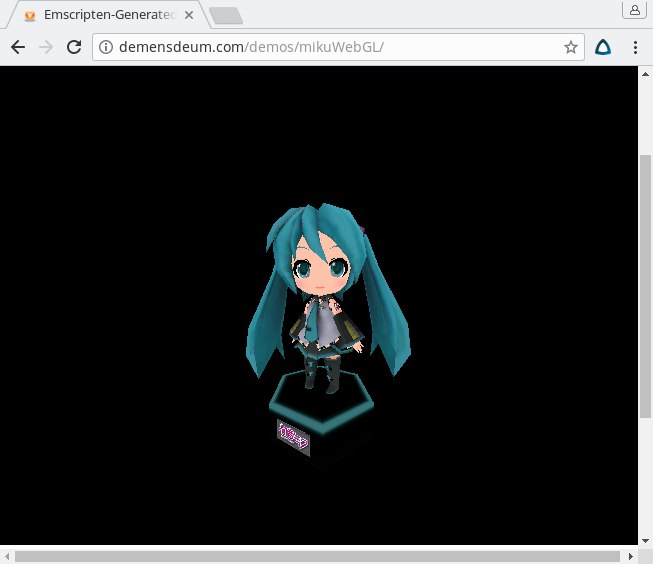
I ended up porting Mika to WebGL using SDL 1 and Emscripten.
Next I will describe what needed to be changed in the code so that the assembly in JavaScript would complete successfully.
Use SDL 1 instead of SDL 2. There is currently a port of SDL 2 for emscripten, but I found it more appropriate to use the built-in emscripten SDL 1. The context is initialized not in the window, but with SDL_SetVideoMode and the SDL_OPENGL flag. The buffer is drawn with the SDL_GL_SwapBuffers() command
Due to the peculiarities of execution of cycles in JavaScript – rendering is moved to a separate function and its periodic call is set using the function emscripten_set_main_loop
Also, the assembly must be carried out with the key “-s FULL_ES2=1“
I had to abandon the assimp library, loading the model from the file system, loading the texture from the disk. All the necessary buffers were loaded onto the desktop version, and passed to the c-header file for assembly using emscripten.
Result of work on FSGL library with OpenGL ES and code:
Next I will describe how all this was programmed, and how various interesting problems were solved.
First we initialize the OpenGL ES context, as I wrote in the previous note. Further we will consider only rendering, a brief description of the code.
The Matrix is watching you
This Miku figure in the video is made up of triangles. To draw a triangle in OpenGL, you need to specify three points with x, y, z coordinates in the 2D coordinates of the OpenGL context. Since we need to draw a figure containing 3D coordinates, we need to use the projection matrix. We also need to rotate, zoom, or do anything with the model – for this, the model matrix is used. There is no concept of a camera in OpenGL, in fact, objects rotate around a static camera. For this, the view matrix is used.
To simplify the implementation of OpenGL ES – it does not have matrix data. You can use libraries that add missing functionality, such as GLM.
Shaders
In order to allow the developer to draw whatever and however he wants, it is necessary to implement vertex and fragment shaders in OpenGL ES. A vertex shader must receive rendering coordinates as input, perform transformations using matrices, and pass the coordinates to gl_Position. A fragment or pixel shader – already draws the color/texture, applies overlay, etc.
I wrote the shaders in GLSL. In my current implementation, the shaders are embedded directly into the main application code as C strings.
Buffers
The vertex buffer contains the coordinates of the vertices (vertices), this buffer also receives coordinates for texturing and other data necessary for shaders. After generating the vertex buffer, you need to bind a pointer to the data for the vertex shader. This is done with the glVertexAttribPointer command, where you need to specify the number of elements, a pointer to the beginning of the data and the step size that will be used to walk through the buffer. In my implementation, the binding of vertex coordinates and texture coordinates for the pixel shader is done. However, it is worth mentioning that the transfer of data (texture coordinates) to the fragment shader is carried out through the vertex shader. For this, the coordinates are declared using varying.
