In diesem Beitrag beschreibe ich, wie man Farben in Assemblersprache in die Shogi-Palette lädt.
Das Endergebnis im Exodus-Emulator sieht folgendermaßen aus:
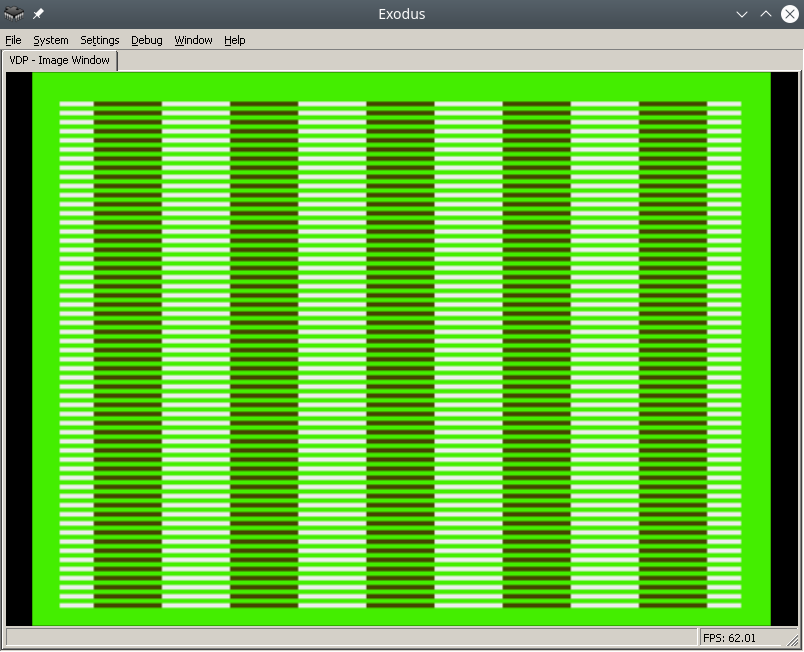
Um den Prozess zu vereinfachen, finden Sie im Internet ein PDF mit dem Titel Genesis Software Manual (1989). Es beschreibt den gesamten Prozess sehr detailliert. Tatsächlich handelt es sich bei dieser Notiz um einen Kommentar zum Originalhandbuch.< /p>
Um Farben auf den VDP-Chip des Sega-Emulators zu schreiben, müssen Sie die folgenden Dinge tun:
Für den Zusammenbau verwenden wir vasmm68k_mot und einen bevorzugten Texteditor, zum Beispiel Echo. Der Zusammenbau erfolgt mit dem Befehl:
Порты VDP
VDP чип общается с M68K через два порта в оперативной памяти – порт контроля и порт данных.
По сути:
- Через порт контроля можно выставлять значения регистрам VDP.
- Также порт контроля является указателем на ту часть VDP (VRAM, CRAM, VSRAM etc.) через которую передаются данные через порт данных
Интересная информация: Сега сохранила совместимость с играми Master System, на что указывает MODE 4 из мануала разработчика, в нем VDP переключается в режим Master System.
Объявим порты контроля и данных:
vdp_data_port = $C00000
Отключить систему защиты TMSS
Защита от нелицензионных игр TMSS имеет несколько вариантов разблокировки, например требуется чтобы до обращения к VDP в адресном регистре A1 лежала строка “SEGA”.
MOVE.B A1,D0; Получаем версию хардвары цифрой из A1 в регистр D0
ANDI.B 0x0F,D0; По маске берем последние биты, чтобы ничего не сломать
BEQ.B SkipTmss; Если версия равна 0, скорее всего это японка или эмулятор без включенного TMSS, тогда идем в сабрутину SkipTmss
MOVE.L "SEGA",A1; Или записываем строку SEGA в A1
Korrekte Parameter in VDP-Register schreiben
Warum überhaupt die richtigen Parameter in den VDP-Registern einstellen? Der Grundgedanke ist, dass VDP viel kann. Sie müssen es also vor dem Rendern mit den erforderlichen Funktionen initialisieren, sonst versteht es einfach nicht, was Sie von ihm erwarten.
Jedes Register ist für eine bestimmte Einstellung/Betriebsart verantwortlich. Das Segov-Handbuch gibt alle Bits/Flags für jedes der 24 Register an, eine Beschreibung der Register selbst.
