDPReg10: dc.b $01 ; 16: Vert. scroll 32, Horiz. scroll 64
VDPReg11: dc.b $00 ; 17: Window Plane X pos 0 left
; (pos in bits 0-4, left/right in bit 7)
VDPReg12: dc.b $00 ; 18: Window Plane Y pos 0 up
; (pos in bits 0-4, up/down in bit 7)
VDPReg13: dc.b $FF ; 19: DMA length lo byte
VDPReg14: dc.b $FF ; 20: DMA length hi byte
VDPReg15: dc.b $00 ; 21: DMA source address lo byte
VDPReg16: dc.b $00 ; 22: DMA source address mid byte
VDPReg17: dc.b $80 ; 23: DMA source address hi byte,
; memory-to-VRAM mode (bits 6-7)
Ok, allons maintenant au port de contrôle et écrivons tous les indicateurs dans les registres VDP :
move.l #VDPRegisters,a0 ; Пишем адрес таблицы параметров в A1
move.l #$18,d0 ; Счетчик цикла - 24 = 18 (HEX) в D0
move.l #$00008000,d1 ; Готовим команду на запись в регистр VDP по индексу 0, по мануалу - 1000 0000 0000 0000 (BIN) = 8000 (HEX)
FillInitialStateForVDPRegistersLoop:
move.b (a0)+,d1 ; Записываем в D1 итоговое значение регистра VDP из таблицы параметров, на отправку в порт контроля VDP
move.w d1,vdp_control_port ; Отправляем итоговую команду + значение из D1 в порт контроля VDP
add.w #$0100,d1 ; Поднимаем индекс регистра VDP на 1 (бинарное сложение +1 к индексу по мануалу Сеги)
dbra d0,FillInitialStateForVDPRegistersLoop ; Уменьшаем счетчик регистров, продолжаем цикл если необходимо
Самое сложное это прочитать мануал и понять в каком формате подаются данные на порт контроля, опытные разработчики разберутся сразу, а вот неопытные… Немного подумают и поймут, что синтаксис для записи регистров такой:
0B100(5 бит – индекс регистра)(8 бит/байт – значение)
0B1000001001000101 – записать в регистр VDP 2 (00010), значение флажков 01000101.
Записать нужные цвета в CRAM
Далее идем писать два цвета в память цветов CRAM (Color RAM). Для этого пишем в порт контроля команду на доступ к цвету по индексу 0 в CRAM и отправляем по дата порту цвет. Все!
Пример:
move.l #$C0000000,vdp_control_port ; Доступ к цвету по индексу 0 в CRAM через порт контроля
move.w #228,d0; Цвет в D0
move.w d0,vdp_data_port; Отправляем цвет в порт данных
Après avoir construit et exécuté l'émulateur dans Exodus, votre écran devrait être rempli de la couleur 228.
Remplissons-le avec une deuxième couleur, basée sur le dernier octet 127.
move.l #$C07f0000,vdp_control_port ; Доступ к цвету по байту 127 в CRAM через порт контроля
move.w #69,d0; Цвет в D0
move.w d0,vdp_data_port; Отправляем цвет в порт данных
Le premier article consacré à l’écriture de jeux pour la console classique Sega Genesis dans Motorola 68000 Assembly.
Écrivons la boucle infinie la plus simple pour Sega. Pour cela nous aurons besoin : d’un assembleur, d’un émulateur avec un désassembleur, d’un éditeur de texte préféré, d’une compréhension de base de la structure du rhum Sega.
Pour le développement, j’utilise mon propre assembleur/désassembleur Gen68KryBaby :
L’outil est développé en Python 3, pour l’assemblage un fichier avec l’extension .asm ou .gen68KryBabyDisasm est fourni en entrée, la sortie est un fichier avec l’extension .gen68KryBabyAsm.bin, qui peut être exécuté dans l’émulateur ou sur une vraie console (attention, éloignez-vous, la console risque d’exploser !)
Le désassemblage des roms est également pris en charge, pour cela vous devez soumettre un fichier rom en entrée, sans les extensions .asm ou .gen68KryBabyDisasm. Le support des opcodes augmentera ou diminuera en fonction de mon intérêt pour le sujet et de la participation des contributeurs.
