Данная заметка посвящается всем, не сдающим позиции, пользователям жестких дисков.

Через 1.5 года использования ноутбука HP Pavilion в дуалбуте HDD (Windows 10) и SSD (Ubuntu) я стал замечать очень долгую загрузку приложений, общую неотзывчивость интерфейса, зависания на простейших операциях в Windows 10. Проблема была минимизирована до той степени, что пользоваться ноутбуком стало возможно снова. Далее опишу действия которые я предпринял для устранения проблемы.
Диагностика
Для начала исследования нужно устранить мистификацию любого порядка, для начала определим основные причины поломок жестких дисков. Что может пойти не так при работе с жестким диском? Проблемы могут возникать на физическом уровне электроники и на логическом, программном уровне данных.
К проблемам электроники относятся такие вещи как: нерабочий блок питания компьютера/ноутбука, проблемы с аккумулятором ноутбука; износ компонентов жесткого диска, неполадки в схемах и чипах внутренних компонентов диска, программные ошибки прошивки, последствия ударов/падений диска, либо аналогичные проблемы с другими устройствами которые влияют на его работу.
Критическим износом жесткого диска считается момент появления количества такого количества сбойных секторов (bad block) при котором дальнейшая эксплуатация диска невозможна. Данные блоки блокируются прошивкой жесткого диска, данные переносятся на другие сектора автоматически и не должны влиять на работу диска до определенного критического момента.
К проблемам программной логики относятся ошибки в файловой системе из-за некорректной работы приложений, действий пользователя: отключение устройства по горячему, завершение процессов записи без корректной остановки приложений, ошибки в драйверах, сервисах операционной системы.
Не имея специализированных средств диагностики электроники, нам остается только проверять корректность программного уровня, уже в процессе могут обнаружиться неполадки электроники, которые обычно устраняют методом блочного ремонта (замена компонентов/чипов); Далее рассмотрим методы программной диагностики с помощью диагностических утилит. Стоит заметить что все утилиты должны запускаться на системе с максимальным приоритетом, т.к. другие приложения могут помешать замерам производительности, блокировать диск на чтение/запись, что приведет к некорректным результатам диагностики.
SMART
S.M.A.R.T. система мониторинга состояния устройств хранения данных – HDD, SDD, eMMC и пр. Позволяет оценить износ устройства, просматривать количество сбойных блоков (bad block), опираясь на данные предпринять дальнейшие действия. Просматривать SMART можно в разных приложениях для работы с дисками, я предпочитаю использовать утилиты от производителя. Для своего жесткого диска Seagate я использовал утилиту SeaTools, для него состояние выводилось как GOOD, то есть прошивка диска считает что все хорошо.
Утилиты производителя
Утилиты производителя диска предоставляют тесты для проверки его работы. SeaTools имеет несколько видов тестов, можно использовать их все для локализации проблемы. Быстрые и простые тесты могут не выявить каких-либо проблем, поэтому предпочитайте долгие тесты. В моем случае только на Long Test были найдены ошибки.
Slowride
Для проверки корректности чтения, нахождения медленных или мертвых блоков, я написал приложение slowride, оно работает по очень простому принципу – открывает дескриптор блочного устройства, с заданными настройками пользователя производит чтения данных всего устройства, с замерами времени, выводом медленных блоков. Программа останавливается на первой же ошибке, в таком случае придется перейти к более серьезным утилитам для снятия данных, так как простыми методами данные диска прочитать не представляется возможным.
В моем случае чтение всего диска осуществлялось корректно, с небольшой просадкой по скорости – 90мб/сек (5400rpm) за одну секунду, на некоторых областях диска. Из чего можно было сделать вывод что я имею дело с программной проблемой.
Акустический анализ
Данный метод не относится к программным методам диагностики, однако является достаточно важным для устранения проблемы. Например при частично рабочем блоке питания, жесткий диск может подвисать/зависать издавая громкий щелчок.
В моем случае при работе с диском в Windows 10 я слышал знакомый всем владельцам HDD, громкий треск бегающей туда-сюда головки диска при попытке сделать что-либо в операционной системе, однако звук был почти постоянным, это навело меня на мысль о слишком большой фрагментации диска, перегрузе диска фоновыми сервисами.
Исправляем
Проблемы электроники во время программной диагностики обнаружены не были, поблочное чтение всего диска завершалось корректно, однако SeaTools показал ошибки на проверке Long Test.