Nehmen wir vorgefertigte Parameter mit Kommentaren aus dem Bigevilcorporation-Blog:
VDPReg0: dc.b $14 ; 0: H interrupt on, palettes on
VDPReg1: dc.b $74 ; 1: V interrupt on, display on, DMA on, Genesis mode on
VDPReg2: dc.b $30 ; 2: Pattern table for Scroll Plane A at VRAM $C000
; (bits 3-5 = bits 13-15)
VDPReg3: dc.b $00 ; 3: Pattern table for Window Plane at VRAM $0000
; (disabled) (bits 1-5 = bits 11-15)
VDPReg4: dc.b $07 ; 4: Pattern table for Scroll Plane B at VRAM $E000
; (bits 0-2 = bits 11-15)
VDPReg5: dc.b $78 ; 5: Sprite table at VRAM $F000 (bits 0-6 = bits 9-15)
VDPReg6: dc.b $00 ; 6: Unused
VDPReg7: dc.b $00 ; 7: Background colour - bits 0-3 = colour,
; bits 4-5 = palette
VDPReg8: dc.b $00 ; 8: Unused
VDPReg9: dc.b $00 ; 9: Unused
VDPRegA: dc.b $FF ; 10: Frequency of Horiz. interrupt in Rasters
; (number of lines travelled by the beam)
VDPRegB: dc.b $00 ; 11: External interrupts off, V scroll fullscreen,
; H scroll fullscreen
VDPRegC: dc.b $81 ; 12: Shadows and highlights off, interlace off,
; H40 mode (320 x 224 screen res)
VDPRegD: dc.b $3F ; 13: Horiz. scroll table at VRAM $FC00 (bits 0-5)
VDPRegE: dc.b $00 ; 14: Unused
VDPRegF: dc.b $02 ; 15: Autoincrement 2 bytes
VDPReg10: dc.b $01 ; 16: Vert. scroll 32, Horiz. scroll 64
VDPReg11: dc.b $00 ; 17: Window Plane X pos 0 left
; (pos in bits 0-4, left/right in bit 7)
VDPReg12: dc.b $00 ; 18: Window Plane Y pos 0 up
; (pos in bits 0-4, up/down in bit 7)
VDPReg13: dc.b $FF ; 19: DMA length lo byte
VDPReg14: dc.b $FF ; 20: DMA length hi byte
VDPReg15: dc.b $00 ; 21: DMA source address lo byte
VDPReg16: dc.b $00 ; 22: DMA source address mid byte
VDPReg17: dc.b $80 ; 23: DMA source address hi byte,
; memory-to-VRAM mode (bits 6-7)
Ok, jetzt gehen wir zum Steuerport und schreiben alle Flags in die VDP-Register:
move.l #VDPRegisters,a0 ; Пишем адрес таблицы параметров в A1
move.l #$18,d0 ; Счетчик цикла - 24 = 18 (HEX) в D0
move.l #$00008000,d1 ; Готовим команду на запись в регистр VDP по индексу 0, по мануалу - 1000 0000 0000 0000 (BIN) = 8000 (HEX)
FillInitialStateForVDPRegistersLoop:
move.b (a0)+,d1 ; Записываем в D1 итоговое значение регистра VDP из таблицы параметров, на отправку в порт контроля VDP
move.w d1,vdp_control_port ; Отправляем итоговую команду + значение из D1 в порт контроля VDP
add.w #$0100,d1 ; Поднимаем индекс регистра VDP на 1 (бинарное сложение +1 к индексу по мануалу Сеги)
dbra d0,FillInitialStateForVDPRegistersLoop ; Уменьшаем счетчик регистров, продолжаем цикл если необходимо
Самое сложное это прочитать мануал и понять в каком формате подаются данные на порт контроля, опытные разработчики разберутся сразу, а вот неопытные… Немного подумают и поймут, что синтаксис для записи регистров такой:
0B100(5 бит – индекс регистра)(8 бит/байт – значение)
0B1000001001000101 – записать в регистр VDP 2 (00010), значение флажков 01000101.
Записать нужные цвета в CRAM
Далее идем писать два цвета в память цветов CRAM (Color RAM). Для этого пишем в порт контроля команду на доступ к цвету по индексу 0 в CRAM и отправляем по дата порту цвет. Все!
Пример:
move.l #$C0000000,vdp_control_port ; Доступ к цвету по индексу 0 в CRAM через порт контроля
move.w #228,d0; Цвет в D0
move.w d0,vdp_data_port; Отправляем цвет в порт данных
Nachdem Sie den Emulator in Exodus erstellt und ausgeführt haben, sollte Ihr Bildschirm mit der Farbe 228 gefüllt sein.
Füllen wir es mit einer zweiten Farbe, basierend auf dem letzten Byte 127.
move.l #$C07f0000,vdp_control_port ; Доступ к цвету по байту 127 в CRAM через порт контроля
move.w #69,d0; Цвет в D0
move.w d0,vdp_data_port; Отправляем цвет в порт данных
Links
https://gitlab.com/demensdeum/segagenesissamples
https://www.exodusemulator.com/
http://sun.hasenbraten.de/vasm/
https://tomeko.net/online_tools/bin_to_32bit_hex.php?lang=en
Quellen
https://namelessalgorithm.com/genesis/blog/genesis/
https://plutiedev.com/vdp-commands
https://huguesjohnson.com/programming/genesis/palettes/
https://www.chibiakumas.com/68000/helloworld.php#LessonH5
https://blog.bigevilcorporation.co.uk/2012/03/09/sega-megadrive-3-awaking-the-beast/
Der erste Artikel über das Schreiben von Spielen für die klassische Sega Genesis-Konsole in Motorola 68000 Assembly.
Lassen Sie uns die einfachste Endlosschleife für Sega schreiben. Dafür benötigen wir: einen Assembler, einen Emulator mit Disassembler, einen bevorzugten Texteditor, ein grundlegendes Verständnis der Struktur von Sega Rum.