Structure
L’en-tête de la ROM Sega occupe les 512 premiers octets. Il contient des informations sur le jeu, le nom, les périphériques pris en charge, la somme de contrôle et d’autres indicateurs système. Je suppose que sans titre, la console ne regardera même pas le rhum, pensant que c’est incorrect, en disant “qu’est-ce que tu me donnes ici ?”
Après l’en-tête, il y a un sous-programme/sous-programme Reset, avec lequel commence le travail du processeur m68K. D’accord, c’est une petite affaire – trouver des opcodes (codes d’opération), à savoir ne rien faire (!) et passer au sous-programme à l’adresse en mémoire. En cherchant sur Google, vous pouvez trouver l’opcode NOP, qui ne fait rien, et l’opcode JSR, qui effectue un saut inconditionnel vers l’adresse de l’argument, c’est-à-dire qu’il déplace simplement le chariot là où nous le demandons, sans aucun caprice.
Rassembler tout cela
Le donneur d’en-tête de la rom était l’un des jeux de la version bêta, actuellement enregistré sous forme de données hexadécimales.
Код программы со-но представляет из себя объявление сабрутины Reset/EntryPoint в 512 (0x200) байте, NOP, возврат каретки к 0x00000200, таким образом мы получим бесконечный цикл.
Запускаем ром 1infiniteloop.asm.gen68KryBabyAsm.bin в режиме дебаггера эмулятора Exodus/Gens, смотрим что m68K корректно считывает NOP, и бесконечно прыгает к EntryPoint в 0x200 на JSR
Здесь должен быть Соник показывающий V, но он уехал на Вакен.
Dans cette note, j’écrirai sur l’importance des décisions architecturales lors du développement, de la prise en charge d’une application et dans un environnement de développement en équipe.
Dans ma jeunesse, j’ai travaillé sur une application de commande de taxi. Dans le programme, vous pouvez sélectionner un point de prise en charge, un point de dépôt, calculer le coût du trajet, le type de tarif et, effectivement, commander un taxi. J’ai reçu l’application lors de la dernière étape du pré-lancement ; après avoir ajouté plusieurs correctifs, l’application a été publiée dans l’AppStore. Déjà à ce stade, toute l’équipe a compris qu’il était très mal implémenté, que les modèles de conception n’étaient pas utilisés, que tous les composants du système étaient étroitement liés, en général, il était possible de l’écrire dans une grande classe continue (objet Dieu), rien n’aurait changé, de même la manière dont les classes ont mélangé leurs frontières de responsabilité et, dans leur masse totale, se sont superposées dans un couplage mort. Plus tard, la direction a décidé d’écrire l’application à partir de zéro, en utilisant la bonne architecture, ce qui a été fait et le produit final a été implémenté chez plusieurs dizaines de clients B2B.
Cependant, je vais décrire un curieux incident de l’architecture passée, dont je me réveille parfois avec des sueurs froides au milieu de la nuit, ou dont je me souviens soudainement au milieu de la journée et me mets à rire hystériquement. Le problème, c’est que je n’ai pas réussi à frapper le gars sur le poteau du premier coup, ce qui a fait échouer la plupart des applications, mais avant tout.
C’était une journée de travail ordinaire, l’un des clients a reçu pour tâche d’affiner légèrement la conception de l’application – Il est simple de déplacer l’icône au centre de l’écran de sélection de l’adresse de retrait de quelques pixels. Eh bien, après avoir professionnellement estimé la tâche à 10 minutes, j’ai élevé l’icône de 20 pixels, ne me doutant absolument de rien, j’ai décidé de vérifier la commande de taxi.
Quoi ? L’application n’affiche plus le bouton de commande ? Comment est-ce arrivé ?
Je n’en croyais pas mes yeux ; après avoir augmenté l’icône de 20 pixels, l’application a cessé d’afficher le bouton Continuer la commande. Après avoir annulé le changement, j’ai revu le bouton. Quelque chose n’allait pas ici. Après avoir passé 20 minutes dans le débogueur, j’en avais un peu marre de dérouler les spaghettis d’appels à des classes qui se chevauchent, mais j’ai découvert que *déplacer l’image change vraiment la logique de l’application*
Tout était question de l’icône au centre – un homme sur un poteau, en déplaçant la carte il sautait pour animer le mouvement de la caméra, cette animation était suivie de la disparition du bouton en bas. Apparemment, le programme pensait que l’homme décalé de 20 pixels était en train de sauter, donc selon sa logique interne, il a caché le bouton de confirmation.
