Shell Sort – uma variante da classificação por inserção com combinação preliminar de uma matriz de números.
Precisamos lembrar como funciona a classificação por inserção:
1. Um loop é iniciado do zero até o final do loop, assim o array é dividido em duas partes 2. Para a parte esquerda, um segundo loop é iniciado, comparando os elementos da direita para a esquerda, o elemento menor à direita é descartado até que um elemento menor à esquerda seja encontrado 3. No final de ambos os loops, obtemos uma lista ordenada
Era uma vez, o cientista da computação Donald Schell se perguntou como melhorar o algoritmo de classificação por inserção. Ele também teve a ideia de primeiro percorrer o array em dois ciclos, mas a uma certa distância, reduzindo gradativamente o “pente” até que ele se transforme em um algoritmo regular de ordenação por inserção. Tudo é realmente tão simples, sem armadilhas, aos dois ciclos acima acrescentamos outro, no qual vamos reduzindo gradativamente o tamanho do “pente”. A única coisa que você precisa fazer é verificar a distância ao comparar para que ela não ultrapasse o array.
Um tópico realmente interessante é escolher a sequência para alterar o comprimento da comparação a cada iteração do primeiro loop. É interessante porque o desempenho do algoritmo depende disso.
Pessoas diferentes estiveram envolvidas no cálculo da distância ideal, aparentemente, esse assunto era muito interessante para elas. Eles não poderiam simplesmente executar Ruby e chamar o algoritmo sort() mais rápido?
Em geral, essas pessoas estranhas escreveram dissertações sobre o tema do cálculo da distância/gap do “pente” para o algoritmo Shell. Simplesmente usei os resultados do trabalho deles e verifiquei 5 tipos de sequências, Hibbard, Knuth-Pratt, Chiura, Sedgwick.
import time
import random
from functools import reduce
import math
DEMO_MODE = False
if input("Demo Mode Y/N? ").upper() == "Y":
DEMO_MODE = True
class Colors:
BLUE = '\033[94m'
RED = '\033[31m'
END = '\033[0m'
def swap(list, lhs, rhs):
list[lhs], list[rhs] = list[rhs], list[lhs]
return list
def colorPrintoutStep(numbers: List[int], lhs: int, rhs: int):
for index, number in enumerate(numbers):
if index == lhs:
print(f"{Colors.BLUE}", end = "")
elif index == rhs:
print(f"{Colors.RED}", end = "")
print(f"{number},", end = "")
if index == lhs or index == rhs:
print(f"{Colors.END}", end = "")
if index == lhs or index == rhs:
print(f"{Colors.END}", end = "")
print("\n")
input(">")
def ShellSortLoop(numbers: List[int], distanceSequence: List[int]):
distanceSequenceIterator = reversed(distanceSequence)
while distance:= next(distanceSequenceIterator, None):
for sortArea in range(0, len(numbers)):
for rhs in reversed(range(distance, sortArea + 1)):
lhs = rhs - distance
if DEMO_MODE:
print(f"Distance: {distance}")
colorPrintoutStep(numbers, lhs, rhs)
if numbers[lhs] > numbers[rhs]:
swap(numbers, lhs, rhs)
else:
break
def ShellSort(numbers: List[int]):
global ShellSequence
ShellSortLoop(numbers, ShellSequence)
def HibbardSort(numbers: List[int]):
global HibbardSequence
ShellSortLoop(numbers, HibbardSequence)
def ShellPlusKnuttPrattSort(numbers: List[int]):
global KnuttPrattSequence
ShellSortLoop(numbers, KnuttPrattSequence)
def ShellPlusCiuraSort(numbers: List[int]):
global CiuraSequence
ShellSortLoop(numbers, CiuraSequence)
def ShellPlusSedgewickSort(numbers: List[int]):
global SedgewickSequence
ShellSortLoop(numbers, SedgewickSequence)
def insertionSort(numbers: List[int]):
global insertionSortDistanceSequence
ShellSortLoop(numbers, insertionSortDistanceSequence)
def defaultSort(numbers: List[int]):
numbers.sort()
def measureExecution(inputNumbers: List[int], algorithmName: str, algorithm):
if DEMO_MODE:
print(f"{algorithmName} started")
numbers = inputNumbers.copy()
startTime = time.perf_counter()
algorithm(numbers)
endTime = time.perf_counter()
print(f"{algorithmName} performance: {endTime - startTime}")
def sortedNumbersAsString(inputNumbers: List[int], algorithm) -> str:
numbers = inputNumbers.copy()
algorithm(numbers)
return str(numbers)
if DEMO_MODE:
maximalNumber = 10
numbersCount = 10
else:
maximalNumber = 10
numbersCount = random.randint(10000, 20000)
randomNumbers = [random.randrange(1, maximalNumber) for i in range(numbersCount)]
ShellSequenceGenerator = lambda n: reduce(lambda x, _: x + [int(x[-1]/2)], range(int(math.log(numbersCount, 2))), [int(numbersCount / 2)])
ShellSequence = ShellSequenceGenerator(randomNumbers)
ShellSequence.reverse()
ShellSequence.pop()
HibbardSequence = [
0, 1, 3, 7, 15, 31, 63, 127, 255, 511, 1023, 2047, 4095,
8191, 16383, 32767, 65535, 131071, 262143, 524287, 1048575,
2097151, 4194303, 8388607, 16777215, 33554431, 67108863, 134217727,
268435455, 536870911, 1073741823, 2147483647, 4294967295, 8589934591
]
KnuttPrattSequence = [
1, 4, 13, 40, 121, 364, 1093, 3280, 9841, 29524, 88573, 265720,
797161, 2391484, 7174453, 21523360, 64570081, 193710244, 581130733,
1743392200, 5230176601, 15690529804, 47071589413
]
CiuraSequence = [
1, 4, 10, 23, 57, 132, 301, 701, 1750, 4376,
10941, 27353, 68383, 170958, 427396, 1068491,
2671228, 6678071, 16695178, 41737946, 104344866,
260862166, 652155416, 1630388541
]
SedgewickSequence = [
1, 5, 19, 41, 109, 209, 505, 929, 2161, 3905,
8929, 16001, 36289, 64769, 146305, 260609, 587521,
1045505, 2354689, 4188161, 9427969, 16764929, 37730305,
67084289, 150958081, 268386305, 603906049, 1073643521,
2415771649, 4294770689, 9663381505, 17179475969
]
insertionSortDistanceSequence = [1]
algorithms = {
"Default Python Sort": defaultSort,
"Shell Sort": ShellSort,
"Shell + Hibbard" : HibbardSort,
"Shell + Prat, Knutt": ShellPlusKnuttPrattSort,
"Shell + Ciura Sort": ShellPlusCiuraSort,
"Shell + Sedgewick Sort": ShellPlusSedgewickSort,
"Insertion Sort": insertionSort
}
for name, algorithm in algorithms.items():
measureExecution(randomNumbers, name, algorithm)
reference = sortedNumbersAsString(randomNumbers, defaultSort)
for name, algorithm in algorithms.items():
if sortedNumbersAsString(randomNumbers, algorithm) != reference:
print("Sorting validation failed")
exit(1)
print("Sorting validation success")
exit(0)
Na minha implementação, para um conjunto aleatório de números, as lacunas mais rápidas são Sedgwick e Hibbard.
meupy
Gostaria também de mencionar o analisador de tipagem estática para Python 3 – meu Deus. Ajuda a resolver os problemas inerentes às linguagens com digitação dinâmica, nomeadamente, elimina a possibilidade de colar algo onde não é necessário.
Como dizem programadores experientes, “a digitação estática não é necessária quando você tem uma equipe de profissionais”, um dia todos nos tornaremos profissionais, escreveremos código em total unidade e compreensão com as máquinas, mas por enquanto você pode usar utilitários semelhantes e linguagens de tipo estaticamente.
Classificação por seleção dupla – um subtipo de classificação por seleção, parece que deveria ser duas vezes mais rápido. O algoritmo vanilla faz um loop duplo pela lista de números, encontra o número mínimo e troca de lugar com o número atual apontado pelo loop no nível acima. A classificação por seleção dupla procura os números mínimo e máximo e, em seguida, substitui os dois dígitos apontados pelo loop no nível acima de – dois números à esquerda e à direita. Toda essa orgia termina quando os cursores dos números a serem substituídos são encontrados no meio da lista e, como resultado, os números ordenados são obtidos à esquerda e à direita do centro visual. A complexidade de tempo do algoritmo é semelhante à classificação por seleção – O(n2), mas supostamente há uma aceleração de 30 %.
Estado limítrofe
Já nesta fase, você pode imaginar o momento de uma colisão, por exemplo, quando o número do cursor esquerdo (o número mínimo) aponta para o número máximo da lista, então o número mínimo é reorganizado, o rearranjo do número máximo quebra imediatamente. Portanto, todas as implementações do algoritmo contêm a verificação de tais casos e a substituição dos índices pelos corretos. Na minha implementação, uma verificação foi suficiente:
maximalNumberIndex = minimalNumberIndex;
}
Реализация на Cito
Cito – язык либ, язык транслятор. На нем можно писать для C, C++, C#, Java, JavaScript, Python, Swift, TypeScript, OpenCL C, при этом совершенно ничего не зная про эти языки. Исходный код на языке Cito транслируется в исходный код на поддерживаемых языках, далее можно использовать как библиотеку, либо напрямую, исправив сгенеренный код руками. Эдакий Write once – translate to anything.
Double Selection Sort на cito:
{
public static int[] sort(int[]# numbers, int length)
{
int[]# sortedNumbers = new int[length];
for (int i = 0; i < length; i++) {
sortedNumbers[i] = numbers[i];
}
for (int leftCursor = 0; leftCursor < length / 2; leftCursor++) {
int minimalNumberIndex = leftCursor;
int minimalNumber = sortedNumbers[leftCursor];
int rightCursor = length - (leftCursor + 1);
int maximalNumberIndex = rightCursor;
int maximalNumber = sortedNumbers[maximalNumberIndex];
for (int cursor = leftCursor; cursor <= rightCursor; cursor++) { int cursorNumber = sortedNumbers[cursor]; if (minimalNumber > cursorNumber) {
minimalNumber = cursorNumber;
minimalNumberIndex = cursor;
}
if (maximalNumber < cursorNumber) {
maximalNumber = cursorNumber;
maximalNumberIndex = cursor;
}
}
if (leftCursor == maximalNumberIndex) {
maximalNumberIndex = minimalNumberIndex;
}
int fromNumber = sortedNumbers[leftCursor];
int toNumber = sortedNumbers[minimalNumberIndex];
sortedNumbers[minimalNumberIndex] = fromNumber;
sortedNumbers[leftCursor] = toNumber;
fromNumber = sortedNumbers[rightCursor];
toNumber = sortedNumbers[maximalNumberIndex];
sortedNumbers[maximalNumberIndex] = fromNumber;
sortedNumbers[rightCursor] = toNumber;
}
return sortedNumbers;
}
}
Classificação de coqueteleira – classificação por shaker, uma variante da classificação por bolha bidirecional. O algoritmo funciona da seguinte maneira:
A direção inicial da pesquisa no loop é selecionada (geralmente da esquerda para a direita)
A seguir no loop, os números são verificados em pares
Se o próximo elemento for maior, eles serão trocados
Ao terminar, o processo de busca recomeça com a direção invertida
A busca é repetida até que não haja mais permutações
A complexidade de tempo do algoritmo é semelhante à bolha – O(n2).