Für die Entwicklung verwende ich meinen eigenen Assembler/Disassembler Gen68KryBaby:
https://gitlab.com/demensdeum/gen68krybaby/
Das Tool ist in Python 3 entwickelt, zum Zusammenstellen wird eine Datei mit der Erweiterung .asm oder .gen68KryBabyDisasm als Eingabe bereitgestellt, die Ausgabe ist eine Datei mit der Erweiterung .gen68KryBabyAsm.bin, die im Emulator oder auf ausgeführt werden kann eine echte Konsole (Vorsicht, weggehen, die Konsole könnte explodieren!)
Das Zerlegen von ROMs wird ebenfalls unterstützt. Dazu müssen Sie eine ROM-Datei als Eingabe übermitteln, ohne die Erweiterungen .asm oder .gen68KryBabyDisasm. Die Opcode-Unterstützung wird abhängig von meinem Interesse am Thema und der Beteiligung von Mitwirkenden steigen oder sinken.
Struktur
Der Sega-ROM-Header belegt die ersten 512 Bytes. Es enthält Informationen über das Spiel, den Namen, unterstützte Peripheriegeräte, Prüfsumme und andere Systemflags. Ich gehe davon aus, dass die Konsole ohne Titel nicht einmal auf den Rum schaut und denkt, dass er falsch ist, und sagt: „Was gibst du mir hier?“
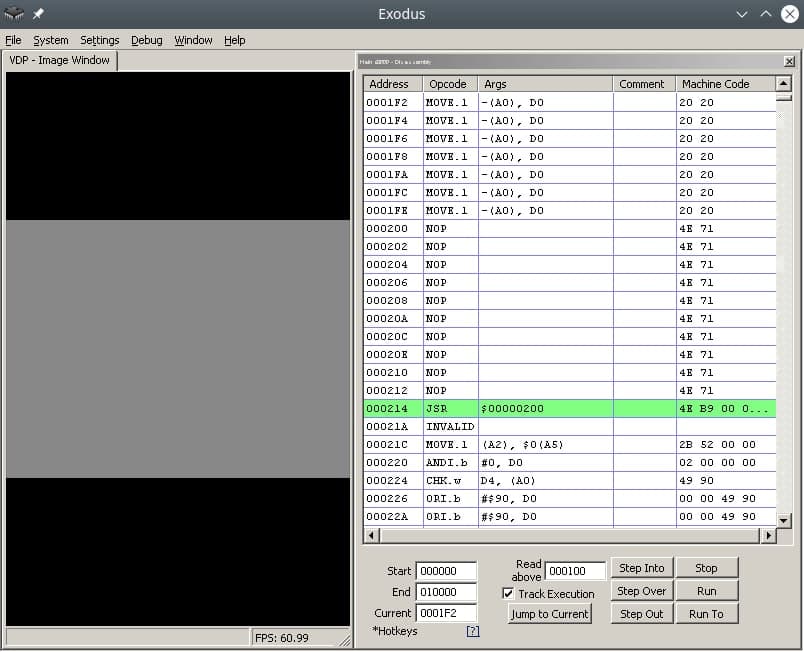
Nach dem Header kommt das Unterprogramm/Reset-Unterprogramm, in dem der m68K-Prozessor seine Arbeit beginnt. Okay, es ist eine Kleinigkeit – Opcodes (Operationscodes) finden, nämlich nichts tun (!) und zur Unterroutine an der Adresse im Speicher wechseln. Wenn Sie googeln, können Sie den NOP-Opcode finden, der nichts tut, und den JSR-Opcode, der einen bedingungslosen Sprung zur Argumentadresse ausführt, das heißt, er bewegt den Schlitten einfach ohne irgendwelche Launen dorthin, wo wir ihn fragen.
Alles zusammenfügen
Der Header-Donor für die ROM war eines der Spiele in der Beta-Version, derzeit als Hex-Daten aufgezeichnet.
00 ff 2b 52 00 00 02 00 00 00 49 90 00 00 49 90 00 00 49 90 00...и т.д.
Код программы со-но представляет из себя объявление сабрутины Reset/EntryPoint в 512 (0x200) байте, NOP, возврат каретки к 0x00000200, таким образом мы получим бесконечный цикл.
Ассемблерный код сабрутины Reset/EntryPoint:
NOP
NOP
NOP
NOP
NOP
JSR 0x00000200
Vollständiges Beispiel zusammen mit ROM-Header:
https://gitlab.com /demensdeum/segagenesisamples/-/blob/main/1InfiniteLoop/1infiniteloop.asm
Wir sammeln als nächstes:
In dieser Notiz werde ich über die Bedeutung von Architekturentscheidungen bei der Entwicklung, der Unterstützung einer Anwendung und in einer Teamentwicklungsumgebung schreiben.

