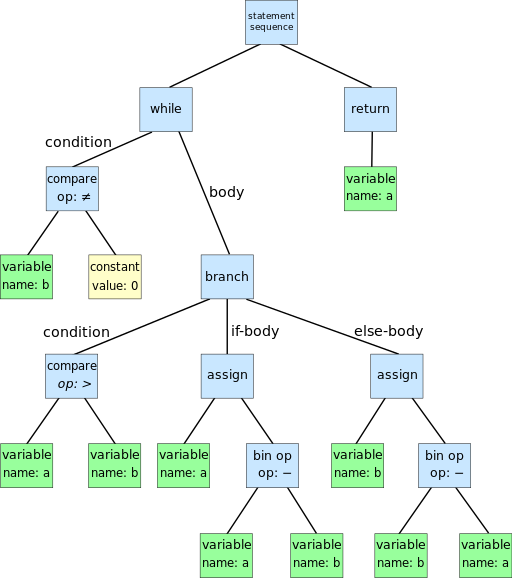
В этой заметке я опишу как загружать цвета в палитру Сеги на ассемблере.
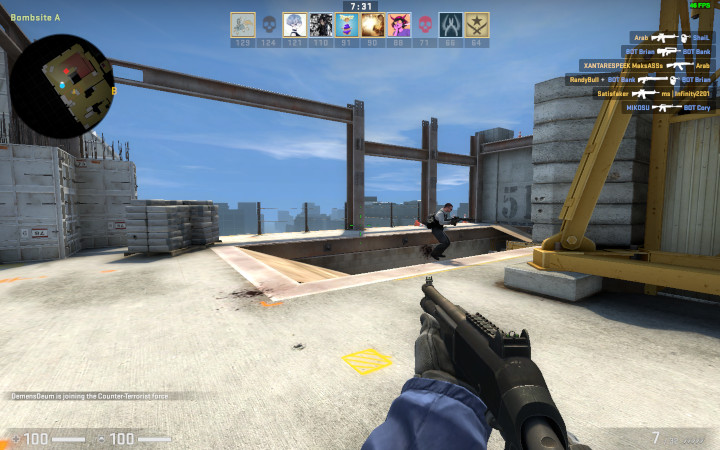
Итоговый результат в эмуляторе Exodus будет выглядеть так:
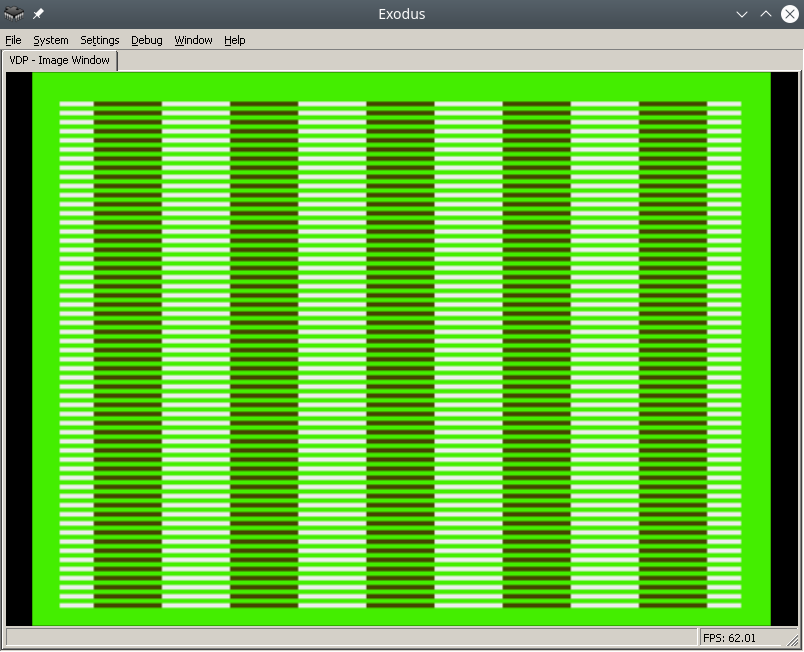
Чтобы процесс происходил проще, найдите в интернете pdf под названием Genesis Software Manual (1989), в нем описывается весь процесс в мельчайших деталях, по сути, эта заметка является комментариями к оригинальному мануалу.
Для того чтобы записывать цвета в VDP чип эмулятора Сеги, нужно сделать следующие вещи:
Для сборки будем использовать vasmm68k_mot и любимый текстовый редактор, например echo. Сборка осуществляется командой:
Порты VDP
VDP чип общается с M68K через два порта в оперативной памяти – порт контроля и порт данных.