In order for OpenGL to know in what order to draw the points for triangles – you need an index buffer (index). The index buffer contains the number of the vertex in the array, with three such indices you get a triangle.
Textures
First, you need to load/generate a texture for OpenGL. For this, I used SDL_LoadBMP, the texture is loaded from a bmp file. However, it is worth noting that only 24-bit BMPs are suitable, and the colors in them are not stored in the usual RGB order, but in BGR. That is, after loading, you need to replace the red channel with blue. Texture coordinates are specified in the UV format, i.e. it is necessary to transmit only two coordinates. The texture is output in the fragment shader. To do this, it is necessary to bind the texture to the fragment shader.
Nothing extra
Since, according to our instructions, OpenGL draws 3D via 2D – then to implement depth and sampling of invisible triangles – we need to use sampling (culling) and a depth buffer (Z-Buffer). In my implementation, I managed to avoid manual generation of the depth buffer using two commands glEnable(GL_DEPTH_TEST); and sampling glEnable(GL_CULL_FACE); Also, be sure to check that the near plane for the projection matrix is greater than zero, since depth checking with a zero near plane will not work.
Rendering
To fill the vertex buffer, index buffer with something conscious, for example the Miku model, you need to load this model. For this, I used the assimp library. Miku was placed in a Wavefront OBJ file, loaded using assimp, and data conversion from assimp to vertex, index buffers was implemented.
Rendering takes place in several stages:
Rotate Miku using the model matrix rotation
Clearing the screen and depth buffer
Drawing triangles using the glDrawElements command.
The next step is to implement WebGL rendering using Emscripten.
Having drawn a red teapot in 3D, I consider it my duty to briefly describe how it is done.
Modern OpenGL does not draw 3D, it only draws triangles, points, etc. in 2D screen coordinates. To output anything with OpenGL, you need to provide a vertex buffer, write a vertex shader, add all the necessary matrices (projection, model, view) to the vertex shader,link all the input data to the shader, call the rendering method in OpenGL. Seems simple?
Ok, what is a vertex buffer? A list of coordinates to draw (x, y, z) The vertex shader tells the GPU what coordinates to draw. A pixel shader tells what to draw (color, texture, blending, etc.) Matrices translate 3D coordinates into 2D coordinates OpenGL can render
In the following articles I will provide code examples and the result.
I love Panda3D game engine. But right now this engine is very hard to compile and debug on Microsoft Windows operation system. So as I said some time ago, I begin to develop my own graphics library. Right now it’s based on OpenGL ES and SDL2.
In this article I am going to tell how to initialize OpenGL ES context and how SDL2 helps in this task. We are going to show nothing.
King Nothing
First of all you need to install OpenGL ES3 – GLES 3 libraries. This operation is platform dependant, for Ubuntu Linux you can just type sudo apt-get install libgles2-mesa-dev. To work with OpenGL you need to initialize OpenGL context. There is many ways to do that, by using one of libraries – SDL2, GLFW, GLFM etc. Actually there is no one right way to initialize OpenGL context, but I chose SDL2 because it’s cross-platform solution, code will look same for Windows/*nix/HTML5/iOS/Android/etc.
To install sdl2 on Ubuntu use this command sudo apt-get install libsdl2-dev
So here is OpenGL context initialization code with SDL2:
Без лишних слов о крутости квантовых компьютеров и всего такого, сегодня я покажу как сделать генератор чисел на реальном квантовом процессоре IBM.
Для этого мы будем использовать всего один кубит, фреймворк для разработки квантового ПО для python – ProjectQ, и 16 кубитовый процессор от IBM, онлайн доступ к которому открыт любому желающему по программе IBM Quantum Experience.