If the game doesn’t start with fcntl(5) for /tmp/source_engine_2808995433.lock failed, then try deleting the /tmp/source_engine_2808995433.lock file rm /tmp/source_engine_2808995433.lock
Usually the lock file is left over from the last game session unless the game was closed naturally.
How to check?
The easiest way to check the launch of applications on a discrete Nvidia graphics card is through the nvidia-smi utility:
For games on the Source engine, you can check through the game console using the mat_info command:
Classificação do sono – sleep sort, outro representante de algoritmos determinísticos de classificação estranha.
Funciona assim:
Percorre uma lista de elementos
Um thread separado é lançado para cada loop
O thread fica suspenso por um período de tempo – valor do elemento e saída do valor após dormir
No final do loop, aguarde a conclusão do sono mais longo do thread e exiba a lista classificada
Exemplo de código para algoritmo de classificação de sono em C:
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
typedef struct {
int number;
} ThreadPayload;
void *sortNumber(void *args) {
ThreadPayload *payload = (ThreadPayload*) args;
const int number = payload->number;
free(payload);
usleep(number * 1000);
printf("%d ", number);
return NULL;
}
int main(int argc, char *argv[]) {
const int numbers[] = {2, 42, 1, 87, 7, 9, 5, 35};
const int length = sizeof(numbers) / sizeof(int);
int maximal = 0;
pthread_t maximalThreadID;
printf("Sorting: ");
for (int i = 0; i < length; i++) { pthread_t threadID; int number = numbers[i]; printf("%d ", number); ThreadPayload *payload = malloc(sizeof(ThreadPayload)); payload->number = number;
pthread_create(&threadID, NULL, sortNumber, (void *) payload);
if (maximal < number) {
maximal = number;
maximalThreadID = threadID;
}
}
printf("\n");
printf("Sorted: ");
pthread_join(maximalThreadID, NULL);
printf("\n");
return 0;
}
Nesta implementação usei a função usleep em microssegundos com o valor multiplicado por 1000, ou seja, em milissegundos. Complexidade de tempo do algoritmo – O(muito longo)
Classificação de Stalin – sort through, um dos algoritmos de classificação com perda de dados. O algoritmo é muito produtivo e eficiente, complexidade de tempo O(n).
Funciona assim:
Percorre o array, comparando o elemento atual com o próximo
Se o próximo elemento for menor que o atual, remova-o
Como resultado, obtemos um array ordenado em O(n)
Exemplo de saída do algoritmo:
Gulag: [1, 3, 2, 4, 6, 42, 4, 8, 5, 0, 35, 10]
Element 2 sent to Gulag
Element 4 sent to Gulag
Element 8 sent to Gulag
Element 5 sent to Gulag
Element 0 sent to Gulag
Element 35 sent to Gulag
Element 10 sent to Gulag
Numbers: [1, 3, 4, 6, 42]
Gulag: [2, 4, 8, 5, 0, 35, 10]
Código Python 3:
gulag = []
print(f"Numbers: {numbers}")
print(f"Gulag: {numbers}")
i = 0
maximal = numbers[0]
while i < len(numbers):
element = numbers[i]
if maximal > element:
print(f"Element {element} sent to Gulag")
gulag.append(element)
del numbers[i]
else:
maximal = element
i += 1
print(f"Numbers: {numbers}")
print(f"Gulag: {gulag}")
As desvantagens incluem a perda de dados, mas se avançarmos em direção a uma lista utópica, ideal e ordenada em O(n), então de que outra forma?
Classificação por seleção – algoritmo de classificação por seleção. Escolhendo o quê? Mas o número mínimo!!! Complexidade de tempo do algoritmo – O(n2)
O algoritmo funciona da seguinte maneira:
Percorremos o array em um loop da esquerda para a direita, lembre-se do índice inicial atual e do número no índice, vamos chamá-lo de número A
Dentro do loop, executamos outro para ir da esquerda para a direita, procurando algo menor que A
Quando encontramos o menor, lembramos do índice, agora o menor vira o número A
Quando o loop interno terminar, troque o número no índice inicial e o número A
Depois de passar completamente pelo loop superior, obtemos um array ordenado
Não encontrei uma implementação de Objective-C no Rosetta Code , eu mesmo escrevi:
#include <Foundation/Foundation.h>
@implementation SelectionSort
- (void)performSort:(NSMutableArray *)numbers
{
NSLog(@"%@", numbers);
for (int startIndex = 0; startIndex < numbers.count-1; startIndex++) {
int minimalNumberIndex = startIndex;
for (int i = startIndex + 1; i < numbers.count; i++) {
id lhs = [numbers objectAtIndex: minimalNumberIndex];
id rhs = [numbers objectAtIndex: i];
if ([lhs isGreaterThan: rhs]) {
minimalNumberIndex = i;
}
}
id temporary = [numbers objectAtIndex: minimalNumberIndex];
[numbers setObject: [numbers objectAtIndex: startIndex]
atIndexedSubscript: minimalNumberIndex];
[numbers setObject: temporary
atIndexedSubscript: startIndex];
}
NSLog(@"%@", numbers);
}
@end
Собрать и запустить можно либо на MacOS/Xcode, либо на любой операционной системе поддерживающей GNUstep, например у меня собирается Clang на Arch Linux.
Скрипт сборки:
Classificação de contagem – algoritmo de classificação de contagem. Em termos de? Sim! Simples assim!
O algoritmo envolve pelo menos dois arrays, o primeiro – lista de inteiros a serem classificados, segundo – uma matriz de tamanho = (número máximo – número mínimo) + 1, contendo inicialmente apenas zeros. Em seguida, os números são classificados na primeira matriz e o elemento numérico é usado para obter um índice na segunda matriz, que é incrementado em um. Depois de percorrer toda a lista, obteremos um segundo array completamente preenchido com o número de repetições dos números do primeiro. O algoritmo tem uma séria sobrecarga – a segunda matriz também contém zeros para números que não estão na primeira lista, a chamada. sobrecarga da memória
Após receber o segundo array, iteramos por ele e escrevemos a versão ordenada do número por índice, decrementando o contador a zero. Inicialmente, um contador zero é ignorado.
Um exemplo de operação não otimizada do algoritmo de classificação por contagem:
Matriz de entrada 1,9,1,4,6,4,4
Então o array a ser contado será 0,1,2,3,4,5,6,7,8,9 (número mínimo 0, máximo 9)
Com contadores totais 0,2,0,0,3,0,1,0,0,1
Matriz classificada total 1,1,4,4,4,6,9
Código do algoritmo em Python 3:
numbers = [42, 89, 69, 777, 22, 35, 42, 69, 42, 90, 777]
minimal = min(numbers)
maximal = max(numbers)
countListRange = maximal - minimal
countListRange += 1
countList = [0] * countListRange
print(numbers)
print(f"Minimal number: {minimal}")
print(f"Maximal number: {maximal}")
print(f"Count list size: {countListRange}")
for number in numbers:
index = number - minimal
countList[index] += 1
replacingIndex = 0
for index, count in enumerate(countList):
for i in range(count):
outputNumber = minimal + index
numbers[replacingIndex] = outputNumber
replacingIndex += 1
print(numbers)
Из-за использования двух массивов, временная сложность алгоритма O(n + k)
Pseudo-classificação ou classificação por pântano, um dos algoritmos de classificação mais inúteis.
Funciona assim: 1. A entrada é uma matriz de números 2. Uma matriz de números é embaralhada aleatoriamente (embaralhar) 3. Verifica se o array está classificado 4. Se não for classificado, o array será embaralhado novamente 5. Toda essa ação é repetida até que o array seja classificado aleatoriamente.
Como você pode ver, o desempenho deste algoritmo é terrível, pessoas inteligentes acreditam que mesmo O(n * n!), ou seja, há uma chance de você ficar preso jogando dados para a glória do deus do caos por muitos anos, o array nunca será classificado, ou talvez será classificado?
Implementação
Para implementá-lo em TypeScript, precisei implementar as seguintes funções: 1. Embaralhe uma série de objetos 2. Comparação de matrizes 3. Gerando um número aleatório no intervalo de zero a um número (sic!) 4. Imprima o progresso, porque parece que a classificação continua indefinidamente
Abaixo está o código de implementação do TypeScript:
const randomInteger = (maximal: number) => Math.floor(Math.random() * maximal);
const isEqual = (lhs: any[], rhs: any[]) => lhs.every((val, index) => val === rhs[index]);
const shuffle = (array: any[]) => {
for (var i = 0; i < array.length; i++) { var destination = randomInteger(array.length-1); var temp = array[i]; array[i] = array[destination]; array[destination] = temp; } } let numbers: number[] = Array.from({length: 10}, ()=>randomInteger(10));
const originalNumbers = [...numbers];
const sortedNumbers = [...numbers].sort();
let numberOfRuns = 1;
do {
if (numberOfRuns % 1000 == 0) {
printoutProcess(originalNumbers, numbers, numberOfRuns);
}
shuffle(numbers);
numberOfRuns++;
} while (isEqual(numbers, sortedNumbers) == false)
console.log(`Success!`);
console.log(`Run number: ${numberOfRuns}`)
console.log(`Original numbers: ${originalNumbers}`);
console.log(`Current numbers: ${originalNumbers}`);
console.log(`Sorted numbers: ${sortedNumbers}`);
Для отладки можно использовать VSCode и плагин TypeScript Debugger от kakumei.
Как долго
Вывод работы алгоритма:
src/bogosort.ts:1
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 8,7,0,2,4,7,2,5,9,5, try number: 145000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 7,5,2,4,9,8,0,5,2,7, try number: 146000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 0,2,7,4,9,5,7,5,8,2, try number: 147000
src/bogosort.ts:2
Still trying to sort: 5,4,8,7,5,0,2,9,7,2, current shuffle 5,9,7,8,5,4,2,7,0,2, try number: 148000
src/bogosort.ts:2
Success!
src/bogosort.ts:24
Run number: 148798
src/bogosort.ts:25
Original numbers: 5,4,8,7,5,0,2,9,7,2
src/bogosort.ts:26
Current numbers: 5,4,8,7,5,0,2,9,7,2
src/bogosort.ts:27
Sorted numbers: 0,2,2,4,5,5,7,7,8,9
Для массива из 10 чисел Богосорт перемешивал исходный массив 148798 раз, многовато да?