По сути:
- Через порт контроля можно выставлять значения регистрам VDP.
- Также порт контроля является указателем на ту часть VDP (VRAM, CRAM, VSRAM etc.) через которую передаются данные через порт данных
Интересная информация: Сега сохранила совместимость с играми Master System, на что указывает MODE 4 из мануала разработчика, в нем VDP переключается в режим Master System.
Объявим порты контроля и данных:
vdp_data_port = $C00000
Отключить систему защиты TMSS
Защита от нелицензионных игр TMSS имеет несколько вариантов разблокировки, например требуется чтобы до обращения к VDP в адресном регистре A1 лежала строка “SEGA”.
MOVE.B A1,D0; Получаем версию хардвары цифрой из A1 в регистр D0
ANDI.B 0x0F,D0; По маске берем последние биты, чтобы ничего не сломать
BEQ.B SkipTmss; Если версия равна 0, скорее всего это японка или эмулятор без включенного TMSS, тогда идем в сабрутину SkipTmss
MOVE.L "SEGA",A1; Или записываем строку SEGA в A1
Записать правильные параметры в регистры VDP
Зачем вообще выставлять правильные параметры в регистры VDP? Идея в том, что VDP может многое, поэтому перед отрисовкой нужно проинициализировать его с нужными фичами, иначе он просто не поймет, что от него хотят.
Каждый регистр отвечает за определенную настройку/режим работы. В Сеговском мануале указаны все биты/флажки для каждого из 24 регистров, описание самих регистров.
Возьмем готовые параметры с комментариями из блога bigevilcorporation:
VDPReg0: dc.b $14 ; 0: H interrupt on, palettes on
VDPReg1: dc.b $74 ; 1: V interrupt on, display on, DMA on, Genesis mode on
VDPReg2: dc.b $30 ; 2: Pattern table for Scroll Plane A at VRAM $C000
; (bits 3-5 = bits 13-15)
VDPReg3: dc.b $00 ; 3: Pattern table for Window Plane at VRAM $0000
; (disabled) (bits 1-5 = bits 11-15)
VDPReg4: dc.b $07 ; 4: Pattern table for Scroll Plane B at VRAM $E000
; (bits 0-2 = bits 11-15)
VDPReg5: dc.b $78 ; 5: Sprite table at VRAM $F000 (bits 0-6 = bits 9-15)
VDPReg6: dc.b $00 ; 6: Unused
VDPReg7: dc.b $00 ; 7: Background colour - bits 0-3 = colour,
; bits 4-5 = palette
VDPReg8: dc.b $00 ; 8: Unused
VDPReg9: dc.b $00 ; 9: Unused
VDPRegA: dc.b $FF ; 10: Frequency of Horiz. interrupt in Rasters
; (number of lines travelled by the beam)
VDPRegB: dc.b $00 ; 11: External interrupts off, V scroll fullscreen,
; H scroll fullscreen
VDPRegC: dc.b $81 ; 12: Shadows and highlights off, interlace off,
; H40 mode (320 x 224 screen res)
VDPRegD: dc.b $3F ; 13: Horiz. scroll table at VRAM $FC00 (bits 0-5)
VDPRegE: dc.b $00 ; 14: Unused
VDPRegF: dc.b $02 ; 15: Autoincrement 2 bytes
VDPReg10: dc.b $01 ; 16: Vert. scroll 32, Horiz. scroll 64
VDPReg11: dc.b $00 ; 17: Window Plane X pos 0 left
; (pos in bits 0-4, left/right in bit 7)
VDPReg12: dc.b $00 ; 18: Window Plane Y pos 0 up
; (pos in bits 0-4, up/down in bit 7)
VDPReg13: dc.b $FF ; 19: DMA length lo byte
VDPReg14: dc.b $FF ; 20: DMA length hi byte
VDPReg15: dc.b $00 ; 21: DMA source address lo byte
VDPReg16: dc.b $00 ; 22: DMA source address mid byte
VDPReg17: dc.b $80 ; 23: DMA source address hi byte,
; memory-to-VRAM mode (bits 6-7)
Ок, теперь пойдем в порт контроля и запишем все флажки в регистры VDP:
move.l #VDPRegisters,a0 ; Пишем адрес таблицы параметров в A1
move.l #$18,d0 ; Счетчик цикла - 24 = 18 (HEX) в D0
move.l #$00008000,d1 ; Готовим команду на запись в регистр VDP по индексу 0, по мануалу - 1000 0000 0000 0000 (BIN) = 8000 (HEX)
FillInitialStateForVDPRegistersLoop:
move.b (a0)+,d1 ; Записываем в D1 итоговое значение регистра VDP из таблицы параметров, на отправку в порт контроля VDP
move.w d1,vdp_control_port ; Отправляем итоговую команду + значение из D1 в порт контроля VDP
add.w #$0100,d1 ; Поднимаем индекс регистра VDP на 1 (бинарное сложение +1 к индексу по мануалу Сеги)
dbra d0,FillInitialStateForVDPRegistersLoop ; Уменьшаем счетчик регистров, продолжаем цикл если необходимо
Самое сложное это прочитать мануал и понять в каком формате подаются данные на порт контроля, опытные разработчики разберутся сразу, а вот неопытные… Немного подумают и поймут, что синтаксис для записи регистров такой:
0B100(5 бит – индекс регистра)(8 бит/байт – значение)
0B1000001001000101 – записать в регистр VDP 2 (00010), значение флажков 01000101.