Comment cela peut-il arriver ? L’*état* de l’écran ne dépend-il vraiment pas du modèle de la machine à états, mais de la *représentation* de la position de l’homme sur le poteau ?
Il s’est avéré que chaque fois que la carte est dessinée, l’application *a poussé visuellement* au milieu de l’écran et a vérifié ce qu’il y avait là, s’il y a un homme sur un poteau, cela signifie que l’animation de changement de carte est terminée et doit être affichée bouton. Si l’homme n’est pas là, alors la carte est décalée et le bouton doit être masqué.
Dans l’exemple ci-dessus, tout va bien, d’une part, c’est un exemple de machines Goldberg (machines abscons), et d’autre part, un exemple de la réticence du développeur à interagir d’une manière ou d’une autre avec d’autres développeurs de l’équipe (essayez de le comprendre sans moi), troisièmement, vous pouvez lister tous les problèmes selon SOLID, les modèles (odeurs de code), les violations MVC et bien plus encore.
Essayez de ne pas faire cela, développez-vous dans toutes les directions possibles, aidez vos collègues dans leur travail. Bonne année à tous)
Dans cet article, je décrirai l’utilisation du classificateur de texte fasttext.
Fasttext – bibliothèque d’apprentissage automatique pour la classification de texte. Essayons de lui apprendre à identifier un groupe de métal par le titre de la chanson. Pour ce faire, nous utilisons l’apprentissage supervisé à l’aide d’un ensemble de données.
Créons un ensemble de données de chansons avec des noms de groupe :
В результате мы получим список классов на которые похож данный пример, с указанием уровня похожести цифрой, в нашем случае похожесть названия песни Bleed на одну из групп датасета.
Для того чтобы модель fasttext умела работать с датасетом выходящим за границы обучающей выборки, используют режим autotune с использованием файла валидации (файл тест). Во время автотюна fasttext подбирает оптимальные гиперпараметры модели, проводя валидацию результата на выборке из тест файла. Время автотюна ограничивается пользователем в самостоятельно, с помощью передачи аргумента autotuneDuration.
Пример создания модели с использованием файла тест:
Dans cette note, je décrirai le processus d’appel de fonctions C depuis l’assembleur. Essayons d’appeler printf(“Hello World!\n”); et quitter(0);
message: db "Hello, world!", 10, 0
section .text
extern printf
extern exit
global main
main:
xor rax, rax
mov rdi, message
call printf
xor rdi, rdi
call exit
Tout est beaucoup plus simple qu’il n’y paraît, dans la section .rodata nous décrirons les données statiques, dans ce cas la ligne “Hello, world!”, 10 est un caractère de nouvelle ligne, et nous n’oublions pas non plus de l’annuler.
Dans la section code nous déclarerons les fonctions externes printf, exit des bibliothèques stdio, stdlib, et nous déclarerons également la fonction d’entrée main :
extern printf
extern exit
global main
Nous passons 0 au registre de retour depuis la fonction rax, vous pouvez utiliser mov rax, 0; mais pour accélérer, ils utilisent xor rax, rax ; Ensuite, nous passons un pointeur vers la chaîne au premier argument :
Dans cet article, je décrirai le processus de configuration de l’EDI, en écrivant le premier Hello World en assembleur x86_64 pour le système d’exploitation Ubuntu Linux. Commençons par installer l’IDE SASM, l’assembleur nasm :
Code Hello World extrait du blog James Fisher, adapté pour l'assemblage et le débogage dans SASM. La documentation SASM indique que le point d'entrée doit être une fonction nommée main, sinon le débogage et la compilation du code seront incorrects. Qu'avons-nous fait dans ce code ? J'ai passé un appel système – accès au noyau du système d'exploitation Linux avec des arguments corrects dans les registres, un pointeur vers une chaîne dans la section données.