Алгоритм можно использовать как учебный, для понимания возможностей языка с которым предстоит работать на рынке. Лично я был удивлен узнав что в ванильных JS и TS до сих пор нет своего алгоритма перемешивания массивов, генерации целого числа в диапазоне, доступа к хэшам объектов для быстрого сравнения.
O padrão Interpreter refere-se a padrões de design comportamentais. Este padrão permite implementar sua própria linguagem de programação trabalhando com uma árvore AST, cujos vértices são expressões terminais e não terminais que implementam o método Interpret, que fornece a funcionalidade da linguagem.
Expressão terminal – por exemplo, constante de string – “Olá, Mundo”
Expressão não terminal – por exemplo Print(“Hello World”), contém Print e um argumento da expressão Terminal “Hello World”
Qual é a diferença? A diferença é que a interpretação termina nas expressões terminais, mas para as não-terminais ela continua em profundidade em todos os vértices/argumentos recebidos. Se a árvore AST consistisse apenas em expressões não terminais, o aplicativo nunca seria concluído, porque é necessária uma certa finitude de qualquer processo, essa finitude é o que são as expressões terminais, elas geralmente contêm dados, por exemplo strings.
Um exemplo de árvore AST está abaixo:
Dcoetzee, CC0, via Wikimedia Commons
Como você pode ver, as expressões terminais são constantes e variáveis, as expressões não terminais são o resto.
O que não está incluído
A implementação do Interpretador não inclui a análise da entrada da string de idioma na árvore AST. Basta implementar classes de expressões terminais e não terminais, métodos Interpret com o argumento Context na entrada, criar uma árvore de expressões AST e executar o método Interpret na expressão raiz. Um contexto pode ser usado para armazenar o estado do aplicativo em tempo de execução.
Implementação
O padrão envolve:
Cliente – retorna a árvore AST e executa Interpret(context) para o nó raiz (Cliente)
Contexto – contém o estado da aplicação, passado para expressões quando interpretado (Contexto)
Expressão abstrata – uma classe abstrata contendo o método Interpret(context) (Expression)
A expressão terminal é uma expressão final, descendente de uma expressão abstrata (TerminalExpression)
Uma expressão não terminal não é uma expressão finita; ela contém ponteiros para vértices profundos na árvore AST. Os vértices subordinados geralmente afetam o resultado da interpretação da expressão não terminal (NonTerminalExpression).
Exemplo de cliente em C#
static void Main(string[] args)
{
var context = new Context();
var initialProgram = new PerformExpression(
new IExpression[] {
new SetExpression("alpha", "1"),
new GetExpression("alpha"),
new PrintExpression(
new IExpression[] {
new ConstantExpression("Hello Interpreter Pattern")
}
)
}
);
System.Console.WriteLine(initialProgram.interpret(context));
}
}
Exemplo de expressão abstrata em C#
{
String interpret(Context context);
}
Exemplo de expressão terminal em C# (String Constant)
Exemplo de expressão não terminal em C# (Iniciando e concatenando os resultados de vértices subordinados, utilizando o delimitador “;”
{
public PerformExpression(IExpression[] leafs) : base(leafs) {
this.leafs = leafs;
}
override public String interpret(Context context) {
var output = "";
foreach (var leaf in leafs) {
output += leaf.interpret(context) + ";";
}
return output;
}
}
Você consegue fazer isso funcionalmente?
Como é sabido, todas as linguagens Turing-completas são equivalentes. É possível transferir o padrão Orientado a Objetos para a linguagem de programação Funcional?
Para um experimento, vamos usar uma linguagem FP para a web chamada Elm. Não há classes no Elm, mas existem registros e tipos, portanto, os seguintes registros e tipos estão envolvidos na implementação:
Expressão – listando todas as expressões de linguagem possíveis (Expressão)
Expressão subordinada – uma expressão subordinada à expressão não terminal (ExpressionLeaf)
Contexto – um registro que armazena o estado do aplicativo (Contexto)
Funções que implementam métodos Interpret(context) – todas as funções necessárias que implementam a funcionalidade de expressões terminais e não terminais
Registros auxiliares do estado do Intérprete – necessários para o correto funcionamento do Intérprete, armazenam o estado do Intérprete, contexto
Um exemplo de função que implementa a interpretação para todo o conjunto de expressões possíveis no Elm:
case input.expression of
Constant text ->
{
output = text,
context = input.context
}
Perform leafs ->
let inputs = List.map (\leaf -> { expressionLeaf = leaf, context = input.context } ) leafs in
let startLeaf = { expressionLeaf = (Node (Constant "")), context = { variables = Dict.empty } } in
let outputExpressionInput = List.foldl mergeContextsAndRunLeafs startLeaf inputs in
{
output = (runExpressionLeaf outputExpressionInput).output,
context = input.context
}
Print printExpression ->
run
{
expression = printExpression,
context = input.context
}
Set key value ->
let variables = Dict.insert key value input.context.variables in
{
output = "OK",
context = { variables = variables }
}
Get key ->
{
output = Maybe.withDefault ("No value for key: " ++ key) (Dict.get key input.context.variables),
context = input.context
}
E quanto à análise?
A análise do código-fonte em uma árvore AST não está incluída no padrão Interpreter, existem várias abordagens para análise do código-fonte, mas falaremos mais sobre isso em outro momento. Na implementação do Interpreter for Elm, escrevi um analisador simples na árvore AST, consistindo em duas funções – análise de um vértice, análise de vértices subordinados.
parseLeafs state =
let tokensQueue = state.tokensQueue in
let popped = pop state.tokensQueue in
let tokensQueueTail = tail state.tokensQueue in
if popped == "Nothing" then
state
else if popped == "Perform(" then
{
tokensQueue = tokensQueue,
result = (state.result ++ [Node (parse tokensQueue)])
}
else if popped == ")" then
parseLeafs {
tokensQueue = tokensQueueTail,
result = state.result
}
else if popped == "Set" then
let key = pop tokensQueueTail in
let value = pop (tail tokensQueueTail) in
parseLeafs {
tokensQueue = tail (tail tokensQueueTail),
result = (state.result ++ [Node (Set key value)])
}
else if popped == "Get" then
let key = pop tokensQueueTail in
parseLeafs {
tokensQueue = tail tokensQueueTail,
result = (state.result ++ [Node (Get key)])
}
else
parseLeafs {
tokensQueue = tokensQueueTail,
result = (state.result ++ [Node (Constant popped)])
}
parse tokensQueue =
let popped = pop tokensQueue in
let tokensQueueTail = tail tokensQueue in
if popped == "Perform(" then
Perform (
parseLeafs {
tokensQueue = tokensQueueTail,
result = []
}
).result
else if popped == "Set" then
let key = pop tokensQueueTail in
let value = pop (tail tokensQueueTail) in
Set key value
else if popped == "Print" then
Print (parse tokensQueueTail)
else
Constant popped
Neste post irei descrever o algoritmo para conversão de um buffer RGB para cinza (Escala de Cinza). E isso é feito de forma bastante simples, cada canal de cor de pixel do buffer é convertido de acordo com uma determinada fórmula e a saída é uma imagem cinza. Método médio:
red = average;
green = average;
blue = average;
Складываем 3 цветовых канала и делим на 3.
Однако существует еще один метод – метод средневзвешенный, он учитывает цветовосприятие человека:
red = luminance;
green = luminance;
blue = luminance;
Какой метод лучше использовать? Да какой вам больше подходит для конкретной задачи. Далее сравнение методов с помощью тестовой цветовой сетки:
Пример реализации на JavaScript + HTML 5
image,
canvas,
weightedAverage
) {
const context = canvas.getContext('2d');
const imageWeight = image.width;
const imageHeight = image.height;
canvas.width = imageWeight;
canvas.height = imageHeight;
context.drawImage(image, 0, 0);
let pixels = context
.getImageData(
0,
0,
imageWeight,
imageHeight
);
for (let y = 0; y & lt; pixels.height; y++) {
for (let x = 0; x & lt; pixels.width; x++) {
const i = (y * 4) * pixels.width + x * 4;
let red = pixels.data[i];
let green = pixels.data[i + 1];
let blue = pixels.data[i + 2]
const average = (red + green + blue) / 3;
const luminance = 0.2126 * red +
0.7152 * green +
0.0722 * blue;
red = weightedAverage ? luminance : average;
green = weightedAverage ? luminance : average;
blue = weightedAverage ? luminance : average;
pixels.data[i] = red;
pixels.data[i + 1] = green;
pixels.data[i + 2] = blue;
}
}
context
.putImageData(
pixels,
0,
0,
0,
0,
pixels.width,
pixels.height
);
}
Se você receber o erro SDL_GetDesktopDisplayMode_REAL em um Macbook M1 ao iniciar o CSGO, faça conforme descrito abaixo. 1. Adicione opções de inicialização ao Steam para CSGO: -w 1440 -h 900 -tela cheia 2. Inicie o CSGO via Steam 3. Clique em Ignorar ou Sempre Ignorar o erro SDL_GetDesktopDisplayMode_REAL 4. Aproveite
Apresento a sua atenção uma tradução das primeiras páginas do artigo de Alan Turing – “SOBRE NÚMEROS COMPUTÁVEIS COM APLICAÇÃO AO PROBLEMA DE RESOLUÇÃO” 1936. Os primeiros capítulos contêm uma descrição dos computadores, que mais tarde se tornaram a base da computação moderna.
A tradução completa do artigo e a explicação podem ser lidas no livro do divulgador norte-americano Charles Petzold, intitulado “Reading Turing. Uma viagem pelo artigo marcante de Turing sobre computabilidade e máquinas de Turing – (ISBN 978-5-97060-231-7, 978-0-470-22905-7)
SOBRE NÚMEROS COMPUTÁVEIS COM APLICAÇÃO AO PROBLEMA DE RESOLUÇÃO
A. M. TURING
[Recebido em 28 de maio de 1936 – lido em 12 de novembro de 1936]
Os números computáveis podem ser brevemente descritos como números reais cujas expressões como frações decimais são calculáveis de um número finito de maneiras. Embora à primeira vista este artigo trate os números como computáveis, é quase tão fácil definir e explorar funções computáveis de uma variável inteira, uma variável real, uma variável computável, predicados computáveis e similares. Contudo, os problemas fundamentais associados a estes objetos computáveis são os mesmos em cada caso. Para uma consideração detalhada, escolhi números computáveis como objeto computável porque o método de considerá-los é o menos complicado. Espero descrever em breve a relação entre números computáveis e funções computáveis e assim por diante. Paralelamente, serão realizadas pesquisas no campo da teoria das funções de uma variável real expressa em termos de números computáveis. Pela minha definição, um número real é computável se a sua representação como uma fração decimal puder ser escrita por uma máquina.
Nos parágrafos 9 e 10 apresento alguns argumentos para mostrar que os números computáveis incluem todos os números que são naturalmente considerados computáveis. Em particular, mostro que algumas grandes classes de números são computáveis. Incluem, por exemplo, as partes reais de todos os números algébricos, as partes reais dos zeros das funções de Bessel, os números π, e e outros. No entanto, os números computáveis não incluem todos os números definíveis, como evidenciado pelo seguinte exemplo de um número definível que não é computável.