Записать нужные цвета в CRAM
Далее идем писать два цвета в память цветов CRAM (Color RAM). Для этого пишем в порт контроля команду на доступ к цвету по индексу 0 в CRAM и отправляем по дата порту цвет. Все!
Пример:
move.l #$C0000000,vdp_control_port ; Доступ к цвету по индексу 0 в CRAM через порт контроля
move.w #228,d0; Цвет в D0
move.w d0,vdp_data_port; Отправляем цвет в порт данных
После сборки и запуска в эмуляторе в Exodus, у вас должен быть залит экран цветом 228.
Давайте зальем еще вторым цветом, по последнему байту 127.
move.l #$C07f0000,vdp_control_port ; Доступ к цвету по байту 127 в CRAM через порт контроля
move.w #69,d0; Цвет в D0
move.w d0,vdp_data_port; Отправляем цвет в порт данных
Ссылки
https://gitlab.com/demensdeum/segagenesissamples
https://www.exodusemulator.com/
http://sun.hasenbraten.de/vasm/
https://tomeko.net/online_tools/bin_to_32bit_hex.php?lang=en
Источники
https://namelessalgorithm.com/genesis/blog/genesis/
https://plutiedev.com/vdp-commands
https://huguesjohnson.com/programming/genesis/palettes/
https://www.chibiakumas.com/68000/helloworld.php#LessonH5
https://blog.bigevilcorporation.co.uk/2012/03/09/sega-megadrive-3-awaking-the-beast/
Первая статья посвященная написанию игр для классической приставки Sega Genesis на Ассемблере Motorola 68000.
Напишем простейший бесконечный цикл для Сеги. Для этого нам понадобятся: ассемблер, эмулятор с дизассемблером, любимый текстовый редактор, базовое понимание строения рома Сеги.
Для разработки я использую собственный ассемблер/дизассемблер Gen68KryBaby:
https://gitlab.com/demensdeum/gen68krybaby/
Тул разработан на языке Python 3, для сборки на вход подается файл с расширением .asm либо .gen68KryBabyDisasm, на выходе получается файл с расширением.gen68KryBabyAsm.bin, который можно запустить в эмуляторе, либо на реальной приставке (осторожно, отойдите подальше, приставка может взорваться!)
Также поддерживается дизассемблинг ромов, для этого на вход надо подать файл рома, вне расширений .asm или .gen68KryBabyDisasm. Поддержка опкодов будет увеличиваться или уменьшаться в зависимости от моего интереса к теме, участия контрибьютеров.
Структура
Заголовок рома Сеги занимает первые 512 байт. В нем содержится информация об игре, название, поддерживаемая периферия, чексумма, прочие системные флаги. Предполагаю, что без заголовка приставка даже не будет смотреть на ром, подумав, что он некорректный, мол “что вы мне тут даете?”