Sous une loupe
Regardons le code plus en détail :
global – директива ассемблера позволяющая задавать глобальные символы со строковыми именами. Хорошая аналогия – интерфейсы заголовочных файлов языков C/C++. В данном случае мы задаем символ main для функции входа.
section – директива ассемблера позволяющая задавать секции (сегменты) кода. Директивы section или segment равнозначны. В секции .text помещается код программы.
Обьявляем начало функции main. В ассемблере функции называются подпрограммами (subroutine)
Первая машинная команда mov – помещает значение из аргумента 1 в аргумент 2. В данном случае мы переносим значение регистра rbp в rsp. Из комментария можно понять что эту строку добавил SASM для упрощения отладки. Видимо это личные дела между SASM и дебаггером gdb.
Далее посмотрим на код до сегмента данных .rodata, два вызова syscall, первый выводит строку Hello World, второй обеспечивает выход из приложения с корректным кодом 0.
Представим себе что регистры это переменные с именами rax, rdi, rsi, rdx, r10, r8, r9. По аналогии с высокоуровневыми языками, перевернем вертикальное представление ассемблера в горизонтальное, тогда вызов syscall будет выглядеть так:
Тогда вызов печати текста:
Вызов exit с корректным кодом 0:
Рассмотрим аргументы подробнее, в заголовочном файле asm/unistd_64.h находим номер функции __NR_write – 1, далее в документации смотрим аргументы для write:
ssize_t write(int fd, const void *buf, size_t count);
Первый аргумент – файловый дескриптор, второй – буфер с данными, третий – счетчик байт для записи в дескриптор. Ищем номер файлового дескриптора для стандартного вывода, в мануале по stdout находим код 1. Далее дело за малым, передать указатель на буфер строки Hello World из секции данных .rodata – msg, счетчик байт – msglen, передать в регистры rax, rdi, rsi, rdx корректные аргументы и вызвать syscall.
Обозначение константных строк и длины описывается в мануале nasm:
La table de hachage vous permet d’implémenter une structure de données de tableau associatif (dictionnaire) avec des performances moyennes O(1) pour les opérations d’insertion, de suppression et de recherche.
Vous trouverez ci-dessous un exemple de l’implémentation la plus simple d’une carte de hachage dans nodeJS :
Comment ça marche ? Surveillez vos mains :
À l’intérieur de la carte de hachage se trouve un tableau
À l’intérieur de l’élément du tableau se trouve un pointeur vers le premier nœud de la liste chaînée
La mémoire est allouée à un tableau de pointeurs (par exemple, 65 535 éléments)
Ils implémentent une fonction de hachage, la clé du dictionnaire est l’entrée, et en sortie elle peut tout faire, mais à la fin elle renvoie l’index de l’élément du tableau
Comment fonctionne l’enregistrement :
A l’entrée, il y a une paire de clés – valeur
La fonction de hachage renvoie l’index par clé
Obtenir un nœud de liste chaînée à partir d’un tableau par index
Vérifiez si cela correspond à la clé
Si cela correspond, remplacez la valeur
S’il ne correspond pas, passez au nœud suivant jusqu’à ce que nous trouvions ou trouvions un nœud avec la clé requise.
Si le nœud n’est toujours pas trouvé, créez-le à la fin de la liste chaînée
Fonctionnement de la recherche par clé :
A l’entrée, il y a une paire de clés – valeur
La fonction de hachage renvoie l’index par clé
Obtenir un nœud de liste chaînée à partir d’un tableau par index
Vérifiez si cela correspond à la clé
Si cela correspond, renvoyez la valeur
S’il ne correspond pas, passez au nœud suivant jusqu’à ce que nous trouvions ou trouvions un nœud avec la clé requise.
Pourquoi avons-nous besoin d’une liste chaînée dans un tableau ? En raison de collisions possibles lors du calcul de la fonction de hachage. Dans ce cas, plusieurs paires clé-valeur différentes seront situées au même index dans le tableau, auquel cas la liste chaînée est parcourue pour trouver la clé requise.