Утилиты производителя
Софт производителя диска помимо диагностики предоставляет процедуры исправления ошибок. В SeaTools за это отвечает кнопка Fix All, после подтверждения согласия с потенциальной потерей данных, запустится процесс исправления. Помог ли в моем случае этот фикс? Нет, диск продолжил работать также громко и медленно, однако ошибок Long Test больше не показывал.
CHKDSK
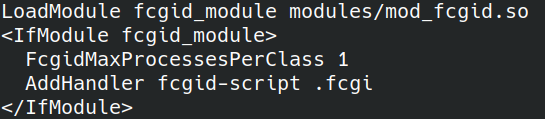
CHKSDK это утилита компании Microsoft для устранения программных ошибок для файловых систем Windows. Со временем такие ошибки накапливаются на диске и могут очень сильно мешать работе, в том числе приводить к невозможности читать/писать какие-либо данные вообще. Инструкцию по использованию утилиты вы можете найти на сайте Microsoft, я же порекомендую использовать все возможные флаги для исправления ошибок (на момент написания заметки это /r /b /f); Запускать проверку нужно с правами администратора через терминал Windows (cmd), для системного раздела она будет проходить на загрузке системы, может проходить очень долгое время, в моем случае заняло 12 часов.
Помог ли этот фикс в моем случае? Нет.
Дефрагментация диска
Работа с данными на диске осуществляется блоками, большие файлы обычно записываются в несколько блоков/фрагментов. Со временем, множество удаленных файлов создают пустые блоки которые не находятся рядом, из-за этого при записи файлы заполняют эти пустоты, и головке диска приходится физически преодолевать большие расстояния. Данная проблема называется фрагментацией, и с ней сталкиваются только пользователи жестких дисков. На момент нескольких фиксов фрагментация моего жесткого диска составляла 41%, визуально это выглядело так:
![]()
То есть все плохо. Увидеть фрагментацию, провести дефрагментацию можно с помощью утилиты Defragger, либо встроенным дефрагментатором. Также можно включить сервис “Optimize drives” в Windows 10, проставить дефрагментацию по расписанию в контрольной панели. Дефрагментацию нужна только HDD дискам, включать для SSD дисков нежелательно, так как это приведет к ускоренному износу диска, видимо по этой причине фоновая дефрагментация отключена по умолчанию.
Известен также альтернативный вариант дефрагментации – перенос данных на другой диск, форматирование диска, и копирование данных обратно. В таком случае данные будут записаны на абсолютно пустые сектора, с сохранением корректной логической структуры для работы системы. Данный вариант чреват проблемами сброса потенциально критических метаданных, которые могут не переместиться при обычном копировании.
Отключаем сервисы
С помощью утилиты Марка Руссиновича Process Monitor можно отследить процессы которые загружают жесткий диск своими делами, достаточно включить колонки IO Write/Read. После исследования данной колонки я отключил сервис Xbox Game Bar, известный сервис фонового ускорения программ Superfetch под новым названием SysMain, через панель сервисов контрольной панели. Superfetch должен постоянно анализировать приложения которыми пользуется юзер и ускорять их запуск с помощью кэширования в оперативную память, в моем случае это приводило к фоновой загрузке всего диска и невозможности работы.
Чистим диск
Также я удалил старые приложения, ненужные файлы, таким образом освободив сектора для корректной фрагментации, упростив работу операционной системе, уменьшив количество бесполезных, тяжелых сервисов и программ.
Итог
Что помогло больше всего? Заметная разница в производительности была достигнута после дефрагментации диска, спонтанные зависания удалось устранить с помощью отключения сервисов Xbox и Superfetch. Не было бы этих проблем, если бы я пользовался SSD? Проблем с медленной работой при фрагментацией определенно не было бы, проблемы с сервисами устранять пришлось бы в любом случае, а программные ошибки не зависят от типа накопителя. В ближайшем будущем планирую полный переход на SSD, ну а пока “Да здравствуют блины, блины навсегда!”
Ссылки
http://www.outsidethebox.ms/why-windows-8-defragments-your-ssd-and-how-you-can-avoid-this/
https://channel9.msdn.com/Shows/The-Defrag-Show
https://www.seagate.com/ru/ru/support/downloads/seatools/
https://www.ccleaner.com/defraggler/download
https://docs.microsoft.com/en-us/windows-server/administration/windows-commands/chkdsk
https://gitlab.com/demensdeum/slowride/