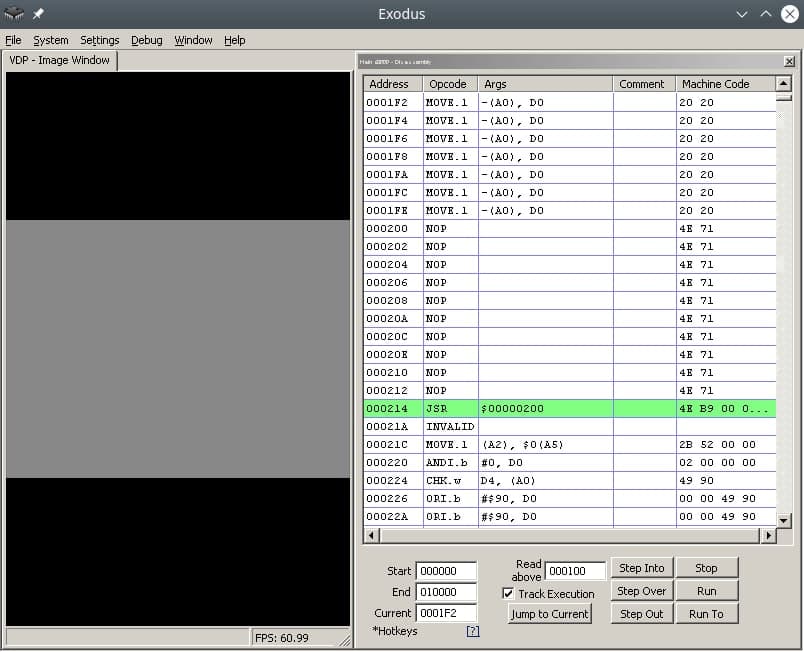
После заголовка идет сабрутина/подпрограмма Reset, с нее начинается работа процессора m68K. Хорошо, дело за малым – найти опкоды (коды операций), а именно выполнение ничего(!) и переход на сабрутину по адресу в памяти. Погуглив, можно найти опкод NOP, которые не делает ничего и опкод JSR который осуществляет безусловный переход на адрес аргумент, то есть просто двигает каретку туда куда мы его просим, без всяких капризов.
Собираем все вместе
Донором заголовка для рома выступила одна из игр в Beta версии, на данный момент записывается в виде hex данных.
00 ff 2b 52 00 00 02 00 00 00 49 90 00 00 49 90 00 00 49 90 00...и т.д.
Код программы со-но представляет из себя объявление сабрутины Reset/EntryPoint в 512 (0x200) байте, NOP, возврат каретки к 0x00000200, таким образом мы получим бесконечный цикл.
Ассемблерный код сабрутины Reset/EntryPoint:
NOP
NOP
NOP
NOP
NOP
JSR 0x00000200
Полный пример вместе с заголовком рома:
https://gitlab.com/demensdeum/segagenesissamples/-/blob/main/1InfiniteLoop/1infiniteloop.asm
Далее собираем:
В данной заметке я напишу о важности архитектурных решений при разработке, поддержке приложения, в условиях командной разработки.

Самодействующая салфетка профессора Люцифера Горгонзолы. Руб Голдберг
Во времена своей юности я работал над приложением для заказа такси. В проге можно было выбирать точку пикапа, точку дропа, рассчитывать стоимость поездки, тип тарифа, и собственно говоря, заказать такси. Приложение мне досталось на последнем этапе пред-запуска, после добавления нескольких фиксов приложение было выпущено в AppStore. Уже на том этапе вся команда понимала что реализована она очень плохо, паттерны проектирования не использовались, все компоненты системы были связаны намертво, в общем и целом, можно было ее записать в один большой сплошной класс (God object), ничего бы не изменилось, так как классы смешивали свои границы ответственности и в общей своей массе перекрывали друг друга мертвой сцепкой. Позже руководством было принято решение написать приложение с нуля, с использованием корректной архитектуры, что было выполнено и итоговый продукт был внедрен нескольким десяткам B2B клиентов.
Однако я опишу курьезный случай из прошлой архитектуры, от которого я иногда просыпаюсь в холодном поту посреди ночи, или внезапно вспоминаю посреди дня и начинаю истерично смеяться. Все дело в том что я не смог с первого раза попасть в мужика на шесте, и это обрушило бОльшую часть приложения, но обо всем по порядку.
Это был обычный рабочий день, от одного из заказчиков пришло задание немного доработать дизайн приложения – банально подвинуть на несколько пикселей вверх иконку в центре экрана выбора адреса пикапа. Что ж, профессионально оценив задачу в 10 минут я поднял иконку на 20 пикселей вверх, совершенно ничего не подозревая, я решил проверить заказ такси.
Что? Приложение больше не показывает кнопку заказа? Как это получилось?
Я не мог поверить своим глазам, после поднятия иконки на 20 пикселей приложение перестало показывать кнопку продолжения заказа. Откатив изменение я увидел кнопку снова. Что-то здесь было не так. Просидев 20 минут в дебаггере я немного устал от разматывания спагетти из вызовов перекрывающих друг друга классов, но обнаружил что *сдвигание картинки действительно меняет логику приложения*
Все дело было в иконке по центру – мужике на шесте, при сдвигании карты он подпрыгивал для анимации перемещения камеры, за этой анимацией следовало пропадание кнопки внизу. Видимо прога подумала что сдвинутый на 20 пикселей мужик находился в прыжке, поэтому по внутренней логике прятала кнопку подтверждения.