Embora a classe dos números computáveis seja muito grande e em muitos aspectos semelhante à classe dos números reais, ela ainda é enumerável. No §8 considero certos argumentos que parecem argumentar o contrário. Quando um destes argumentos é aplicado corretamente, tiram-se conclusões que, à primeira vista, são semelhantes às de Gödel*. Esses resultados têm aplicações extremamente importantes. Em particular, conforme mostrado abaixo (§11), o problema de resolução não pode ser resolvido.
Em seu artigo recente, Alonzo Church** introduziu a ideia de “calculabilidade efetiva”, que é equivalente à minha ideia de “computabilidade”, mas tem uma definição completamente diferente. Church também chega a conclusões semelhantes em relação ao problema da resolução. A prova da equivalência entre “computabilidade” e “capacidade de ser efetivamente contada” é apresentada no apêndice deste artigo.
1. Computadores
Já dissemos que números computáveis são aqueles números cujas casas decimais são contáveis por meios finitos. Uma definição mais clara é necessária aqui. Este artigo não fará nenhuma tentativa real de justificar as definições aqui dadas até chegarmos ao §9. Por enquanto, observarei apenas que a justificativa (lógica) para isso é que a memória humana é, por necessidade, limitada.
Vamos comparar uma pessoa no processo de cálculo de um número real com uma máquina que é capaz de cumprir apenas um número finito de condições q1, q2, …, qR; Vamos chamar essas condições de “m-configurações”. Esta máquina (isto é, assim definida) está equipada com uma “fita” (análoga ao papel). Esta correia que passa pela máquina é dividida em seções. Vamos chamá-los de “quadrados”. Cada um desses quadrados pode conter algum tipo de “símbolo”. Em qualquer momento, existe apenas um desses quadrados, digamos o enésimo, contendo o símbolo que está “nesta máquina”. Vamos chamar esse quadrado de “símbolo digitalizado”. Um “caractere digitalizado” é o único caractere do qual a máquina está, por assim dizer, “diretamente consciente”. No entanto, ao alterar sua configuração m, a máquina pode efetivamente lembrar alguns dos caracteres que “viu” (digitalizou) anteriormente. O possível comportamento da máquina a qualquer momento é determinado pela configuração m qn e pelo símbolo digitalizado***. Vamos chamar esse par de símbolos de qn, “configuração”. A configuração assim designada determina o comportamento possível de uma determinada máquina. Em algumas dessas configurações em que o quadrado digitalizado está em branco (ou seja, não contém nenhum caractere), a máquina escreve um novo caractere no quadrado digitalizado e em outras configurações apaga o caractere digitalizado. Esta máquina também é capaz de se mover para escanear outro quadrado, mas desta forma só pode se mover para o quadrado adjacente à direita ou à esquerda. Além de qualquer uma destas operações, a configuração m da máquina pode ser alterada. Neste caso, alguns dos caracteres escritos formarão uma sequência de dígitos, que é a parte decimal do número real que está sendo calculado. O restante nada mais será do que marcas imprecisas para “ajudar a memória”. Neste caso, apenas as marcas imprecisas mencionadas acima podem ser apagadas.
Afirmo que as operações consideradas aqui incluem todas as operações usadas no cálculo. A justificativa para esta afirmação é mais fácil de entender para o leitor que conhece a teoria das máquinas. Portanto, na próxima seção continuarei a desenvolver a teoria em questão, com base na compreensão do significado dos termos “máquina”, “fita”, “digitalizado”, etc. *Gödel “Sobre as sentenças formalmente indecidíveis dos Principia Mathematics (publicado por Whitehead e Russell em 1910, 1912 e 1913) e Sistemas Relacionados, Parte I”, Journal of Mathematics. Física, boletim mensal em alemão nº 38 (para 1931, pp. 173-198. ** Alonzo Church, “Um problema indecidível na teoria elementar dos números”, American J. of Math., No. 58 (1936), pp.*** Alonzo Church, “Uma nota sobre o problema da resolução”, J. of Symbolic Logic, No. 1 (1936), pp.
Em 1936, o cientista Alan Turing, em sua publicação “On Computable Numbers, With An Application to Entscheidungsproblem”, descreve o uso de uma máquina de computação universal que poderia pôr fim ao problema de solubilidade em matemática. Como resultado, ele chega à conclusão de que tal máquina não seria capaz de resolver nada corretamente se o resultado de seu trabalho fosse invertido e girado sobre si mesmo. Acontece que é impossível criar um antivírus *ideal*, um configurador de blocos *ideal*, um programa que sugira frases ideais para o seu travamento, etc. Paradoxo!
No entanto, esta máquina de computação universal pode ser usada para implementar qualquer algoritmo, do qual a inteligência britânica se aproveitou, contratando Turing e permitindo a criação de uma máquina “Bombe” para decifrar mensagens alemãs durante a Segunda Guerra Mundial.
A seguir está a modelagem OOP de um computador de fita única na linguagem Dart, com base no documento original.
Uma máquina de Turing consiste em um filme dividido em seções, cada seção contém um símbolo, os símbolos podem ser lidos ou escritos. Exemplo de aula de cinema:
final _map = Map<int, String>();
String read({required int at}) {
return _map[at] ?? "";
}
void write({required String symbol, required int at}) {
_map[at] = symbol;
}
}
Existe também um “quadrado de digitalização”, que pode mover-se pelo filme, ler ou escrever informações, em linguagem moderna – cabeça magnética. Exemplo de classe de cabeça magnética:
A máquina contém “m-configurações” pelas quais ela pode decidir o que fazer em seguida. Na linguagem moderna – estados e manipuladores de estado. Exemplo de manipulador de estado:
FiniteStateControlDelegate? delegate = null;
void handle({required String symbol}) {
if (symbol == OPCODE_PRINT) {
final argument = delegate?.nextSymbol();
print(argument);
}
else if (symbol == OPCODE_GENERATE_RANDOM_NUMBER_FROM_ZERO_TO_AND_WRITE_AFTER) {
final to = int.tryParse(delegate!.nextSymbol())!;
final value = new Random().nextInt(to);
delegate!.nextSymbol();
delegate!.write(value.toString());
}
else if (symbol == OPCODE_INPUT_TO_NEXT) {
final input = stdin.readLineSync()!;
delegate?.nextSymbol();
delegate?.write(input);
}
else if (symbol == OPCODE_COPY_FROM_TO) {
final currentIndex = delegate!.index();
и т.д.
Depois disso, você precisa criar “configurações”, em linguagem moderna são códigos de operação (opcodes) e seus manipuladores. Códigos de operação de exemplo:
const OPCODE_PRINT = "print";
const OPCODE_INCREMENT_NEXT = "increment next";
const OPCODE_DECREMENT_NEXT = "decrement next";
const OPCODE_IF_PREVIOUS_NOT_EQUAL = "if previous not equal";
const OPCODE_MOVE_TO_INDEX = "move to index";
const OPCODE_COPY_FROM_TO = "copy from index to index";
const OPCODE_INPUT_TO_NEXT = "input to next";
const OPCODE_GENERATE_RANDOM_NUMBER_FROM_ZERO_TO_AND_WRITE_AFTER = "generate random number from zero to next and write after";
Não se esqueça de criar um opcode e um manipulador de parada, caso contrário você não será capaz de provar ou deixará de provar (sic!) a resolução do problema.
Agora, usando o padrão “mediador”, conectamos todas as classes da classe Turing Machine, criamos uma instância da classe, gravamos o programa através de um gravador, carregamos a fita e você pode usá-la!
Para mim, pessoalmente, a questão do que era primário permaneceu interessante – criação de uma calculadora universal ou prova do “Entscheidungsproblem” como resultado do qual, como subproduto, apareceu uma calculadora.
Cassetes
Para me divertir, gravei vários programas em fita cassete para minha versão da máquina.
Olá, mundo
hello world
stop
Считаем до 16-ти
0
if previous not equal
16
copy from index to index
1
8
print
?
move to index
0
else
copy from index to index
1
16
print
?
print
Finished!
stop
Самой интересной задачей было написание Quine программы, которая печатает свой исходный код, для одноленточной машины. Первые 8 часов мне казалось что эта задача не решаема с таким малым количеством опкодов, однако всего через 16 часов оказалось что я был не прав.
Nesta nota descreverei o processo de leitura do joystick, mudança de posição do sprite, giro horizontal, emulador Sega Genesis e potencialmente o próprio console.
A leitura de cliques e o processamento de “eventos” de um joystick shogi ocorre de acordo com o seguinte esquema:
Solicitação de uma combinação de bits de botões pressionados
Lendo pedaços de botões pressionados
Processamento no nível lógico do jogo
Para mover o sprite do esqueleto, precisamos armazenar variáveis da posição atual.
RAM
As variáveis lógicas do jogo são armazenadas na RAM; até agora as pessoas não encontraram nada melhor. Vamos declarar endereços de variáveis e alterar o código de renderização:
Como você pode ver, o endereço disponível para trabalho começa em 0xFF0000 e termina em 0xFFFFFF, no total temos 64 KB de memória disponíveis. As posições do esqueleto são declaradas em esqueletoXpos, esqueletoYpos, rotação horizontal em esqueletoHorizontalFlip.
Joypad
Por analogia com o VDP, o trabalho com joypads ocorre através de duas portas separadamente – porta de controle e porta de dados, para a primeira 0xA10009 e 0xA10003 co-no. Há um recurso interessante ao trabalhar com um joypad: Primeiro você precisa solicitar uma combinação de botões para polling e, em seguida, após aguardar uma atualização no barramento, ler os pressionamentos necessários. Para os botões C/B e D-pad é 0x40, exemplo abaixo:
move.b #$40,joypad_one_control_port; C/B/Dpad
nop ; bus sync
nop ; bus sync
move.b joypad_one_data_port,d2
rts
No registro d2 permanecerá o estado dos botões pressionados ou não pressionados, em geral permanecerá o que foi solicitado através da porta data. Depois disso, vá até o visualizador de registros Motorola 68000 do seu emulador favorito, veja a que é igual o registro d2, dependendo das teclas digitadas. De forma inteligente, você pode descobrir no manual, mas não acreditamos apenas na palavra deles. Processamento adicional de botões pressionados no registro d2
cmp #$FFFFFF7B,d2; handle left
beq MoveLeft
cmp #$FFFFFF77,d2; handle right
beq MoveRight
cmp #$FFFFFF7E,d2; handle up
beq MoveUp
cmp #$FFFFFF7D,d2; handle down
beq MoveDown
rts
Проверять нужно конечно отдельные биты, а не целыми словами, но пока и так сойдет. Теперь осталось самое простое – написать обработчики всех событий перемещения по 4-м направлениям. Для этого меняем переменные в RAM, и запускаем процедуру перерисовки.