Pour travailler avec des ressources sous Android via ndk – En C++, il existe plusieurs options :
Utiliser l’accès aux ressources à partir d’un fichier apk à l’aide d’AssetManager
Téléchargez les ressources depuis Internet et décompressez-les dans le répertoire de l’application, utilisez-les à l’aide des méthodes C++ standard
Méthode combinée – accédez à l’archive avec les ressources dans l’apk via AssetManager, décompressez-les dans le répertoire de l’application, puis utilisez-les à l’aide des méthodes C++ standard
Ensuite, je décrirai la méthode d’accès combinée utilisée dans le moteur de jeu Flame Steel Engine. Lorsque vous utilisez SDL, vous pouvez simplifier l’accès aux ressources à partir d’un apk ; la bibliothèque encapsule les appels à AssetManager, offrant des interfaces similaires à stdio (fopen, fread, fclose, etc.)
Après avoir téléchargé l’archive de l’apk vers le tampon, vous devez remplacer le répertoire de travail actuel par le répertoire de l’application, il est disponible pour l’application sans obtenir d’autorisations supplémentaires. Pour ce faire, nous utiliserons un wrapper SDL :
chdir(SDL_AndroidGetInternalStoragePath());
Ensuite, écrivez l’archive du tampon vers le répertoire de travail actuel en utilisant fopen, fwrite, fclose. Une fois l’archive dans un répertoire accessible en C++, décompressez-la. Les archives Zip peuvent être décompressées à l’aide d’une combinaison de deux bibliothèques : minizip et zlib, le premier peut travailler avec la structure des archives, tandis que le second décompresse les données. Pour gagner plus de contrôle et faciliter le portage, j’ai implémenté mon propre format d’archive sans compression appelé FSChest (Flame Steel Chest). Ce format prend en charge l’archivage d’un répertoire avec des fichiers et le déballage ; La hiérarchie des dossiers n’est pas prise en charge ; vous pouvez uniquement travailler avec des fichiers. On connecte l’en-tête de la bibliothèque FSChest, on décompresse l’archive :
Après le déballage, les interfaces C/C++ auront accès aux fichiers de l’archive. Ainsi, je n’ai pas eu à réécrire tout le travail avec les fichiers dans le moteur, mais j’ai seulement ajouté le déballage des fichiers au stade du lancement.
Supposons que nous devions implémenter un simple interpréteur de bytecode, quelle approche pour implémenter cette tâche devrions-nous choisir ?
Structure des données La pile offre la possibilité d’implémenter une machine de bytecode simple. Les fonctionnalités et les implémentations des machines à pile sont décrites dans de nombreux articles sur l’Internet occidental et national ; je mentionnerai simplement que la machine virtuelle Java est un exemple de machine à pile.
Le principe de fonctionnement de la machine est simple, un programme contenant des données et des codes d’opération (opcodes) est fourni à l’entrée, et les opérations nécessaires sont mises en œuvre à l’aide de manipulations avec la pile. Regardons un exemple de programme de bytecode de ma machine à pile :
пMVkcatS olleHП
En sortie, nous recevrons la chaîne « Hello StackVM ». La machine à pile lit le programme de gauche à droite, chargeant les données caractère par caractère sur la pile lorsqu’un opcode apparaît dans le symbole – implémente la commande en utilisant la pile.
Exemple d’implémentation d’une stack machine dans nodejs :
Notation polonaise inversée (RPN)
Les machines Stack sont également faciles à utiliser pour mettre en œuvre des calculatrices, pour cela elles utilisent la notation polonaise inversée (notation suffixe). Exemple de notation infixe régulière : 2*2+3*4
Convertit en RPN : 22*34*+
Pour compter l’enregistrement postfix, nous utilisons une machine à pile : 2– en haut de la pile (pile : 2) 2– en haut de la pile (pile : 2,2) *– obtenir le haut de la pile deux fois, multiplier le résultat, l’envoyer en haut de la pile (pile : 4) 3– en haut de la pile (pile : 4, 3) 4– en haut de la pile (pile : 4, 3, 4) *– obtenir le haut de la pile deux fois, multiplier le résultat, l’envoyer en haut de la pile (pile : 4, 12) +– récupérez deux fois le haut de la pile, ajoutez le résultat, envoyez-le en haut de la pile (pile : 16)
Comme vous pouvez le voir – le résultat des opérations 16 reste sur la pile, il peut être imprimé en implémentant des opcodes d’impression de pile, par exemple : p22*34*+P
P – Opcode de démarrage de l’impression de la pile, p – opcode pour terminer l’impression de la pile et envoyer la ligne finale pour le rendu. Pour convertir les opérations arithmétiques d’infixe en suffixe, l’algorithme d’Edsger Dijkstra appelé « Sorting Yard » est utilisé. Un exemple d’implémentation peut être vu ci-dessus, ou dans le référentiel du projet de pile de machines nodejs ci-dessous.