Как это может происходить? Неужели *состояние* экрана зависит не от паттерна машины состояния, а от *представления* позиции мужика на шесте?
Все так и оказалось, при каждой отрисовке карты приложение *визуально тыкало* в середину экрана и проверяла что там, если там мужик на шесте то это значит что анимация сдвига карты закончилась и нужно показать кнопку. В случае когда мужика там нет — значит происходит сдвиг карты, и кнопку надо спрятать.
В примере выше прекрасно все, во первых это пример Машины Голдберга (заумные машины), во вторых пример нежелания разработчика как-то взаимодействовать с другими разработчиками в команде (попробуй разберись без меня), в третьих можно перечислить все проблемы по SOLID, паттернам (запахи кода), нарушение MVC и многое многое другое.
Старайтесь так не делать, развивайтесь во всех возможных направлениях, помогайте своим коллегам в работе. Всех с наступившим новым годом)
Ссылки
https://ru.wikipedia.org/wiki/Машина_Голдберга
https://ru.wikipedia.org/wiki/SOLID
https://refactoring.guru/ru/refactoring/smells
https://ru.wikipedia.org/wiki/Model-View-Controller
https://refactoring.guru/ru/design-patterns/state
В данной заметке я опишу работу с текстовым классификатором fasttext.
Fasttext – библиотека машинного обучения для классификации текстов. Попробуем научить ее определять метал группу по названию песни. Для этого используем обучение с учителем при помощи датасета.
Создадим датасет песен с названиями групп:
__label__metallica fuel
__label__metallica escape
__label__black_sabbath gypsy
__label__black_sabbath snowblind
__label__black_sabbath am i going insane
__label__anthrax anthrax
__label__anthrax i'm alive
__label__anthrax antisocial
[и т.д.]
Формат обучающей выборки:
Обучим fasttext и сохраним модель:
model.save_model("model.bin")
Загрузим обученную модель и попросим определить группу по названию песни:
predictResult = model.predict("Bleed")
print(predictResult)
В результате мы получим список классов на которые похож данный пример, с указанием уровня похожести цифрой, в нашем случае похожесть названия песни Bleed на одну из групп датасета.
Для того чтобы модель fasttext умела работать с датасетом выходящим за границы обучающей выборки, используют режим autotune с использованием файла валидации (файл тест). Во время автотюна fasttext подбирает оптимальные гиперпараметры модели, проводя валидацию результата на выборке из тест файла. Время автотюна ограничивается пользователем в самостоятельно, с помощью передачи аргумента autotuneDuration.
Пример создания модели с использованием файла тест:
В данной заметке я опишу процесс вызова функций Си из ассемблера.
Попробуем вызвать printf(“Hello World!\n”); и exit(0);
message: db "Hello, world!", 10, 0
section .text
extern printf
extern exit
global main
main:
xor rax, rax
mov rdi, message
call printf
xor rdi, rdi
call exit
Все гораздо проще чем кажется, в секции .rodata мы опишем статичные данные, в данном случае строку “Hello, world!”, 10 это символ новой строки, также не забудем занулить ее.
В секции кода объявим внешние функции printf, exit библиотек stdio, stdlib, также объявим функцию входа main:
extern printf
extern exit
global main
В регистр возврата из функции rax передаем 0, можно использовать mov rax, 0; но для ускорения используют xor rax, rax; Далее в первый аргумент передаем указатель на строку:
В данной заметке я опишу процесс настройки IDE, написание первого Hello World на ассемблере x86_64 для операционной системы Ubuntu Linux.
Начнем с установки IDE SASM, ассемблера nasm:
Далее запустим SASM и напишем Hello World:
section .text
main:
mov rbp, rsp ; for correct debugging
mov rax, 1 ; write(
mov rdi, 1 ; STDOUT_FILENO,
mov rsi, msg ; "Hello, world!\n",
mov rdx, msglen ; sizeof("Hello, world!\n")
syscall ; );
mov rax, 60 ; exit(
mov rdi, 0 ; EXIT_SUCCESS
syscall ; );
section .rodata
msg: db "Hello, world!"
msglen: equ $-msg
Код Hello World взят из блога Джеймса Фишера, адаптирован для сборки и отладки в SASM. В документации SASM указано что точкой входа должна быть функция с именем main, иначе отладка и компиляция кода будет некорректной.