Пример для перемещения влево + изменение горизонтального флипа:
После добавления всех обработчиков и сборки, вы увидите как скелет перемещается и поворачивается по экрану, но слишком быстро, быстрее самого ежа Соника.
Не так быстро!
Чтобы замедлить скорость игрового цикла, существуют несколько техник, я выбрал самую простую и не затрагивающую работу с внешними портами – подсчет цифры через регистр пока она не станет равна нулю.
Depois disso, o esqueleto fica mais lento, o que era necessário. Como eu sei, a opção mais comum para “desacelerar” é contar o sinalizador de sincronização vertical, você pode contar quantas vezes a tela foi desenhada, ficando assim vinculada a um fps específico.
Neste post irei descrever como desenhar sprites usando o emulador VDP do console Sega Genesis. O processo de renderização de sprites é muito semelhante ao de renderização de blocos:
Usando ImaGenesis, vamos convertê-lo em cores CRAM e padrões VRAM para assembler. Depois disso, obteremos dois arquivos no formato asm, depois reescreveremos as cores no tamanho da palavra, e os ladrilhos deverão ser colocados na ordem correta para o desenho. Informação interessante: você pode mudar o incremento automático de VDP através do registro 0xF para o tamanho da palavra, isso removerá o incremento de endereço do código de preenchimento de cores CRAM.
VRAM
O manual do Shogi tem a ordem correta dos blocos para sprites grandes, mas somos mais espertos, então pegaremos os índices do blog ChibiAkumas, vamos começar a contar a partir do índice 0:
0 4 8 12
1 5 9 13
2 6 10 14
3 7 11 15
Por que está tudo de cabeça para baixo? O que você quer, o console é japonês! Pode até ser da direita para a esquerda! Vamos alterar manualmente a ordem no arquivo sprite asm:
Para desenhar um sprite, basta preencher a Tabela de Sprites
Tabela Sprite
A tabela de sprites é preenchida em VRAM, o endereço de sua localização é inserido no registrador VDP 0x05, o endereço é novamente complicado, você pode ver no manual, um exemplo para o endereço F000:
Ок, теперь запишем наш спрайт в таблицу. Для этого нужно заполнить “структуру” данных состоящую из четырех word. Бинарное описание структуры вы можете найти в мануале. Лично я сделал проще, таблицу спрайтов можно редактировать вручную в эмуляторе Exodus.
Os parâmetros da estrutura são óbvios pelo nome, por exemplo XPos, YPos – coordenadas, blocos – número do bloco inicial para desenho, HSize, VSize – tamanhos de sprite adicionando partes 8×8, HFlip, VFlip – rotação de hardware do sprite horizontal e verticalmente. É muito importante lembrar que os sprites podem ficar fora da tela, esse é um comportamento correto, pois… descarrega sprites fora da tela da memória – uma atividade que consome muitos recursos. Após preencher os dados no emulador, eles precisam ser copiados da VRAM para o endereço 0xF000, o Exodus também suporta esse recurso. Por analogia com o desenho de blocos, primeiro acessamos a porta de controle VDP para começar a escrever no endereço 0xF000, depois escrevemos a estrutura na porta de dados. Deixe-me lembrar que a descrição do endereçamento VRAM pode ser lida no manual ou no blog Algoritmo Sem Nome .
Resumindo, o endereçamento VDP funciona assim: [..DC BA98 7654 3210 …. …. …. ..FE] Onde hex é a posição do bit no endereço desejado. Os dois primeiros bits são o tipo de comando solicitado, por exemplo 01 – escreva para VRAM. Então para o endereço 0XF000 acontece: 0111 0000 0000 0000 0000 0000 0000 0011 (70000003)
Neste post irei descrever como exibir uma imagem de blocos no emulador Sega Genesis usando assembler. A imagem inicial do Demens Deum no emulador Exodus terá esta aparência:
O processo de saída de uma imagem PNG usando blocos é feito passo a passo:
Reduzindo a imagem para o tamanho da tela do Shogi
Converta PNG em código de dados assembly, separado em cores e blocos
Carregando uma paleta de cores no CRAM
Carregando blocos/padrões na VRAM
Carregando índices de blocos em endereços do plano A/B na VRAM
Você pode reduzir a imagem para o tamanho da tela do Shogi usando seu editor gráfico favorito, como o Blender.
Conversão de PNG
Para converter imagens, você pode usar a ferramenta ImaGenesis; para trabalhar no wine, são necessárias bibliotecas Visual Basic 6, elas podem ser instaladas usando winetricks (winetricks vb6run), ou RICHTX32.OCX pode ser baixado da Internet e colocado em a pasta do aplicativo para operação correta.< /p>
No ImaGenesis você precisa selecionar cores de 4 bits, exportar cores e blocos para dois arquivos no formato assembler. A seguir, no arquivo com cores, você precisa colocar cada cor em uma palavra (2 bytes), para isso utiliza o opcode dc.w.
Como você pode ver no exemplo acima, os blocos são uma grade 8×8 que consiste em índices da paleta de cores CRAM.
Cores no CRAM
O carregamento na CRAM é feito configurando um comando de carregamento de cores para um endereço CRAM específico na porta de controle (controle vdp). O formato do comando está descrito no Sega Genesis Software Manual (1989), apenas acrescentarei que você só precisa adicionar 0x20000 ao endereço para passar para a próxima cor.
Em seguida você precisa carregar a cor na porta de dados (dados vdp); A maneira mais fácil de entender o carregamento é com o exemplo abaixo:
A seguir, carregamos blocos/padrões na memória de vídeo VRAM. Para fazer isso, selecione um endereço na VRAM, por exemplo 0x00000000. Por analogia com a CRAM, entramos em contato com a porta de controle VDP com um comando para escrever na VRAM e no endereço inicial.
Depois disso, você pode fazer upload de palavras longas para VRAM; em comparação com CRAM, não é necessário especificar o endereço de cada palavra longa, pois existe um modo de incremento automático de VRAM. Você pode habilitá-lo usando o sinalizador de registro VDP 0x0F (dc.b $02)
Agora temos que preencher a tela com blocos de acordo com seu índice. Para isso, a VRAM é preenchida no endereço do Plano A/B, que é inserido nos registradores VDP (0x02, 0x04). Mais informações sobre endereçamento complicado estão no manual da Sega; no meu exemplo, o endereço VRAM é 0xC000, vamos fazer upload dos índices lá.
Sua imagem preencherá o espaço VRAM fora da tela de qualquer maneira, então depois de desenhar o espaço da tela, seu renderizador deverá parar de desenhar e continuar novamente quando o cursor se mover para uma nova linha. Existem muitas opções de como implementar isso; usei a versão mais simples de contagem em dois registros do contador de largura da imagem e do contador de posição do cursor.
Exemplo de código:
move.w #0,d0 ; column index
move.w #1,d1 ; tile index
move.l #$40000003,(vdp_control_port) ; initial drawing location
move.l #2500,d7 ; how many tiles to draw (entire screen ~2500)
imageWidth = 31
screenWidth = 64
FillBackgroundStep:
cmp.w #imageWidth,d0
ble.w FillBackgroundStepFill
FillBackgroundStep2:
cmp.w #imageWidth,d0
bgt.w FillBackgroundStepSkip
FillBackgroundStep3:
add #1,d0
cmp.w #screenWidth,d0
bge.w FillBackgroundStepNewRow
FillBackgroundStep4:
dbra d7,FillBackgroundStep ; loop to next tile
Stuck:
nop
jmp Stuck
FillBackgroundStepNewRow:
move.w #0,d0
jmp FillBackgroundStep4
FillBackgroundStepFill:
move.w d1,(vdp_data_port) ; copy the pattern to VPD
add #1,d1
jmp FillBackgroundStep2
FillBackgroundStepSkip:
move.w #0,(vdp_data_port) ; copy the pattern to VPD
jmp FillBackgroundStep3
Depois disso, só falta montar a rom usando o vasm, iniciar o simulador e ver a foto.
Depuração
Nem tudo vai dar certo imediatamente, então eu gostaria de recomendar as seguintes ferramentas do emulador Exodus:
Depurador de processador M68k
Alterando o número de ciclos do processador m68k (para modo câmera lenta no depurador)
Visualizadores CRAM, VRAM, Plano A/B
Leia atentamente a documentação do m68k, os opcodes usados (nem tudo é tão óbvio quanto parece à primeira vista)
Veja exemplos de código/desmontagem do jogo no github
Implementar sub-rotinas de exceções do processador e processá-las
Ponteiros para sub-rotinas de exceção do processador são colocados no cabeçalho da rom. Há também um projeto no GitHub com um depurador de tempo de execução interativo para Sega, chamado genesis-debugger.
Use todas as ferramentas disponíveis, tenha uma boa codificação à moda antiga e que o Blast Processing esteja com você!
Neste post irei descrever como carregar cores na paleta Shogi em linguagem assembly. O resultado final no emulador Exodus ficará assim:
Para facilitar o processo, encontre um pdf na Internet chamado Genesis Software Manual (1989), ele descreve todo o processo detalhadamente, na verdade, esta nota é um comentário ao manual original.< /p>
Para gravar cores no chip VDP do emulador Sega, você precisa fazer o seguinte:
Desativar proteção TMSS
Escrever parâmetros corretos nos registros VDP
Escreva as cores desejadas no CRAM
Para montagem usaremos vasmm68k_mot e um editor de texto favorito, por exemplo echo. A montagem é realizada com o comando:
Порты VDP
VDP чип общается с M68K через два порта в оперативной памяти – порт контроля и порт данных.
По сути:
Через порт контроля можно выставлять значения регистрам VDP.
Также порт контроля является указателем на ту часть VDP (VRAM, CRAM, VSRAM etc.) через которую передаются данные через порт данных
Интересная информация: Сега сохранила совместимость с играми Master System, на что указывает MODE 4 из мануала разработчика, в нем VDP переключается в режим Master System.
Объявим порты контроля и данных:
vdp_data_port = $C00000
Отключить систему защиты TMSS
Защита от нелицензионных игр TMSS имеет несколько вариантов разблокировки, например требуется чтобы до обращения к VDP в адресном регистре A1 лежала строка “SEGA”.
MOVE.B A1,D0; Получаем версию хардвары цифрой из A1 в регистр D0
ANDI.B 0x0F,D0; По маске берем последние биты, чтобы ничего не сломать
BEQ.B SkipTmss; Если версия равна 0, скорее всего это японка или эмулятор без включенного TMSS, тогда идем в сабрутину SkipTmss
MOVE.L "SEGA",A1; Или записываем строку SEGA в A1
Escrever parâmetros corretos nos registros VDP
Por que definir os parâmetros corretos nos registros VDP? A ideia é que o VDP pode fazer muita coisa, então antes de renderizar você precisa inicializá-lo com os recursos necessários, caso contrário ele simplesmente não entenderá o que querem dele.
Cada registro é responsável por um modo de configuração/operação específico. O manual do Segov indica todos os bits/sinalizadores para cada um dos 24 registros, uma descrição dos próprios registros.