Selbst- Betriebsserviette Professor Lucifer Gorgonzola. Rube Goldberg
In meiner Jugend habe ich an einer Taxi-Bestellanwendung gearbeitet. Im Programm können Sie einen Abholpunkt und einen Abgabepunkt auswählen, die Fahrtkosten und die Tarifart berechnen und tatsächlich ein Taxi bestellen. Ich habe die Anwendung in der letzten Phase des Vorabstarts erhalten; nach dem Hinzufügen mehrerer Korrekturen wurde die Anwendung im AppStore veröffentlicht. Bereits zu diesem Zeitpunkt war dem gesamten Team klar, dass die Implementierung sehr schlecht war, keine Entwurfsmuster verwendet wurden, alle Komponenten des Systems eng miteinander verbunden waren und es im Allgemeinen möglich war, es in eine große kontinuierliche Klasse (Gottobjekt) zu schreiben. Es hätte sich nichts geändert, so wie die Klassen ihre Verantwortungsgrenzen durcheinander brachten und sich in ihrer Gesamtmasse in einer toten Kopplung überlappten. Später beschloss das Management, die Anwendung unter Verwendung der richtigen Architektur von Grund auf neu zu schreiben, was auch geschah und das Endprodukt für mehrere Dutzend B2B-Kunden implementiert wurde.
Ich werde jedoch einen merkwürdigen Vorfall aus der Architektur der Vergangenheit beschreiben, von dem ich manchmal mitten in der Nacht schweißgebadet aufwache oder mich mitten am Tag plötzlich daran erinnere und hysterisch zu lachen beginne. Die Sache ist die, dass ich den Kerl an der Stange beim ersten Mal nicht treffen konnte, was den Großteil der Bewerbung zum Scheitern brachte, aber das Wichtigste zuerst.
Es war ein gewöhnlicher Arbeitstag, einer der Kunden erhielt die Aufgabe, das Anwendungsdesign leicht zu verfeinern – Es ist einfach, das Symbol in der Mitte des Auswahlbildschirms für die Abholadresse um ein paar Pixel nach oben zu verschieben. Nun, nachdem ich die Aufgabe professionell auf 10 Minuten geschätzt hatte, hob ich das Symbol um 20 Pixel an, völlig ahnungslos, und beschloss, den Taxiauftrag zu überprüfen.
Was? Die App zeigt den Bestellbutton nicht mehr an? Wie ist das passiert?
Ich traute meinen Augen nicht; nachdem ich das Symbol um 20 Pixel erhöht hatte, zeigte die Anwendung die Schaltfläche „Bestellung fortsetzen“ nicht mehr an. Nachdem ich die Änderung rückgängig gemacht hatte, sah ich die Schaltfläche wieder. Hier stimmte etwas nicht. Nachdem ich 20 Minuten im Debugger verbracht hatte, hatte ich es ein wenig satt, die vielen Aufrufe überlappender Klassen abzuwickeln, aber ich entdeckte, dass *das Verschieben des Bildes die Logik der Anwendung wirklich verändert*
Es drehte sich alles um das Symbol in der Mitte – Ein Mann auf einer Stange, der beim Bewegen der Karte nach oben sprang, um die Bewegung der Kamera zu animieren. Auf diese Animation folgte das Verschwinden des Knopfes unten. Anscheinend ging das Programm davon aus, dass der um 20 Pixel verschobene Mann einen Sprung machte, und versteckte daher gemäß seiner internen Logik die Bestätigungsschaltfläche.
Wie kann das passieren? Hängt der *Zustand* des Bildschirms wirklich nicht vom Muster der Zustandsmaschine ab, sondern von der *Darstellung* der Position des Mannes auf der Stange?
Es stellte sich heraus, dass jedes Mal, wenn die Karte gezeichnet wurde, die Anwendung *visuell* in die Mitte des Bildschirms gestochen und überprüft, was dort war. Wenn sich ein Mann auf einer Stange befindet, bedeutet dies, dass die Kartenverschiebungsanimation beendet ist und angezeigt werden muss Taste. Wenn der Mann nicht da ist, wird die Karte verschoben und die Schaltfläche muss ausgeblendet werden.
Im obigen Beispiel ist alles in Ordnung, erstens ist es ein Beispiel für Goldberg-Maschinen (abstruse Maschinen), zweitens ein Beispiel für die Zurückhaltung des Entwicklers, irgendwie mit anderen Entwicklern im Team zu interagieren (versuchen Sie, es ohne herauszufinden). Drittens können Sie alle Probleme nach SOLID, Mustern (Code-Smells), MVC-Verletzungen und vielem mehr auflisten.
Versuchen Sie, dies nicht zu tun, entwickeln Sie sich in alle möglichen Richtungen und helfen Sie Ihren Kollegen bei ihrer Arbeit. Frohes neues Jahr euch allen.
Links
https://ru.wikipedia.org/wiki/Goldberg_Machine
https://ru.wikipedia.org/wiki/SOLID
https://refactoring.guru/ru/refactoring/smells
https://ru.wikipedia.org/wiki/Model -View-Controller
https://refactoring.guru/ru/design-patterns/state
In diesem Beitrag beschreibe ich die Arbeit mit dem Fasttext-Textklassifikator.
Fasttext – Bibliothek für maschinelles Lernen zur Textklassifizierung. Versuchen wir ihr beizubringen, eine Metal-Band anhand des Songtitels zu identifizieren. Dazu nutzen wir überwachtes Lernen anhand eines Datensatzes.
Lassen Sie uns einen Datensatz von Liedern mit Gruppennamen erstellen:
__label__metallica fuel
__label__metallica escape
__label__black_sabbath gypsy
__label__black_sabbath snowblind
__label__black_sabbath am i going insane
__label__anthrax anthrax
__label__anthrax i'm alive
__label__anthrax antisocial
[и т.д.]