Что мы сделали в данном коде? Произвели вызов syscall – обращение к ядру операционной системы Linux с корректными аргументами в регистрах, указателем на строку в секции данных.
Под лупой
Рассмотрим код подробнее:
global – директива ассемблера позволяющая задавать глобальные символы со строковыми именами. Хорошая аналогия – интерфейсы заголовочных файлов языков C/C++. В данном случае мы задаем символ main для функции входа.
section – директива ассемблера позволяющая задавать секции (сегменты) кода. Директивы section или segment равнозначны. В секции .text помещается код программы.
Обьявляем начало функции main. В ассемблере функции называются подпрограммами (subroutine)
Первая машинная команда mov – помещает значение из аргумента 1 в аргумент 2. В данном случае мы переносим значение регистра rbp в rsp. Из комментария можно понять что эту строку добавил SASM для упрощения отладки. Видимо это личные дела между SASM и дебаггером gdb.
Далее посмотрим на код до сегмента данных .rodata, два вызова syscall, первый выводит строку Hello World, второй обеспечивает выход из приложения с корректным кодом 0.
Представим себе что регистры это переменные с именами rax, rdi, rsi, rdx, r10, r8, r9. По аналогии с высокоуровневыми языками, перевернем вертикальное представление ассемблера в горизонтальное, тогда вызов syscall будет выглядеть так:
Тогда вызов печати текста:
Вызов exit с корректным кодом 0:
Рассмотрим аргументы подробнее, в заголовочном файле asm/unistd_64.h находим номер функции __NR_write – 1, далее в документации смотрим аргументы для write:
ssize_t write(int fd, const void *buf, size_t count);
Первый аргумент – файловый дескриптор, второй – буфер с данными, третий – счетчик байт для записи в дескриптор. Ищем номер файлового дескриптора для стандартного вывода, в мануале по stdout находим код 1. Далее дело за малым, передать указатель на буфер строки Hello World из секции данных .rodata – msg, счетчик байт – msglen, передать в регистры rax, rdi, rsi, rdx корректные аргументы и вызвать syscall.
Обозначение константных строк и длины описывается в мануале nasm:
Хеш таблица позволяет реализовать структуру данных ассоциативный массив (словарь), со средней производительностью O(1) для операций вставки, удаления, поиска.
Ниже пример простейшей реализации хэш мапы на nodeJS:
Как это работает? Следим за руками:
- Внутри хеш мапы находится массив
- Внутри элемента массива находится указатель на первую ноду связанного списка
- Размечается память для массива указателей (например 65535 элементов)
- Реализуют хеш функцию, на вход идет ключ словаря, а на выходе она может делать что угодно, но в итоге возвращает индекс элемента массива
Как работает запись:
- На вход идет пара ключ – значение
- Хэш функция возвращает индекс по ключу
- Получаем ноду связанного списка из массива по индексу
- Проверяем соответствует ли он ключу
- Если соответствует, то заменяем значение
- Если не соответствует, то переходим к следующей ноде, пока найдем либо, не найдем ноду с нужным ключом.
- Если ноду так и не нашли, то создаем ее в конце связанного списка
Как работает поиск по ключу:
- На вход идет пара ключ – значение
- Хэш функция возвращает индекс по ключу
- Получаем ноду связанного списка из массива по индексу
- Проверяем соответствует ли он ключу
- Если соответствует, то возвращаем значение
- Если не соответствует, то переходим к следующей ноде, пока найдем либо, не найдем ноду с нужным ключом.
Зачем нужен связанный список внутри массива? Из-за возможных коллизий при вычислении хеш функции. В таком случае несколько разных пар ключ-значение будут находиться по одинаковому индексу в массиве, в таком случае осуществляется проход по связанному списку с поиском необходимого ключа.
Источники
https://ru.wikipedia.org/wiki/Хеш-таблица
https://www.youtube.com/watch?v=wg8hZxMRwcw
Исходный код
https://gitlab.com/demensdeum/datastructures
Для работы с ресурсами в Android через ndk – C++ существует несколько вариантов:
- Использовать доступ к ресурсам из apk файла, с помощью AssetManager
- Загружать ресурсы из интернета и распаковав их в директорию приложения, использовать с помощью стандартных методов C++
- Комбинированный способ – получить доступ к архиву с ресурсами в apk через AssetManager, распаковать их в директорию приложения, далее использовать с помощью стандартных методов C++
Далее я опишу комбинированный способ доступа, использующийся в игровом движке Flame Steel Engine.