Je continue à décrire l’algorithme d’animation squelettique tel qu’il est implémenté dans Flame Steel Engine.
Étant donné que l’algorithme est le plus complexe de tous ceux que j’ai implémentés, des erreurs peuvent apparaître dans les notes sur le processus de développement. Dans l’article précédent sur cet algorithme, j’ai commis une erreur : le réseau d’os est transféré au shader pour chaque maillage séparément, et non pour l’ensemble du modèle.
Hiérarchie des nœuds
Pour que l’algorithme fonctionne correctement, il est nécessaire que le modèle contienne une connexion entre les os entre eux (graphique). Imaginons une situation dans laquelle deux animations sont jouées simultanément – sautez et levez la main droite. L’animation de saut doit soulever le modèle le long de l’axe Y, tandis que l’animation de lever de bras doit en tenir compte et monter avec le modèle au fur et à mesure qu’il saute, sinon le bras restera en place tout seul.
Nous décrirons la connexion des nœuds pour ce cas – le corps contient la main. Lors de l’élaboration de l’algorithme, le graphique osseux sera lu, toutes les animations seront prises en compte avec les connexions correctes. Dans la mémoire du modèle, le graphique est stocké séparément de toutes les animations, uniquement pour refléter la connectivité des os du modèle.
Interpolation sur CPU
Dans le dernier article, j’ai décrit le principe du rendu de l’animation squelettique : “Les matrices de transformation sont transférées du CPU au shader à chaque image de rendu.”
Chaque image de rendu est traitée sur le processeur ; pour chaque os de maillage, le moteur reçoit la matrice de transformation finale en utilisant l’interpolation de position, la rotation et le zoom. Lors de l’interpolation de la matrice osseuse finale, un passage est effectué à travers l’arborescence des nœuds pour toutes les animations de nœuds actives, la matrice finale est multipliée par celles parent, puis envoyée pour rendu au vertex shader.
Les vecteurs sont utilisés pour l’interpolation de position et le grossissement ; les quaternions sont utilisés pour la rotation, car ils sont très faciles à interpoler (SLERP), contrairement aux angles d’Euler, et ils sont également très faciles à représenter sous forme de matrice de transformation.
Comment simplifier la mise en œuvre
Pour faciliter le débogage du vertex shader, j’ai ajouté une simulation du vertex shader sur le CPU à l’aide de la macro FSGLOGLNEWAGERENDERER_CPU_BASED_VERTEX_MODS_ENABLED. Le fabricant de la carte vidéo NVIDIA dispose d’un utilitaire de débogage du code de shader Nsight, peut-être qu’il peut aussi simplifier le développement d’algorithmes complexes de shader de sommets/pixels, mais je n’ai jamais pu tester sa fonctionnalité sur le CPU, c’était suffisant.
Dans le prochain article, je prévois de décrire le mélange de plusieurs animations et de combler les lacunes restantes.
Dans cet article, je décrirai une manière d’ajouter la prise en charge des scripts JavaScript à une application C++ à l’aide de la bibliothèque Tiny-JS.
Tiny-JS est une bibliothèque à intégrer en C++, permettant l’exécution de code JavaScript, avec prise en charge des liaisons (possibilité d’appeler du code C++ à partir de scripts)
Au début, je voulais utiliser les bibliothèques populaires ChaiScript, Duktape ou connect Lua, mais en raison des dépendances et des éventuelles difficultés de portabilité vers différentes plates-formes, il a été décidé de trouver une bibliothèque MIT JS simple, minimale mais puissante ; JS répond à ces critères. Le seul inconvénient de cette bibliothèque est le manque de support/développement par l’auteur, mais son code est assez simple, ce qui permet de prendre en charge le support si nécessaire.