Формат обучающей выборки:
Обучим fasttext и сохраним модель:
model.save_model("model.bin")
Laden Sie das trainierte Modell und bitten Sie darum, die Gruppe anhand des Namens des Songs zu identifizieren:
predictResult = model.predict("Bleed")
print(predictResult)
В результате мы получим список классов на которые похож данный пример, с указанием уровня похожести цифрой, в нашем случае похожесть названия песни Bleed на одну из групп датасета.
Для того чтобы модель fasttext умела работать с датасетом выходящим за границы обучающей выборки, используют режим autotune с использованием файла валидации (файл тест). Во время автотюна fasttext подбирает оптимальные гиперпараметры модели, проводя валидацию результата на выборке из тест файла. Время автотюна ограничивается пользователем в самостоятельно, с помощью передачи аргумента autotuneDuration.
Пример создания модели с использованием файла тест:
In dieser Notiz beschreibe ich den Prozess des Aufrufs von C-Funktionen aus dem Assembler.
Versuchen wir, printf(“Hello World!\n”); aufzurufen. und Exit(0);
message: db "Hello, world!", 10, 0
section .text
extern printf
extern exit
global main
main:
xor rax, rax
mov rdi, message
call printf
xor rdi, rdi
call exit
Alles ist viel einfacher als es scheint. Im Abschnitt .rodata beschreiben wir statische Daten, in diesem Fall die Zeile „Hallo Welt!“, 10 ist ein Zeilenumbruchzeichen und wir vergessen auch nicht, es auf Null zu setzen.
Im Codeabschnitt deklarieren wir die externen Funktionen printf, Exit der stdio- und stdlib-Bibliotheken und deklarieren auch die Eingabefunktion main:
extern printf
extern exit
global main
Wir übergeben 0 von der Rax-Funktion an das Rückgaberegister. Sie können mov rax, 0; aber um es zu beschleunigen, benutzen sie xor rax, rax; Als nächstes übergeben wir einen Zeiger auf die Zeichenfolge an das erste Argument:
In diesem Beitrag beschreibe ich den Prozess der Einrichtung der IDE und schreibe den ersten Hello World in x86_64-Assembler für das Ubuntu-Linux-Betriebssystem.
Beginnen wir mit der Installation der SASM-IDE, Nasm-Assembler:
Далее запустим SASM и напишем Hello World:
section .text
main:
mov rbp, rsp ; for correct debugging
mov rax, 1 ; write(
mov rdi, 1 ; STDOUT_FILENO,
mov rsi, msg ; "Hello, world!\n",
mov rdx, msglen ; sizeof("Hello, world!\n")
syscall ; );
mov rax, 60 ; exit(
mov rdi, 0 ; EXIT_SUCCESS
syscall ; );
section .rodata
msg: db "Hello, world!"
msglen: equ $-msg
Hello World-Code aus dem Blog James Fisher, angepasst für Assemblierung und Debugging in SASM. In der SASM-Dokumentation heißt es, dass der Einstiegspunkt eine Funktion namens „main“ sein muss, da sonst das Debuggen und Kompilieren des Codes fehlerhaft ist.
Was haben wir in diesem Code gemacht? Habe einen Systemaufruf getätigt – Zugriff auf den Kernel des Linux-Betriebssystems mit korrekten Argumenten in Registern, einem Zeiger auf eine Zeichenfolge im Datenabschnitt.
Unter der Lupe
Sehen wir uns den Code genauer an:
global – директива ассемблера позволяющая задавать глобальные символы со строковыми именами. Хорошая аналогия – интерфейсы заголовочных файлов языков C/C++. В данном случае мы задаем символ main для функции входа.
section – директива ассемблера позволяющая задавать секции (сегменты) кода. Директивы section или segment равнозначны. В секции .text помещается код программы.
Обьявляем начало функции main. В ассемблере функции называются подпрограммами (subroutine)
Первая машинная команда mov – помещает значение из аргумента 1 в аргумент 2. В данном случае мы переносим значение регистра rbp в rsp. Из комментария можно понять что эту строку добавил SASM для упрощения отладки. Видимо это личные дела между SASM и дебаггером gdb.
Далее посмотрим на код до сегмента данных .rodata, два вызова syscall, первый выводит строку Hello World, второй обеспечивает выход из приложения с корректным кодом 0.
Представим себе что регистры это переменные с именами rax, rdi, rsi, rdx, r10, r8, r9. По аналогии с высокоуровневыми языками, перевернем вертикальное представление ассемблера в горизонтальное, тогда вызов syscall будет выглядеть так:
Тогда вызов печати текста:
Вызов exit с корректным кодом 0:
Рассмотрим аргументы подробнее, в заголовочном файле asm/unistd_64.h находим номер функции __NR_write – 1, далее в документации смотрим аргументы для write:
ssize_t write(int fd, const void *buf, size_t count);
Первый аргумент – файловый дескриптор, второй – буфер с данными, третий – счетчик байт для записи в дескриптор. Ищем номер файлового дескриптора для стандартного вывода, в мануале по stdout находим код 1. Далее дело за малым, передать указатель на буфер строки Hello World из секции данных .rodata – msg, счетчик байт – msglen, передать в регистры rax, rdi, rsi, rdx корректные аргументы и вызвать syscall.