При использовании SDL можно упростить доступ к ресурсам из apk, библиотека оборачивает вызовы к AssetManager, предлагая схожие с stdio интерфейсы (fopen, fread, fclose и т.д.)
SDL_RWops *io = SDL_RWFromFile("files.fschest", "r");
После загрузки архива из apk в буфер, нужно сменить текущую рабочую директорию на директорию приложения, она доступна для приложения без получения дополнительных разрешений. Для этого воспользуемся оберткой на SDL:
chdir(SDL_AndroidGetInternalStoragePath());
Далее записываем архив из буфера в текущую рабочую директорию с помощью fopen, fwrite, fclose. После того как архив окажется в доступной для C++ директории, распакуем его. Архивы zip можно распаковывать с помощью комбинации двух библиотек – minizip и zlib, первая умеет работать со структурой архивов, вторая же распаковывает данные.
Для получения более полного контроля, простоты портирования, я реализовал собственный формат архивов с нулевым сжатием под названием FSChest (Flame Steel Chest). Данный формат поддерживает архивацию директории с файлами, и распаковку; Поддержка иерархии папок отсутствует, возможна работа только с файлами.
Подключаем header библиотеки FSChest, распаковываем архив:
#include "fschest.h"
FSCHEST_extractChestToDirectory(archivePath, SDL_AndroidGetInternalStoragePath());
После распаковки интерфейсам C/C++ будут доступны файлы из архива. Таким образом мне не пришлось переписывать всю работу с файлами в движке, а лишь добавить распаковку файлов на этапе запуска.
Источники
https://developer.android.com/ndk/reference/group/asset
Исходный Код
https://gitlab.com/demensdeum/space-jaguar-action-rpg
https://gitlab.com/demensdeum/fschest
Допустим нам необходимо реализовать простой интерпретатор байткода, какой подход к реализации этой задачи выбрать?
Структура данных Стек предоставляет возможность реализовать простейшую байткод-машину. Особенности и реализации стек машин описаны во множестве статей западного и отечественного интернета, упомяну только что виртуальная машина Java является примером стековой машины.
Принцип работы машины прост, на вход подается программа содержащая данные и коды операций (опкоды), с помощью манипуляций со стеком выполняется реализация необходимых операций. Рассмотрим пример программы байткода моей стековой машины:
На выходе мы получим строку “Hello StackVM”. Стэк машина прочитывает программу слева-направо, загружая посимвольно данные в стек, при появлении опкода в символе – выполняет реализацию команды с использованием стека.
Пример реализации стековой машины на nodejs:
Обратная польская запись (RPN)
Также стековые машины легко использовать для реализации калькуляторов, для этого используют Обратную польскую запись (постфиксную запись).
Пример обычной инфиксной записи:
2*2+3*4
Конвертируется в RPN:
22*34*+
Для подсчета постфиксной записи используем стек машину:
2 – на вершину стека (стек: 2)
2 – на вершину стека (стек: 2,2)
* – получаем вершину стека два раза, перемножаем результат, отправляем на вершину стека (стек: 4)
3 – на вершину стека (стек: 4, 3)
4 – на вершину стека (стек: 4, 3, 4)
* – получаем вершину стека два раза, перемножаем результат, отправляем на вершину стека (стек: 4, 12)
+ – получаем вершину стека два раза, складываем результат, отправляем на вершину стека (стек: 16)
Как можно заметить – результат операций 16 остается в стеке, его можно вывести реализовав опкоды печати стека, например:
п22*34*+П
П – опкод начала печати стека, п – опкод окончания печати стека и отправки итоговой строки на рендеринг.
Для конвертации арифметических операций из инфиксной в постфикснуют используют алгоритм Эдсгера Дейкстры под названием “Сортировочная станция”. Пример реализации можно посмотреть выше, либо в репозитории проекта стек машины на nodejs ниже.
Источники
https://tech.badoo.com/ru/article/579/interpretatory-bajt-kodov-svoimi-rukami/
https://ru.wikipedia.org/wiki/Обратная_польская_запись
Исходный код
https://gitlab.com/demensdeum/stackvm/
Продолжаю описывать алгоритм скелетной анимации, по мере его реализации в игровом движке Flame Steel Engine.
Так как алгоритм является наисложнейшим из всех что я реализовывал, в заметках о процессе разработки могут появляться ошибки. В прошлой статье о данном алгоритме я допустил ошибку, массив костей передается в шейдер для каждого мэша по отдельности, а не для всей модели.