Vamos usar parâmetros prontos com comentários do blog bigevilcorporation:
VDPReg0: dc.b $14 ; 0: H interrupt on, palettes on
VDPReg1: dc.b $74 ; 1: V interrupt on, display on, DMA on, Genesis mode on
VDPReg2: dc.b $30 ; 2: Pattern table for Scroll Plane A at VRAM $C000
; (bits 3-5 = bits 13-15)
VDPReg3: dc.b $00 ; 3: Pattern table for Window Plane at VRAM $0000
; (disabled) (bits 1-5 = bits 11-15)
VDPReg4: dc.b $07 ; 4: Pattern table for Scroll Plane B at VRAM $E000
; (bits 0-2 = bits 11-15)
VDPReg5: dc.b $78 ; 5: Sprite table at VRAM $F000 (bits 0-6 = bits 9-15)
VDPReg6: dc.b $00 ; 6: Unused
VDPReg7: dc.b $00 ; 7: Background colour - bits 0-3 = colour,
; bits 4-5 = palette
VDPReg8: dc.b $00 ; 8: Unused
VDPReg9: dc.b $00 ; 9: Unused
VDPRegA: dc.b $FF ; 10: Frequency of Horiz. interrupt in Rasters
; (number of lines travelled by the beam)
VDPRegB: dc.b $00 ; 11: External interrupts off, V scroll fullscreen,
; H scroll fullscreen
VDPRegC: dc.b $81 ; 12: Shadows and highlights off, interlace off,
; H40 mode (320 x 224 screen res)
VDPRegD: dc.b $3F ; 13: Horiz. scroll table at VRAM $FC00 (bits 0-5)
VDPRegE: dc.b $00 ; 14: Unused
VDPRegF: dc.b $02 ; 15: Autoincrement 2 bytes
VDPReg10: dc.b $01 ; 16: Vert. scroll 32, Horiz. scroll 64
VDPReg11: dc.b $00 ; 17: Window Plane X pos 0 left
; (pos in bits 0-4, left/right in bit 7)
VDPReg12: dc.b $00 ; 18: Window Plane Y pos 0 up
; (pos in bits 0-4, up/down in bit 7)
VDPReg13: dc.b $FF ; 19: DMA length lo byte
VDPReg14: dc.b $FF ; 20: DMA length hi byte
VDPReg15: dc.b $00 ; 21: DMA source address lo byte
VDPReg16: dc.b $00 ; 22: DMA source address mid byte
VDPReg17: dc.b $80 ; 23: DMA source address hi byte,
; memory-to-VRAM mode (bits 6-7)
Ok, agora vamos para a porta de controle e escrever todas as flags nos registradores VDP:
move.l #VDPRegisters,a0 ; Пишем адрес таблицы параметров в A1
move.l #$18,d0 ; Счетчик цикла - 24 = 18 (HEX) в D0
move.l #$00008000,d1 ; Готовим команду на запись в регистр VDP по индексу 0, по мануалу - 1000 0000 0000 0000 (BIN) = 8000 (HEX)
FillInitialStateForVDPRegistersLoop:
move.b (a0)+,d1 ; Записываем в D1 итоговое значение регистра VDP из таблицы параметров, на отправку в порт контроля VDP
move.w d1,vdp_control_port ; Отправляем итоговую команду + значение из D1 в порт контроля VDP
add.w #$0100,d1 ; Поднимаем индекс регистра VDP на 1 (бинарное сложение +1 к индексу по мануалу Сеги)
dbra d0,FillInitialStateForVDPRegistersLoop ; Уменьшаем счетчик регистров, продолжаем цикл если необходимо
Самое сложное это прочитать мануал и понять в каком формате подаются данные на порт контроля, опытные разработчики разберутся сразу, а вот неопытные… Немного подумают и поймут, что синтаксис для записи регистров такой:
0B100(5 бит – индекс регистра)(8 бит/байт – значение)
0B1000001001000101 – записать в регистр VDP 2 (00010), значение флажков 01000101.
Записать нужные цвета в CRAM
Далее идем писать два цвета в память цветов CRAM (Color RAM). Для этого пишем в порт контроля команду на доступ к цвету по индексу 0 в CRAM и отправляем по дата порту цвет. Все!
Пример:
move.l #$C0000000,vdp_control_port ; Доступ к цвету по индексу 0 в CRAM через порт контроля
move.w #228,d0; Цвет в D0
move.w d0,vdp_data_port; Отправляем цвет в порт данных
Depois de construir e executar o emulador no Exodus, sua tela deverá ser preenchida com a cor 228.
Vamos preenchê-lo com uma segunda cor, com base no último byte 127.
move.l #$C07f0000,vdp_control_port ; Доступ к цвету по байту 127 в CRAM через порт контроля
move.w #69,d0; Цвет в D0
move.w d0,vdp_data_port; Отправляем цвет в порт данных
O primeiro artigo dedicado a escrever jogos para o clássico console Sega Genesis em Motorola 68000 Assembly.
Vamos escrever o loop infinito mais simples para a Sega. Para isso precisaremos de: um montador, um emulador com desmontador, um editor de texto favorito, um conhecimento básico da estrutura do Sega rum.
Para desenvolvimento eu uso meu próprio montador/desmontador Gen68KryBaby:
A ferramenta é desenvolvida em Python 3, para montagem é fornecido como entrada um arquivo com extensão .asm ou .gen68KryBabyDisasm, a saída é um arquivo com extensão .gen68KryBabyAsm.bin, que pode ser executado no emulador ou em um console real (tenha cuidado, afaste-se, o console pode explodir!)
A desmontagem de roms também é suportada, para isso você precisa enviar um arquivo rom como entrada, sem as extensões .asm ou .gen68KryBabyDisasm. O suporte ao Opcode aumentará ou diminuirá dependendo do meu interesse no tópico e da participação dos colaboradores.
Estrutura
O cabeçalho rom da Sega ocupa os primeiros 512 bytes. Ele contém informações sobre o jogo, nome, periféricos suportados, soma de verificação e outros sinalizadores do sistema. Presumo que sem título o console nem vai olhar para o rum, pensando que está incorreto, dizendo “o que você está me dando aqui?”
Depois do cabeçalho vem a sub-rotina/Reset sub-rotina, que é onde o processador m68K inicia seu trabalho. Ok, é uma questão pequena – encontrar opcodes (códigos de operação), ou seja, não fazer nada (!) e mudar para a sub-rotina no endereço da memória. Pesquisando no Google, você encontra o opcode NOP, que não faz nada, e o opcode JSR, que realiza um salto incondicional para o endereço do argumento, ou seja, simplesmente move o carro para onde solicitamos, sem nenhum capricho.
Juntando tudo
O doador de cabeçalho da rom foi um dos jogos da versão Beta, atualmente registrado como dados hexadecimais.
Код программы со-но представляет из себя объявление сабрутины Reset/EntryPoint в 512 (0x200) байте, NOP, возврат каретки к 0x00000200, таким образом мы получим бесконечный цикл.
Запускаем ром 1infiniteloop.asm.gen68KryBabyAsm.bin в режиме дебаггера эмулятора Exodus/Gens, смотрим что m68K корректно считывает NOP, и бесконечно прыгает к EntryPoint в 0x200 на JSR
Здесь должен быть Соник показывающий V, но он уехал на Вакен.
Nesta nota escreverei sobre a importância das decisões arquitetônicas ao desenvolver, dar suporte a um aplicativo e em um ambiente de desenvolvimento de equipe.
Durante minha juventude, trabalhei em um aplicativo de pedido de táxi. No programa você pode selecionar um ponto de coleta, um ponto de entrega, calcular o custo da viagem, o tipo de tarifa e, de fato, pedir um táxi. Recebi o aplicativo na última etapa de pré-lançamento, após adicionar diversas correções, o aplicativo foi lançado na AppStore; Já nessa fase, toda a equipe entendeu que estava muito mal implementado, não eram utilizados padrões de projeto, todos os componentes do sistema estavam intimamente conectados, em geral era possível escrevê-lo em uma grande classe contínua (objeto Deus), nada teria mudado, portanto, a forma como as classes misturavam os seus limites de responsabilidade e, na sua massa total, sobrepunham-se umas às outras num acoplamento morto. Posteriormente, a administração decidiu escrever a aplicação do zero, utilizando a arquitetura correta, o que foi feito e o produto final foi implementado para várias dezenas de clientes B2B.
No entanto, descreverei um incidente curioso da arquitetura do passado, do qual às vezes acordo suando frio no meio da noite, ou de repente me lembro no meio do dia e começo a rir histericamente. O problema é que não consegui acertar o cara no poste da primeira vez, e isso derrubou a maior parte do aplicativo, mas o mais importante primeiro.
Era um dia normal de trabalho, um dos clientes recebeu a tarefa de refinar um pouco o design do aplicativo. É trivial mover o ícone no centro da tela de seleção do endereço de coleta alguns pixels para cima. Bem, tendo estimado profissionalmente a tarefa em 10 minutos, levantei o ícone 20 pixels para cima, sem suspeitar de nada, resolvi verificar a ordem do táxi.
O quê? O aplicativo não mostra mais o botão de pedido? Como isso aconteceu?
Eu não conseguia acreditar no que via; depois de aumentar o ícone em 20 pixels, o aplicativo parou de mostrar o botão continuar pedido. Depois de reverter a alteração, vi o botão novamente. Algo estava errado aqui. Depois de passar 20 minutos no depurador, fiquei um pouco cansado de desenrolar o espaguete de chamadas para classes sobrepostas, mas descobri que *mover a imagem realmente muda a lógica da aplicação*
Tudo girava em torno do ícone no centro – um homem em um poste, ao movimentar a carta ele pulou para animar o movimento da câmera, essa animação foi seguida pelo desaparecimento do botão na parte inferior. Aparentemente o programa pensou que o homem deslocado em 20 pixels estava pulando, então de acordo com sua lógica interna ele escondeu o botão de confirmação.
Como isso pode acontecer? Será que o *estado* da tela realmente não depende do padrão da máquina de estado, mas da *representação* da posição do homem no mastro?
Acontece que assim, toda vez que o mapa é desenhado, o aplicativo *cutucou visualmente* no meio da tela e verificou o que estava lá, se houver um homem em um poste, significa que a animação de mudança do mapa terminou e precisa ser mostrada botão. Se o homem não estiver lá, o mapa será deslocado e o botão deverá ser ocultado.
No exemplo acima, está tudo bem, em primeiro lugar, é um exemplo de Máquinas Goldberg (máquinas obscuras), em segundo lugar, um exemplo da relutância do desenvolvedor em interagir de alguma forma com outros desenvolvedores da equipe (tente descobrir sem eu), em terceiro lugar, você pode listar todos os problemas de acordo com o SOLID, padrões (cheiros de código), violações de MVC e muito mais.
Tente não fazer isso, desenvolva-se em todas as direções possíveis, ajude seus colegas no trabalho. Feliz Ano Novo a todos)
Nesta postagem descreverei como trabalhar com o classificador de texto fasttext.