Обозначение константных строк и длины описывается в мануале nasm:
Mit der Hash-Tabelle können Sie eine assoziative Array-Datenstruktur (Wörterbuch) mit einer durchschnittlichen Leistung von O(1) für Einfüge-, Lösch- und Suchvorgänge implementieren.
Unten finden Sie ein Beispiel für die einfachste Implementierung einer Hash-Map in nodeJS:
Wie funktioniert es? Passen Sie auf Ihre Hände auf:
- Innerhalb der Hash-Map befindet sich ein Array
- Im Array-Element befindet sich ein Zeiger auf den ersten Knoten der verknüpften Liste
- Speicher wird für ein Array von Zeigern zugewiesen (z. B. 65535 Elemente)
- Sie implementieren eine Hash-Funktion, der Wörterbuchschlüssel ist die Eingabe, und am Ausgang kann sie alles tun, aber am Ende gibt sie den Index des Array-Elements zurück
So funktioniert die Aufnahme:
- Am Eingang liegt ein Schlüsselpaar – Wert
- Hash-Funktion gibt Index nach Schlüssel zurück
- Einen verknüpften Listenknoten aus einem Array nach Index abrufen
- Überprüfen Sie, ob es mit dem Schlüssel übereinstimmt
- Wenn es übereinstimmt, ersetzen Sie den Wert
- Wenn es nicht übereinstimmt, fahren Sie mit dem nächsten Knoten fort, bis wir einen Knoten mit dem erforderlichen Schlüssel finden oder finden.
- Wenn der Knoten immer noch nicht gefunden wird, erstellen Sie ihn am Ende der verknüpften Liste
So funktioniert die Suche nach Schlüssel:
- Am Eingang liegt ein Schlüsselpaar – Wert
- Hash-Funktion gibt Index nach Schlüssel zurück
- Einen verknüpften Listenknoten aus einem Array nach Index abrufen
- Überprüfen Sie, ob es mit dem Schlüssel übereinstimmt
- Wenn es übereinstimmt, wird der Wert zurückgegeben
- Wenn es nicht übereinstimmt, fahren Sie mit dem nächsten Knoten fort, bis wir einen Knoten mit dem erforderlichen Schlüssel finden oder finden.
Warum brauchen wir eine verknüpfte Liste innerhalb eines Arrays? Aufgrund möglicher Kollisionen bei der Berechnung der Hash-Funktion. In diesem Fall befinden sich mehrere verschiedene Schlüssel-Wert-Paare am selben Index im Array. In diesem Fall wird die verknüpfte Liste durchlaufen, um den erforderlichen Schlüssel zu finden.
Quellen
https://ru.wikipedia.org/wiki/Hash-Tabelle
https://www.youtube.com/watch?v=wg8hZxMRwcw
Quellcode
https://gitlab.com/demensdeum/datastructures
Um mit Ressourcen in Android über ndk zu arbeiten – C++ gibt es mehrere Möglichkeiten:
- Verwenden Sie den Zugriff auf Ressourcen aus einer APK-Datei mit AssetManager
- Laden Sie Ressourcen aus dem Internet herunter, entpacken Sie sie in das Anwendungsverzeichnis und verwenden Sie sie mit Standard-C++-Methoden
- Kombinierte Methode – Greifen Sie über AssetManager auf das Archiv mit Ressourcen in der APK zu, entpacken Sie sie in das Anwendungsverzeichnis und verwenden Sie sie dann mit Standard-C++-Methoden
Als nächstes werde ich die kombinierte Zugriffsmethode beschreiben, die in der Flame Steel Engine-Spiel-Engine verwendet wird.
Wenn Sie SDL verwenden, können Sie den Zugriff auf Ressourcen von einer APK aus vereinfachen. Die Bibliothek umschließt Aufrufe an AssetManager und bietet Schnittstellen ähnlich wie stdio (fopen, fread, fclose usw.).
SDL_RWops *io = SDL_RWFromFile("files.fschest", "r");
Nachdem Sie das Archiv von der APK in den Puffer heruntergeladen haben, müssen Sie das aktuelle Arbeitsverzeichnis in das Anwendungsverzeichnis ändern. Es steht der Anwendung zur Verfügung, ohne dass zusätzliche Berechtigungen eingeholt werden müssen. Dazu verwenden wir einen SDL-Wrapper:
chdir(SDL_AndroidGetInternalStoragePath());
Als nächstes schreiben Sie das Archiv mit fopen, fwrite, fclose aus dem Puffer in das aktuelle Arbeitsverzeichnis. Sobald sich das Archiv in einem für C++ zugänglichen Verzeichnis befindet, entpacken Sie es. Zip-Archive können mit einer Kombination aus zwei Bibliotheken entpackt werden – minizip und zlib, das erste kann mit der Struktur von Archiven arbeiten, während das zweite Daten entpackt.
Um mehr Kontrolle zu erlangen und die Portierung zu vereinfachen, habe ich mein eigenes Archivformat ohne Komprimierung namens FSCest (Flame Steel Chest) implementiert. Dieses Format unterstützt das Archivieren eines Verzeichnisses mit Dateien und das Entpacken; Es gibt keine Unterstützung für die Ordnerhierarchie; Sie können nur mit Dateien arbeiten.