Dans cet article, je décrirai la procédure pour créer une application C++ SDL pour iOS sous Linux, signer une archive ipa sans abonnement Apple Developer payant et l’installer sur un appareil propre (iPad) utilisant macOS sans Jailbreak.< /p>
Pour le moment, vous devez télécharger Xcode dmg et copier le SDK à partir de là pour créer le port cctools. Cette étape est plus facile à réaliser sur macOS ; copiez simplement les fichiers SDK nécessaires à partir du Xcode installé. Après un assemblage réussi, le terminal contiendra le chemin d’accès à la chaîne d’outils du compilateur croisé.
Vous pouvez ensuite commencer à créer l’application SDL pour iOS. Ouvrons cmake et ajoutons les modifications nécessaires pour construire le code C++ :
Dans mon cas, les bibliothèques SDL, SDL_Image et SDL_mixer sont compilées à l’avance dans Xcode sur macOS pour les liaisons statiques ; Frameworks copiés depuis Xcode. La bibliothèque libclang_rt.ios.a a également été ajoutée, qui inclut des appels d’exécution spécifiques à iOS, par exemple isOSVersionAtLeast. Une macro est incluse pour travailler avec OpenGL ES, désactivant les fonctions non prises en charge dans la version mobile, similaire à Android.
Après avoir résolu tous les problèmes de construction, vous devriez obtenir le binaire assemblé pour arm. Ensuite, envisageons d’exécuter le binaire assemblé sur un appareil sans Jailbreak.
Sur macOS, installez Xcode, inscrivez-vous sur le portail Apple, sans payer pour le programme développeur. Ajouter un compte dans Xcode -> Préférences -> Comptes, créez une application vierge et construisez sur un appareil réel. Lors de l’assemblage, l’appareil sera ajouté au compte développeur gratuit. Après l’assemblage et le lancement, vous devez créer l’archive ; pour ce faire, sélectionnez Appareil et produit iOS génériques -> Archive. Une fois l’archive créée, extrayez-en les fichiersembedded.mobileprovision et PkgInfo. Depuis le journal de build vers l’appareil, recherchez la ligne de codedesign avec la clé de signature correcte, le chemin d’accès au fichier de droits avec l’extension app.xcent, copiez-le.
Copiez le dossier .app de l’archive, remplacez le binaire de l’archive par un compilé par un compilateur croisé sous Linux (par exemple SpaceJaguar.app/SpaceJaguar), puis ajoutez les ressources nécessaires au .app, vérifiez le intégrité des fichiers PkgInfo et Embedded.mobileprovision dans le .app à partir de l’archive, copiez à nouveau si nécessaire. Nous re-signons le .app à l’aide de la commande codesign – le codedesign nécessite une clé d’entrée pour la signature, le chemin d’accès au fichier de droits (peut être renommé avec une extension .plist)
Après la re-signature, créez un dossier Payload, déplacez-y le dossier avec l’extension .app, créez une archive zip avec Payload à la racine, renommez l’archive avec l’extension .ipa. Après cela, dans Xcode, ouvrez la liste des appareils et faites glisser le nouvel ipa vers la liste des applications de l’appareil ; L’installation via Apple Configurator 2 ne fonctionne pas pour cette méthode. Si la re-signature est effectuée correctement, alors l’application avec le nouveau binaire sera installée sur un appareil iOS (par exemple iPad) avec un certificat de 7 jours, cela suffit pour la période de test.