Иерархия нод
Для корректной работы алгоритма необходимо чтобы модель содержала в себе связь костей друг с другом (граф). Представим себе ситуацию при которой проигрываются одновременно две анимации – прыжок и поднятие правой руки. Анимация прыжка должна поднимать модель по оси Y, при этом анимация поднятия руки должна учитывать это и подниматься вместе с моделью в прыжке, иначе рука останется сама по себе на месте.
Опишем связь нод для данного случая – тело содержит руку. При отработке алгоритма будет произведено чтение графа костей, все анимации будут учтены с корректными связями. В памяти модели граф хранится отдельно от всех анимаций, только для отражения связанности костей модели.
Интерполяция на CPU
В прошлой статья я описал принцип рендеринга скелетной анимации – “матрицы трансформации передаются из CPU в шейдер при каждом кадре рендеринга.”
Каждый кадр рендеринга обрабатывается на CPU, для каждой кости мэша движок получает финальную матрицу трансформации с помощью интерполяции позиции, поворота, увеличения. Во время интерполяции финальной матрицы кости, производится проход по древу нод для всех активных анимаций нод, финальная матрица перемножается с родительскими, затем отправляется на рендеринг в вертексный шейдер.
Для интерполяции позиции и увеличения используют вектора, для поворота используются кватернионы, т.к. они очень легко интерполируются (SLERP) в отличии от углов Эйлера, также их очень просто представить в виде матрицы трансформации.
Как упростить реализацию
Чтобы упростить отладку работы вертексного шейдера, я добавил симуляцию работы вертексного шейдера на CPU с помощью макроса FSGLOGLNEWAGERENDERER_CPU_BASED_VERTEX_MODS_ENABLED. У производителя видеокарт NVIDIA есть утилита для отладки шейдерного кода Nsight, возможно она тоже может упростить разработку сложных алгоритмов вертексного/пиксельных шейдеров, однако проверить работоспособность мне так и не довелось, хватило симуляции на CPU.
В следующей статье я планирую описать микширование нескольких анимаций, заполнить оставшиеся пробелы.
Источники
https://www.youtube.com/watch?v=f3Cr8Yx3GGA
В данной заметке я опишу способ добавления поддержки JavaScript скриптов в приложение на C++ с помощью библиотеки Tiny-JS.
Tiny-JS представляет из себя библиотеку для встраивания в C++, обеспечивающая выполнение JavaScript кода, с поддержкой биндингов (возможность вызывать код C++ из скриптов)
Сначала я хотел использовать популярные библиотеки ChaiScript, Duktape или подключить Lua, но из-за зависимостей и возможных сложностей в портируемости на разные платформы, было принято решение найти простую, минимальную, но мощную MIT JS либу, этим критериям отвечает Tiny-JS. Единственный минус этой библиотеки в отсутствии поддержки/развития автором, однако ее код достаточно прост, что позволяет взять поддержку на себя, если это потребуется.
Загрузите Tiny-JS из репозитория:
https://github.com/gfwilliams/tiny-js
Далее добавьте в код который отвечает за скрипты хидеры Tiny-JS:
#include "tiny-js/TinyJS.h"
#include "tiny-js/TinyJS_Functions.h"
На этап сборки добавьте .cpp файлы TinyJS, далее можно приступать к написанию загрузки и запуска скриптов.
Пример использования библотеки доступен ее в репозитории:
https://github.com/gfwilliams/tiny-js/blob/master/Script.cpp
https://github.com/gfwilliams/tiny-js/blob/wiki/CodeExamples.md
Пример имплементации класса-обработчика можно посмотреть в проекте SpaceJaguar:
https://gitlab.com/demensdeum/space-jaguar-action-rpg/-/blob/master/project/src/Controllers/SpaceJaguarScriptController/SpaceJaguarScriptController.h
https://gitlab.com/demensdeum/space-jaguar-action-rpg/-/blob/master/project/src/Controllers/SpaceJaguarScriptController/SpaceJaguarScriptController.cpp
Пример игрового скрипта добавленного в приложение:
https://gitlab.com/demensdeum/space-jaguar-action-rpg/-/blob/master/project/resources/com.demensdeum.spacejaguaractionrpg.scripts.sceneController.js
Источники
https://github.com/gfwilliams/tiny-js
https://github.com/dbohdan/embedded-scripting-languages
https://github.com/AlexKotik/embeddable-scripting-languages
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
Manage consent






.gif)