Texto rápido – biblioteca de aprendizado de máquina para classificação de texto. Vamos tentar ensiná-la a identificar uma banda de metal pelo título da música. Para fazer isso, usamos aprendizagem supervisionada usando um conjunto de dados.
Vamos criar um conjunto de dados de músicas com nomes de grupos:
В результате мы получим список классов на которые похож данный пример, с указанием уровня похожести цифрой, в нашем случае похожесть названия песни Bleed на одну из групп датасета.
Для того чтобы модель fasttext умела работать с датасетом выходящим за границы обучающей выборки, используют режим autotune с использованием файла валидации (файл тест). Во время автотюна fasttext подбирает оптимальные гиперпараметры модели, проводя валидацию результата на выборке из тест файла. Время автотюна ограничивается пользователем в самостоятельно, с помощью передачи аргумента autotuneDuration.
Пример создания модели с использованием файла тест:
Nesta nota descreverei o processo de chamada de funções C a partir do assembler. Vamos tentar chamar printf(“Hello World!\n”); e sair(0);
message: db "Hello, world!", 10, 0
section .text
extern printf
extern exit
global main
main:
xor rax, rax
mov rdi, message
call printf
xor rdi, rdi
call exit
Tudo é muito mais simples do que parece, na seção .rodata iremos descrever dados estáticos, neste caso a linha “Hello, world!”, 10 é um caractere de nova linha, e também não esquecemos de anulá-lo.
Na seção de código declararemos as funções externas printf, exit das bibliotecas stdio, stdlib e também declararemos a função de entrada main:
extern printf
extern exit
global main
Passamos 0 para o registrador de retorno da função rax, você pode usar mov rax, 0; mas para acelerar eles usam xor rax, rax; A seguir, passamos um ponteiro para a string do primeiro argumento:
Neste post irei descrever o processo de configuração do IDE, escrevendo o primeiro Hello World em assembler x86_64 para o sistema operacional Ubuntu Linux. Vamos começar instalando o IDE SASM, montador nasm:
Código Hello World retirado do blog James Fisher, adaptado para montagem e depuração em SASM. A documentação do SASM afirma que o ponto de entrada deve ser uma função chamada main, caso contrário a depuração e compilação do código serão incorretas. O que fizemos neste código? Fez uma chamada syscall – acesso ao kernel do sistema operacional Linux com argumentos corretos nos registros, um ponteiro para uma string na seção de dados.
Sob uma lupa
Vejamos o código com mais detalhes:
global – директива ассемблера позволяющая задавать глобальные символы со строковыми именами. Хорошая аналогия – интерфейсы заголовочных файлов языков C/C++. В данном случае мы задаем символ main для функции входа.
section – директива ассемблера позволяющая задавать секции (сегменты) кода. Директивы section или segment равнозначны. В секции .text помещается код программы.
Обьявляем начало функции main. В ассемблере функции называются подпрограммами (subroutine)
Первая машинная команда mov – помещает значение из аргумента 1 в аргумент 2. В данном случае мы переносим значение регистра rbp в rsp. Из комментария можно понять что эту строку добавил SASM для упрощения отладки. Видимо это личные дела между SASM и дебаггером gdb.
Далее посмотрим на код до сегмента данных .rodata, два вызова syscall, первый выводит строку Hello World, второй обеспечивает выход из приложения с корректным кодом 0.
Представим себе что регистры это переменные с именами rax, rdi, rsi, rdx, r10, r8, r9. По аналогии с высокоуровневыми языками, перевернем вертикальное представление ассемблера в горизонтальное, тогда вызов syscall будет выглядеть так:
Тогда вызов печати текста:
Вызов exit с корректным кодом 0:
Рассмотрим аргументы подробнее, в заголовочном файле asm/unistd_64.h находим номер функции __NR_write – 1, далее в документации смотрим аргументы для write:
ssize_t write(int fd, const void *buf, size_t count);
Первый аргумент – файловый дескриптор, второй – буфер с данными, третий – счетчик байт для записи в дескриптор. Ищем номер файлового дескриптора для стандартного вывода, в мануале по stdout находим код 1. Далее дело за малым, передать указатель на буфер строки Hello World из секции данных .rodata – msg, счетчик байт – msglen, передать в регистры rax, rdi, rsi, rdx корректные аргументы и вызвать syscall.
Обозначение константных строк и длины описывается в мануале nasm:
A tabela hash permite implementar uma estrutura de dados de array associativo (dicionário) com desempenho médio O(1) para operações de inserção, exclusão e pesquisa.
Abaixo está um exemplo da implementação mais simples de um mapa hash em nodeJS:
Como funciona? Cuidado com as mãos:
Dentro do mapa hash há um array
Dentro do elemento array há um ponteiro para o primeiro nó da lista vinculada
A memória é alocada para uma matriz de ponteiros (por exemplo, 65.535 elementos)
Eles implementam uma função hash, a chave do dicionário é a entrada e na saída pode fazer qualquer coisa, mas no final retorna o índice do elemento do array
Como funciona a gravação:
Na entrada há um par de chaves – valor
A função hash retorna índice por chave
Obter um nó de lista vinculada de um array por índice
Verifique se corresponde à chave
Se corresponder, substitua o valor
Se não corresponder, passe para o próximo nó até encontrarmos ou encontrarmos um nó com a chave necessária.
Se o nó ainda não for encontrado, crie-o no final da lista vinculada
Como funciona a pesquisa por chave:
Na entrada há um par de chaves – valor
A função hash retorna índice por chave
Obter um nó de lista vinculada de um array por índice
Verifique se corresponde à chave
Se corresponder, retorne o valor
Se não corresponder, passe para o próximo nó até encontrarmos ou encontrarmos um nó com a chave necessária.
Por que precisamos de uma lista vinculada dentro de um array? Devido a possíveis colisões ao calcular a função hash. Nesse caso, vários pares de valores-chave diferentes estarão localizados no mesmo índice da matriz, caso em que a lista vinculada é percorrida para encontrar a chave necessária.
Para trabalhar com recursos no Android via ndk – C++ existem várias opções:
Use o acesso aos recursos de um arquivo apk usando o AssetManager
Baixe recursos da Internet e descompacte-os no diretório do aplicativo, use-os usando métodos C++ padrão
Método combinado – acesse o arquivo com recursos no apk via AssetManager, descompacte-os no diretório do aplicativo e use-os usando métodos C++ padrão
A seguir descreverei o método de acesso combinado usado no motor de jogo Flame Steel Engine. Ao usar SDL, você pode simplificar o acesso aos recursos de um apk; a biblioteca agrupa chamadas para o AssetManager, oferecendo interfaces semelhantes ao stdio (fopen, fread, fclose, etc.)
Depois de baixar o arquivo do apk para o buffer, você precisa alterar o diretório de trabalho atual para o diretório do aplicativo, ele fica disponível para o aplicativo sem obter permissões adicionais. Para fazer isso, usaremos um wrapper SDL:
chdir(SDL_AndroidGetInternalStoragePath());
Em seguida, grave o arquivo do buffer no diretório de trabalho atual usando fopen, fwrite, fclose. Assim que o arquivo estiver em um diretório acessível ao C++, descompacte-o. Os arquivos Zip podem ser descompactados usando uma combinação de duas bibliotecas – – minizip e zlib, o primeiro pode trabalhar com a estrutura de arquivos, enquanto o segundo descompacta dados. Para obter mais controle e facilidade de portabilidade, implementei meu próprio formato de arquivo de compactação zero chamado FSChest (Flame Steel Chest). Este formato suporta arquivar um diretório com arquivos e descompactá-lo; Não há suporte para hierarquia de pastas; você só pode trabalhar com arquivos. Conectamos o cabeçalho da biblioteca FSChest, descompacte o arquivo:
Após a descompactação, as interfaces C/C++ terão acesso aos arquivos do arquivo. Assim, não precisei reescrever todo o trabalho com arquivos no mecanismo, apenas adicionei a descompactação dos arquivos na fase de inicialização.
Suponha que precisemos implementar um interpretador de bytecode simples. Que abordagem devemos escolher para implementar essa tarefa?
Estrutura de dados A pilha fornece a capacidade de implementar uma máquina de bytecode simples. Os recursos e implementações de máquinas stack são descritos em muitos artigos na Internet ocidental e doméstica. Apenas mencionarei que a máquina virtual Java é um exemplo de máquina stack.
O princípio de funcionamento da máquina é simples, um programa contendo dados e códigos de operação (opcodes) é fornecido à entrada e as operações necessárias são implementadas por meio de manipulações com a pilha. Vejamos um exemplo de programa de bytecode da minha máquina de pilha:
пMVkcatS olleHП
Na saída receberemos a string “Hello StackVM”. A máquina de pilha lê o programa da esquerda para a direita, carregando dados caractere por caractere na pilha quando um opcode aparece no símbolo – implementa o comando usando a pilha.
Exemplo de implementação de uma máquina stack em nodejs:
Notação polonesa reversa (RPN)
As máquinas Stack também são fáceis de usar para implementar calculadoras, para isso utilizam a notação polonesa reversa (notação postfix). Exemplo de notação infixa regular: 2*2+3*4
Converte para RPN: 22*34*+
Para contar o registro postfix usamos uma máquina de pilha: 2– para o topo da pilha (pilha: 2) 2– para o topo da pilha (pilha: 2,2) *– pegue o topo da pilha duas vezes, multiplique o resultado, envie para o topo da pilha (pilha: 4) 3– para o topo da pilha (pilha: 4, 3) 4– para o topo da pilha (pilha: 4, 3, 4) *– pegue o topo da pilha duas vezes, multiplique o resultado, envie-o para o topo da pilha (pilha: 4, 12) +– pegue o topo da pilha duas vezes, some o resultado, envie-o para o topo da pilha (pilha: 16)
Como você pode ver – o resultado das operações 16 permanece na pilha, ele pode ser impresso implementando opcodes de impressão da pilha, por exemplo: p22*34*+P
P – Código de operação de início de impressão da pilha, p – opcode para finalizar a impressão da pilha e enviar a linha final para renderização. Para converter operações aritméticas de infixo para pós-fixo, é usado o algoritmo de Edsger Dijkstra chamado “Sorting Yard”. Um exemplo da implementação pode ser visto acima, ou no repositório do projeto de pilha de máquinas nodejs abaixo.
Continuo descrevendo o algoritmo de animação do esqueleto conforme ele é implementado no Flame Steel Engine.
Como o algoritmo é o mais complexo de todos que implementei, podem aparecer erros nas notas sobre o processo de desenvolvimento. No artigo anterior sobre esse algoritmo, cometi um erro; o array de ossos é transferido para o shader para cada malha separadamente, e não para o modelo inteiro.