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
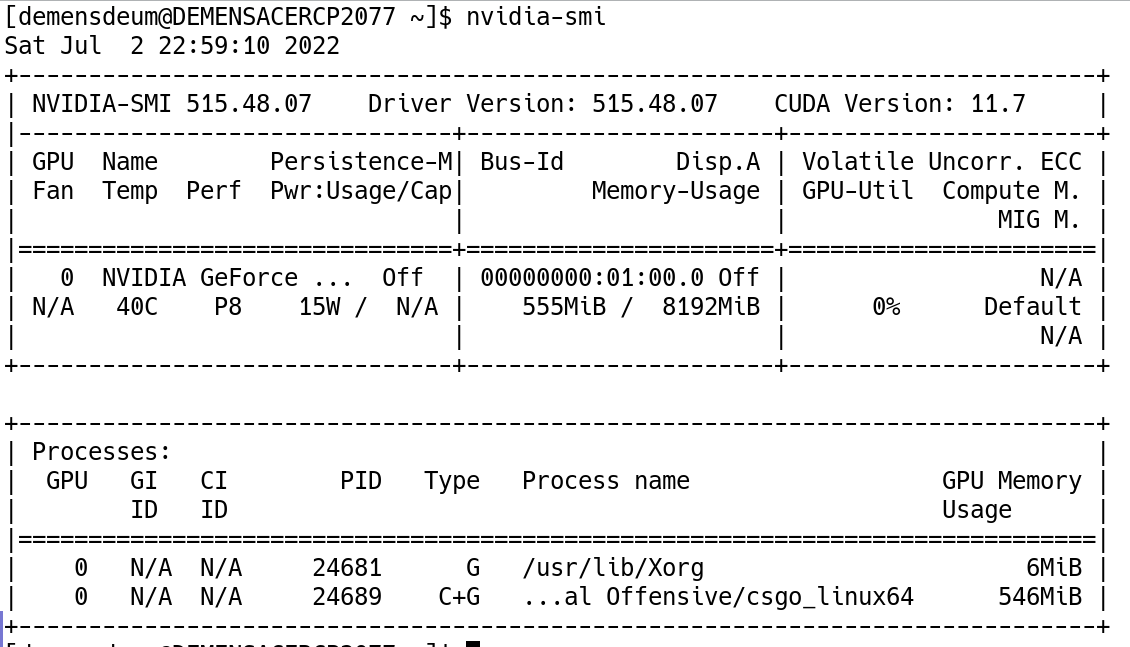
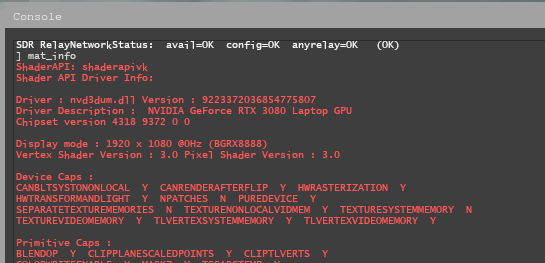






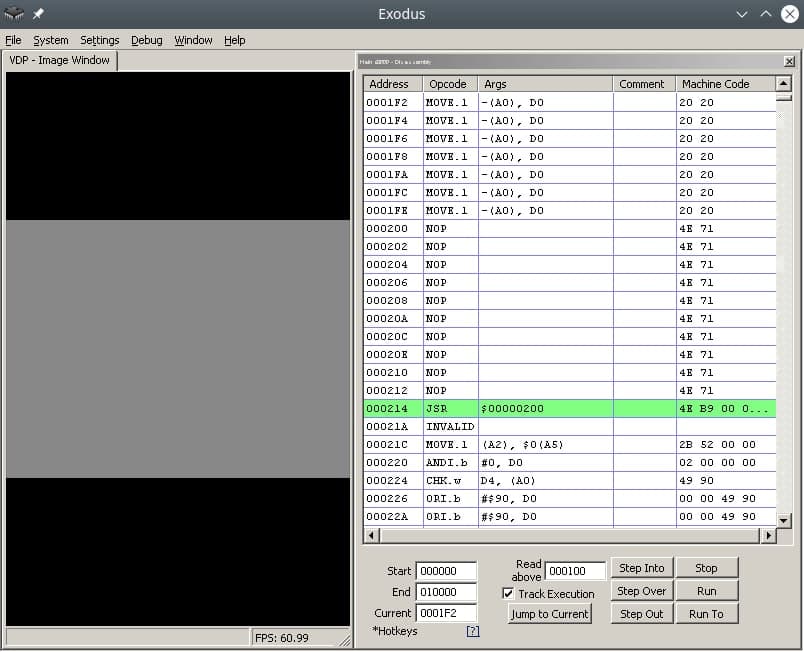
.gif)