Wir verbinden den Header der FSCest-Bibliothek, entpacken das Archiv:
#include "fschest.h"
FSCHEST_extractChestToDirectory(archivePath, SDL_AndroidGetInternalStoragePath());
Nach dem Entpacken haben die C/C++-Schnittstellen Zugriff auf die Dateien aus dem Archiv. Daher musste ich nicht die gesamte Arbeit mit Dateien in der Engine neu schreiben, sondern fügte nur das Entpacken von Dateien in der Startphase hinzu.
Quellen
https://developer.android.com/ndk/ Referenz/Gruppe/Asset
Quellcode
https://gitlab.com/demensdeum/space- Jaguar-Action-RPG
https://gitlab.com/demensdeum/fschest
Angenommen, wir müssen einen einfachen Bytecode-Interpreter implementieren. Welchen Ansatz zur Implementierung dieser Aufgabe sollten wir wählen?
Datenstruktur Der Stack bietet die Möglichkeit, eine einfache Bytecode-Maschine zu implementieren. Funktionen und Implementierungen von Stack-Maschinen werden in vielen Artikeln im westlichen und inländischen Internet beschrieben; ich möchte nur erwähnen, dass die Java Virtual Machine ein Beispiel für eine Stack-Maschine ist.
Das Funktionsprinzip der Maschine ist einfach: Ein Programm mit Daten und Operationscodes (Opcodes) wird dem Eingang zugeführt und die erforderlichen Operationen werden durch Manipulationen am Stapel implementiert. Schauen wir uns ein Beispiel-Bytecode-Programm von meiner Stack-Maschine an:
Am Ausgang erhalten wir die Zeichenfolge „Hello StackVM“. Die Stapelmaschine liest das Programm von links nach rechts und lädt Daten Zeichen für Zeichen auf den Stapel, wenn ein Opcode im Symbol – implementiert den Befehl mithilfe des Stapels.
Beispiel für die Implementierung einer Stack-Maschine in nodejs:
Umgekehrte polnische Notation (RPN)
Stack -Maschinen sind auch einfach zum Implementieren von Taschenrechnern zu verwenden. Dafür verwenden sie umgekehrte polnische Notation (Postfix -Notation).
Beispiel einer regulären Infix-Notation:
2*2+3*4
Konvertiert in RPN:
22*34*+
Um den Postfix-Datensatz zu zählen, verwenden wir eine Stapelmaschine:
2– an die Spitze des Stapels (Stapel: 2)
2– an die Spitze des Stapels (Stapel: 2,2)
*– Holen Sie sich zweimal die Oberseite des Stapels, multiplizieren Sie das Ergebnis und senden Sie es an die Oberseite des Stapels (Stapel: 4)
3– an die Spitze des Stapels (Stapel: 4, 3)
4– an die Spitze des Stapels (Stapel: 4, 3, 4)
*– Holen Sie sich zweimal die Oberseite des Stapels, multiplizieren Sie das Ergebnis und senden Sie es an die Oberseite des Stapels (Stapel: 4, 12)
+– Holen Sie sich zweimal die Spitze des Stapels, addieren Sie das Ergebnis und senden Sie es an die Spitze des Stapels (Stapel: 16)
Wie Sie sehen können – Das Ergebnis der Operationen 16 verbleibt auf dem Stapel. Es kann durch Implementierung von Stapeldruck-Opcodes gedruckt werden, zum Beispiel:
p22*34*+P
P – Stapeldruck-Start-Opcode, p – Opcode zum Fertigstellen des Stapeldrucks und zum Senden der letzten Zeile zum Rendern.
Um arithmetische Operationen von Infix in Postfix umzuwandeln, wird der Algorithmus „Sorting Yard“ von Edsger Dijkstra verwendet. Ein Beispiel für die Implementierung finden Sie oben oder im Repository des NodeJS-Maschinenstack-Projekts unten.
Quellen
https:/ /tech.badoo.com/ru/article/579/interpretatory-bajt-kodov-svoimi-rukami/
https://ru.wikipedia.org/wiki/Обратная_польская_запись
Quellcode
https://gitlab.com/demensdeum/stackvm/< /p>
Ich beschreibe weiterhin den Skelettanimationsalgorithmus, wie er in der Flame Steel Engine implementiert ist.
Da der Algorithmus der komplexeste von allen ist, die ich implementiert habe, können in den Notizen zum Entwicklungsprozess Fehler auftreten. Im vorherigen Artikel über diesen Algorithmus habe ich einen Fehler gemacht; das Array von Knochen wird für jedes Netz separat und nicht für das gesamte Modell an den Shader übertragen.
Knotenhierarchie
Damit der Algorithmus korrekt funktioniert, ist es notwendig, dass das Modell eine Verbindung zwischen den Knochen untereinander enthält (Grafik). Stellen wir uns eine Situation vor, in der zwei Animationen gleichzeitig abgespielt werden – Springe und hebe deine rechte Hand. Die Sprunganimation muss das Modell entlang der Y-Achse anheben, während die Animation zum Anheben des Arms dies berücksichtigen und beim Springen mit dem Modell ansteigen muss, sonst bleibt der Arm von selbst an Ort und Stelle.