Установка ProjectQ
Для начала у вас должен быть Linux, Python и pip. Какие либо инструкции по установке этих базовых вещей приводить бесполезно, т.к. в любом случае инструкции устареют через неделю, поэтому просто найдите гайд по установке на официальном сайте. Далее устанавливаем ProjectQ, гайд по установке приведен в документации. На данный момент все свелось к установке пакета ProjectQ через pip, одной командой: python -m pip install –user projectq
Ставим кубит в суперпозицию
Создаем файл quantumNumberGenerator.py и берем пример генератора бинарного числа из документации ProjectQ, просто добавляем в него цикл на 32 шага, собираем бинарную строку и переводим в 32-битное число:
importprojectq.setups.ibmfromprojectq.opsimport H, Measure
fromprojectqimport MainEngine
fromprojectq.backendsimport IBMBackend
binaryString =""
eng = MainEngine()
for i inrange(1, 33):
qubit = eng.allocate_qubit()
H | qubit
Measure | qubit
eng.flush()
binaryString = binaryString +str(int(qubit))
print("Step "+str(i))
number =int(binaryString, 2)
print("\n--- Quantum 32-Bit Number Generator by demensdeum@gmail.com (2017) ---\n")
print("Binary: "+ binaryString)
print("Number: "+str(number))
print("\n---")
Запускаем и получаем число из квантового симулятора с помощью команды python quantumNumberGenerator.py
Незнаю как вы, но я получил вывод и число 3974719468:
--- Quantum 32-Bit Number Generator by demensdeum@gmail.com (2017) ---
Binary: 11101100111010010110011111101100
Number: 3974719468
---
Хорошо, теперь мы запустим наш генератор на реальном квантовом процессоре IBM.
Хакаем IBM
Проходим регистрацию на сайте IBM Quantum Experience, подтверждаем email, в итоге должен остаться email и пароль для доступа.
Далее включаем айбиэмовский движок, меняем строку eng = MainEngine() -> eng = MainEngine(IBMBackend()) В теории после этого вы запускаете код снова и теперь он работает на реальном квантовом процессоре, используя один кубит. Однако после запуска вам придется 32 раза набрать свой email и пароль при каждой аллокации реального кубита. Обойти это можно прописав свой email и пароль прямо в библиотеки ProjectQ.
Заходим в папку где лежит фреймворк ProjectQ, ищем файл с помощью grep по строке IBM QE user (e-mail). В итоге я исправил строки в файле projectq/backends/_ibm/_ibm_http_client.py:
email= input_fun('IBM QE user (e-mail) > ') -> email="quantumPsycho@aport.ru"password= getpass.getpass(prompt='IBM QE password > ') -> password="ilovequbitsandicannotlie"
Напишите свой email и password со-но.
После этого IBM будет отправлять результаты работы с кубитом онлайн прямо в ваш скрипт, процесс генерации занимает около 20 секунд.
Возможно в дальнейшем я доберусь до работы квантового регистра, и возможно будет туториал, но это не обязательно.
Да прибудет с вами запутанность.
За последний год я написал простейший движок Flame Steel Engine и набор классов для игровой разработки Flame Steel Engine Game Toolkit. В данной статье я опишу как производил портирование движка и SDL игры Bad Robots на HTML 5, с использованием компилятора Emscripten.
Установка Hello World – Emscripten
Для начала нужно установить Emscripten. Простейшим вариантом оказалось использование скрипта emsdk для Linux. На официальном сайте данный тип установки называется как “Portable Emscripten SDK for Linux and OS X“. Внутри архива есть инструкция по установке с использованием скрипта. Я производил установку в директорию ~/emsdk/emsdk_portable.
После установки emscripten нужно проверить корректность работы компилятора, для этого создаем простейший hello_world.cpp и собираем его в hello_world.html с помощью команд:
После компиляции в папке появится hello_world.html и вспомогательные файлы, откройте его в лучшем браузере Firefox, проверьте что все работает корректно.