Hierarquia de nós
Para que o algoritmo funcione corretamente é necessário que o modelo contenha uma conexão entre os ossos entre si (gráfico). Vamos imaginar uma situação em que duas animações são reproduzidas simultaneamente – – pule e levante a mão direita. A animação de salto deve levantar o modelo ao longo do eixo Y, enquanto a animação de levantar o braço deve levar isso em consideração e subir com o modelo enquanto ele salta, caso contrário o braço permanecerá no lugar por conta própria.
Descreveremos a conexão dos nós para este caso – o corpo contém a mão. Ao elaborar o algoritmo, o gráfico ósseo será lido, todas as animações serão levadas em consideração com as conexões corretas. Na memória do modelo, o gráfico é armazenado separadamente de todas as animações, apenas para refletir a conectividade dos ossos do modelo.
Interpolação na CPU
No último artigo descrevi o princípio de renderização de animação esquelética – “matrizes de transformação são transferidas da CPU para o shader a cada quadro de renderização.”
Cada quadro de renderização é processado na CPU; para cada osso da malha, o mecanismo recebe a matriz de transformação final usando interpolação de posição, rotação e zoom. Durante a interpolação da matriz óssea final, uma passagem é feita através da árvore de nós para todas as animações de nós ativos, a matriz final é multiplicada pelas matrizes pai e, em seguida, enviada para renderização ao sombreador de vértice.
Os vetores são usados para interpolação de posição e a ampliação é usada para rotação, porque; eles são muito fáceis de interpolar (SLERP), ao contrário dos ângulos de Euler, e também são muito fáceis de representar como uma matriz de transformação.
Como simplificar a implementação
Para facilitar a depuração do vertex shader, adicionei uma simulação do vertex shader na CPU usando a macro FSGLOGLNEWAGERENDERER_CPU_BASED_VERTEX_MODS_ENABLED. O fabricante de placas de vídeo NVIDIA possui um utilitário para depurar código de shader Nsight, talvez ele também possa simplificar o desenvolvimento de algoritmos complexos de shader de vértices/pixels, mas nunca consegui testar sua funcionalidade. A simulação na CPU foi suficiente.
No próximo artigo pretendo descrever a mistura de múltiplas animações e preencher as lacunas restantes.
Neste post descreverei uma maneira de adicionar suporte para scripts JavaScript a uma aplicação C++ usando a biblioteca Tiny-JS.
Tiny-JS é uma biblioteca para incorporação em C++, fornecendo execução de código JavaScript, com suporte para vinculações (a capacidade de chamar código C++ a partir de scripts)
No começo eu queria usar as bibliotecas populares ChaiScript, Duktape ou Connect Lua, mas devido a dependências e possíveis dificuldades de portabilidade para diferentes plataformas, decidi encontrar uma biblioteca MIT JS simples, mínima, mas poderosa; JS atende a esses critérios. A única desvantagem desta biblioteca é a falta de suporte/desenvolvimento por parte do autor, mas seu código é bastante simples, o que permite assumir o suporte se necessário.
Nesta postagem, descreverei o procedimento para criar um aplicativo C++ SDL para iOS no Linux, assinar um arquivo ipa sem uma assinatura paga do Apple Developer e instalá-lo em um dispositivo limpo (iPad) usando macOS sem Jailbreak.< /p>
No momento, você precisa baixar o Xcode dmg e copiar o SDK de lá para construir o cctools-port. Esta etapa é mais fácil de concluir no macOS; basta copiar os arquivos SDK necessários do Xcode instalado. Após a montagem bem-sucedida, o terminal conterá o caminho para o conjunto de ferramentas do compilador cruzado.
Em seguida, você pode começar a criar o aplicativo SDL para iOS. Vamos abrir o cmake e adicionar as alterações necessárias para construir o código C++:
No meu caso, as bibliotecas SDL, SDL_Image, SDL_mixer são compiladas no Xcode no macOS antecipadamente para vinculação estática; Frameworks copiados do Xcode. A biblioteca libclang_rt.ios.a também foi adicionada, que inclui chamadas de tempo de execução específicas do iOS, por exemplo isOSVersionAtLeast. Uma macro está incluída para trabalhar com OpenGL ES, desabilitando funções não suportadas na versão móvel, semelhante ao Android.
Depois de resolver todos os problemas de construção, você deverá obter o binário montado para arm. A seguir, vamos considerar a execução do binário montado em um dispositivo sem Jailbreak.
No macOS, instale o Xcode, cadastre-se no portal da Apple, sem pagar pelo programa de desenvolvedor. Adicione uma conta no Xcode -> Preferências -> Contas, crie um aplicativo em branco e construa em um dispositivo real. Durante a montagem, o dispositivo será adicionado à conta de desenvolvedor gratuita. Após a montagem e lançamento, você precisa construir o arquivo para fazer isso, selecione Dispositivo e produto iOS genérico -> Arquivo. Depois que o arquivo for compilado, extraia os arquivos incorporados.mobileprovision e PkgInfo dele. No log de compilação do dispositivo, encontre a linha de codesign com a chave de assinatura correta, o caminho para o arquivo de direitos com a extensão app.xcent e copie-o.
Copie a pasta .app do arquivo, substitua o binário no arquivo por um compilado por um compilador cruzado no Linux (por exemplo SpaceJaguar.app/SpaceJaguar), depois adicione os recursos necessários ao .app, verifique o integridade dos arquivos PkgInfo e incorporado.mobileprovision no .app do arquivo, copie novamente se necessário. Assinamos novamente o .app usando o comando codesign – codesign requer uma chave de entrada para assinar, o caminho para o arquivo de direitos (pode ser renomeado com uma extensão .plist)
Após assinar novamente, crie uma pasta Payload, mova a pasta com a extensão .app para lá, crie um arquivo zip com Payload na raiz, renomeie o arquivo com a extensão .ipa. Depois disso, no Xcode, abra a lista de dispositivos e arraste e solte o novo ipa na lista de aplicativos do dispositivo; A instalação via Apple Configurator 2 não funciona para este método. Se a nova assinatura for feita corretamente, o aplicativo com o novo binário será instalado em um dispositivo iOS (por exemplo iPad) com certificado de 7 dias, o que é suficiente para o período de teste.
We use cookies on our website. By clicking “Accept”, you consent to the use of ALL the cookies. Мы используем куки на сайте. Нажимая "ПРИНЯТЬ" вы соглашаетесь с этим.
This website uses cookies to improve your experience while you navigate through the website. Out of these, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may affect your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
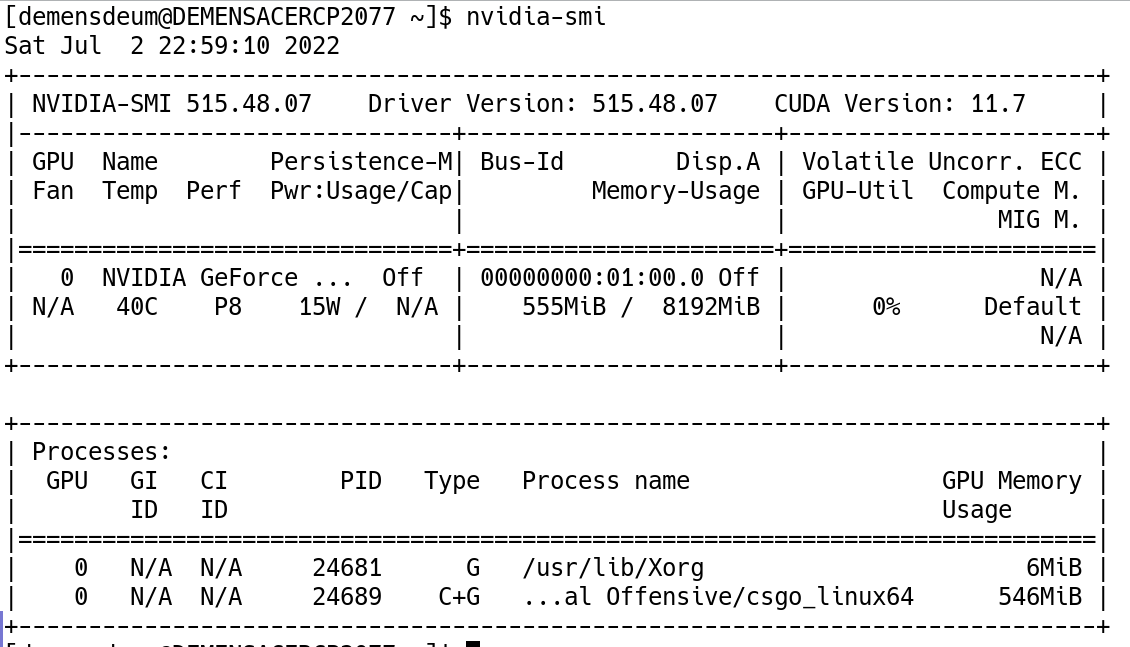
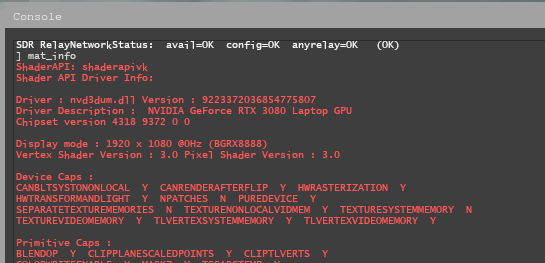






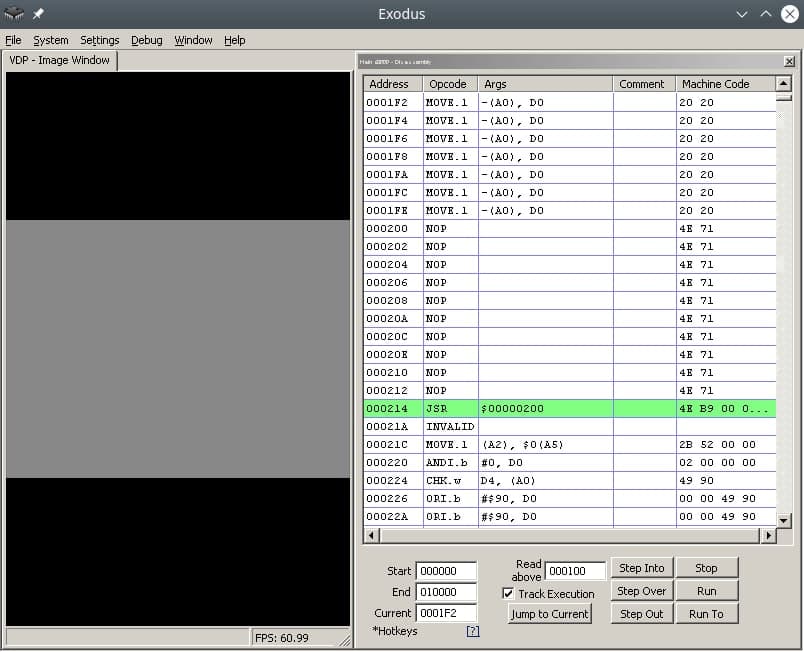
.gif)