Wir werden die Verbindung von Knoten für diesen Fall beschreiben – Der Körper enthält die Hand. Bei der Ausarbeitung des Algorithmus wird der Knochengraph ausgelesen, alle Animationen werden mit den richtigen Verbindungen berücksichtigt. Im Speicher des Modells wird das Diagramm getrennt von allen Animationen gespeichert, nur um die Konnektivität der Knochen des Modells widerzuspiegeln.
Interpolation auf der CPU
Im letzten Artikel habe ich das Prinzip des Renderns von Skelettanimationen beschrieben – „Transformationsmatrizen werden bei jedem Rendering-Frame von der CPU an den Shader übertragen.“
Jeder Rendering-Frame wird auf der CPU verarbeitet; für jeden Mesh-Bone erhält die Engine die endgültige Transformationsmatrix mithilfe von Positionsinterpolation, Drehung und Zoom. Während der Interpolation der endgültigen Knochenmatrix wird für alle aktiven Knotenanimationen ein Durchlauf durch den Knotenbaum durchgeführt, die endgültige Matrix wird mit den übergeordneten Matrix multipliziert und dann zum Rendern an den Vertex-Shader gesendet.
Vektoren werden zur Positionsinterpolation und Vergrößerung verwendet; Quaternionen werden zur Rotation verwendet, weil Sie sind im Gegensatz zu Euler-Winkeln sehr einfach zu interpolieren (SLERP) und auch sehr einfach als Transformationsmatrix darzustellen.
So vereinfachen Sie die Implementierung
Um das Debuggen des Vertex-Shaders zu vereinfachen, habe ich mithilfe des Makros FSGLOGLNEWAGERENDERER_CPU_BASED_VERTEX_MODS_ENABLED eine Simulation des Vertex-Shaders auf der CPU hinzugefügt. Der Grafikkartenhersteller NVIDIA verfügt über ein Dienstprogramm zum Debuggen von Shader-Code, Nsight. Vielleicht kann es auch die Entwicklung komplexer Vertex-/Pixel-Shader-Algorithmen vereinfachen, aber ich konnte seine Funktionalität nie ausreichend auf der CPU testen.
Im nächsten Artikel möchte ich das Mischen mehrerer Animationen beschreiben und die verbleibenden Lücken schließen.
Quellen
https://www.youtube.com/watch?v= f3Cr8Yx3GGA
In diesem Beitrag beschreibe ich eine Möglichkeit, mithilfe der Tiny-JS-Bibliothek Unterstützung für JavaScript-Skripte zu einer C++-Anwendung hinzuzufügen.
Tiny-JS ist eine Bibliothek zum Einbetten in C++, die die Ausführung von JavaScript-Code ermöglicht und Bindungen unterstützt (die Möglichkeit, C++-Code aus Skripten aufzurufen)
Zuerst wollte ich die beliebten Bibliotheken ChaiScript, Duktape oder Connect Lua verwenden, aber aufgrund von Abhängigkeiten und möglichen Schwierigkeiten bei der Portabilität auf verschiedene Plattformen entschied ich mich, eine einfache, minimale, aber leistungsstarke MIT Tiny-Bibliothek zu finden; JS erfüllt diese Kriterien. Der einzige Nachteil dieser Bibliothek ist die fehlende Unterstützung/Entwicklung durch den Autor, ihr Code ist jedoch recht einfach, sodass Sie bei Bedarf die Unterstützung übernehmen können.
Laden Sie Tiny-JS aus dem Repository herunter:
https://github.com/gfwilliams/tiny-js
Fügen Sie als Nächstes Tiny-JS-Header zum Code hinzu, der für die Skripte verantwortlich ist:
#include "tiny-js/TinyJS.h"
#include "tiny-js/TinyJS_Functions.h"
Fügen Sie TinyJS-CPP-Dateien zur Build-Phase hinzu, dann können Sie mit dem Schreiben von Lade- und Ausführungsskripten beginnen.
Ein Beispiel für die Verwendung der Bibliothek ist im Repository verfügbar:
https://github.com/gfwilliams/tiny-js/blob/master/Script.cpp
https://github.com/gfwilliams/tiny-js/blob/wiki/CodeExamples.md
Ein Beispiel für die Implementierung der Handler-Klasse finden Sie im SpaceJaguar-Projekt:
https://gitlab.com/demensdeum/space-jaguar-action-rpg/-/blob/master/project/src/Controllers/SpaceJaguarScriptController/SpaceJaguarScriptController.h
https://gitlab.com/demensdeum/space-jaguar-action-rpg/-/blob/master/project/src/Controllers/SpaceJaguarScriptController/SpaceJaguarScriptController.cpp
Beispiel eines der Anwendung hinzugefügten Spielskripts:
https://gitlab.com/demensdeum/space-jaguar-action-rpg/-/blob/master/project/resources/com.demensdeum.spacejaguaractionrpg.scripts.sceneController.js
Quellen
https://github.com/gfwilliams/tiny-js
https://github.com/dbohdan/embedded-scripting-languages
https://github.com/AlexKotik/embeddable-scripting-languages
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
Manage consent






.gif)