Портирование кода игры
В javascript нежелательно вызывать бесконечный цикл – это приводит к зависанию браузера. На данный момент корректная стратегия – запрашивать один шаг цикла у браузера с помощью вызова window.requestAnimationFrame(callback)
В Emscripten данное обстоятельство решено с помощью вызова:
emscripten_set_main_loop(em_callback_func func, int fps, int simulate_infinite_loop);
Таким образом, нужно изменить код игры для корректного вызова метода emscripten. Для этого я сделал глобальный метод GLOBAL_fsegt_emscripten_gameLoop, в котором вызываю шаг цикла игрового контроллера. Главный игровой контроллер также вынесен в глобальную видимость:
Также для обработки специфических для Emscripten моментов, нужно использовать макрос __EMSCRIPTEN__.
Ресурсы и оптимизация
Emscripten поддерживает ресурсы и сборку с оптимизацией.
Для добавления изображений, музыки и прочего, положите все файлы в одну папку, например data. Далее в скрипт сборки добавьте:
emcc <файлы для сборки> –use-preload-plugins –preload-file data
Флаг –use-preload-plugins включает красивый прелоадер в углу экрана, –preload-file добавляет указанный ресурс в файл <имя проекта>.data Код постоянно останавливался с ошибками доступа к ресурсам, пока я не включил оба этих флага. Также стоит заметить что для корректного доступа к ресурсам, желательно запускать игру на https (возможно и http) сервере, или отключить защиту локального доступа к файлам в вашем браузере.
Для включения оптимизации добавьте флаги:
-s TOTAL_MEMORY=67108864 -O3 -ffast-math
TOTAL_MEMORY – оперативная память в байтах(?) необходимая для корректной работы игры. Вы можете использовать флаг для динамического выделения памяти, но тогда часть оптимизаций работать не будет.
Производительность
Код javascript из C++ работает гораздо медленнее, даже со включенными оптимизациями. Поэтому если ваша цель это разработка для HTML5, то приготовьтесь к ручной оптимизации алгоритмов игры, паралелльному тестированию, также к написанию javascript кода вручную в особо узких местах. Для написания javascript кода используется макрос EM_ASM. Во время реализации рейкастера на emscripten, мне удалось добиться повышения fps с 2-4 до 30 с помощью прямого использования методов canvas.drawImage, в обход обертки SDL->Canvas, что почти приравнялось к написанию всего на javascript.
Поддержка SDL
На данный момент почти не работает SDL_TTF, поэтому отрисовка шрифта для Game Score в BadRobots очень проста. SDL_Image, SDL_Mixer работают корректно, в mixer я проверил только проигрывание музыки.
Исходный код Flame Steel Engine, Flame Steel Engine Game Toolkit, игры Bad Robots:
I have no time right now for record YouTube tutorial, so here is short text version.
Now you can just download Demon’s Cave code and compile on your machine.
We are going to show Demens Deum Logo on top of Rajawali engine (OpenGL-ES 2.0)
6. Add demensdeum_logo.png into res/drawable directory
7. Compile and run on your android device!
You will see Demens Deum company logo on your android device. If it’s flipped by horizontal, just flip it in Gimp first.
Or (for advanced users) try to use last Rajawali engine, this is known issue.
If you have questions, just ask me.
Keep learning!
2. Add Rajawali library to the project Filebuild.gradle (Project: Demon’s Cave) Add mavenCentral() < /span>to the buildscript/repositories sectionAdd maven{url< /span> “https://oss.sonatype.org/content/repositories/snapshots/”} to the allprojects/repositories section
File build.gradle (Module: app) Add compile‘org.rajawali3d:rajawali:1.0.306-SNAPSHOT@aar& #8217; to the dependencies section
Demon’s Cave is coming to Android soon. I started recording a course on porting a game to Android because there are a lot of people who are really interested in the development process. Please write to me if you have any questions or if you would like to add something to this course. You can also add subtitles for other languages: http://www.youtube.com/timedtext_video?ref=share&v=rx7NYkAJB2I
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.